【机器学习】线性回归【上】朴素最小二乘估计
主要参考了B站UP主“shuhuai008”和“王木头学科学”,以及DeepLearning(花书/圣经),包含自己的理解。
有任何的书写错误、排版错误、概念错误等,希望大家包含指正。
由于字数限制,分成两篇博客。
【机器学习】线性回归【上】朴素最小二乘估计
【机器学习】线性回归【下】正则化最小二乘估计
提醒 下文中的 α \alpha α 和 λ \lambda λ 在不同的小章节中可能表示不同的含义,一般地, α \alpha α 表示向量或正则化, λ \lambda λ 表示学习率或特征值(向量)等。
规定符号。
数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) } D=\{(x_1,y_1),(x_2,y_2),\dots,(x_n,y_n)\} D={(x1,y1),(x2,y2),…,(xn,yn)},向量 x i ∈ R p x_i\in\mathbb{R}^p xi∈Rp 为样本, y i ∈ R y_i\in \mathbb R yi∈R 为标签, i = 1 , 2 , … , n i=1,2,\dots,n i=1,2,…,n; W ∈ R p W\in \mathbb R^p W∈Rp 为模型参数(权重)。
记
X = ( x 1 x 2 … x n ) T = ( x 1 T x 2 T ⋮ x n T ) = ( x 11 x 12 … x 1 p x 11 x 12 … x 2 p ⋮ ⋮ ⋮ x n 1 x n 2 … x n p ) n × p Y = ( y 1 y 2 … y n ) n × 1 T W = ( w 1 w 2 … w p ) p × 1 T X= \left( \begin{matrix} x_1 & x_2 & \dots & x_n \end{matrix} \right)^T =\left( \begin{matrix} x_1^T \\ x_2^T \\ \vdots \\ x_n^T \end{matrix} \right) =\left( \begin{matrix} x_{11} & x_{12} & \dots & x_{1p} \\ x_{11} & x_{12} & \dots & x_{2p} \\ \vdots & \vdots & & \vdots \\ x_{n1} & x_{n2} & \dots & x_{np} \\ \end{matrix} \right)_{n\times p} \\ \\ Y=\left( \begin{matrix} y_1 & y_2 & \dots & y_n \end{matrix} \right)^T_{n\times 1} \\\\ W=\left( \begin{matrix} w_1 & w_2 & \dots & w_p \end{matrix} \right)^T_{p\times 1} X=(x1x2…xn)T=⎝ ⎛x1Tx2T⋮xnT⎠ ⎞=⎝ ⎛x11x11⋮xn1x12x12⋮xn2………x1px2p⋮xnp⎠ ⎞n×pY=(y1y2…yn)n×1TW=(w1w2…wp)p×1T
1. 线性回归
1.1. 定义
模型定义为
f ( α ) = w 0 + w 1 α 1 + ⋯ + w p α p f(\alpha)=w_0+w_1\alpha_1+\dots+w_p\alpha_p f(α)=w0+w1α1+⋯+wpαp
其中样本 α ∈ R p \alpha\in\mathbb R^p α∈Rp,对应标签 y y y , w 0 w_0 w0 为偏置项。一般为了统一处理,认为样本为 p + 1 p+1 p+1 维,在 x i x_i xi(或 X X X) 的第一维添加 x 0 = 1 x_0=1 x0=1,在 W W W 的第一维添加 w 0 w_0 w0 。线性回归模型的目标是找到模型参数 W W W 使得每个样本对应的输出值 f ( α ) = W T α f(\alpha) = W^T\alpha f(α)=WTα 都尽可能地贴近其标签 y y y。
