VIT vision transformer pytorch代码复现
这篇论文将transformer机制运用到计算机视觉领域(主要是进行了图片分类),并且取得了不错的效果
其实整体思路挺简单的,就是将是图片拆分成很多小块,然后将小块排列成矩阵送入transformer encoder模块中计算,具体的计算过程如下图所示
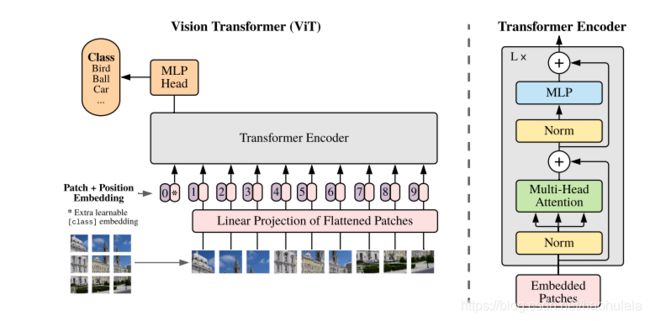
我主要分享一下代码
import torch
import torch.nn as nn
import math
class MLP(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super(MLP, self).__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, input):
output = self.net(input)
return output
class MSA(nn.Module):
"""
dim就是输入的维度,也就是embeding的宽度
heads是有多少个patch
dim_head是每个patch要多少dim
dropout是nn.Dropout()的参数
"""
def __init__(self, dim, heads=8, dim_head=64, dropout=0.):
super(MSA, self).__init__()
self.dim = dim
self.heads = heads
self.dropout = dropout
# 论文里面的Dh
self.Dh = dim_head ** -0.5
# self-attention里面的Wq,Wk和Wv矩阵
inner_dim = dim_head * heads
self.linear_q = nn.Linear(dim, inner_dim, bias=False)
self.linear_k = nn.Linear(dim, inner_dim, bias=False)
self.linear_v = nn.Linear(dim, inner_dim, bias=False)
self.output = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
)
def forward(self, input):
"""
:param input: 输入是embeding,[batch, N, D]
:return: MSA的计算结果的维度和输入维度是一样的
"""
# 首先计算q k v
# [batch, N, inner_dim]
q = self.linear_q(input)
k = self.linear_k(input)
v = self.linear_v(input)
# 接着计算矩阵A
# [batch, N, N]
A = torch.bmm(q, k.permute(0,2,1)) * self.Dh
A = torch.softmax(A.view(A.shape[0],-1), dim=-1)
A = A.view(A.shape[0], int(math.sqrt(A.shape[1])), int(math.sqrt(A.shape[1])))
# [batch, N, inner_dim]
SA = torch.bmm(A, v)
# [batch, N, D]
out = self.output(SA)
return out
class TransformerEncoder(nn.Module):
def __init__(self, dim, hidden_dim=64):
super(TransformerEncoder, self).__init__()
self.norm = nn.LayerNorm(dim)
self.msa = MSA(dim)
self.mlp = MLP(dim, hidden_dim)
def forward(self, input):
output = self.norm(input)
output = self.msa(output)
output_s1 = output + input
output = self.norm(output_s1)
output = self.mlp(output)
output_s2 = output + output_s1
return output_s2
class VIT(nn.Module):
def __init__(self, dim, hidden_dim=64, num_classes=10, num_layers=10):
super(VIT, self).__init__()
self.layers = nn.ModuleList([])
for _ in range(num_layers):
self.layers.append(TransformerEncoder(dim, hidden_dim))
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, num_classes)
)
def forward(self, x):
for layer in self.layers:
x = layer(x)
x = x.mean(dim=1)
x = self.mlp_head(x)
return x
if __name__ == "__main__":
vit = VIT(64).cuda()
seq = torch.rand(2,16,64).cuda()
out = vit(seq)
print(out.shape)