【目标检测-YOLO】YOLO v2总结
目录
yolov2架构总结
模型细节
yolov2 损失函数
Loss总结
正负样本理解
推理(VOCdata上)
思考:
YOLOv2的优缺点:
优点:
缺点:
如何优化YOLOv2?
参考
yolov2架构总结

图来自:2.1 YOLO入门教程:YOLOv2(1)-解读YOLOv2 - 知乎

模型细节

图来自:【精读AI论文】YOLO V2目标检测算法_哔哩哔哩_bilibili
YOLOv2 损失函数
Joseph Redmon的官方代码: darknet/region_layer.c at master · pjreddie/darknet · GitHub
AlexeyAB版本代码: darknet/region_layer.c at master · AlexeyAB/darknet · GitHub
下面以 AlexeyAB版本讨论:
代码注释参考:Darknet/region_layer.c at master · BBuf/Darknet · GitHub
yolov2 输出 13*13*5*(4+1+20) 张量(VOC数据集)
13*13 个 grid cell;每个 grid cell 有5个 预测框,每个预测框 有 4个坐标(x, y, w, h) + 1 个置信度(c) + 20 个条件类别概率。
对于每张图像,损失函数包含两部分:
- 遍历 每个 grid cell。 假设 当前 grid cell 的 5个 预测框 为 (b1, b2, b3, b4, b5),5个 Anchor框 为 (A1, A2, A3, A4, A5),当前图像有(T1, T2, ..., T30) 个标注框(x, y, w, h, class(20dims))。
- 遍历 5个 预测框。假设当前为 b1,那么 b1和 每个标注框计算IOU,选择 最大的 IOU,设为 best_iou。计算 b1 的 置信度损失: L1 = noobject_scale*(0 - c_hat)^2。c_hat 为 b1 的预测置信度。如果 best_iou> 0.6,让 L1 = 0。所以当前 cell 计算了 5个损失,如果当前b与所有标注框的IOU的最大值> 0.6,则不计算损失。如果在迭代前 12800 张图像时,计算 b1 和 anchor 的 A1 的 坐标损失(x, y, w, h):L2 = scale*(b1 - A1)^2,这里 A1的中心点在 当前 grid cell中心,但是scale只有 0.01。假设batchsize是32,12800 / 32 = 400,在400步时结束该部分的迭代,这里把 预测框的标签值 设置为 Anchor, 使网络在训练前期 预测框快速学习到先验框的形状。
- 遍历 每个 标注框。假设当前标注框为 T1,计算T1的中心点落在哪个 grid cell 中,假设这个 grid cell 有5个 预测框 为 (b1, b2, b3, b4, b5),有 5个 Anchor框 为 (A1, A2, A3, A4, A5)。
- 遍历 5个 预测框,每个预测框的(w, h)修改为对应anchor 的(w, h), 中心点移到(0,0)位置,其实就是 anchor框 。T1和每个 anchor 框(将二者的中心点移到(0,0)位置) 分别计算IOU, 选择 最大的 IOU,设为 best_iou, 对应的索引为 best_index。计算 best_index对应的预测框(假设为b) 和 当前真实框 T1的IOU,记为 IOU_truth。并计算坐标损失:L3 = coord_scale * (T1 - b)^2,其中代码中对 b的 (x, y) 求了sigmoid。该IOU为当前预测框置信度的标签,设b的置信度为C_hat,因此置信度损失为:L4 = object_scale * (IOU_truth - C_hat)^2。然后计算 T1 和 b 的类别损失: L5 = class_scale * (T1 - b)^2。
Joseph Redmon版本中, coord_scale = coord_scale * (2 - truth.w*truth.h)。有人说是:
在计算boxes的w和h误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale * (2 - truth.w*truth.h)(这里和都归一化到(0,1)),这样对于尺度较小的其权重系数会更大一些,可以放大误差,起到和YOLOv1计算平方根相似的效果。
