深度学习入门系列2:用TensorFlow构建你的第一个神经网络
仅供学习参考,不做商用!
大家好,我技术人Howzit,这是深度学习入门系列第二篇,欢迎大家一起交流!
深度学习入门系列1:多层感知器概述
深度学习入门系列2:用TensorFlow构建你的第一个神经网络
深度学习入门系列3:深度学习模型的性能评价方法
深度学习入门系列4:用scikit-learn找到最好的模型
深度学习入门系列5项目实战:用深度学习识别鸢尾花种类
深度学习入门系列6项目实战:声纳回声识别
深度学习入门系列7项目实战:波士顿房屋价格回归
深度学习入门系列8:用序列化保存模型便于继续训练
深度学习入门系列9:用检查点保存训练期间最好的模型
深度学习入门系列10:从绘制记录中理解训练期间的模型行为
深度学习入门系列11:用Dropout正则减少过拟合
深度学习入门系列12:使用学习规划来提升性能
深度学习入门系列13:卷积神经网络概述
深度学习入门系列14:项目实战:基于CNN的手写数字识别
深度学习入门系列15:用图像增强改善模型性能
深度学习入门系列16:项目实战:图像中目标识别
深度学习入门系列17:项目实战:从电影评论预测情感
深度学习入门系列18:循环神经网络概述
深度学习入门系列19:基于窗口(window)的多层感知器解决时序问题
深度学习入门系列20:LSTM循环神经网络解决国际航空乘客预测问题
深度学习入门系列21:项目:用LSTM+CNN对电影评论分类
深度学习入门系列22:从猜字母游戏中理解有状态的LSTM递归神经网络
深度学习入门系列23:项目:用爱丽丝梦游仙境生成文本
文章目录
- 1概况
- 2 印第安匹马人糖尿病数据集
- 3加载数据
- 4 定义模型
- 5 编译模型
- 6 拟合模型
- 7 评估模型
- 8 整合
- 9 总结
-
- 9.1 接下来
- 参考
Keras 是个强大而易用的python 库,用于构建和评估深度学习模型。它封装了Theano 和 TensorFlow 的高效的数值计算库并让你用几行代码就能定义和训练神经网络模型。在这节课你将在python中学习如何使用 Keras 创建第一个神经网络模型。完成这节课之后,你将学习:
- 如何用加载 CSV数据集,为使用keras做准备。
- 如何在Keras中定义和编译多层感知器模型。
- 如何在验证集上评估Keras模型。
让我们开始吧
1概况
虽然不需要写很多代码,但是我们需要逐步介绍它,以便于让你了解如何创建自己的模型。本篇包含的步骤如下:
- 1.加载数据。
- 2.定义模型
- 3.编译模型
- 4.拟合模型
- 5.评估模型
- 6.整合所有
2 印第安匹马人糖尿病数据集
在这个教程中,我们将使用匹马印第安人糖尿病数据集。这是一个标准的机器学习数据集,你可以从UCI机器学习仓库免费下载。它描述了匹马印第安病人的医疗记录和是否在五年之内有糖尿病。这是个二分类问题(是糖尿病为1,否则为0)。描述每个病人的输入变量是数字的而且有变化的。下面列表是数据集中8个属性。
1.Number of times Pregnant(怀孕次数)
2.Plasma glucose concentration a 2 hours in an oral glucose tolerance test.(口服葡萄糖耐量试验中2小时血浆葡萄糖浓度)
3.Diastolic blood pressure(mm Hg)(舒张压mm Hg)。
4.triceps skin fold thickness(肱三头肌皮肤褶皱厚度mm)。
5.2-Hours serum insulin(mu u/ml)(2小时血清胰岛素)。
6.Body mass index(体重指数)。
7.diabetes pedigree function(糖尿病谱系功能)。
8.Age 年龄(年)。
9.五年之内糖尿病分类。
鉴于所有属性都是数字的,因此很容易直接用于神经网络的输入和输出值。这个数据集也在本书的其他课程中也使用,因此,最后保存在很容易找得到地方。下面是数据集的样例,展示了768实例中前5行。

数据集文件可在本书提供的代码包中可以获得。或者,你可以从UCI机器学习仓库中下载印第安匹马人数据集,并把它放在本里工程目录下,和你的python文件一样。保存的名字如下:
pima-indians-diabetes.csv
如果所有预测是在没有糖尿病数据上,那么基准准确率为65.1%。在数据集上使用10倍交叉验证,排名靠前的77.7%准确性。你可以在数据集网站UCI机器学习仓库上了解更多关于这个数据集信息。
3加载数据
我们无论什么时候从事机器学习算法,都可以采用随机处理(如随机数),用一个固定的数初始化随机数生成器是一个不错的操作。因此当你重复跑代码时,能够得到同样的结果。如果你需要展示结果,比较算法或者调试程序,那么你需要使用同样的随机源是合适的。你可以用任意随机种子来初始化,例如:
from keras.models import Sequential
from keras.models import Dense
import numpy
# fix random seed for reproducility
seed = 7
numpy.random.seed(seed)
现在我可以加载Pima Indians 数据集。你现在可以使用Numpy中loadtxt()函数直接加载文件。有八个输入变量和一个输出变量(最后一列)。一旦加载我们就将数据集分成输入变量(X)和输出类变量(Y)。
# load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabets.csv",delimiter=",")
# splite into input(X) and output(Y) variables
X = dataset[:,0.8]
Y = dataset[:,8]
我们已经初始化随机生成器,以确保结果的可复制性并加载数据。现在我们准备定义我们的神经网络模型。
4 定义模型
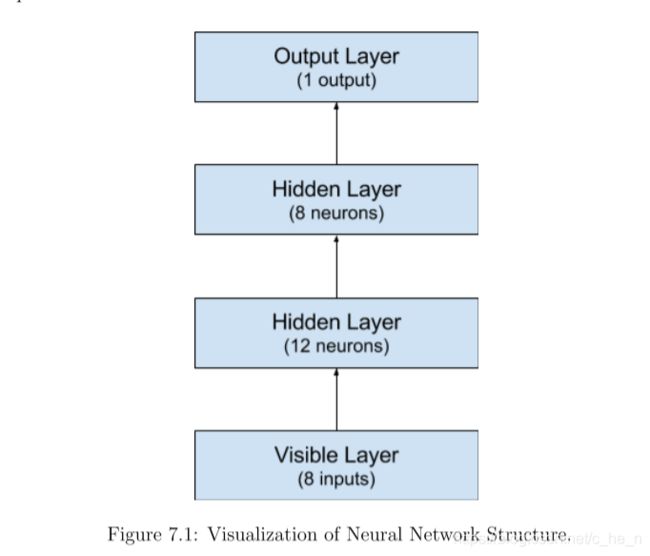
Keras模型由一系列的层组成。我们创建Sequential模型,每次添加一个层,直到满足我们网络拓扑结构。第一件正确的事情是确保输入层与数据集输入个数匹配。当你使用input_dim参数创建第一层时,其设置的8,明确了8为输入变量个数。
如何知道使用的层数和他们类型呢?这是个非常难的问题。可以使用启发式方法,最好的网络结构是在试错过程中找到的。一般来说,如果有必要的话,用一个足够大的网络来捕获问题的结构。在这个例子中,我们将使用三层全连接网络结构。
全连接层使用Dense类定义的。我们能指定该层的神经元个数作为第一个参数,初始化函数为第二个参数init和使用activation指定激活函数。在这个例子中,我们采用一个小的连续性均匀分布(uniform)随机生成的数字来初始化网络权重,在0和0.05之间,因为它是Keras默认均匀权重初始化。另外一个可以选择的是noraml,它是高斯分布随机生成的数字。
我们将在前两层使用整流器(rectifier)relu激活函数,在输出层使用sigmoid激活函数。以前对于所有层的首选是sigmoid和tanh激活函数。现在使用整流器会有更好的性能。
我们在输出层使用sigmoid函数是确保网络的输出在0和1之间而且易于映射到要么类1的概率要么使用默认阈值0.5捕捉到某一类别。通过增加每层把它们拼起来。第一个隐藏层有12个神经元,期望有8输出变量。第二份隐藏层有8个神经元,最后输出层有1个神经元用于预测类(是否会犯糖尿病)。
# create model
model = Sequential()
model.add(Dense(12,input_dim=9,init='uniform',activation='relu'))
model.add(Dense(8,init='uniform',acitvation='relu'))
model.add(Dense(8,init='uniform',acitvation='sigmoid'))
5 编译模型
既然模型已经定义,那么我们就可以编译它。编译模型的后端使用有效的数值计算库,如theano或者tensorflow。为了训练和预测,后端自动的选择最好的方法来表示神经网络并在你的硬件上运行。当编译时,我们必须指定训练网络的必要属性。记住训练网络意味着找到最好的权重集合来预测问题。
对于神经网络,我们必须指定用于评估权重的损失函数、用于搜索不同的网络权重的优化器,在训练中有选择的收集和报告的度量。在这个例子中,我们使用对数损失函数,因为二分类问题在Keras中被定义为binary_crossentropy。我们使用了效率较高的梯度下降算法adam,不为别的原因,默认的有效方法。Adam优化算法可以在Aadm:A method for stochastic Optiimization论文中学习。最后,因为它是分类问题,我们将收集并报展示类别的精度作为指标。
# compile model
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy']
6 拟合模型
我们已经定义了我们模型而且编译它,准备好有效的计算。现在是时候在数据上执行我们的模型了。我们能在已加载数据上通过调用fit()函数训练或者拟合我们的模型。
训练过程以固定迭代次数在数据集上运行,叫做epochs,它通过nb_epoch参数来指定。网络中权重更新之前,我们可以设置很多被评估的实例数量,叫做批量大小(batch size)并且使用batch_size参数进行设置。对于这个问题,我们将以迭代次数(150)和相对较小批量大小10来运行的。再次,通过试错方式来实验选择这些参数。
# Fit the model
model.fit(X,Y,nb_epoch=150,batch_size=10)
这个可以在你的CPU或者GPU上运行。
7 评估模型
我们已经在整个数据集上训练神经网路,我们也能在同样的数据上评估网络性能。这仅仅让我了解到如何在数据集上建模(如训练精度),但是不知道在新数据上如何表现。为了简化但是必要,我们可以这么做,你可以将数据分成训练集和测试集,用于训练和评估你的模型。
在你的训练集上可以用evaluation() 函数评估你的模型,传同样的输入和输出用于训练模型。这将为每对输入和输出生成预测并收集分手,包括平均损失和任何你已经配置的度量,如精度。
# evaluate the model
scores = model.evaluate(X,Y)
print("%s:%.2f%%"%(model.metrics_name[1],scores[1]*100)
8 整合
你已经学到了如何轻松的在Keras上创建第一个神经网络模型,让我们它整合成一个完整的代码。
# create your first MLP in Keras
from keras.models import Sequential
from keras.models import Dense
import numpy
# fix random seed for reproducility
seed = 7
numpy.random.seed(seed)
# load pima indians dataset
dataset = numpy.loadtxt("pima-indians-diabets.csv",delimiter=",")
# splite into input(X) and output(Y) variables
X = dataset[:,0.8]
Y = dataset[:,8]
# create model
model = Sequential()
model.add(Dense(12,input_dim=9,init='uniform',activation='relu'))
model.add(Dense(8,init='uniform',acitvation='relu'))
model.add(Dense(8,init='uniform',acitvation='sigmoid'))
# compile model
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy']
# Fit the model
model.fit(X,Y,nb_epoch=150,batch_size=10)
# evaluate the model
scores = model.evaluate(X,Y)
print("%s:%.2f%%"%(model.metrics_name[1],scores[1]*100)
运行这个例子,你能看到下面的信息-每150周期打印一个损失值和准确率,紧接着是在训练集上训练模型的最后评估。它在theano后端工作站的CPU上执行,花费大概10秒。

9 总结
在这节课中,你已经知道如何使用强大的深度学习keras python 库创建你的第一个神经网络。特别是,你已经学习了使用Keras创建神经网路或者深度学习关键的五步,包括:
- 如何加载数据
- 如何在Keras定义神经网络模型。
- 如何用有效的使用数值后端和编译Keras模型。
- 如何在数据上训练模型。
- 如何在数据集上评估模型
9.1 接下来
你现在已经知道如何在Keras上构建多层感知器。接下来部分,你将学习在未知数据上评估你的模型,并学习估计他们性能的不同方法。
参考
数据集