直观上,图 1 1 1 中的绿线显然比红线更加贴近样本点,故认为绿线对应的模型参数比红线对应的模型参数更符合预期。
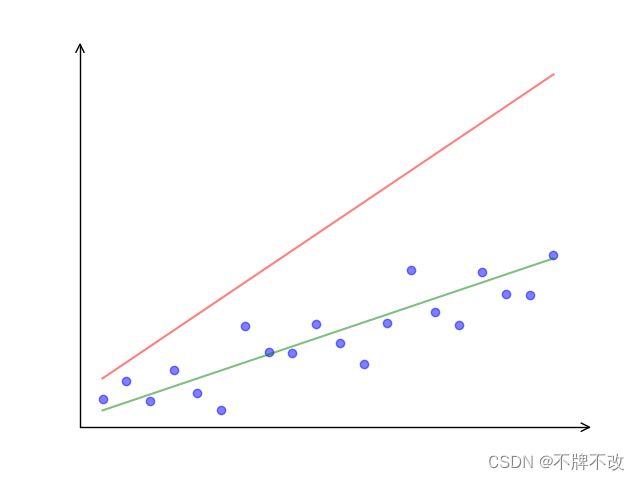
图 1 二维线性回归拟合曲线例图
2. 最小二乘估计
为了方便讲解,不妨忽略掉偏置项。
2.1. 矩阵形式
最小二乘估计(Least Square Estimate,LSE)是训练线性回归模型常用的方法,这个方法对应着一个目标函数
L ( W ) = ∑ i = 1 n ∣ ∣ W T x i − y i ∣ ∣ 2 2 = ∑ i = 1 n ( W T x i − y i ) 2 (1) \begin{aligned} L(W)&=\sum_{i=1}^n||W^Tx_i-y_i||^2_2 \\\notag &=\sum_{i=1}^n(W^Tx_i-y_i)^2\tag{1} \end{aligned} L(W)=i=1∑n∣∣WTxi−yi∣∣22=i=1∑n(WTxi−yi)2(1)
∣ ∣ ⋅ ∣ ∣ 2 ||·||_2 ∣∣⋅∣∣2 表示二范数, ∣ ∣ ⋅ ∣ ∣ 2 2 ||·||_2^2 ∣∣⋅∣∣22 表示二范数的平方。
其他一些资料中可能会在目标函数中添加一些系数,本质上都是等价的。
将式 ( 1 ) (1) (1) 以矩阵形式表示
L ( W ) = ∑ i = 1 n ( W T x i − y i ) 2 = ( W T x 1 − y 1 W T x 2 − y 2 … W T x n − y n ) ( W T x 1 − y 1 W T x 2 − y 2 … W T x n − y n ) T = [ W T ( x 1 x 2 … x n ) − ( y 1 y 2 … y n ) ] [ W T ( x 1 x 2 … x n ) − ( y 1 y 2 … y n ) ] T = ( W T X T − Y T ) ( X W − Y ) = W T X T X W − W T X T Y − Y T X W + Y T Y = W T X T X W − 2 W T X T Y + Y T Y (2) \begin{aligned} L(W)&=\sum_{i=1}^n(W^Tx_i-y_i)^2 \\\notag &=\left(\begin{matrix}W^Tx_1-y_1 & W^Tx_2-y_2 & \dots & W^Tx_n-y_n \end{matrix}\right)\left(\begin{matrix}W^Tx_1-y_1 & W^Tx_2-y_2 & \dots & W^Tx_n-y_n \end{matrix}\right)^T \\\notag &=[W^T\left(\begin{matrix}x_1 & x_2 & \dots & x_n \end{matrix}\right)-\left(\begin{matrix}y_1 & y_2 & \dots & y_n \end{matrix}\right)][W^T\left(\begin{matrix}x_1 & x_2 & \dots & x_n \end{matrix}\right)-\left(\begin{matrix}y_1 & y_2 & \dots & y_n \end{matrix}\right)]^T \\\notag &=(W^TX^T-Y^T)(XW-Y) \\\notag &=W^TX^TXW-W^TX^TY-Y^TXW+Y^TY \\\notag &=W^TX^TXW-2W^TX^TY+Y^TY \tag{2} \end{aligned} L(W)=i=1∑n(WTxi−yi)2=(WTx1−y1WTx2−y2…WTxn−yn)(WTx1−y1WTx2−y2…WTxn−yn)T=[WT(x1x2…xn)−(y1y2…yn)][WT(x1x2…xn)−(y1y2…yn)]T=(WTXT−YT)(XW−Y)=WTXTXW−WTXTY−YTXW+YTY=WTXTXW−2WTXTY+YTY(2)
