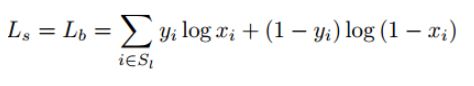场景文本检测的方法(CTPN+EAST+DBNet)
前言
文字识别分为两个具体步骤:一个是文字区域的检测,二是对文字内容进行识别。两者缺一不可,尤其是文字检测部分,是识别的前提。如果连包含文字的区域都找不到,那后面也就无法进行文字识别了。
因为文本存在多种分布,多种方向、排版多样性的特点,所以检测不是一件简单的任务,尤其是当文本是不规则的形状,检测起来就很具有挑战性了。
1.传统的图像学处理:
基本思想就是 : 得出文本信息所在位置的轮廓,中间还可能进行一些形态学的操作:
- 先二值化图片可以自适应二值化
- 如果有些噪声可以采用高斯滤波来简单过滤掉
- 然后通过腐蚀、膨胀这些形态学操作来获取文本的区域,(只要膨胀中的参数kernel设置比较大,就会合并周边的文字了)
- 上面能不能采用开闭运算,我也不知道,没有试过
- 之后再使用查找轮廓的函数来获取轮廓上的点,你也可以画出来看轮廓对不对
- 最后再取出最小外接矩形即可

但是以上的鲁棒性不强,只适合比较简单的文本分布,并且在文本中,字符与字符之间的间隔不能太小。
2.目标检测的方法:
其实我们只需要找到文本所在的位置,根据这一思路,就和目标检测的思想大同小异。因此我们也可以尝试使用目标检测的方法来进行检测,并且看上去类别较少,只有是文字区域或者是背景,看起来就像一个简单的单类别目标检测的任务,自然而然我们就会想到用经典的目标检测网络来进行文本检测,比如经典的Faster RCNN/ YOLO。
但是之前有朋友使用这些方法区检测车牌,说效果也不太理想,也许是因为文本具有方向性,旋转角度的特点吧,单凭目标检测无法判断角度,方向。但是我使用CTPN,EAST,YOLO分别进行检测,可是却发现使用YOLO检测车牌效果还不错?
此外: 文本检测与目标检测的区别:
文本大多数以长矩形形式存在,即长宽比一般较大或较小, 而普通的目标检测中的物体长宽都是比较接近1的。
并且普通物体(比如猫)存在明显的闭合边缘轮廓,而文本却没有。
此外,文本中包含多个文字,但是文字之间是有间隔的,那么我们就可能把每个字都当成单独的文本,而不是把一整行当成目标文本框。
3.CTPN(Connectionist Text Proposal Network)
如今比较常用的文字检测网络还是使用CTPN。因为上述提到,如果采用YOLO这些目标检测的方法,就无法很好地解决字符与字符直接存在空白的问题,而CTPN就是根据这一问题把文本检测的任务进行拆分。
首先CTPN的基础网络使用了VGG16用于特征提取,在VGG的最后一个卷积层CONV5,CTPN用了3×3的卷积核来对该feature map做卷积,这个CVON5 特征图的尺寸由输入图像来决定,而卷积时的步长却限定为16,感受野被固定为228个像素。
卷积后的特征将送入BLSTM继续学习,最后接上一层全连接层FC输出我们要预测的参数:2K个纵向坐标y,2k个分数,k个x的水平偏移量。
那么下面开始介绍CTPN具体的算法:
第一步是首先检测文本框中的一小部分,判断这一部分属于不属于某个文本,然后依次检测,当对一幅图里所有小文本框都检测之后,就将属于同一个文本框的小文本框进行合并,合并之后就可以得到一个完整的、大的文本框了,也就完成了文本的检测任务。

如图所示,左边的图是直接使用Faster RCNN中的RPN来进行候选框提取,可以看出,这种候选框太粗糙了,效果并不好。而右图是利用许多小候选框来合并成一个大文本预测框,可以看出这个算法的效果非常不错,需要说明的是,红色框表示这个小候选框的置信度比较高,而其他颜色的候选框的置信度比较低。我们可以看到,一个大文本的边界都是比较难预测的,那怎么解决这个边界预测不准的问题呢?后面会提到。
除了利用检测小框来代替检测大文本框之外,CTPN还引入了RNN来提升效果。因为检测文本这个任务多少也有一些序列上的相关性。那我们CTPN算法中,把一个完整的文本框拆分成多个小文本框集合,其实这也是一个序列模型,所以,就可以利用前面获取到的信息以及即将获取到的信息进行学习和预测,所以同样可以使用RNN模型。而且,在CTPN中,用的还是BiLSTM(双向LSTM),因为一个小文本框,对于它的预测,我们不仅与其左边的小文本框有关系,而且还与其右边的小文本框有关系!

