【CV】在各种硬件配置下都能如鱼得水的图像分类平台
前言
这是一个分离式图片分类平台,有多种模型,最终要用的模型只有一种。对于这种顾虑,本项目将训练任务与测试任务二分离法,使得工程开发更加轻松便捷。
代码在Bibbliiiing大大的基础上进行二次开发。

【CV】在各种硬件配置下都能如鱼得水的图像分类平台
前言
内置模型
1、CNN轻量级模型王者:MobilenetV2
2、CNN重量级模型王者:EfficientNetV2
3、“模型很重,效果很好”的Transformer模型王者:Swin Transformer
平台优势
开源代码
1、classification_trainPlatform
2、classification_testPlatform
训练自己的数据集
1、摆放数据集
2、运行pretreatment .py
3、train.py文件中设置参数(各参数在train.py中皆有详细介绍)编辑
4、运行tain.py
内置模型
内置了三种模型,他们分别在各自的领域扮演着中流砥柱的角色,博主对分类模型大致做了 一个总结与分类,选择这三个模型是深思熟虑的结果。
1、CNN轻量级模型王者:MobilenetV2
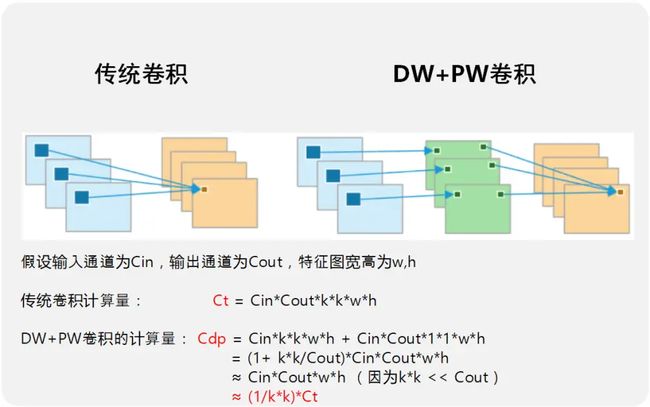
MobileNet v1 最大的成就在于提出了depthwise卷积(DW)+pointwise卷积(PW),将普通卷积的计算量近乎降低了一个数量级,成为第一个在轻量级领域取得成功的网络。如下图所示,对于一个常规的3*3卷积,使用dw+PW,计算量降低为原来的 1/(3*3)=1/9, 接近于降低了一个数量级。之后MboileNet v2横空出世,V2与V1之间的性能比较如下:

MobileNet v2借鉴了resnet的残差结构,引入了inverted resdual模块(倒置残差模块),进一步提升了MobileNet的性能。因为inverted resdual一方面有利于网络的学习,因为毕竟学的是残差(这也是resnet的精髓),另一方面,也降低了原来的PW卷积的计算量。在MobileNet v1的dw+pw卷积中,计算量主要集中在PW卷积上。使用了inverted resdual模块之后,原来的一个PW卷积,变成了一个升维PW+一个降维PW,其计算量有所下降,即便V2比V1版本先进了不少,但我们说MboileNetV2是轻量级的王者的证据似乎依旧不足,还需要与其他同样量级的模型进行比较:

图1:各个轻量级模型性能比较
从图中可以看出来 ,mobilenetv2的综合指标是最高的,在低配的环境时,强烈推荐使用。
2、CNN重量级模型王者:EfficientNetV2
======================================================
AlexNet 提出时间:2012/9 Top-1 准确率:62.5% 参数量:60M
======================================================
VGG-19 提出时间:2014/9 Top-1 准确率:74% 参数量:144M
======================================================
Inception V3 提出时间:2015/12 Top-1 准确率:78.8% 参数量:23.8M
======================================================
EfficientNetV1 提出时间:2019/5 Top-1 准确率:84.4% 参数量:66M
======================================================
EfficientNetV2 提出时间:2021 Top-1 准确率:87.3% 参数量:比EfficientNetV1小
======================================================从以上数据分析显而易得:EfficientNetV1恐怕是参数量较少且准确率非常高的王者模型了,然而EfficientNetV2 不仅准确率超过EfficientNetV1 3%,且速度快了5~10倍,所以重量级模型王者非EfficientNetV2莫属。
值得一提的是,本分类平台一共提供了三个EfficientNetV2模型,分别是EfficientNetV2-s,EfficientNetV2-m,EfficientNetV2-l。他们的训练参数量是逐级递增的,具体选择哪个模型训练还需参考实际环境。
3、“模型很重,效果很好”的Transformer模型王者:Swin Transformer
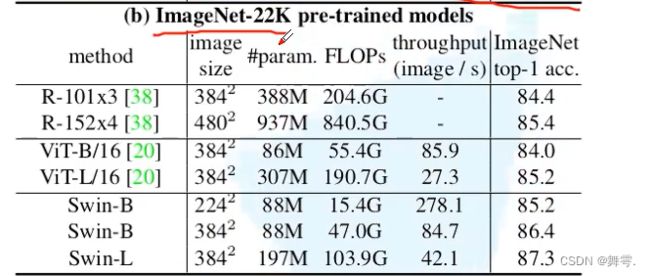
其实Transformer类的模型没有什么好比较的,我们的这个分类平台相对来讲还是比较简陋的,所以能够搭建的还是比较主流的模型ViT和 Swin Transformer,很明显Swin Transformer的性能是要好过ViT的,然而Swin Transformer的预训练模型太大了,很难下载实际上我测试过,其实这两个模型都不如EfficienetNetV2的效果好,所以这里平台中有关Transformer的模型只是草草使用了Vit。
平台优势
支持Windows/Linux
一个平台多种场景:可以采用切换模型的方式解决单模型不够全面的问题——不同的实验环境与不同的实验目标下模型变得不适用的困扰。
内置三种模型皆支持迁移学习,且warehouse/pretrained_weights文件夹下自带多个预训练模型,不必自己去网上冲浪下载。
支持冻结训练、 支持DP模式/DDP模式训练、支持单机多卡分布式训练、支持混合精度训练。
灵活训练自己的模型,可调节参数多达20+。
支持多种学习率下降方式:固定步长下降方式与余弦退火下降方式等。
支持多线程读取数据。
内置大量处理数据集的小工具:/tools文件夹下(期待探索哦!)
训练、预测分离想法:抱着“宁非需要,勿曾新知”的想法,为工程实现仅保留必要之物——预测任务中当且仅需得到训练出的模型
开源代码
暂时只支持百度网盘下载,其余的方式可能需要过段时间。
1、classification_trainPlatform
链接:https://pan.baidu.com/s/1YnDL76gWBUywq8FCwfmFcw
提取码:jdsp
2、classification_testPlatform
链接:https://pan.baidu.com/s/1M81QOxW9W1aD3F4xzx2jNw
提取码:qztm
训练自己的数据集
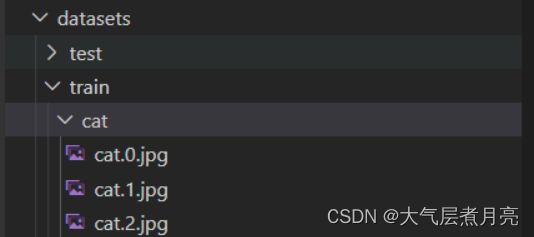
1、摆放数据集
datasets文件夹下存放的是训练图片,分为两部分,train里面是训练图片,test里面是测试图片

在训练之前需要首先准备好数据集,数据集格式为在train和test文件夹下分不同的文件夹,每个文件夹的名称为对应的类别名称,文件夹下面的图片为这个类的图片。

2、运行pretreatment .py
(1)自动读取datasets/train和datasets/test文件下所有目录,比如:cat/dog,自动将cat、dog写入.txt文件,作为分类类别。
(2)自动读取每个类别目录下所有图片,写入另外的.txt文件,记录着训练和测试所需图片的位置,方便训练的时候自动读取。
3、train.py文件中设置参数(各参数在train.py中皆有详细介绍)
4、运行tain.py
完毕!
希望对大家学习深度学习中的图像处理有所帮助,并且能够得到大家的三连支持!