CLRNet Cross Layer Refinement Network for Lane Detection
CLRNet: Cross Layer Refinement Network for Lane Detection
question
-
Q1论文试图解决什么问题?
- lane detection
-
Q2这是否是一个新的问题?
- 否
-
Q3这篇文章要验证一个什么科学假设?
- 利用不同的特征水平对精确的车道检测具有重要的意义,通过进一步借助车道线的高级和低级特征,车道线检测能达到更好的效果
-
Q4有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
- Line-CNN、CondLaneNet、Structure Guided Lane Detection等
- 属于目标检测类
-
Q5论文中提到的解决方案之关键是什么?
- ROIGather结合上下文,lane IoU loss更好的收敛,stage Refinement低级高级语义结合更加平滑
-
Q6论文中的实验是如何设计的?
-
Q7用于定量评估的数据集是什么?代码有没有开源?
- CULane、 Tusimple、 LLAMAS
- 开源
-
Q8论文中的实验及结果有没有很好地支持需要验证的科学假设?
- 有
-
Q9这篇论文到底有什么贡献?
- 提出了ROIGather借助attention结合上下文
- 提出lane IoU loss 更好的损失函数
-
Q10下一步呢?有什么工作可以继续深入
abstract
难点1:lane有高级语义,而它拥有特定的局部模式,需要详细的底层特征才能精确定位 不同层特征层运用对应的语义
难点2:车道被遮挡没有存在的视觉证据,极端光照条件下,车道难以识别
- 低级特征、高级特征互补
- ROIGather 手机全局背景来增强车道特征的表示
- 定制IoU损失,将车道作为一个整体进行回归。
related
基于语义分割
-
Spatial as deep: Spatial CNN for traffic scene understanding(2018)
- 提出消息传递,体现了车道线的空间关系
- 实时性较差
-
RESA: Recurrent Feature-Shift Aggregator for Lane Detection(2020.8)
- 提出了特征聚合模块对全局特征聚合
-
Curvelane-NAS(2020.7)
- 基于NAS来寻找更好的网络极其昂贵和耗费时间,是无意义的
以上总结:基于分割的方法来做车道线检测是无效和耗时的,因为他们是对整个图像做像素级的预测,没有将车道作为一个整体来考虑,丧失了他独有的性质,并且车道对低级和高级语义要同时要求才能做到
基于锚点方法
- Line-CNN: End-to-End Traffic Line Detection With Line Proposal Unit(2020.1)
- 基于线锚的开创性工作
- Keep your Eyes on the Lane: Real-time Attention-guided Lane Detection(2020.10)
- 提出了新型的基于锚的注意力机制,可以聚合全局信息
- Structure Guided Lane Detection.(2021.8)
- 引入一种点消失引导锚生成器,增加多层结构一稿性能
- Ultra Fast Structure-aware Deep Lane Detection(2020.8)
- 构建具有全局特征的全连通层来预测车道
- 基于行锚的车道检测方法,并采用轻量级骨干实现了较高的推理速度
- 速度快、性能不好
- CondLaneNet: a Top-to-down Lane Detection Framework Based on Conditional Convolution(2021.5)
- 引入了一种基于条件卷积和行锚定公式的条件车道检测策略,即先定位车道线的起始点,再进行行锚定车道检测
- 在一些复杂的场景中,起点很难识别,这导致性能相对较差
基于参数方法
基于参数对车道曲线进行建模,并且对这些参数回归来检测车道
- PolyLaneNet: Lane Estimation via Deep Polynomial Regression(2020.4)
- 用多项式回归问题,实现了高效率
- End-to-end Lane Shape Prediction with Transformers(2020.11)
- 考虑摄像机姿态下的道路结构对车道形状进行建模,然后在车道检测任务中引入transform获得全局特征
基于参数的方法需要回归的参数较少,但对预测的参数比较敏感,例如高阶系数的误差预测可能会引起车道形状的变化非常大。尽管基于参数的方法具有快速的推理速度,但它们仍然难以获得更高的性能。
CLRNet
本文提出了能结合全局和局部特征的框架,具体来说,我们首先在高语义特征中进行检测,以粗定位车道。然后,我们进行基于精细细节特征的细化,以获得更精确的位置。
method
网络架构

使用一个FPN网络去提取图像特征,之后在每个特征stage上去优化车道线的回归结果,而当前stage的回归结果会被下一阶段的细致优化所采用,从而实现车道线的级联优化。从stage0开始逐渐细化得到的收益是最大的

