【自然语言处理】【实体匹配】用于实体匹配中blocking环节的深度学习:一个设计空间的探索
论文地址:http://vldb.org/pvldb/vol14/p2459-thirumuruganathan.pdf
相关博客:
【自然语言处理】【实体匹配】用于实体匹配中blocking环节的深度学习:一个设计空间的探索
【自然语言处理】【实体匹配】PromptEM:用于低资源广义实体匹配的Prompt-tuning
【自然语言处理】【知识图谱】利用属性、值、结构来实现实体对齐
【自然语言处理】【知识图谱】基于图匹配神经网络的跨语言知识图谱对齐
【自然语言处理】【知识图谱】使用属性嵌入实现知识图谱间的实体对齐
【自然语言处理】【知识图谱】用于实体对齐的多视角知识图谱嵌入
【自然语言处理】【知识图谱】MTransE:用于交叉知识对齐的多语言知识图谱嵌入
【自然语言处理】【知识图谱】SEU:无监督、非神经网络实体对齐超越有监督图神经网络?
一、简介
实体匹配 (Entity Matching,EM) \text{(Entity Matching,EM)} (Entity Matching,EM)是寻找指向现实中相同实体的数据实例。大多数的实体匹配解决方案都会先执行blocking再执行matching。已经有许多工作将深度学习应用到matching环节,但很少有工作将深度学习应用在blocking阶段。这些blocking的工作也具有局限性,其仅考虑了深度学习的简单形式,并且一部分工作还需要标注数据。在本文中,开发了 DeepBlocker \text{DeepBlocker} DeepBlocker框架,其显著改进了深度学习在实体匹配blocking阶段的state-of-the-art。作者先定义了一个用于blocking的深度学习解决方案的解空间,其包含了不同复杂性的解决方案并包含了大量先前的工作。接下来,作者在解空间中开发了8个具有代表性的解决方案。这些解决方案不需要标注数据,并能够利用深度学习近期的进展。实验结果显示本文的最优方案在dirty数据和textual数据上超越了现有的最优深度学习解决方案和非深度学习解决方案,并在结构化数据上展示出好的竞争力。最终,实验展示了合并最优的深度学习和非深度学习解决方案能够得到更好的效果。
二、背景知识
1. 实体匹配
实体匹配有许多的场景,例如:直接匹配两个表、同一个表中的tuple进行匹配、匹配表和知识库等。本文仅考虑常见的匹配场景:给定两个具有相同schema的表 A A A和 B B B,目标是发现指向现实中相同实体的匹配tuple对 ( a ∈ A , b ∈ B ) (a\in A,b\in B) (a∈A,b∈B)。具有相同schema的匹配场景非常常见,即使是匹配两个不同schema的表,许多解决方案都仅会考虑两个表的公共属性。本文的解决方案也会处理不同schema的表,但仅在表的共享属性上进行测试。
大多数的实体匹配解决方案都包含两个步骤:blocking和matching。blocking阶段会使用启发式的方法快速过滤掉不可能匹配的对 ( a , b ) (a,b) (a,b)。matching阶段则会使用一个匹配器来预测保留下来的实体对是否匹配。本文主要专注在blocking阶段。
2. 非深度学习Blocking
常见的blocker都是基于属性等价 (attribute equivalence) \text{(attribute equivalence)} (attribute equivalence)、哈希或者相邻排序 (sorted neighborhood) \text{(sorted neighborhood)} (sorted neighborhood)。属性等价方法会输出共享相同属性值的tuple对。哈希方法是属性等价的推广,其会输出两个具有相同哈希值的tuple对。相邻排序则是会输出哈希值在指定范围内的tuple对。