这个解释就很有说服力了,如果我们仅仅根据一个文本框的信息区预测该框内含不含有文字其实是很草率的,我们应该多参考这个框的左边和右边的小框的信息后(尤其是与其紧挨着的框)再做预测准确率会大大提升。
具体的做法是使用x的偏移进行修正。在卷积后的特征将送入BLSTM继续学习,最后接上一层全连接层FC输出我们要预测的参数:2K个纵向坐标y,2k个分数,k个x的水平偏移量。
这个x的偏移作用是作者提到,也是他们论文的一大亮点,称之为Side-refinement,我理解为文本框边缘优化,对左右边缘进行优化。

如上图所示,如果我们单纯依靠1号框内的信息来直接预测1号框中否存在文字(或者说是不是文本的一部分),其实难度相当大,因为1号框只包含文字的很小一部分。但是如果我们把2号框和3号框的信息都用上,来预测1号框是否存在文字,那么我们就会有比较大的把握来预测1号框确实有文字。
我们还可以看看为什么边缘的文本框的置信度会较中间的低呢?个人认为很大一部分原因就在于因为这些框都位于总文本的边缘,没有办法充分利用左右相邻序列的信息做预测(比如位于最左的文本框丢失了其右边的信息)。
这就是双向LSTM的作用,把左右两个方向的序列信息都加入到学习的过程中去。
与目标检测类似,CTPN还借助了anchor回归的机制,使得RPN能有效地用单一尺寸的滑动窗口来检测多尺寸的物体。当然CTPN根据文本检测的特点做了比较多的创新。
比如采用垂直anchor回归机制,检测小尺度的文本候选框,文本检测的难点在于文本的长度是不固定,可以是很长的文本,也可以是很短的文本。如果采用通用目标检测的方法,将会面临一个问题:如何生成好的text proposal。
针对上述问题,作者提出了一个vertical anchor的方法,具体的做法是只预测文本的竖直方向上的位置,水平方向的位置不预测。与Faster RCNN中的anchor类似,但是不同的是,vertical anchor的宽度都是固定好的了,论文中的大小是16个像素。而高度则从11像素到273像素(每次除以0.7)变化,总共10个anchor。然后采用RNN循环网络将检测的小尺度文本进行连接,得到文本行。

在RPN中anchor机制是使用K个anchor(CTPN中是10个)直接回归预测物体的四个参数(x,y,w,h,但是CTPN采取之回归两个参数(y,h),即anchor的纵向偏移以及该anchor的文本框的高度,因为在CTPN中,每个候选框的宽度w已经规定为16个像素,不用再改,而x坐标直接使用anchor的x坐标,也不用学习,所以CTPN的思路就是只学习y和h这两个参数来完成小候选框的检测!
可是如何将这枚多断断续续的的小尺度候串联成一个完整的文本行呢?其实文本行构建很简单,通过将那些text/no-text score > 0.7的连续的text proposals相连接即可。文本行的构建如下。
首先,为一个proposal Bi定义一个邻居(Bj):Bj−>Bi,其中:Bj在水平距离上离Bi最近,该距离小于50 pixels,它们的垂直重叠(vertical overlap) > 0.7(交集大于一个阈值)
另外,如果同时满足Bj−>Bi和Bi−>Bj,会将两个proposals被聚集成一个pair。接着,一个文本行会通过连续将具有相同proposal的pairs来进行连接来构建。
最后总结一下CTPN这个流行的文本检测框架的三个闪光点:
将文本检测任务转化为一连串小尺度文本框的检测;
引入RNN提升文本检测效果;
Side-refinement(边界优化)提升文本框边界预测精准度。
当然,CTPN也有一个很明显的缺点:对于非水平的文本的检测效果并不好。CTPN论文中给出的文本检测效果图都是文本位于水平方向的,显然CTPN并没有针对多方向的文本检测有深入的探讨。
EAST(An Efficient and Accurate Scene Text Detector)
因为对于将完整的文本行先进行分割检测然后再合并的思路,有人提出质疑,觉得这种做法比较麻烦,把文本检测切割成多个阶段来进行,与上述先将完整文本进行分割检测,然后再合并的思路不同,有人认为这不但增加了检测的耗时,并且还可能造成更大的检测精度上的损失,所以EAST的作者就采用另一种方法。
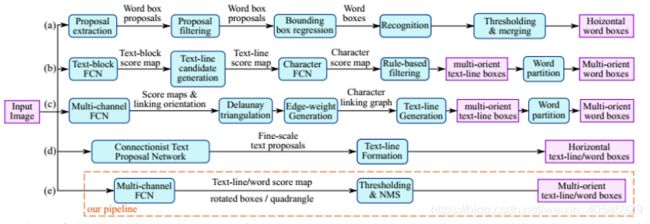
EAST网络分为特征提取层+特征融合层+输出层三大部分。
其中特征提取是采用FCN的结构,接下来送入卷积层,而且后面的卷积层的尺寸依次递减(size变为上一层的一半),而且卷积核的数量依次递增(是前一层的2倍)。抽取不同level的feature map,这样可以得到不同尺度的特征图,目的是解决文本行尺度变换剧烈的问题,size大的层可用于预测小的文本行,size小的层可用于预测大的文本行。