参考链接
但是我在最新代码中没有发现这句,估计是代码版本问题。代码中是这句:
float iou = delta_region_box(truth, l.output, l.biases, best_n, best_index, i, j, l.w, l.h, l.delta, l.coord_scale);计算两个框的IOU和 tx, ty, tw, th 与传入框的x, y, w, h 的LOSS
float delta_region_box(box truth, float *x, float *biases, int n, int index, int i, int j, int w, int h, float *delta, float scale)
{
box pred = get_region_box(x, biases, n, index, i, j, w, h);
float iou = box_iou(pred, truth);
float tx = (truth.x*w - i);
float ty = (truth.y*h - j);
float tw = log(truth.w / biases[2*n]);
float th = log(truth.h / biases[2*n + 1]);
if(DOABS){
tw = log(truth.w*w / biases[2*n]);
th = log(truth.h*h / biases[2*n + 1]);
}
delta[index + 0] = scale * (tx - logistic_activate(x[index + 0])) * logistic_gradient(logistic_activate(x[index + 0]));
delta[index + 1] = scale * (ty - logistic_activate(x[index + 1])) * logistic_gradient(logistic_activate(x[index + 1]));
delta[index + 2] = scale * (tw - x[index + 2]);
delta[index + 3] = scale * (th - x[index + 3]);
return iou;
}Loss总结
重新整理下源码中的Loss 函数:w,h代表特征图的宽高,B代表每个grid cell 预测框的个数 = A(Anchor框)的个数。上标C表示计算置信度损失,上标x,y,w,h 表示计算坐标损失,上标Class表示计算类别损失。
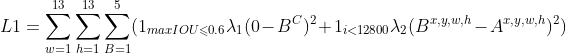
![]() 表示:当前cell, 一个预测框 B 和全图标注框 T 的 maxIOU <= 0.6,那么该项为1,否则为0。
表示:当前cell, 一个预测框 B 和全图标注框 T 的 maxIOU <= 0.6,那么该项为1,否则为0。![]() 表示只在迭代前12800张图像时为1,否则为0。
表示只在迭代前12800张图像时为1,否则为0。![]() 。
。
![]() 表示:当前标注框T,中心点落在的那个cell中,T与该cell中所有 Anchor,计算只考虑形状,不考虑位置的IOU((x,y)移动到(0,0)),取最大的为
表示:当前标注框T,中心点落在的那个cell中,T与该cell中所有 Anchor,计算只考虑形状,不考虑位置的IOU((x,y)移动到(0,0)),取最大的为 ![]() 。也就是一个有标注框中心落在的 cell 中,只有最大的
。也就是一个有标注框中心落在的 cell 中,只有最大的![]() 对应的B,参与了 后面的三项损失计算。其中,置信度的标签与YOLOv1一致,为该B与当前标注框T的IOU。
对应的B,参与了 后面的三项损失计算。其中,置信度的标签与YOLOv1一致,为该B与当前标注框T的IOU。
所以总的Loss = L1 + L2。
网上大佬总结的为:

含义和我总结的是一致的。
正负样本理解
yolov1损失函数的设计与yolov2的区别是什么?
正样本的选择yolov1和yolov2是一致的,即标注框的中心落在哪个cell,哪个cell中的一个预测框就“负责”预测该标注框,这里“负责”的意思是,该框被选为了正样本,那么会计算该预测框与真实框的 坐标损失、分类损失和置信度损失。置信度损失的标签定义v1和v2依旧是一样的,就是预测框和标注框的IOU。
不同点在哪里呢?