更复杂的blocker还有基于相似度、基于规则或者复合的方法。基于相似度的方法类似于属性等价,它只使用了编辑距离、 Jaccard \text{Jaccard} Jaccard等方式来处理脏数据、错误拼写、缩写。基于规则的blocking则会利用多个规则以及逻辑谓词。
3. 深度学习Blocking
相较于大量基于非深度学习的blocking,基于深度学习的工作要少的多。最早的工作时 DeepER \text{DeepER} DeepER,其通过对单个单词的向量进行未加权聚合为tuple向量。近期, AutoBlock \text{AutoBlock} AutoBlock通过标注数据来学习聚合词的权重。 DeepBlock \text{DeepBlock} DeepBlock仍然会执行基于关键词的聚合,但是会使用词向量计算关键词的语义相似度来进行优化。
4. 本文的问题设定
本文考虑的问题是对两个具有相同schema的表 A A A和 B B B来进行blocking。此外,不假设存在任何标注数据。令 C C C表示在表 A A A和 B B B上应用blocker产生的候选样本对集合。本文的目标是寻找能够最大化召回 ∣ C ∩ G ∣ / ∣ G ∣ |C\cap G|/|G| ∣C∩G∣/∣G∣,并且最小化 ∣ C ∣ |C| ∣C∣和时间消耗的blocking解决方案。
三、设计空间
1. 架构模板与设计空间
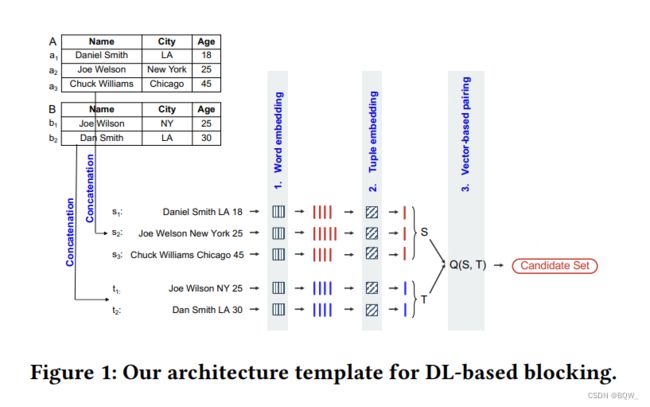
上图展示了用于blocking的深度学习解决方案架构模板。给定两个表 A A A和 B B B,通过合并所有的属性值来将每个tuple转换为一个字符串。举例来说,表 A A A中元组 a 1 a_1 a1转换为Daniel Smith LA 18。由于缺乏人类的输入和标注好的训练数据,不知道什么属性更加重要,所以使用所有的属性。一个合理的解决方案是将所有属性都拼接,然后让深度学习解决方案来以无监督的方法来确定哪些特征最重要。
得到的字符串被送入三个主要的模块:Word Embedding、Tuple Embedding和Vector Pairing。Word Embedding模块将每个字符串中的单词转换为高维向量。Tuple Embedding模块则将这些向量合并成一个单值向量,用来表示整个字符串(原始tuple)。举例来说,表 A A A中的元组 a 1 a_1 a1可以被转换为字符串Daniel Smith LA 18。Word Embedding模块将其转换为4个向量,然后Tuple Embedding模块将这4个向量合并为单个向量。
表 A A A和 B B B中的每个元组被转换为嵌入向量。举例来说,上图中的表 A A A转换为三个向量的表 S S S,类似的表 B B B转换为表 T T T。最终,Vector Pairing模块会使用程序 Q(S,T) \text{Q(S,T)} Q(S,T)来快速搜索表 S S S和 T T T,来寻找相似的向量对。
此时,表 A A A和 B B B中的每个元组被转换为嵌入向量。举例来说,上图中的表 A A A转换为三个向量的表 S S S,类似的表 B B B转换为表 T T T。最终,Vector Pairing模块会使用程序 Q(S,T) \text{Q(S,T)} Q(S,T)来快速搜索表 S S S和 T T T,来寻找相似的向量对。
2. Word Embedding选择
该模块将字符串中的每个单词转换为嵌入向量。这里主要有4个选择:
2.1 单词级粒度 vs 字符级粒度
给定一个单词序列,一个词级别的嵌入会将每个单词编码为固定维度的向量。通常,这是通过映射表来实现的。但不在词表中的任意单词会触发 OOV \text{OOV} OOV,并且会被替换为特殊的token。
字符级的嵌入将每个单词看作是子词序列,例如:独立的字符、bi-grams、tri-grams等,并使用神经网络来产生基于整个词的向量。这个方法可以处理单词的形态学变体(例如,data、database、dataset),并为任意的袋外词产生嵌入,而且对错误拼写具有鲁棒性。因此,该方法更加适合 EM \text{EM} EM场景。