特征合并层是采用了Unet的思想,将抽取的特征从顶部逐渐向下进行合并。这样就可以既能够获得不同阶段的特征信息又能够减少运算了。
然后就轮到了网络输出层:网络的最终输出有5大部分,他们分别是:
- score map:一个参数,表示这个预测框的置信度;
- text boxes: 4个参数,(x,y,w,h),跟普通目标检测任务的bounding box参数一样,表示一个物体的位置;
- text rotation angle: 1个参数,表示text boxe的旋转角度;
- text quadrangle coordinates:8个参数,表示任意四边形的四个顶点坐标,即(x1,y1),(x2,y2),(x3,y3),(x4,y4)。
所以从整体看来,EAST就是借助FCN架构直接回归出文本行的(x,y,w,h,θ)+置信度+四边形的四个坐标!非常简洁!但是看到这里或许会有个问题,为什么要生成四边形的四个坐标呢?(x,y,w,h,θ)这个参数不足以解决文本行定位问题?还真不能,看看下面这个图片。

对于这种带放射变换的文本行(可能还有的是透视变换,呈现出的就不是平行四边形了),呈现出来的形状是平行四边形(黄色虚线为ground true),如果我们以(x,y,w,h,θ)来表示这个文本的位置,就是粉色框所示,显然是不合适的。
EAST目标函数分两部分,第一部分是分类误差,第二部分是几何误差,文中权衡重要性,λg=1。

Ls称为分类误差函数,采用 class-balanced cross-entropy,在我们目标检测的任务中,一般会存在正负样本严重失衡的情况,对于这种情况,现在的方法大部分是采用均衡的采样或者hard negative(即选用一些比较接近正样本,也就是难以区分的负样本作为负样本)进行训练。但是这样会增加一些需要微调的参数,并且增加计算量。其中β=反例样本数量/总样本数量 (balance factor)

Lg为几何误差函数

对于RBOX,采用IoU loss,其中R^是我们预测到的AABB,而R是我们的ground truth。

角度误差则为:其中θ^代表的是我们预测到的旋转角度,θ是我们的ground truth。
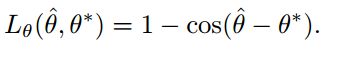
QUAD的损失:其中,文本矩形框的预测偏移量为:

对于QUAD采用smoothed L1 loss:
CQ={x1,y1,x2,y2,x3,y3,x4,y4},NQ*指的是四边形最短边的长度

QUAD的正面积为原图的缩小版,对一个四边形Q={pi|i属于1,2,3,4},pi是按顺时针顺序排列的四边形的顶点。对于缩小的Q,我们首先计算
![]()
其中 D(pi,pj)是两个顶点pi和pj之间的L2距离。
首先收缩两个长点的边,再收缩两个短点的边。对于每对对边,我们通过比较平均长度值来确定长边。对于每个边

