深度学习机器学习面试题——损失函数
深度学习机器学习面试题——损失函数
提示:重要的深度学习机器学习面试题,大厂可能会在笔试面试中考
说一下你了解的损失函数?
说说你平时都用过什么损失函数,各自什么特点?
交叉熵函数与最大似然函数的联系和区别?
在用sigmoid作为激活函数的时候,为什么要用交叉熵损失函数,而不用均方误差损失函数?
关于交叉熵损失函数(Cross-entropy)和 平方损失(MSE)的区别?
推导交叉熵损失函数?
为什么交叉熵损失函数有log项?
说说adaboost损失函数
说说SVM损失函数
简单的深度神经网络(DNN)的损失函数是什么?
说说KL散度
说说Yolo的损失函数
交叉熵的设计思想是什么
说说iou计算
手写miou计算
交叉熵为什么可以做损失函数
文章目录
- 深度学习机器学习面试题——损失函数
-
- @[TOC](文章目录)
- 说一下你了解的损失函数?
- 为啥要设计损失函数?
- 说说你平时都用过什么损失函数,各自什么特点?
- 交叉熵函数与最大似然函数的联系和区别?
- 在用sigmoid作为激活函数的时候,为什么要用交叉熵损失函数,而不用均方误差损失函数?
- 关于交叉熵损失函数(Cross-entropy)和 平方损失(MSE)的区别?
- 推导交叉熵损失函数?
- 为什么交叉熵损失函数有log项?
- 说说adaboost损失函数
- 说说SVM损失函数
- 简单的深度神经网络(DNN)的损失函数是什么?
- 说说KL散度
- 说说Yolo的损失函数
- 交叉熵的设计思想是什么
- 说说iou计算
- 手写miou计算
- 交叉熵为什么可以做损失函数
- 总结
文章目录
- 深度学习机器学习面试题——损失函数
-
- @[TOC](文章目录)
- 说一下你了解的损失函数?
- 为啥要设计损失函数?
- 说说你平时都用过什么损失函数,各自什么特点?
- 交叉熵函数与最大似然函数的联系和区别?
- 在用sigmoid作为激活函数的时候,为什么要用交叉熵损失函数,而不用均方误差损失函数?
- 关于交叉熵损失函数(Cross-entropy)和 平方损失(MSE)的区别?
- 推导交叉熵损失函数?
- 为什么交叉熵损失函数有log项?
- 说说adaboost损失函数
- 说说SVM损失函数
- 简单的深度神经网络(DNN)的损失函数是什么?
- 说说KL散度
- 说说Yolo的损失函数
- 交叉熵的设计思想是什么
- 说说iou计算
- 手写miou计算
- 交叉熵为什么可以做损失函数
- 总结
说一下你了解的损失函数?
(1)用于回归的损失函数:
绝对值损失函数
平方损失函数(squared loss):常用于线性回归。
(2)用于分类的损失函数:
0-1损失函数(zero-one loss):在感知机中,使用的该损失函数
对数损失函数(log loss):用于最大似然估计,等价于交叉熵损失函数
指数损失函数(exponential loss):在adaboost中使用的该损失函数
合页损失函数(hinge loss):在SVM中使用的该损失函数
交叉熵损失函数(cross-entropy loss):用于分类任务
(3)用于分割的损失函数:
IOU loss:就是交集和并集的比值,常用于分割任务、回归任务。–目标检测
Dice loss
Tversky Loss :引入α和β来控制Recall和Precision
(4)用于检测的损失函数:
Smooth L1 Loss :融合绝对值损失函数和平方损失函数,faster RCNN用的该损失函数
Focal loss :用于单阶段目标检测方法中样本极端不平衡的情况。在RetinaNet网络中使用该损失函数。惩罚权重
为啥要设计损失函数?
为什么需要损失函数?
损失函数用来评价模型的预测值和真实值不一样的程度,在模型正常拟合的情况下,损失函数值越低,模型的性能越好。不同的模型用的损失函数一般也不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差值,结构风险损失函数是指经验风险损失函数加上正则项。









分阶段调整,


说说你平时都用过什么损失函数,各自什么特点?
多看几遍,印象就深刻了


交叉熵函数与最大似然函数的联系和区别?
俩意思是反的:对数似然函数添加一个负号就是交叉熵损失函数
最大化似然函数,就是最小化交叉熵损失函数!!!
区别:交叉熵函数使用来描述模型预测值和真实值的差距大小,越大代表越不相近;【熵增混乱,过大代表不相近】
似然函数的本质就是衡量在某个参数下,整体的估计和真实的情况一样的概率,越大代表越相近。【越相似呗】
**联系:**交叉熵函数可以由最大似然函数在伯努利分布的条件下推导出来,或者说最小化交叉熵函数的本质就是对数似然函数的最大化。


在用sigmoid作为激活函数的时候,为什么要用交叉熵损失函数,而不用均方误差损失函数?
因为交叉熵损失函数可以完美解决平方损失函数权重更新过慢的问题,具有“误差大的时候,权重更新快;误差小的时候,权重更新慢”的良好性质。
sigmoid作为激活函数的时候,如果采用均方误差损失函数,那么这是一个非凸优化问题,不宜求解。而采用交叉熵损失函数依然是一个凸优化问题,更容易优化求解。



关于交叉熵损失函数(Cross-entropy)和 平方损失(MSE)的区别?


上一题就推导过参数更新的公式,平方损失更新过慢
但是交叉熵更新要快可以快,要慢可以慢

推导交叉熵损失函数?


为什么交叉熵损失函数有log项?
这里有两种回答方式。
第一种:因为是公式推导出来的,比如第六题的推导,推导出来的有log项。
第二种:通过最大似然估计的方式求得交叉熵公式,这个时候引入log项。
这是因为似然函数(概率)是乘性的,而loss函数是加性的,所以需要引入log项“转积为和”。而且也是为了简化运算。
说说adaboost损失函数

说说SVM损失函数

简单的深度神经网络(DNN)的损失函数是什么?
深度神经网络(DNN)涉及到梯度消失的问题,
如果使用**均方误差 作为损失函数配合sigmoid激活函数,那么参数更新缓慢。
这个时候应该考虑使用交叉熵作为损失函数**,可以避免参数更新缓慢的问题。
说说KL散度

类似的还有一个JS散度,基于KL散度的变体,
解决了KL散度非对称的问题。
GAN网络用的JS散度作为损失函数。
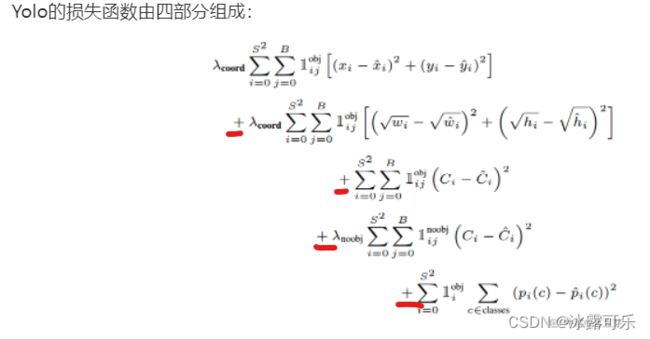
说说Yolo的损失函数

交叉熵的设计思想是什么
交叉熵函数的本质是对数函数。最大似然估计,加一个负号
交叉熵函数使用来描述模型预测值和真实值的差距大小,越大代表越不相近。
最大化似然概率就是最小化交叉熵损失函数
交叉熵损失函数可以完美解决平方损失函数权重更新过慢的问题,具有“误差大的时候,权重更新快;误差小的时候,权重更新慢”的良好性质。
对数损失在逻辑回归和多分类任务上广泛使用。
交叉熵损失函数的标准型就是对数损失函数,本质没有区别。
说说iou计算

手写miou计算
A:
左下角坐标(left_x,left_y)
右上角坐标(right_x,right_y)
B:
左下角坐标(left_x,left_y)
右上角坐标(right_x,right_y)
def IOU(rectangle A, rectangleB):
W = min(A.right_x, B.right_x) - max(A.left_x, B.left_x)
H = min(A.right_y, B.right_y) - max(A.left_y, B.left_y)
if W <= 0 or H <= 0:
return 0;
SA = (A.right_x - A.left_x) * (A.right_y - A.left_y)
SB = (B.right_x - B.left_x) * (B.right_y - B.left_y)
cross = W * H
return cross / (SA + SB - cross)
mIOU一般都是基于类进行计算的,将每一类的IOU计算之后累加,再进行平均,得到的就是mIOU。
交叉熵为什么可以做损失函数
本质上是学习模型,使得预测数据的分布,模拟真实数据的分布
那就洗完相对熵小,于是用交叉熵来替代相对熵。

总结
提示:重要经验:
1)面试官可能会问你平时常见的损失函数,并问你为啥要用这种函数来做训练呢?你看似常用的,但是面试官就是要问你为啥这么干
2)那就需要把各种损失函数的目的搞清楚,咱们用它干嘛,优化模型的参数更新,一个是降低分布差异,一个是加快更新参数的速度
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。