如何选择 正样本,也就是那个预测框,v1和v2 是不同的。
v1 是 选择两个预测框与真实框的IOU最大的那个。
v2因为引入了Anchor ,做法却是 计算当前cell中的所有Anchor 与 当前标注框的IOU,选择最大的IOU的Anchor 对应的 预测框 作为正样本。并且计算该IOU,并没有考虑位置,而是把二者的(x, y) 移动到 (0, 0)计算的,估计这么做是为了简化吧。
为什么v2是选择 Anchor和标注框计算IOU,从而选择正样本?代码中是这么写的。
l.bias_match和 DOABS 都为1,因此预测框的 w和h 变为了 Anchor的,x, y变成了 0,0。因为Anchor和预测框是1对1的,这样就得到了最合适的预测框的索引。然后通过该索引计算正样本的置信度标签,也就是该预测框和标注框的IOU。
for(n = 0; n < l.n; ++n){
int index = size*(j*l.w*l.n + i*l.n + n) + b*l.outputs;
box pred = get_region_box(l.output, l.biases, n, index, i, j, l.w, l.h);
if(l.bias_match){
pred.w = l.biases[2*n];
pred.h = l.biases[2*n+1];
if(DOABS){
pred.w = l.biases[2*n]/l.w;
pred.h = l.biases[2*n+1]/l.h;
}
}
//printf("pred: (%f, %f) %f x %f\n", pred.x, pred.y, pred.w, pred.h);
pred.x = 0;
pred.y = 0;
float iou = box_iou(pred, truth_shift);
if (iou > best_iou){
best_index = index;
best_iou = iou;
best_n = n;
}
}v1和v2负样本的选择的区别?
相同点:二者都是把负样本的置信度往0进行优化
不同点:如何选择负样本不同。
v1 把 正样本那个cell中那个低IOU值的预测框以及所有cell中没有标注框中心的那些预测框(每个cell 两个)设为 负样本。这些预测框的置信度往0优化。
v2 先计算当前cell 中 每个 预测框与 所有 标注框 的 最大IOU,一张图像输入,那么会有 13*13*5= 845 个最大IOU,也是一共 845个预测框,若每个最大IOU小于等于0.6,那么设置为负样本。将这些预测框的置信度往0优化。
推理(VOCdata上)
yolov1因为有FC,所以固定输入448,输出为 7*7*30,然后是后处理。
yolov2因为没有FC,所以输入可变为 32倍,假设输入是416,那么输出为 13*13*5(4+1+20),然后是后处理。
二者的后处理一致。
思考:
yolo v1 和 v2 都是 把一张图像(W, H, 3)编码为一个3D张量,记为(w, h, c)。w和h表示将图像降采样了 W/w和H/h倍,而c表示将坐标(4) + 置信度(1) + 条件概率(20d)存到该向量中。而这25d向量就包含了提取的信息。输出张量的每个像素表示了图像中的某块感受野。
YOLOv2的优缺点:
优点:
- 结果:相对v1 (更快、mAP更高)
- 正负样本:引入Anchor和使用K-means聚类,提高了Recall
- Backbone:DarkNet-19,降低了计算量(更快)
- Neck:引入特征融合模块(passthrouch),融合细粒度特征
- 检测头:去掉v1中的FC,可以适应32x的输入; 多尺度训练提高模型能力;二者实现了速度和精度的权衡
- 小技巧:引入BN,加速网络收敛;约束输出范围,训练更稳定;
- 其他训练细节......
缺点:
- Backbone 可持续优化
- Neck 可持续优化
- 只是单个检测头,小目标识别还不太好
- 损失函数可持续优化
如何优化YOLOv2?
- 改进Backbone,提取更好的特征: DarkNet-19 没有残差结构
- 改进Neck: passthrough层可能并不好,小目标检测不好。如FPN, SPP等
- 借鉴SSD的多级检测
- 改进损失函数,如使用 GIoU损失函数
参考
darknet/region_layer.c at master · AlexeyAB/darknet · GitHub
深度学习知识十四 yolo v2 损失函数源码(训练核心代码)解读和其实现原理、网络的输出格式_yangdeshun888的博客-CSDN博客
darknet源码阅读之region_layer.c_beingod0的摸爬滚打-CSDN博客
GitHub - BBuf/Darknet: AlexeyAB-DarkNet源码解析