NMS的后处理:
因为本文会预测成千上万个几何框,一个简单的NMS算法的时间复杂度是O(n^2),其中n是候选框的数量,这个时间复杂度太高。所以本文提出逐行合并几何图形,假设来自附近像素的几何图形倾向于高度相关,在合并同一行中的几何图形时,将迭代合并当前遇到的几何图形与最后一个合并图形,改进后的时间复杂度为O(n)。
所以会先对所有的output box集合结合相应的阈值(大于阈值则进行合并,小于阈值则不合并),将置信度得分作为权重加权合并,得到合并后的bbox集合;然后对合并后的bbox集合进行标准的NMS操作。
总结一下:
- EAST检测器可以处理的文本实例的最大大小与网络的感受野成正比。这限制了网络预测长文本区域的能力,例如跨越图像的文本行。
- EASt算法可能会遗漏或给出不精确的垂直文本实例预测,因为它们ICDAR 2015训练集中仅有一小部分此种类型的图片。
DBNet(Real-time Scene Text Detection with Differentiable Binarization)
虽然EAST解决了CTPN无法解决的问题:旋转、倾斜文本,但是仍然无法解决扭曲的文本,但是在现实中依旧是存在十分多的这一类场景,因而像DBNet这些基于分割的自然场景文本检测方法变得流行起来。
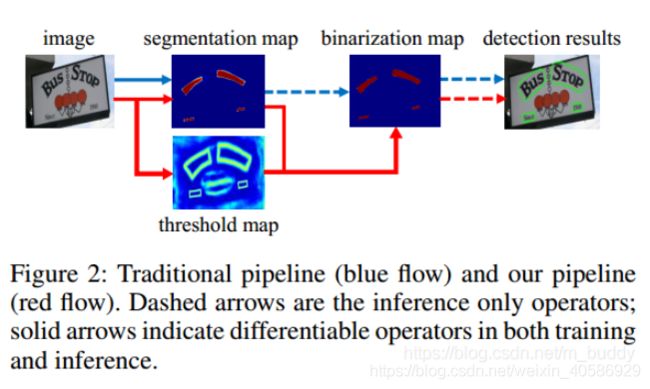
模型结构: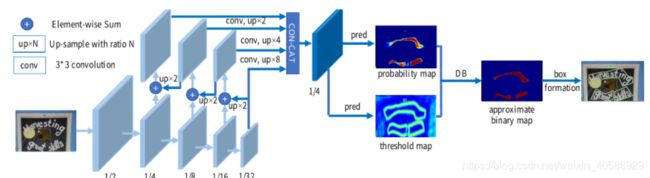
- 首先:图像输入特征提取主干,提取特征;
- 其次: 特征金字塔上采样到相同的尺寸,并进行特征级联到特征F;
- 然后:特征F用于预测概率图(probability map P)和阈值图(threshold map T);
- 最后:通过P和F计算近似二值图(approximate binary map B^)
算法的亮点:
1.可微二值(differentiable binarization)且自适应阈值:
一般的二值化操作都是使用标准二值化:
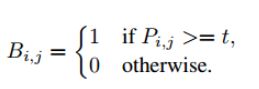
由于上面提到的二值方法不是可微的,因而就不能在分割网络中随着训练的过程进行优化,为了解决这个问题文章提出了一个函数来近似这个二值化过程,既是而在这里是使用可微的二值化。所以,正负样本的优化是具有不同的尺度的,有利于产生更有利于区分的预测
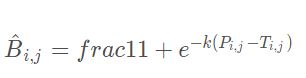
2.可变卷积:
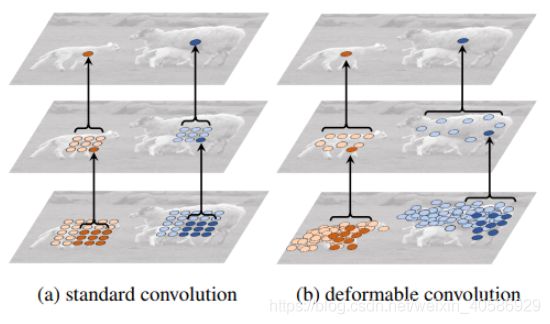
作者使用可变形卷积的原因:可变形卷积可以提供更加丰富的感受野,这对于极端比例的文本检测效果有益。图中以两个3*3的卷积为例,可以看到对于普通卷积来说,卷积操作的位置都是固定的。而可变形卷积因为引入了offset,所以卷积操作的位置会在监督信息的指导下进行选择,可以较好的适应目标的各种尺寸,形状,因此提取的特征更加丰富并更能集中到目标本身。
训练标注的生成:

训练标注的产生和PSENet很像,正样例区域产生通过收缩polygon从G到Gs,使用Vatti clipping algoithm,补偿公式计算:
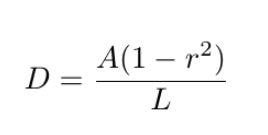
Ls:收缩文本实例的loss;Lb:二值化之后的收缩文本实例loss;Lt:二值化阈值map的loss

网络的损失函数:

上面三个损失分量分别是分割概率损失、二值图损失、阈值图损失, α \alpha α=1.0, β \beta β=10.0 α=1.0,β=10.0。并且为了样本均衡这里使用了困难样本挖掘,保持正负样本的比例为1:3。