解释最后一步化简,根据矩阵乘法规则可知, W T X T Y W^TX^TY WTXTY 和 Y T X W Y^TXW YTXW 的结果为 1 × 1 1\times 1 1×1 矩阵即常数,且二者互为转置矩阵,因此 W T X T Y = Y T X W W^TX^TY=Y^TXW WTXTY=YTXW。故最后一步将二者合并。
最小化目标函数 ( 2 ) (2) (2) 对应的 W W W 为目标模型参数,即
W ^ = a r g min W L ( W ) (3) \hat{W}={\rm arg}\min_W L(W) \tag{3} W^=argWminL(W)(3)
对 L ( W ) L(W) L(W) 求导,并令导数为零
∂ L ( W ) ∂ W = 2 X T X W − 2 X T Y = 0 \frac{\partial L(W)}{\partial W}=2X^TXW-2X^TY=0 ∂W∂L(W)=2XTXW−2XTY=0
令导数为零,可得解析解
W = ( X T X ) − 1 X T Y (4) W=(X^TX)^{-1}X^TY\tag{4} W=(XTX)−1XTY(4)
其中, ( X T X ) − 1 X T (X^TX)^{-1}X^T (XTX)−1XT 称为 X X X 的伪逆。
伪逆的相关知识参考 REF [3]。
更准确地讲, ( X T X ) − 1 X T (X^TX)^{-1}X^T (XTX)−1XT 是 X X X 的左逆矩阵。
我认为,在不采用迭代法的前提下,如果 X X X 不存在左逆矩阵,应该可以计算 M-P 广义逆矩阵作为最优解。
2.2. 几何意义
根据式 ( 1 ) (1) (1) 很容易看出最小二乘估计的其中一种几何解释。最小二乘估计规定了具体度量误差的方式,每个样本投入模型的输出值与标签的差值平方和作为总误差,用于评估模型优劣和训练模型参数。
另外,还可以从向量空间的角度来理解其几何意义。
X n × p W p × 1 = Y ^ ( x 11 x 12 … x 1 p x 11 x 12 … x 2 p ⋮ ⋮ ⋮ x n 1 x n 2 … x n p ) ( w 1 w 2 ⋮ w p ) = ( y ^ 1 y ^ 2 ⋮ y ^ n ) w 1 ( x 11 x 21 ⋮ x n 1 ) + w 2 ( x 12 x 22 ⋮ x n 2 ) + ⋯ + w p ( x 1 p x 2 p ⋮ x n p ) = ( y ^ 1 y ^ 2 ⋮ y ^ n ) \begin{aligned} X_{n\times p}W_{p\times 1} &= \hat{Y} \\ \left(\begin{matrix} x_{11} & x_{12} & \dots & x_{1p} \\ x_{11} & x_{12} & \dots & x_{2p} \\ \vdots & \vdots & & \vdots \\ x_{n1} & x_{n2} & \dots & x_{np} \\ \end{matrix}\right) \left(\begin{matrix} w_1 \\ w_2 \\ \vdots \\ w_p \end{matrix}\right) &= \left(\begin{matrix} \hat y_1 \\ \hat y_2 \\ \vdots \\ \hat y_n \end{matrix}\right) \\ w_1\left(\begin{matrix} x_{11} \\ x_{21} \\ \vdots \\ x_{n1} \end{matrix}\right)+ w_2\left(\begin{matrix} x_{12} \\ x_{22} \\ \vdots \\ x_{n2} \end{matrix}\right)+\dots+ w_p\left(\begin{matrix} x_{1p} \\ x_{2p} \\ \vdots \\ x_{np} \end{matrix}\right) &=\left(\begin{matrix} \hat y_1 \\ \hat y_2 \\ \vdots \\ \hat y_n \end{matrix}\right) \end{aligned} Xn×pWp×1⎝ ⎛x11x11⋮xn1x12x12⋮xn2………x1px2p⋮xnp⎠ ⎞⎝ ⎛w1w2⋮wp⎠ ⎞w1⎝ ⎛x11x21⋮xn1⎠ ⎞+w2⎝ ⎛x12x22⋮xn2⎠ ⎞+⋯+wp⎝ ⎛x1px2p⋮xnp⎠ ⎞=Y^=⎝ ⎛y^1y^2⋮y^n⎠ ⎞=⎝ ⎛y^1y^2⋮y^n⎠ ⎞
其中, Y ^ = ( y ^ 1 y ^ 2 … y ^ n ) T \hat Y = \left(\begin{matrix} \hat y_1 & \hat y_2 & \dots & \hat y_n \end{matrix}\right)^T Y^=(y^1y^2…y^n)T 为样本投入模型的预测值,区别于标签 Y = ( y 1 y 2 … y n ) T Y=\left(\begin{matrix} y_1 & y_2 & \dots & y_n \end{matrix}\right)^T Y=(y1y2…yn)T 。
向量 α i = ( x 1 i x 2 i … x n i ) T , i = 1 , 2 , … , p \alpha_i=\left(\begin{matrix} x_{1i} & x_{2i} & \dots & x_{ni} \end{matrix}\right)^T,\space i=1,2,\dots,p αi=(x1ix2i…xni)T, i=1,2,…,p 在 n n n 维空间 U U U 中, p p p 个向量所张成的空间维度最大不超过 p p p,因为样本数 n n n 一般远大于样本向量的维度 p p p,所以 p p p 个向量所张成的空间为 n n n 维空间的子空间,该不超过 p p p 维的子空间记为 V V V。由解方程 X W = Y ^ XW=\hat Y XW=Y^ 的几何意义可知, Y ^ \hat Y Y^ 相当于向量 α i , i = 1 , 2 , … , p \alpha_i,\space i=1,2,\dots,p αi, i=1,2,…,p 的一种线性组合,组合系数为 W W W,这说明 Y ^ \hat Y Y^ 在 V V V 中。如果标签 Y Y Y 也在子空间 V V V 中,那么 Y Y Y 显然可以由 α i \alpha_i αi 线性组合得到,因此目标 W W W 应该能使得 X W = Y ^ = Y XW=\hat Y= Y XW=Y^=Y,此时最小二乘估计对应的目标函数值为 0 0 0 ,但是实际中这种情况不大可能出现;大多数情况下,标签 Y Y Y 不在 V V V 中,或者说不能由 α i \alpha_i αi 线性表示,那么最小二乘估计的几何意义为在子空间 V V V 中找到一个距离空间 U U U 中向量 Y Y Y 的最近向量 Y ^ \hat Y Y^。直观上来说, Y ^ \hat Y Y^ 为 Y Y Y 向子空间 V V V 的投影向量时,二者最为接近,了解一些降维算法的同学应该知道投影可以保留 Y Y Y 在子空间 V V V 的全部信息;也可以从计算方面简单证明,当 Y ^ \hat Y Y^ 为投影向量时,向量 Y − Y ^ Y-\hat Y Y−Y^ 与子空间 V V V 中的任意一个向量均垂直,故有 X T ( Y − Y ^ ) = X T ( Y − X W ) = O p × 1 X^T(Y-\hat Y)=X^T(Y-XW)=O_{p\times 1} XT(Y−Y^)=XT(Y−XW)=Op×1, O p × 1 O_{p\times 1} Op×1 为 p p p 为零向量,可以解得 W = ( X T X ) − 1 X T Y W=(X^TX)^{-1}X^TY W=(XTX)−1XTY,这与最小二乘估计的解析解式 ( 4 ) (4) (4) 不谋而合。可见,子空间 V V V 中的目标向量就是 Y Y Y 的投影向量。
对于上述关于子空间和投影不理解的同学,可以通过下面的例图来配合思考。
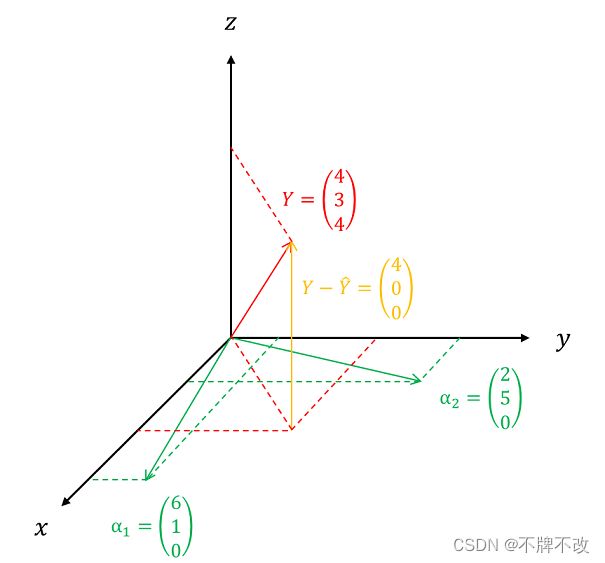
图 2 最小二乘估计几何意义例图
总而言之,定义最小二乘估计的目标函数考虑到了第一种几何意义,也是目标函数直接表达出来的含义;第二种几何意义是从解方程、向量空间的角度来理解,更加抽象,但是有助于我们从不同角度来体会最小二乘估计的优美。
2.3. 概率视角下的朴素最小二乘估计
下面从频率派学者的角度(MLE)来重新审视最小二乘估计(LSE)。
从上面的几何意义可以看出, Y Y Y 能够由 α i \alpha_i αi 线性表示的可能性不大,因为数据本身就具有随机性,带有一定的噪声。假设每个数据的噪声都服从正态分布 ϵ ∼ N ( 0 , σ 2 ) \epsilon\sim N(0,\sigma^2) ϵ∼N(0,σ2) ,标签 Y Y Y 可以表示为噪声形式 Y = Y ^ + ϵ = W T X + ϵ Y=\hat Y + \epsilon= W^TX+\epsilon Y=Y^+ϵ=WTX+ϵ。按照频率派学者的认知,这里的样本 X X X 是已知量,模型参数 W W W 是未知常数,噪声 ϵ \epsilon ϵ 是随机变量,标签 Y Y Y 是观测结果,因此 Y ∣ X , W ∼ N ( W T X , σ 2 ) Y\mid X,W\sim N(W^TX, \sigma^2) Y∣X,W∼N(WTX,σ2) ,对应的概率分布函数为
P ( Y ∣ X , W ) = 1 2 π σ e − ( Y − W T X ) 2 2 σ 2 (5) P(Y\mid X,W)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(Y-W^TX)^2}{2\sigma^2}}\tag{5} P(Y∣X,W)=2πσ1e−2σ2(Y−WTX)2(5)
注意,式 ( 2 ) (2) (2) 其实是 n n n 个正态分布连乘的简便记号,原型为
P ( Y ∣ X , W ) = ∏ i = 1 n P ( y i ∣ x i , W ) = ∏ i = 1 n 1 2 π σ e − ( y i − W T x i ) 2 2 σ 2 (6) P(Y\mid X,W)=\prod_{i=1}^n P(y_i\mid x_i,W)=\prod_{i=1}^n\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i-W^Tx_i)^2}{2\sigma^2}}\tag{6} P(Y∣X,W)=i=1∏nP(yi∣xi,W)=i=1∏n2πσ1e−2σ2(yi−WTxi)2(6)
利用频率派的极大似然估计(MLE)定义目标函数
L ( W ) = log P ( Y ∣ X , W ) = log ∏ i = 1 n P ( y i ∣ x i , W ) = ∑ i = 1 n log P ( y i ∣ x i , W ) = ∑ i = 1 n log ( 1 2 π σ e − ( y i − W T x i ) 2 2 σ 2 ) = ∑ i = 1 n log 1 2 π σ + ∑ i = 1 n log e − ( y i − W T x i ) 2 2 σ 2 = ∑ i = 1 n log 1 2 π σ − ∑ i = 1 n ( y i − W T x i ) 2 2 σ 2 (7) \begin{aligned} L(W)&=\log P(Y\mid X,W) \\\notag &=\log \prod_{i=1}^n P(y_i\mid x_i,W)\\\notag &=\sum_{i=1}^n\log P(y_i\mid x_i,W)\\\notag &=\sum_{i=1}^n\log \left(\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y_i-W^Tx_i)^2}{2\sigma^2}} \right) \\\notag &=\sum_{i=1}^n\log \frac{1}{\sqrt{2\pi}\sigma} +\sum_{i=1}^n\log e^{-\frac{(y_i-W^Tx_i)^2}{2\sigma^2}} \\\notag &=\sum_{i=1}^n\log \frac{1}{\sqrt{2\pi}\sigma}-\sum_{i=1}^n\frac{(y_i-W^Tx_i)^2}{2\sigma^2}\tag{7} \end{aligned} L(W)=logP(Y∣X,W)=logi=1∏nP(yi∣xi,W)=i=1∑nlogP(yi∣xi,W)=i=1∑nlog(2πσ1e−2σ2(yi−WTxi)2)=i=1∑nlog2πσ1+i=1∑nloge−2σ2(yi−WTxi)2=i=1∑nlog2πσ1−i=1∑n2σ2(yi−WTxi)2(7)
最大化目标函数 ( 7 ) (7) (7) 对应的 W W W 为目标模型参数,即
W ^ = a r g max W L ( W ) = a r g max W log P ( Y ∣ X , W ) = a r g max W ∑ i = 1 n log 1 2 π σ − ∑ i = 1 n ( y i − W T x i ) 2 2 σ 2 = a r g max W − ∑ i = 1 n ( y i − W T x i ) 2 2 σ 2 = a r g min W ∑ i = 1 n ( y i − W T x i ) 2 2 σ 2 = a r g min W ∑ i = 1 n ( y i − W T x i ) 2 \begin{aligned} \hat W&={\rm arg}\max_W L(W) \\\notag &={\rm arg}\max_W \log P(Y\mid X,W) \\\notag &={\rm arg}\max_W \sum_{i=1}^n\log \frac{1}{\sqrt{2\pi}\sigma}-\sum_{i=1}^n\frac{(y_i-W^Tx_i)^2}{2\sigma^2} \\\notag &={\rm arg}\max_W -\sum_{i=1}^n\frac{(y_i-W^Tx_i)^2}{2\sigma^2} \\\notag &={\rm arg}\min_W\sum_{i=1}^n\frac{(y_i-W^Tx_i)^2}{2\sigma^2} \\\notag &={\rm arg}\min_W\sum_{i=1}^n{(y_i-W^Tx_i)^2} \\\notag \end{aligned} W^=argWmaxL(W)=argWmaxlogP(Y∣X,W)=argWmaxi=1∑nlog2πσ1−i=1∑n2σ2(yi−WTxi)2=argWmax−i=1∑n2σ2(yi−WTxi)2=argWmini=1∑n2σ2(yi−WTxi)2=argWmini=1∑n(yi−WTxi)2
这与式 ( 1 ) (1) (1) 完全相同,可见,以频率派学者的角度理解 LSE 可以推导出与 LSE 一般定义下相同的目标函数。因此,我们可以认为朴素最小二乘估计与噪声为高斯分布的最大似然估计是等价的。