朴素贝叶斯和情感分类
目录
朴素贝叶斯和情感分类
1 朴素贝叶斯分类器
2 训练朴素贝叶斯分类器
3 例子
4 情感分析优化
5 朴素贝叶斯作为一种语言模型
6 评估指标:精确度,召回率,F-measure
7 测试集和交叉验证
8 特征选择
9 小结
朴素贝叶斯和情感分类
我们将介绍朴素贝叶斯算法,并将其应用于文本分类,即为整个文本或文档分配标签或类别。我们关注一个常见的文本分类任务,情感分析,情感的提取,作者对某个对象表达的积极或消极的倾向。
情绪分析最简单的版本是一个二元分类任务,评论的文字提供了很好的线索。例如,请考虑以下从对电影和餐馆的正面和负面评价中提取的短语。像“伟大”、“丰富多彩”、“令人敬畏”、“可悲”、“糟糕透顶”和“荒谬可笑”这样的词汇都能提供丰富的信息。
垃圾邮件检测是另一个重要的商业应用程序,它是将电子邮件分配给垃圾邮件或非垃圾邮件两类之一的二进制分类任务。可以使用许多词汇和其他特性来执行这种分类。例如,你可能很有理由怀疑一封包含“在线制药”、“免费”或“亲爱的赢家”等短语的电子邮件。
我们的目标是学习一个能够将新文档d映射到其正确的类c∈C的分类器
1 朴素贝叶斯分类器
我们将介绍多项式朴素贝叶斯分类器,之所以这么称呼它,是因为它是一个贝叶斯分类器,它对特征如何交互进行了简化(朴素)假设。
分类器的直观效果如下图所示。我们将文本文档表示为bag-of-words,即一组无序的单词,忽略它们的位置,只保留它们在文档中的频率,而不是代表词序的短语如“I love this movie”和“I would recommend it”,我们只是注意这个词“I”在整个文档发生5次,“ it“出现6次

- 朴素贝叶斯概率分类器,这意味着一个文档d,所有类c∈C分类器返回的类
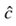 的最大后验概率的文档。我们使用“ˆ”表示估计正确的分类:
的最大后验概率的文档。我们使用“ˆ”表示估计正确的分类:
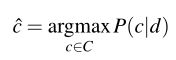
- 条件概率:

- 结合上述两个公式,有:

- 由于P(d)并不是每一类都改变,我们总是预测同一个文档d最可能的类,它必须有相同的概率P(d)。因此,我们简化上面的公式:
![]()
- 因此,我们通过选择两个概率乘积最高的类来计算给定某个文档d的最可能的类
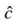 。
。

其中P(c)为先验概率;P(d|c)为文档d的可能性
- 在不失泛化的情况下,我们可以将文档d表示为一组特征f1、f2、…, f n:
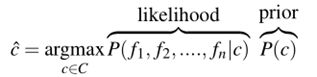
- 上述计算仍然很复杂,因此朴素贝叶斯算法做了两个简单的假设:
第一个是上面直观讨论过的单词包假设:我们假设位置无关紧要,并且单词“love”无论出现在文档中的第1个、第20个还是最后一个单词中,对分类都有相同的影响。因此,我们假设特征f1, f2,…, fn只编码单词标识,而不编码位置。
第二个通常被称为朴素贝叶斯假设:这是一个条件独立的假设,即给定c类的概率P(f i |c)是独立的,因此可以“简单的”相乘如下:
![]()
由朴素贝叶斯分类器选择的类的最终方程为:
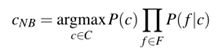
- 要将朴素贝叶斯分类器应用到文本中,我们需要考虑单词的位置,只需遍历文档中的每个单词位置就可以了:
positions←测试文档中的所有单词位置

- 与语言建模计算一样,朴素贝叶斯计算也是在日志空间中进行的,以避免底流并提高速度。因此,通常将上式表示为:

通过考虑log空间中的特征,上式将预测类计算为输入特征的线性函数。使用输入的线性组合来做出分类决策的分类器(如朴素贝叶斯和逻辑回归)称为线性分类器。
2 训练朴素贝叶斯分类器
让我们首先考虑最大似然估计。我们将简单地使用数据中的频率。
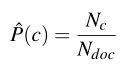
其中,
![]() :为我们训练数据中类别为C的文档数量
:为我们训练数据中类别为C的文档数量
![]() :为文档总数
:为文档总数

注意:如果某单词未在任何文档中出现,这个特征的概率为零。由于朴素贝叶斯简单地将所有的特征概率相乘,所以任何类的可能性项中的零概率都会导致类的概率为零。最简单的解决方案是add-one(拉普拉斯)平滑。虽然拉普拉斯平滑在语言建模中通常被更复杂的平滑算法所替代,但在朴素贝叶斯文本分类中通常使用拉普拉斯平滑算法:
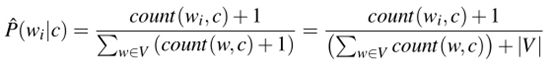
如何有些单词在测试集中出现,但在训练集中未出现,如何处理:对于这些未知单词的解决方案是忽略它们——将它们从测试文档中删除,并且完全不包含它们的任何可能性。
一些系统选择完全忽略另一类词:停止的话,非常频繁的单词和 a。这可以通过分类词汇训练集的频率,将前10 - 100词汇条目定义为停止,或者通过使用网上许多预定义的停止词列表。
3 例子

- 计算p(c)
![]()
- with这个词在训练集中没有出现,所以我们完全删除了它。

- S =“predictable with no fun”,在删除所选类中的单词“with”后
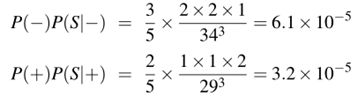
因此,该模型预测了测试语句属于“negative”类。
4 情感分析优化
(1)二元多项式朴素贝叶斯或二元NB

注意,计算结果不必为1;即使是二进制NB, great也有2个计数,因为它出现在多个文档中。
(2)处理否定:
I really like this movie (positive)
I didn’t like this movie (negative)
否定可以修饰一个否定词来产生一个积极的评论
处理方法:在文本规范化过程中,在逻辑否定符号(n NOT、NOT、no、never)之后的每个单词前加上NOT前缀,直到下一个标点符号出现。
didnt like this movie , but I à didnt NOT_like NOT_this NOT_movie , but I
5 朴素贝叶斯作为一种语言模型
由于朴素贝叶斯模型的似然特征为每个单词P赋一个P(word|c),该模型也为每个句子赋一个概率:


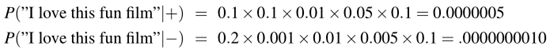
![]()
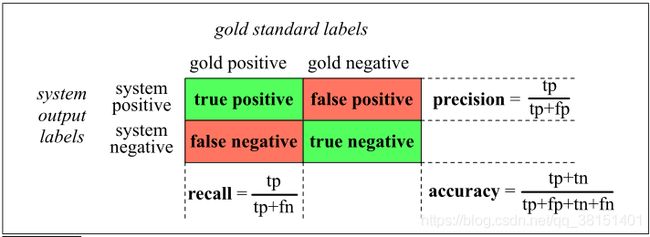
6 评估指标:精确度,召回率,F-measure
(1)评价指标
gold labels:我们试图匹配的每个文档的人为定义的标签。我们将把这些人类的标签称为黄金标签。


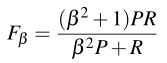
β的值> 1倾向于召回率,,而β< 1的倾向于精度。当β= 1,精度和召回也同样平衡;这是最常用的度量,被称为 ![]() 或F 1:
或F 1:

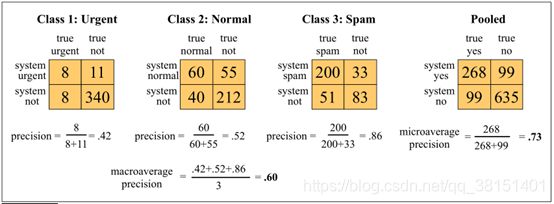
(2)多分类任务
我们可以通过为每个类c构建单独的二进制分类器来解决任意的分类问题,并对标记为c的正例和未标记为c的反例进行训练。给定一个测试文档或项目d,然后每个分类器独立做出决策,我们可以为d分配多个标签。

7 测试集和交叉验证
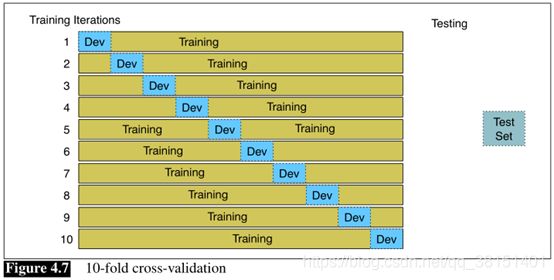
我们随机选择一个训练集和测试集的交叉验证数据,训练分类器,然后计算测试集上的错误率。然后重复与随机选择的一个不同的训练集和测试集。我们这样做抽样过程10次,然后平均这些10次运行平均错误率。这称为10倍交叉验证。
8 特征选择
特征选择的基础是为每个特征分配一定的优度指标,对特征进行排序,并保留最好的特征。要保留的特性数量是一个可以在开发集上优化的元参数。
特征通常根据它们对分类决策的信息量进行排序。一个非常常见的度量标准是信息增益。信息增益告诉我们单词的存在给我们多少位信息来猜测类。
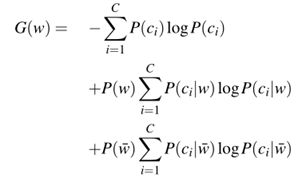
其中,
![]() :第i类
:第i类
![]() :表示一个文档不包含单词w
:表示一个文档不包含单词w
9 小结
•许多语言处理任务可以看作是分类任务。根据观察结果,学习建立分类模型。
•文本分类,即从一个有限的集合中为整个文本分配一个类,包括情感分析、垃圾邮件检测、语言识别和作者署名等任务。
•情感分析将文本分类为反映作者对某个对象表达的积极或消极的倾向(情感)。
•朴素贝叶斯(Naive Bayes)是一个生成模型,它使单词包假设(位置无关紧要)和条件独立假设(给定类,单词是条件独立的)成为生成模型
•带有二进制特征的朴素贝叶斯似乎更适合于许多文本分类任务。
•特性选择可用于自动删除没有帮助的特性。
•分类器基于精确度和召回率进行评估。
•分类器使用不同的培训、开发和测试集进行培训,包括在培训集中使用交叉验证。