用朴素贝叶斯和SVM进行文本分类
写在前面的感悟:
测试集文件删除一定要shift+delete!!!!!要不然回收站直接爆炸,用几个小时打开,然后再用几个小时清空。文本分类的数据集看似只有几个G那么大,但是架不住文件数量多,导致各种移动复制删除操作及其缓慢(可能也因为我用的是轻薄本性能低下)
不知道为什么C盘一直在不断生成新东西,导致我每天都在几百MB几百MB地删东西,只想做完项目尽早让笔记本解脱。分析了一下,程序关闭之后按理来说操作系统就会把资源释放掉啊,可能是生成的临时文件太多了吧,还是没有成功地发现根源。
强烈建议使用云电脑!!!,省去很多麻烦,我做完这个项目之后直接重装系统。
吐槽:为什么搜狗文本分类数据集,大规模的只能快递硬盘过去拷贝,让我想起来之前看的科普文章,比起看似先进的网络传输,有时候用大卡车直接运送硬盘有着更高的传输速率。
代码放在Github上了
代码放在Github上了: 朴素贝叶斯与SVM文本分类
机器学习-文本分类
这里写目录标题
- 机器学习-文本分类
-
- 一、问题分析
- 二、实验素材准备
-
- 1.现有文本分类语料库
- 2.搜狗新闻分类处理 SougouDataExtract.py
-
- (1)处理操作:
- (2)处理结果:
- 3.THUCdata
- 三、总体思路
-
- 1.文本处理
- 2.训练测试
- 四、具体设计
-
- 预处理:
-
- (1)分词 split.py
- (2)聚集 aggregate.py
- (3)去停用词 stop_removal.py
- (4)统计词频 word_count.py
- 2.特征降维 word_count.py
-
- (1)TF-IDF
- (2)CHI2
- 3.朴素贝叶斯文本分类器的构造 NB.py
-
- (1)原理
- (2)训练过程
- (3)求解过程
- (4)性能评估
- (5)算法改进
- 4.SVM分类器的构造 SVM.py
-
- (1)原理
- (2)构造过程
- (3)求解过程
- (4)性能评估
- (5)参数选择试验
- 五、遇到的问题及解决
-
- 1.文件输出问题
- 2.url读取问题
- 3.读取问题
- 六、运行测试
-
- 1.朴素贝叶斯
- 2.SVM
-
- 1.改变C的值
- 2.改变kernel
- 3.改变gamma值
一、问题分析
实验任务为通过机器学习实现对中文文本的分类,实现理论为朴素贝叶斯以及SVM。
具体实现分为以下几个部分:
1.通过现有资源获取进行数据收集(已有语料库以及xml文件解析构造)
2.对训练集数据进行预处理;
3.对语料库的文档进行建模;
4.基于朴素贝叶斯和SVM进行文本分类的有监督训练;
5.利用通过机器学习得到文本分类器,对测试文本进行分类判别;
7.对于所设计的文本分类器进行性能的评估。
二、实验素材准备
1.现有文本分类语料库
复旦大学语料库,但总数只有约9000篇,不能满足实验要求,作为训练集测试集测试后正确率不理想。
2.搜狗新闻分类处理 SougouDataExtract.py
搜狗实验室网站提供了大量新闻网页xml格式数据,但其不具有分类和文本型,故本实验对其进行处理使之成为文本分类语料库,以备进行后续操作。
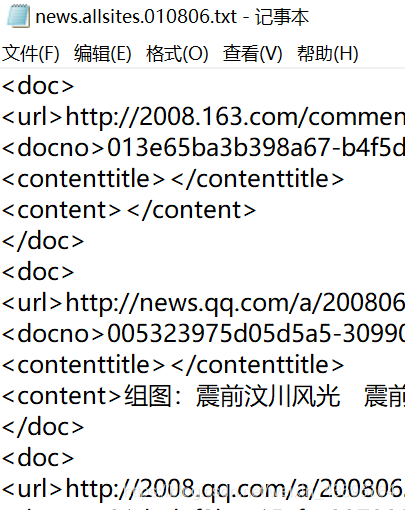
(1)处理操作:
在XML文档中头尾加入以进行解析操作,将会妨碍解析的字符修改(在五、遇到的问题及解决中涉及),基于python的url.parse模块根据xml文件中的url段网址的前缀进行对应content段文本类别的确认,构造文本分类结果。
(2)处理结果:
最终生成文件夹:
结果文件夹:


3.THUCdata

文本分类数量庞大,足以支撑实验文本数量要求。
三、总体思路
1.文本处理
首先对文本进行预处理,分词、去除无用信息、规范格式等等,使其具有特定的形式以便进行数据的提取,这也是文本建模的过程;
接着进行所需数据的提取,主要是对于每个分类中高频词的获取,词语以及频率作为文本分类器的分类依据,也就是特征的选取,对应机器学习的训练过程,这一过程在本实验中采用多项式模型;
在获得众多特征后,利用CHI2卡方降维提取特定数量的特征作为训练特征,有效增强训练的针对性。
2.训练测试
根据已经处理好的数据进行待分类文本的分类应用。
利用朴素贝叶斯、拉普拉斯平滑等等技术同时进行分类器测试与性能评估,这一过程在本实验中采用伯努利模型,因此本实验基于朴素贝叶斯的机器学习文本分类是通过混合模型(多项式训练,伯努利测试)来实现的。
使用python库svm.svc进行svm训练,并在训练测试过程中改变svc参数进行不同参数下实验结果的对比。
召回率、准确率性能的测试借助于混淆矩阵计算。
四、具体设计
预处理:
最终生成文件夹:
对于分类文本,我们需要进行以下四个处理:
(1)分词 split.py
分词操作处理文本中的词语,将其按照词性(名词、动词等)一一提取出来并用特定的分隔符进行区分,本程序使用python结巴分词库进行分词,将文本以词语为最小单位进行分隔、标识。
如图:

(2)聚集 aggregate.py
如上分词结果,文本变得很分散,且文本中的介词、动词等等对于文本分类的帮助非常有限,因此要进行名词的聚集,具体操作为将分词结果中的名词以空格分隔聚集起来。
如图:
![]()
(3)去停用词 stop_removal.py
某些人称代词(他、她)也是对于文本分类没有什么实质性帮助的,因此要进行去除,此处利用老师提供的停用词表进行进一步的文本信息优化。
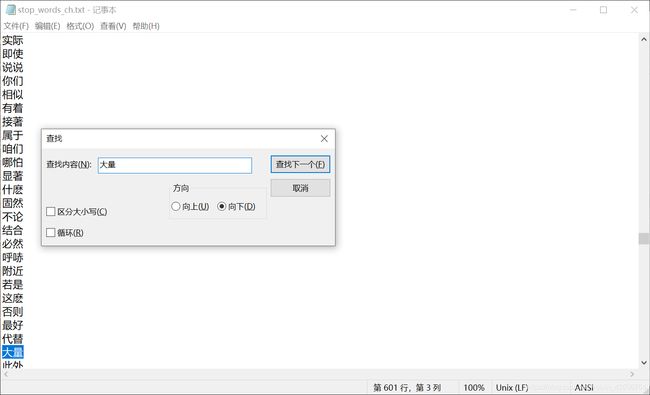
去停用词正确性及有效性:
在上述预处理过程中我们进行了名词的选取,但在诸如“大量”这样的词语也被判断为名词,而这样的词语对于文本分类特征没有帮助,因此要进行去除。
![]()
因此在停用词表中的停用词正确且有效。
下面是一个例子:
下图是利用dos的FC命令进行去停用词前后的文本比较,观察到两个文本的差异中第二行“大量”一词被去除。
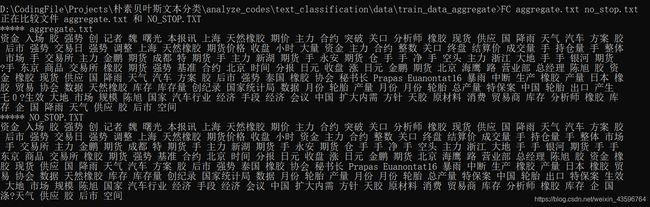
“大量”一词存在于停用词表中。
(4)统计词频 word_count.py
此操作在于将文本中出现频次高的词语进行筛选,这些词语的高频性使得其在文本分类的特征剥离上贡献较大,因此作为文本分类器的重要依据信息来源。
同时进行特征的降维,便于将有代表性的特征提取出来,增强特征集合对于文本分类的贡献,降低训练开销。
如图:

2.特征降维 word_count.py
(1)TF-IDF
实验过程中尝试利用TF-IDF进行词频计算中重要性衡量的优化:


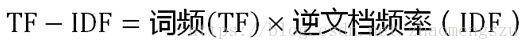
https://blog.csdn.net/zhaomengszu/article/details/81452907
如图:
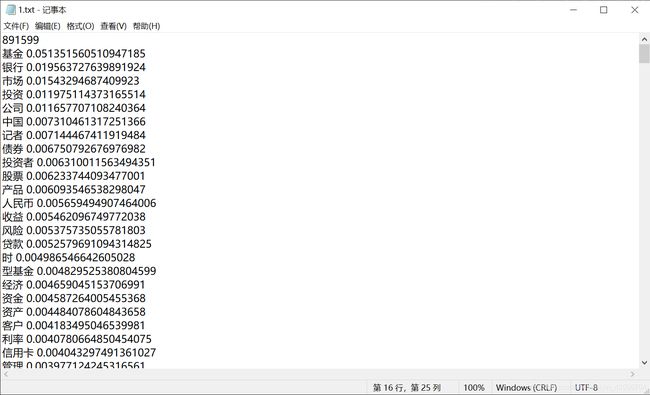
按照TF-IDF计算出的重要性进行词语排序选取前400个词语作为特征,效果并无改变,性能不会有可观改变,故不采用TF-IDF方法。
(2)CHI2
CHI2的差衡量共公式: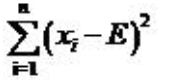
以此为基础进行特征的选取。
将其展开为此形式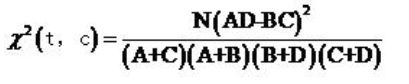
其中:
t:特征 c:类别 N:文档总数
A:属于c类包含特征t的文档数
B:不属于c类但包含特征t的文档数
C:属于c类但不包含特征t的文档数
D:不属于c类也不包含特征t的文档数
在实际使用中效果较好,因此本实验选用CHI2卡方降维。
3.朴素贝叶斯文本分类器的构造 NB.py
(1)原理
朴素贝叶斯分类器基于如下公式进行文本分类:
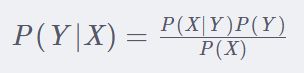
其中左右侧的P(Y∣X)与P(X∣Y)为我们提供了从易求解条件概率到不易求解条件概率的转换途径,在这个问题中,我们易求解某个文本分类下某些特征出现的概率,但很难求解或直观构思具有某些特征的文本属于某一文本分类的概率。
因此我们利用朴素贝叶斯进行文本分类的重点在于计算某一文本分类下某些特征出现的概率,以此为基础进行未知分类文本的推理分析。
(2)训练过程
对于朴素贝叶斯分类器,公式中需要以下四个概率值:P(“属于某类”∣“具有某特征”)、P(“具有某特征”∣“属于某类”)、P(“属于某类”)、P(“具有某特征”)。第一个对应我们的求解过程,第三、四个隐含在第二个的构造中。
训练过程在于求解P(“具有某特征”∣“属于某类”),这个工作是通过进行文本数据的分析而来,具体为计算文本中某些特征(如频数最大的一部分特征)的出现频率,所需数据在数据预处理阶段已经完成,训练阶段对这个预处理结果的操作是将其对应在朴素贝叶斯公式的元素之中,这些元素的值就是训练的目标结果,在求解阶段备用。
(3)求解过程
朴素贝叶斯:
朴素贝叶斯分类依赖于条件独立假设,这一假设使得朴素贝叶斯的概率求解非常简便:

我们可以观察到上述公式中分母相同,因此只需要比较分子的大小
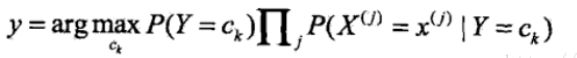
这样我们就可以通过比较各乘积的大小关系进行所属文本的确定。
在本实验训练集中,各分类文件数量一致,因此P(Y=ck)项相同,因此我们直接使用似然函数,也就是所有选定特征概率的乘积,来进行文本分类概率的比较。
平滑处理:
在乘积中,测试文本中某些词语(现实情况下可能是很大一部分,因为训练集不可能覆盖某一领域所有词语)可能不会出现在训练集所给出的词语(特征)列表中,那么P(“具有某特征”∣“属于某类”)的值就会为0,所导致的最终结果是乘积为0,这会使得分类器失去作用,没有意义。
本实验采用拉普拉斯平滑来进行解决,具体公式如下:
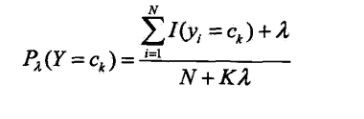
这里K为文本分类类数,λ为1。
(4)性能评估
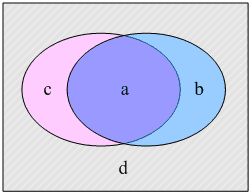
https://blog.csdn.net/xsdjj/article/details/83793310
- a表示正确地标注测试集文本为类别ci 的文本数量;
- b表示错误地标注测试集文本为类别ci 的文本数量;
- c表示错误地排除测试集文本在类别ci 之外的文本数量;
- d表示正确地排除测试集文本在类别ci 之外的文本数量。
![]()
![]()
在本次朴素贝叶斯分类器中直接使用上述公式进行召回率、准确率的计算。在svm分类器中将借由混淆矩阵进行召回率、准确率的计算。
![]()
![]()
(5)算法改进
1.优化计算
我们通过从对应每个分类的朴素贝叶斯概率中选取最大值来确定分类的结果,这其中是一个比较的过程,计算得到的概率值只用于比较,具体的值我们并不会用到,因此只需保留值的大小关系而不用过于追求其精确值的数学含义。
公式中概率的计算是通过乘法来实现的,在特征选取数目较大的情况下耗时会非常大,那么我们通过使用取log来讲运算变为加法,大大减少时间开销。
2.处理重复词语
对于文章中重复出现词语的情况,有三种模型进行训练与求解:
1.在多项式模型中,重复的词语我们视为其出现多次
2.在伯努利模型中,我们将重复的词语视为一次
3.在混合模型中,我们汲取上述两种模型的优点,减小其负面影响,采取多项式训练和伯努利求解的混合模式。
在本实验的算法实现中,我们选取混合模型。
4.SVM分类器的构造 SVM.py
(1)原理
简单来说,SVM
是一种二类分类模型。它的基本模型是在特征空间中寻找间隔最大化的分离超平面的线性分类器,具体图示如下。
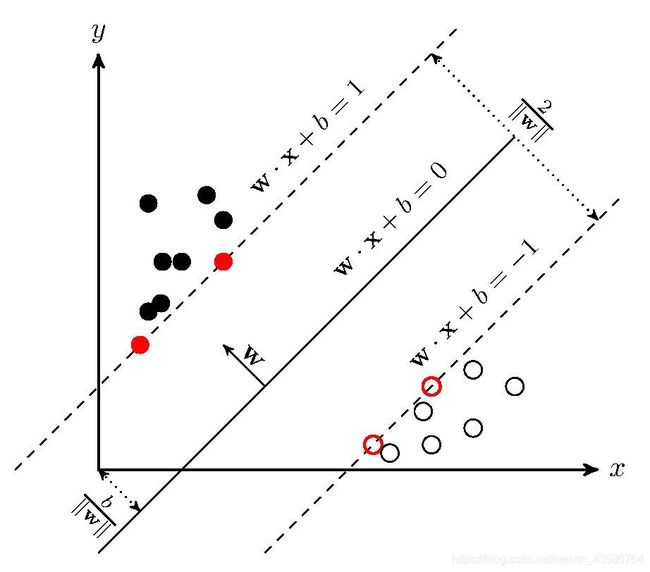
在进行划分的过程中,可以使用非线性的方法来完美划分,让空间从原来的线性空间变成一个更高维的空间,在这个高维的线性空间下,在用一个超平面进行分割,这就是核函数的作用,本试验构造的svm分类器使用的是高斯函数。
(2)构造过程
首先,在上述数据预处理后,我们得到了降维的特征集合,将其转化为特征向量,包含所有特征,同时为每个特征向量分量记录其对应分类,也就是额外构造一个标签向量指示其分类值,提供给svm进行训练划分。
在这之后利用python库svm.svc进行训练,训练输入为特征向量以及特征标签向量,训练过程可以选取不同的核函数模型以及惩罚因子等参数进行效果对比。
(3)求解过程
最终,根据上述训练得到svm分类器,求解过程中中输入测试文本特征向量以及我们预先设置好的测试文本特征标签向量(有监督求解,测试),进行测试文本的分类试验,记录成功率。
在本实验中,svm训练调用
sklearn库中对SVM的算法实现包sklearn.svm。测试使用sklearn库中的svm.svc.fit实现。
(4)性能评估
本次SVM分类器召回率以及准确率计算依靠混淆矩阵完成,具体原理在贝叶斯分类器中已经介绍。
![]()
(5)参数选择试验
详见六、运行测试
五、遇到的问题及解决
1.文件输出问题
使用空格,发现无法对齐,这是由于在python设定宽度的输出中,中文一个字符的宽度和英文一个空格的宽度不同,因此同样字符数量的宽度,在文件中显示并不一致,这个可以通过一定的识别中文字符并调整填充空格数量的方法实现,但这里使用tab键(\t)的方法,简单完整地实现中文字符的对齐问题。
2.url读取问题
读取搜狗全网新闻数据时,在url出现有+,空格,/,?,%,#,&,=等特殊符号的时候,可能无法进行正常的解析工作。本实验进行语料库数据收集中,在进行xml格式txt文件中url解析时,会出现无法解析的‘&’,鉴于被实验中url网页信息除开头分类板块信息外的后续内容无用,因此本实验通过将&字符替换为a字符来进行解决(符合xml文件url数据正确性的解法为使用&转移字符进行修正,但会出现些许问题,故不再花费时间进行解决)。
3.读取问题
读取搜狗全网新闻原始文件时,用gkb以及utf-8编码方式读入数据均会出现无法解析字符的情况,这是由于搜狗新闻数据的格式为ANSI,本实验通过进行批量修改文档格式为utf-8的方法进行解决,具体批量修改方式见
https://blog.csdn.net/hungryfoolisher/article/details/80019437

六、运行测试
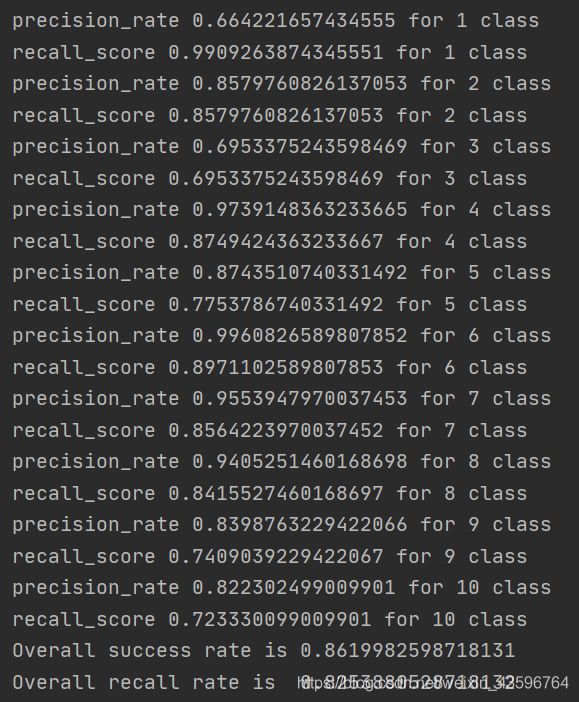
1.朴素贝叶斯
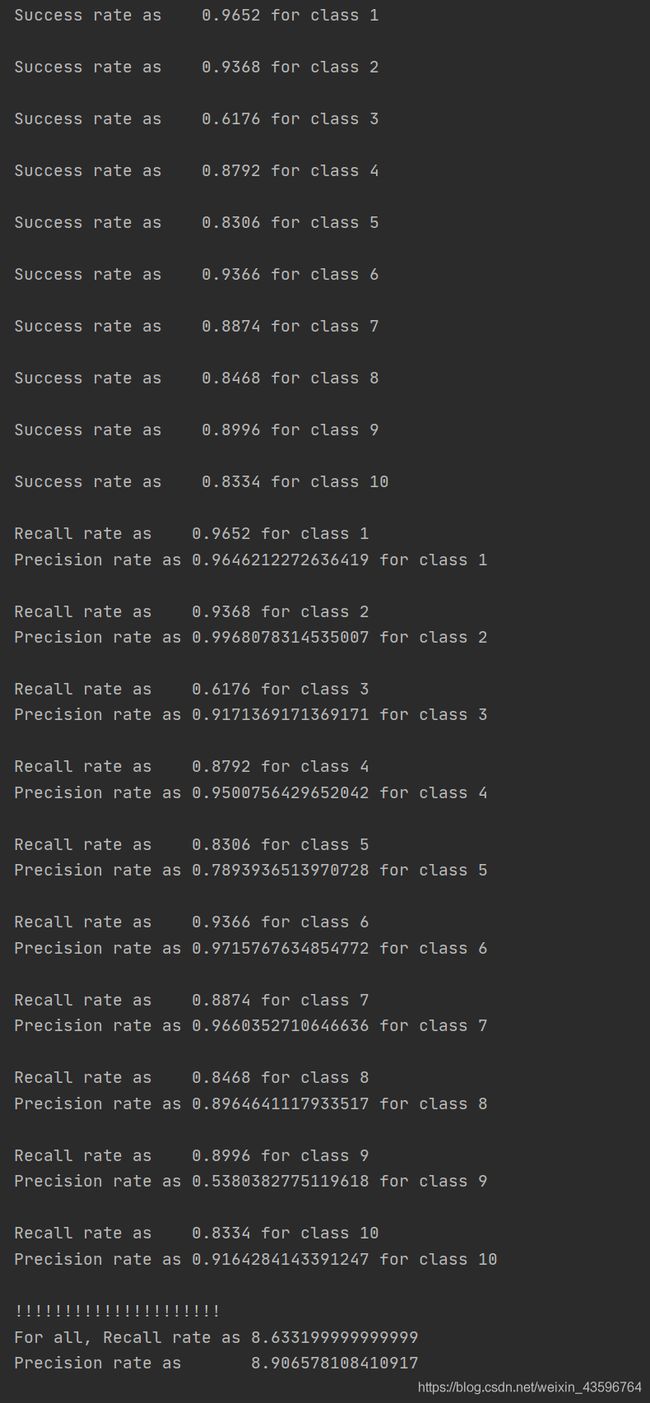
可以看到,在达到数目要求的训练集下,我们可以得到一个比较理想的训练测试结果,召回率和成功率都在85%以上,但其中我们可以看到类别3的召回率以及类别9的成功率都非常低,这可能是由于类别本身性质特征重叠所导致的,比如类别3房地产和类别9家具就会在生活中存在众多的重叠特征,这样的问题只能够通过类别的优化选取或文本训练数量的进一步增加来减轻。
2.SVM
C : float,可选(默认值= 1.0)
错误术语的惩罚参数C。C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
kernel : string,optional(default =‘rbf’)
核函数类型,str类型,默认为’rbf’。可选参数为:
’linear’:线性核函数
‘poly’:多项式核函数
‘rbf’:径像核函数/高斯核
‘sigmod’:sigmod核函数
‘precomputed’:核矩阵
precomputed表示自己提前计算好核函数矩阵,这时候算法内部就不再用核函数去计算核矩阵,而是直接用你给的核矩阵,核矩阵需要为n*n的。
degree : int,可选(默认= 3)
多项式核函数的阶数,int类型,可选参数,默认为3。这个参数只对多项式核函数有用,是指多项式核函数的阶数n,如果给的核函数参数是其他核函数,则会自动忽略该参数。
gamma : float,optional(默认=‘auto’)
核函数系数,float类型,可选参数,默认为auto。只对’rbf’ ,’poly’
,’sigmod’有效。如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features。
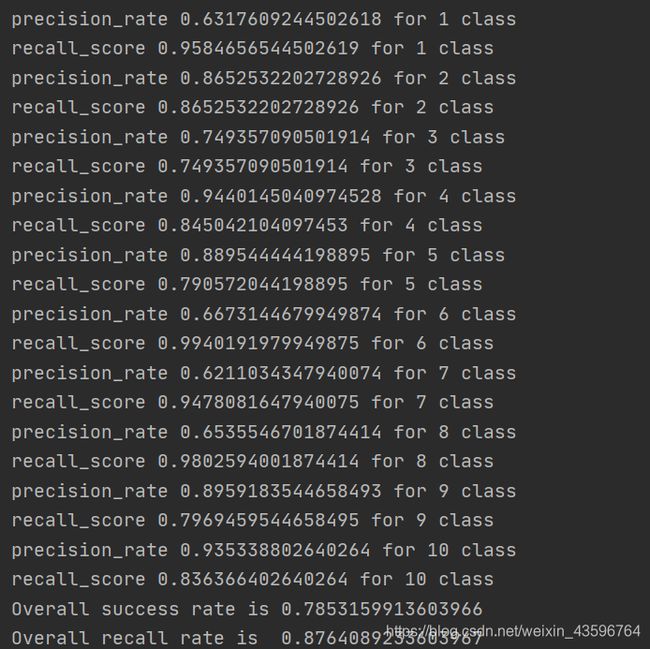
1.改变C的值
![]()
![]()
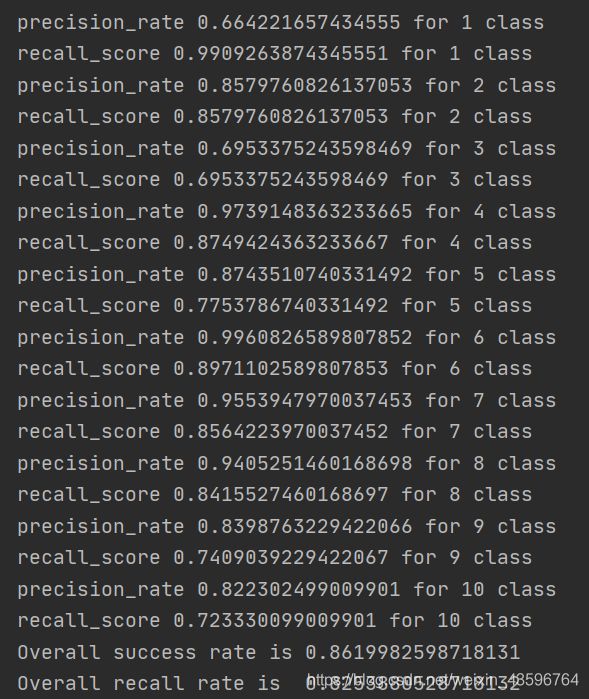
惩罚因子C是调节间隔与准确率的因子,C值越大,越不愿放弃那些离群点;c值越小,越不重视那些离群点。
从上面实验结果可以看出惩罚因子增加对于最终的性能有影响。
2.改变kernel
![]() 
在实验中相较于高斯核函数模型所用时间过多,可能是由于实验所用轻薄本性能所致,故不再详细测试。
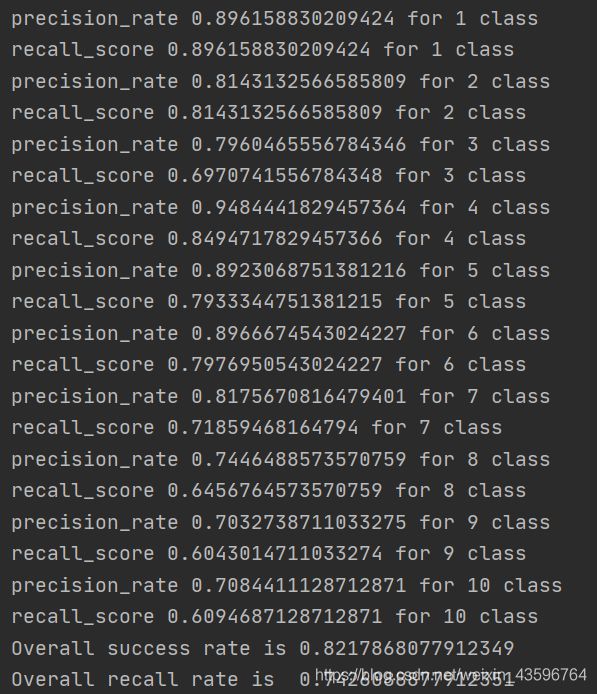
3.改变gamma值
![]()

![]()
![]()

参数gamma主要是对低维的样本进行高度度映射,gamma值越大映射的维度越高,训练的结果越好,但是越容易引起过拟合,即泛化能力低。
在实验中,随着gamma的增大,训练结果呈现不规律的变化,在探求最高性能分类器的过程中可以通过选用不同gamma值不断循环测试选出最佳取值。
图片转存中…(img-UmcIPblJ-1615602667555)]
参数gamma主要是对低维的样本进行高度度映射,gamma值越大映射的维度越高,训练的结果越好,但是越容易引起过拟合,即泛化能力低。
在实验中,随着gamma的增大,训练结果呈现不规律的变化,在探求最高性能分类器的过程中可以通过选用不同gamma值不断循环测试选出最佳取值。