anchor box变种——lane prior
这里车道线的建模是采用的点集的形式P = {(x1,y1),…,(xN,yN) },可以描述位在y轴上的均匀采样:yi=H/(N-1)*i(这里N=72)H为图像高度,回归量有四部分组成
- 二分类—是否为车道线类别信息
- 回归—车道线长度
- 回归—车道线起始点坐标(x,y)和车道线prior与x轴的夹角
- 回归—划分点N的位置回归
车道线和x轴的夹角从一开始就可以通过数据分析确定得到lane prior
motivation
在神经网络中,深度高级特征对整个对象具有更强的语义响应,而浅层低级特征则具有更多的局部上下文信息。允许车道对象访问高级特征可以帮助开发更有用的上下文信息,精细细节特征有助于检测车道,具有较高的定位精度,受Cascade RCNN的启发,我们可以将车道对象分配到所有语义级别
ROIGather
roigather来收集全局上下文,增强车道表示,同时我们引入了line iou loss,使得车道线回归为一个整体,提高定位精度怎么做到整体,之间的强关联是什么
motivation:经过ROIAlign后获得的上下文信息还是不足的,极端光照情况下,没有视觉信息能确定车道线,需要附近的信息。
利用高层次的信息对车道进行定位,对于低层次的车道来说高层次的信息就是先验,由于车道线有不完整的情况,我们用卷积增强信息。
在lane proir 上均匀采样得到采样点Np与对应的stage计算attention权重(获取上下文信息)

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YpCyfKzB-1657165300795)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220613092626230.png)]
g作为利用attention来修正原始采样点的形式出现,与GT相比匹配程度高的权重大,匹配程度低的权重小,根据迭代使得lane prior修正
Line IoU loss
motivation
原来用L1LOSS的前提假设过于简单,并且点之间是离散的,难以得到良好的结果


dio的值可以是负值,在优化上是行得通的
那么LIoU可以被认为是无限个线点的组合。为了简化表达式并使其易于计算,我们将其转换为离散形式
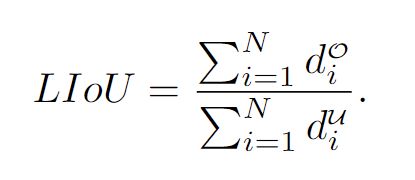
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y5beQVDI-1657165300796)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220613100338637.png)]
LIoU范围是(-1,1)完全重合时收敛于1
优点:简单可微、容易并行、预测车道作为一个整体
Positive samples selection
根据YOLOX的启发,每个GT会被动态的分配多个predicted lanes作为正样本,然后对分配成本进行排序

Csim是预测车道和GT之间的差距,Cdis是有效车道点的平均像素距离,CXY代表起始点的距离,Ctheta代表角度之间的差值
Ccls是预测和标签之间分类信息的差
训练损失包括分类损失和回归损失。回归损失只在分配的样本上进行。总损失函数定义为:

有焦点损失,lane 起始点、角度、长度之间的损失,还有线之间交并比损失,同时,和其他几篇工作一样,可以在训练的时候增加一个额外的二值分割loss,这个是可选的。
由于是基于anchor的方法那么会产生多个锚框,需要用nms来去除
Experiment
在大规模车道检测数据集CULane上取得SOTA

可视化检测效果
消融实验

lane IoU loss改进效果

Refinement改进效果
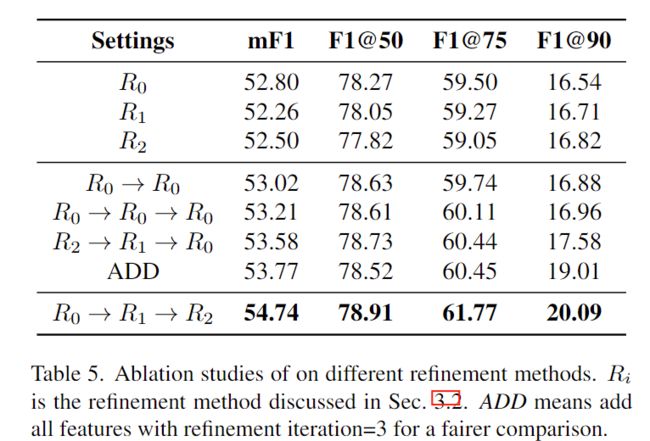
由高阶信息->低阶信息逐步精细化迭代的效果最好,可以更好的利用高级和低级特性
根据attention的可视化,ROIGather能收集具有丰富语义信息的全局上下文,即使在遮挡情况下也能捕获前景车道的特征

conclusion
本文提出了一种用于车道检测的交叉层改进网络(CLRNet)。CLRNet可以利用高级特征来预测车道,同时利用局部细节特征来提高定位精度。为了解决没有视觉证据证明车道存在的问题,我们提出了ROIGather,通过建立与所有像素的关系来增强车道特征的表示。为了将车道作为一个整体回归,我们提出了为车道检测量身定制的lane IoU loss,与标准损耗smooth L1相比,这大大提高了性能。在CULane、LLamas和Tusimple三个车道检测基准数据集上对方法进行了评估。实验表明,提出的方法优于目前最先进的车道检测方法
t)。CLRNet可以利用高级特征来预测车道,同时利用局部细节特征来提高定位精度。为了解决没有视觉证据证明车道存在的问题,我们提出了ROIGather,通过建立与所有像素的关系来增强车道特征的表示。为了将车道作为一个整体回归,我们提出了为车道检测量身定制的lane IoU loss,与标准损耗smooth L1相比,这大大提高了性能。在CULane、LLamas和Tusimple三个车道检测基准数据集上对方法进行了评估。实验表明,提出的方法优于目前最先进的车道检测方法