2.2 预训练 vs 学习嵌入
另一个正交设计选择是如何训练嵌入。word2vec和GloVe是流行的词级别嵌入,fastText则是流行的字符级嵌入。通常有在大规模外部语料 Wikipedia \text{Wikipedia} Wikipedia、 Common Crawl \text{Common Crawl} Common Crawl或者 PubMed \text{PubMed} PubMed上预训练好的嵌入向量,可以在实体匹配中直接使用。
3. Tuple Embedding选择
该模块会将一个tuple中的向量序列转换为整个tuple的向量表示。主要挑战是,在没有标注数据的情况下确保相似tuple具有相同的嵌入。为了解决这个问题,考虑两种深度学习技术:aggregation和self-supervision。
3.1 Aggregation
这类方法会应用一个聚合函数 F : R d e × ⋅ → R d u F:\mathbb{R}^{d_e\times\cdot}\rightarrow\mathbb{R}^{d_u} F:Rde×⋅→Rdu来生成一个tuple嵌入向量 u t \textbf{u}_t ut。最常见的方法是取平均 ,例如 DeepER \text{DeepER} DeepER对所有词向量使用不加权平均,而 SIF \text{SIF} SIF使用加权平均。
由于后续会在 SIF \text{SIF} SIF上进行实验,所以现在描述其更多的细节。首先,在每个tuple中所有单词向量上计算一个加权平均来获得聚合向量。给定一个tuple字符串中的单词 w w w,其权重为 f ( w ) = a / ( a + p ( w ) ) f(w)=a/(a+p(w)) f(w)=a/(a+p(w)),其中 a a a是超参数并且 p ( w ) p(w) p(w)是数据集中单词 w w w的规范化频率。接下来,使用 PCA \text{PCA} PCA计算聚合向量的第一主成分。最终,通过从聚合向量中减去第一主成分来计算每个tuple的嵌入向量。具体来说,令 v t \textbf{v}_t vt表示元组 t t t的聚合向量, p \textbf{p} p是第一主成分,tuple的嵌入向量为 u t = v t − pp T v t \textbf{u}_t=\textbf{v}_t-\textbf{pp}^T\textbf{v}_t ut=vt−ppTvt。 SIF \text{SIF} SIF推广了 DeepER \text{DeepER} DeepER中的不加权拼接方法,其在文本相似度上实现了与复杂 NLP \text{NLP} NLP任务相当的效果。
如上所述,aggregation不涉及到学习并且能够高效的实现。但是其使用的是词袋的方法,序列信息被忽略了。因此,元组A bought B和B bought A将具有相同的嵌入向量。此外,其也不能处理多义词,即相同的单词/短语具有不同的含义,样在Apple tv和Apple tree中的Apple具有相同的嵌入向量。
3.2 Self-Supervised
该方法会采用最近深度学习工作中流行的自监督想法。其按如下工作:(1) 定义一个监督学习任务,也称为辅助任务,其能够自动从表 A A A和 B B B中推导出标注训练数据。(2) 在标注数据上训练一个深度学习模块来解决上面的任务;(3) 使用训练好的深度学习模块为表 A A A和 B B B中的元组产生嵌入向量。
下面会考虑4种类型的辅助任务:self-reproduction、cross-tuple training、triplet loss minimization和hybrid。对于每种类型,讨论一些有前景的深度学习解决方案。
现有的工作仅考虑了blocking中的聚合方法。因此,这个工作的关键技术贡献是,在实体匹配的blocking中采用了近期深度学习中流行的自监督,并且开发了一系列的解决方案。
4. Self-Reproduction方法
该方法将一个元组 t t t输入至一个神经网络,并输出一个稠密向量 u t \textbf{u}_t ut,然后将 u t \textbf{u}_t ut送入至第二个神经网络,尝试恢复原始的tuple。若能恢复原始的tuple, u t \textbf{u}_t ut则可以看作是元组 t t t的稠密摘要,并且可以用作是元组 t t t的嵌入向量。上面两个神经网络称为encoder和decoder。这种称为自编码的框架已经被用于各种任务中,例如维度缩减。但目前还没有在实体匹配的blocking中使用。
下面讨论两种自编码方法: Autoencoder \text{Autoencoder} Autoencoder和 Seq2Seq \text{Seq2Seq} Seq2Seq。
4.1 Autoencoder \text{Autoencoder} Autoencoder
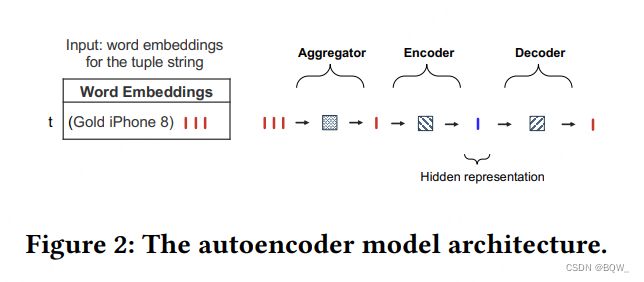
这是一种相对简单的自编码方法。回忆一下,该方法希望构建一个模型来接受词向量序列 e t \textbf{e}_t et作为输入,并生成一个输出向量 o t \textbf{o}_t ot来恢复 e t \textbf{e}_t et中的信息。理想情况下,我们希望模型能够精确的恢复 e t \textbf{e}_t et,并以这个目标来训练模型。
正如上图所示,模型是由一个aggregator、一个encoder和一个decoder组成。使用两层的前馈网来作为encoder和decoder。前馈神经网络不能够接收可变长度的词向量序列。因此,通过一个聚合操作 f ( ⋅ ) f(\cdot) f(⋅),在第一步中将 e t ∈ R d e × ⋅ \textbf{e}_t\in\mathbb{R}^{d_e\times\cdot} et∈Rde×⋅转换为固定尺寸的向量 v t = f ( e t ) ∈ R d e \textbf{v}_t=f(\textbf{e}_t)\in R^{d_e} vt=f(et)∈Rde。具体聚合器则使用 SIF \text{SIF} SIF模型。接下来,将 v t \textbf{v}_t vt送入encoder,并生成隐向量 u t ∈ R d u \textbf{u}_t\in\mathbb{R}^{d_u} ut∈Rdu。最后,解码器使用 u t \textbf{u}_t ut来产生输入 o t ∈ R d e \textbf{o}_t\in\mathbb{R}^{d_e} ot∈Rde,其用于近似 v t \textbf{v}_t vt。
元组 t t t的训练损失函数定义为 l t = ∥ v t − o t ∥ 2 2 l_t=\parallel\textbf{v}_t-\textbf{o}_t\parallel_2^2 lt=∥vt−ot∥22,其是聚合向量和输入向量的均方 l 2 l_2 l2距离。训练时优化encoder和decoder的参数。一旦训练完成,给定一个元组 t t t来生成元组嵌入,将词向量序列 e t \textbf{e}_t et送入聚合器后再送入encocder。对于元组 t t t使用生成的隐表示 u t \textbf{u}_t ut作为元组嵌入向量。
4.2 Seq2Seq \text{Seq2Seq} Seq2Seq
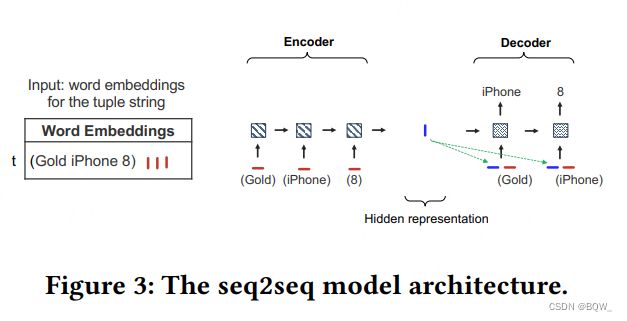
Autoencoder \text{Autoencoder} Autoencoder不能感知顺序。其对输入字符串的任意自排列都会产生相同的聚合向量。 Seq2Seq \text{Seq2Seq} Seq2Seq则是一个序列感知的方法:给定一个词序列 w t w_t wt和其对应的嵌入向量序列 e t \textbf{e}_t et,其重新生成 w t w_t wt。类似于 Autoencoder \text{Autoencoder} Autoencoder, Seq2Seq \text{Seq2Seq} Seq2Seq也是由一个encoder和一个decoder组成的。但是它们都使用 LSTM-RNNs \text{LSTM-RNNs} LSTM-RNNs,其能够处理变长的序列。基于 LSTM \text{LSTM} LSTM的encoder将 e t \textbf{e}_t et中的每个嵌入向量逐个读入来产生隐表示向量 u t \textbf{u}_t ut。
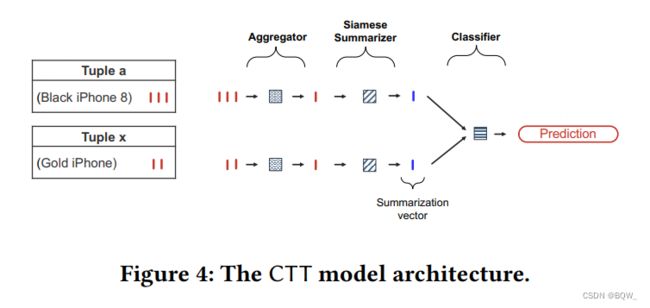
5. Cross-Tuple训练方法
self-reproduction方法会利用单个元组中的信息来生成tuple嵌入向量。 本方法 CTT \text{CTT} CTT则会利用跨元组的信息。关键想法是扰动表 A A A和 B B B中的元组来生成合成标注数据,合成数据是一个tuple对 ( t i , t j ) (t_i,t_j) (ti,tj)的集合,具有匹配和不匹配的标签。使用该数据来训练一个深度学习模型来产生tuple嵌入,这样匹配的tuple对嵌入向量更加接近,而不匹配tuple对的嵌入向量则彼此远离。为了解释 CTT \text{CTT} CTT,先考虑一个具有标签的理想场景,然后展示如何生成合成数据。
5.1 理想模型实现
假设给定一个具有匹配/不匹配标签的tuple对集合 C ⊆ A × B C\subseteq A\times B C⊆A×B。可以训练一个分类器来预测 C C C中的每个对的标签。整个方法分为两个步骤:(1) 给定一个tuple对 ( a ∈ A , b ∈ B ) (a\in A, b\in B) (a∈A,b∈B),将其嵌入序列 e a \textbf{e}_a ea和 e b \textbf{e}_b eb转换为元组嵌入 u a \textbf{u}_a ua和 u b \textbf{u}_b ub。接下来训练一个分类器,其输入为 u a \textbf{u}_a ua和 u b \textbf{u}_b ub,并且预测正确的标签。关键想法是,为了在预测任务上做得好,模型必须学会生成有效的tuple嵌入,以便从tuple对中正确预测匹配。
理想情况下,集合 C C C的生成如下。假设有集合 M ⊆ A × B M\subseteq A\times B M⊆A×B包含所有的匹配对,可以简单的将 M \textbf{M} M中的所有对作为正样本。为了生成负样本数据,可以选择从 A × B A\times B A×B中选择不在 M M M中的tuple对作为负样本。具体来说,令 E = A ∪ B E=A\cup B E=A∪B,对于每个元组 t ∈ E t\in E t∈E,随机选择具有 p p p个元组的集合 S t ⊆ E S_t\subseteq E St⊆E,用来形成一个不匹配对 N t = { ( t , s ) ∣ s ∈ S t } N_t=\{(t,s)|s\in S_t\} Nt={(t,s)∣s∈St}满足每个对 ( t , s ) ∉ M (t,s)\notin M (t,s)∈/M。为每个元组 t ∈ E t\in E t∈E重复这个过程,并合并作为最终的负样本训练数据 N = ∪ { t ∈ E } N t N=\cup_{\{t\in E\}}N_t N=∪{t∈E}Nt。
使用标注数据集 C = M ∪ N C=M\cup N C=M∪N来学习嵌入向量。上图展示了模型的架构,该模型是由三个模块组成:一个aggregator、一个Siamese summarizer和一个classifier。从 C C C中选择一对词嵌入向量序列 e 1 e_1 e1和 e 2 e_2 e2,首先应用aggregator来转换每个嵌入序列为一个固定尺寸的向量,表示为 v 1 ∈ R e d \textbf{v}_1\in\mathbb{R}_e^d v1∈Red和 v 2 ∈ R e d \textbf{v}_2\in\mathbb{R}_e^d v2∈Red。使用 SIF \text{SIF} SIF模型作为嵌入序列的aggregator。接下来,对于 v 1 \textbf{v}_1 v1和 v 2 \textbf{v}_2 v2使用两层前馈网络的Siamese summarizer,生成摘要向量 u 1 ∈ R d u \textbf{u}_1\in\mathbb{R}^{d_u} u1∈Rdu和 u 2 ∈ R d u \textbf{u}_2\in\mathbb{R}^{d_u} u2∈Rdu。将 u 1 \textbf{u}_1 u1和 u 2 \textbf{u}_2 u2的差值的绝对值向量送入至两层前馈网络的classifier,用于预测输入对是匹配还是不匹配。
训练目标是学习两个summarizer的模型参数。使用Siamese网络来缩减模型的容量,即两个summarizer使用相同的模型参数。
5.2 近似理想模型实现
为了实现上面提及的理想方法,需要预先知道所有的匹配对 M ⊆ A × B M\subseteq A\times B M⊆A×B。然而,这意味着早已经解决了实体匹配问题。接下来提出了一种数据生成程序,用于在不访问 M M M的情况下来近似理想训练数据。令 E = A ∪ B E=A\cup B E=A∪B。对于每个 t ∈ E t\in E t∈E,必须生成一个正样本训练实例和 p p p个负样本实例。
使用一个简单但高效的启发式方法来生成正样本对。给定一个元组 t t t,通过拼接来获得单词序列 w t w_t wt。需要生成一个与 t t t高概率匹配的元组 t ′ t' t′。然而,并不知道哪个元组匹配 t t t。为了解决这个难题,随机从 w t w_t wt中选择单词子集来生成合成匹配元组字符串,并表示为 w t ′ w_t' wt′。因为 w t ′ w_t' wt′是从 w t w_t wt中选择的,为这个样本对 ( w t , w t ′ ) (w_t,w_t') (wt,wt′)关联标签1来表示其匹配。改变重叠字符串的比例可以改变匹配的可能性。在本文的实验中,确保合成的元组至少有60%的覆盖。
为了生成一个负实例,从 E E E中随机的选择一个元组 s s s,拼接 s s s的属性值来获得 w s w_s ws。因为元组 s s s是随机选择的,其很有可能与 t t t是不匹配的,因为相比于不匹配,匹配是稀缺的。关联标签0表示样本对 ( w t , w s ) (w_t,w_s) (wt,ws)是不匹配的。重复这个过程 p p p次来从 E E E中选择 p p p个元组作为负实例。对于表 A A A和 B B B中的每个元组重复这个过程,并最终将每个元组的训练实例集合作为近似训练数据。一旦有了近似数据就能像理想的训练场景中一样训练 CTT \text{CTT} CTT模型。
6. Triplet Loss最小化方法
该方法采用triplet loss方法。具体来说,首先会生成一个tripelts集合的训练数据。每个triplet可以表示为 ( x , y , z ) (x,y,z) (x,y,z),其中 x x x是一个tuple, y y y是与 x x x匹配的tuple, z z z是不匹配的tuple。对于表 A A A或者 B B B的每个元组 t i t_i ti,从 t i t_i ti中至多随机移除40%的单词来生成 L L L扰动 p i , 1 , … , p i , L p_{i,1},\dots,p_{i,L} pi,1,…,pi,L。然后挑选 L L L个随机元组 n i , 1 , … , n i , L n_{i,1},\dots,n_{i,L} ni,1,…,ni,L。最终,生成 L L L个triplets: { ( t i , p i , 1 , n i , 1 ) , … , ( t i , p i , L , n i , L ) } \{(t_i,p_{i,1},n_{i,1}),\dots,(t_i,p_{i,L},n_{i,L})\} {(ti,pi,1,ni,1),…,(ti,pi,L,ni,L)}。
随后,训练一个深度学习模型为 x x x, y y y和 z z z产生向量嵌入,其中 x x x和 y y y彼此接近,而 x x x和 z z z则彼此远离。使用预训练的 BERT \text{BERT} BERT来产生向量嵌入,并且 SBERT \text{SBERT} SBERT方法用于元组聚合。Triplet loss的定义如下:
m a x ( ∥ E m b ( x ) − E m b ( y ) ∥ 2 − ∥ E m b ( x ) − E m b ( z ) ∥ 2 + a l p h a , 0 ) max(\parallel Emb(x)-Emb(y)\parallel^2-\parallel Emb(x)-Emb(z)\parallel^2+alpha,0) max(∥Emb(x)−Emb(y)∥2−∥Emb(x)−Emb(z)∥2+alpha,0)
Emb(x) \text{Emb(x)} Emb(x)提供元组 x x x的嵌入向量, α \alpha α是确保正负元组对的距离边界的超参数。
7. Hybrid方法

到目前为止所讨论的单个辅助任务都能够计算tuple嵌入向量:self-reproduction、cross-tuple training或者triplet loss minimization。可以进一步开发更混合的方法,其能够使用两个或者更多的辅助任务。
举例来说,能够合并 Autoencoder \text{Autoencoder} Autoencoder和 CTT \text{CTT} CTT来产生元组嵌入,其能够同时考虑元组内信息和跨元组信息。这样做,使用由两个子训练任务堆叠的训练过程。给定 A A A和 B B B中元组的词嵌入序列,训练一个 Autoencoder \text{Autoencoder} Autoencoder模型 M 1 M_1 M1和一个 CTT \text{CTT} CTT模型 M 2 M_2 M2。 M 2 M_2 M2的训练步骤如前描述,除了使用一个原始 CTT \text{CTT} CTT模型的修改版本,其没有使用 SIF \text{SIF} SIF,而是使用 M 1 M_1 M1的encoder作为 M 2 M_2 M2的aggregator。
需要注意的是, M 1 M_1 M1和 M 2 M_2 M2是通过先训练 M 1 M_1 M1然后再训练 M 2 M_2 M2进行堆叠的,而不是联合训练 M 1 M_1 M1和 M 2 M_2 M2。原因是希望保持两个模型 M 1 M_1 M1和 M 2 M_2 M2分离来避免交叉元组信息扩散到 M 1 M_1 M1的模型参数中,这样模型 M 1 M_1 M1就不能很好的摘要元组内的信息了。一旦训练完成,堆叠模型可以用于生成元组嵌入。给定 A A A或者 B B B中元组 t t t的嵌入序列 e t \textbf{e}_t et,将 e t \textbf{e}_t et送入aggregtor后,再送入 M 2 M_2 M2的Siamese summarizer,并使用其输入作为tuple嵌入向量。
上图解释了提出的架构,将其简单的称为 Hybrid \text{Hybrid} Hybrid。
8. Vector Pairing \text{Vector Pairing} Vector Pairing选择
目前讨论的许多方法都是计算tuple的嵌入向量,现在讨论vector pairing。令 S S S和 T T T为表 A A A和 B B B中对应tuple嵌入向量的表。目标是使用 Q ( S , T ) Q(S,T) Q(S,T)来快速的搜索 S S S和 T T T,从而发现相似的向量对。这里采用非深度学习的方法,其可以分为:基于哈希(hash-based)、基于排序、基于相似度(similarity-based)以及复合方法(composite)。这里仅介绍基于哈希、基于相似度和复合方法。
8.1 Hashing-based Pairing
该方法会对每个tuple的向量表示进行哈希化,并保留共享相同哈希值的tuple对。其能够被高效的实现。因为tuple嵌入是数值向量,Locality Sensitive Hashing(LSH)是一个很好的选择,其能够以高概率将相似的items散列到相同的桶中。 DeepER \text{DeepER} DeepER和 AutoBlock \text{AutoBlock} AutoBlock使用了基于hashing-based的pairing。
8.2 Similarity-based Pairing
基于 cosine \text{cosine} cosine或 Euclidean \text{Euclidean} Euclidean距离这种相似度,仅保留非常相似的tuple对。一种选择是保留超过相似度阈值的tuple对,另一种则是保留 k k k个最近邻。举例来说,使用 cosine \text{cosine} cosine度量,每个元组 a i ∈ A a_i\in A ai∈A具有tuple嵌入向量 u a i \textbf{u}_{a_i} uai,先计算 u a i \textbf{u}_{a_i} uai与每个 u ∈ T u\in T u∈T的 cosine \text{cosine} cosine分数。然后挑选具有 k k k个最高 cosine \text{cosine} cosine分数的tuple B ′ ⊆ B B'\subseteq B B′⊆B。最终,形成 k k k个tuple对 ( a i , b j ) (a_i,b_j) (ai,bj),其中 b j ∈ B ′ b_j\in B' bj∈B′将包括在候选集合中。
8.3 Composite Pairing
该方法会合并上面的方法。举例来说,先使用 LSH \text{LSH} LSH来获得一个哈希桶,然后在每个桶中选择最高cosine相似度的分数。
四、代表性的深度学习解决方案

先前的章节描述了blocking的深度学习解决方案的解空间,其给出了大量的解决方案。这里会选择8个代表性的解决方案进行深入评估,其对应于各种复杂度的深度学习模型。这8个解决方案在tuple嵌入模块上的选择具有显著的不同,并进行了对应的命名。
每个解决方案都使用 fastText \text{fastText} fastText,因为其能够处理单词形态学以及袋外词,并且对错误拼写具有鲁棒性。因此,它是一个词嵌入向量模块的好选择,并被用于多个近期的用于实体匹配的深度学习方法中。基于transformer的解决方案中, SBERT \text{SBERT} SBERT和 Trans-encoder \text{Trans-encoder} Trans-encoder使用 BPE(Byte Pair Encoding) \text{BPE(Byte Pair Encoding)} BPE(Byte Pair Encoding)。此外,所有8个解决方案的vector pairing模块使用top-k cosine相似度。其可以控制blocking的输出尺寸,其在实际应用中是非常理想的性质。上表给定了每个组件实例化的摘要。
五、评估
-
数据集
实验使用来自不同领域和不同规模的数据集,除了Hospital以外都是公开数据集,并已经用于了先前的 EM \text{EM} EM工作中。其中包含6个结构化实体匹配数据集,3个
textual实体匹配数据集,dirty数据集则主要来自于对应的结构化数据,然后将属性值注入至错误的属性下。此外,本文还会在三个真实数据集上进行额外的实验: Restaurants \text{Restaurants} Restaurants、 Book \text{Book} Book和 Cora \text{Cora} Cora。 -
方法
评估了8个有代表性的深度学习解决方案、以及一些
state-of-the-art的深度学习和非深度学习解决方案。令 C C C是候选集合(在两个表 A A A和 B B B上blocking输出),并令 G \text{G} G表示 A A A和 B B B真正匹配的集合。那么 recall \text{recall} recall则称为 ∣ G ∩ C ∣ / ∣ G ∣ |G\cap C|/|G| ