2019CVPR Deep High-Resolution Representation Learning for Human Pose Estimation 姿态估计01
代码:https://github.com/leoxiaobin/ deep-high-resolution-net.pytorch
论文:arXiv:1902.09212v1
题目:深度高分辨率特征学习的姿态估计
摘要:在文章中,主要提出了从始至终维持着高分辨率的特征的深度学习网络,并对比了现存的高分辨率-低分辨率,低分辨率-高分辨率的深度网络框架,本文提出的高分辨率网络分为几个阶段,以高分辨率的子网络作为第一个阶段,不断的添加由高到低的分辨率网络,平行的连接融合多种分辨率的网络,从而获取到高分辨率的特征;作为结果,在预测关键点于热图与空间都取得了更高的精确度。
先附一张此文的主角

1、介绍:本文提出一种新奇的网络框架,高分辨率网络(HRNET),其在网络的整个过程中保持高分辨率特征,第一阶段高分辨率子网络,逐步的在每个阶段添加高-低分辨率的子网,平行连接多尺度网络;反复的使用尺度融合,评估关键点都是从始而终的,网络在图片1中可以看到;提出的网络存在两大优势与现存的网络比较:(1)提出的方法连接高分辨率子网,而不是现存的网络,从网络中恢复到高分辨率,因此热图与空间定位都很准确(2)现存的网络都是融合高分辨率/低分辨率的特征,而我们的网络是反复的融合为高分辨率的网络,高分辨率特征存在丰富的特征信心,预测的热图更精确;在coco keypoint 检测与 MPII human pose 中优于其他的网络的成绩
2 相关的网络:
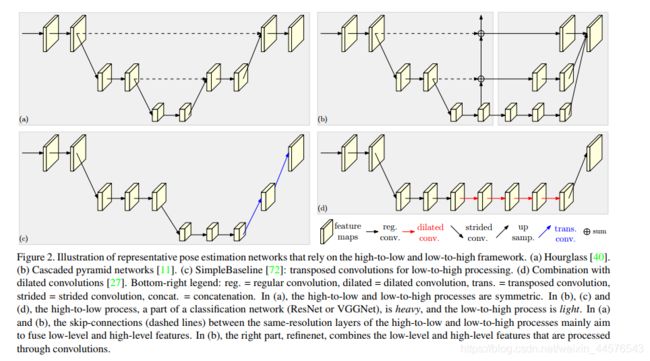
介绍了上面四种网络框架的特点,与本文提出网络的对比,进一步提出自己的方法在计算复杂度与计算参数方面优于现存的方法;
3 方法
人体姿态估计检测主要是关键点的定位,转化为关键点的热图 (热图显示出关键点的置信度),使用卷积网络预测关键点,网络主体的框架输入尺寸等于输出层,回归评估热图转化为完整的分辨率,我们致力于设计网络框架的主体形成了高分辨率网络
连续的多分辨率子网:子网是通过下采样 分别 为原图的 1/2 1/4 1/8 1/16 ,分辨率 提取特征 (N11 N22 N33 N44)
这些子网的输入都是平行存在的,并同时输入相应的主干网络中
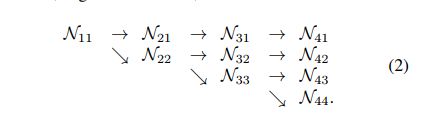
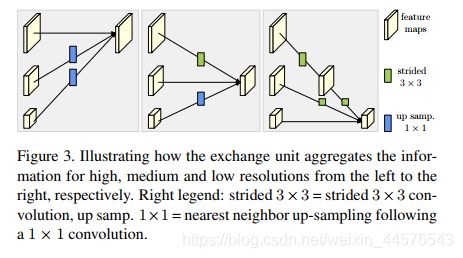
反复多尺度融合:采用上采样(简单的紧邻算法) 下采用(卷积核3*3 步长2 或者4 )
热图估计:通过最后的交换单元的高分辨率输出来回归热图,损失函数 是均值方差,the groundtruth 通过二维高斯生成
网络主题框架:包含4个平行的子网,其分辨率不断减少为前一阶段的一半,第一个阶段包含四个残差在每个单元中,3*3的卷积来减少维度,第二 第三 第四阶段分别包含1 4 3 个交换块,每个块包含4个残差 ,总之包含8个交换单元
4 实验部分
4.1 使用coco 数据集 关键点的检测
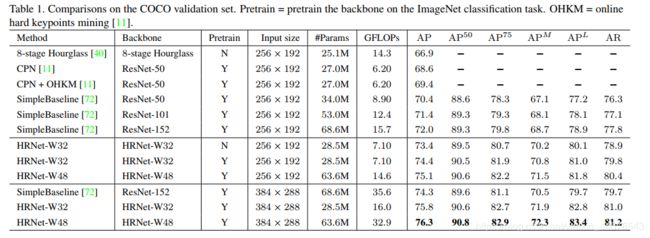
介绍the coco dataset 的基本情况:20万张图片 25万人的标记(17个关键点),本文训练model使用coco train 2017 (包含5.7万图片 15万人的label),验证集在 val 2017,测试集test-dev 2017 其分别包含50万、2万张图片
评价标准:使用(OKS object keypoint similarity)
![]()
我们这里报告 标准的均值精度与召回分数,(AP 50、AP 75 、AP MEAN、AP L )与AR 分别在oks=0.50 0.55 ....0.90 0.95 情况下。
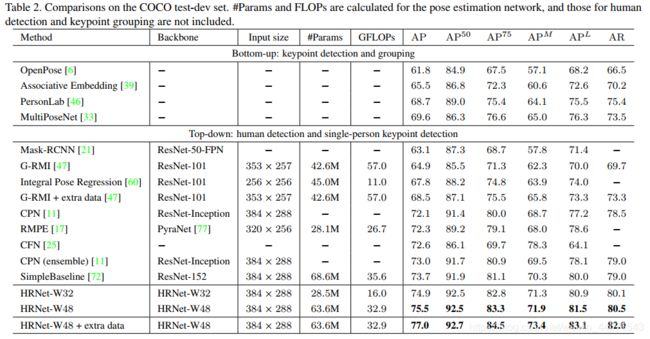
训练:扩张人体姿态检测框的尺寸 形成固定比例4:3 (256*192 384*288);数据增强 在正负45度 随机旋转,在0.65 1.35 之间随机缩放比例,翻转;
使用adam 优化器,学习率0.001 在170、200 epoch 设置le-4 le-5 共210个epoch
测试:先检测人 然后使用预测关键点(从上到下 ),在验证集与测试集使用simple-baseline 人体检测器,通过均值原始与翻转的图片计算热图,每个关键点的预测通过调整热力值,从最高响应到次高响应
验证集上的结果:在表1 可以看到结果 (1)与 Hourglass AP 提高6.5个百分点,计算量减少 (2)与CPN OHKM 我们的大小网络取得4.8 4.0的提升,(3)相比 之前最好的Simple-Baseline提高3个点
网络的优势 得益于(1)从ImageNet训练的分类微调 (2)在宽度上的提高 但计算代价少的多
4.2 在MPII human pose estimation
数据集介绍:此数据集包含宽范围的全体活动标记,2.5万张图片有4万张物体,1.2万用于测试,其余的训练 数据增强与之前的相同,在尺寸方面不同256*256
训练:与之前不同的是提供person box ,六种不同比例的金字塔测试过程,
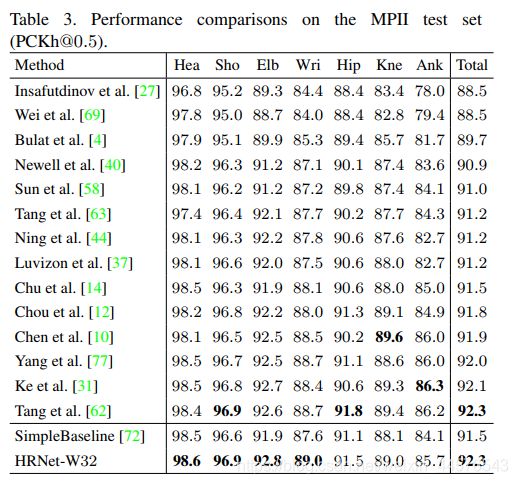
评价方法:使用标准评价方法 the pckh (head-normalized probability of correct keypoint )score,如果关键点在a*l 像素内,则认为正取 a 是常数 0.5 、L 是相对应的头部box对角线的0.6
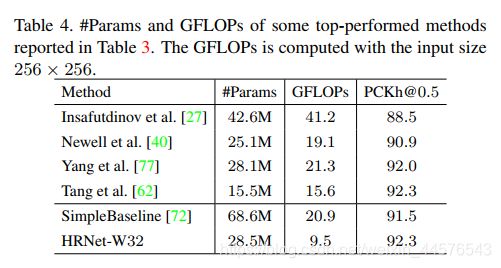
测试结果在表3 、4 上显示
4.3 方法应用姿态跟踪
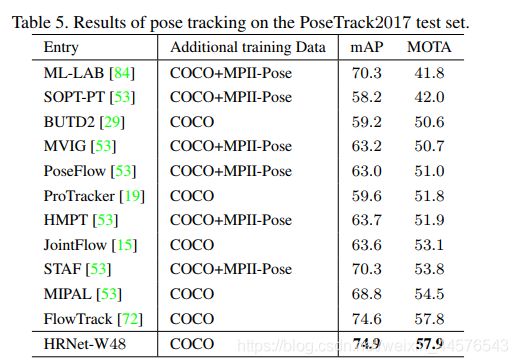
数据集:PoseTrack 大尺度标记用于姿态估计与姿态跟踪的视频集合,数据集基于纯天然的MPII human pose 数据集,包含550 视频 66374个帧;视频序列被分29250208个视频用于训练,验证、测试。每个视频段在41-151不等的帧,30帧被标注,验证集与测试集的视频在65-298帧之间。
评价标准:两个任务 一个是多人的帧间姿态估计、多人姿态跟踪 姿态估计采用(mAP)姿态跟踪是使用MOTA
训练过程:
测试:
结果在表5
4.4 模块简化研究
反复多尺度融合:
分辨率的保持:
特征分辨率:
5、结论与未来的工作
重申了两点(1)高分辨率的保持 并不是恢复到高分辨率(2)多尺度的分辨率反复融合
未来的工作包括:语义分割 物体检测 面部校准 图片翻译等 更多看主页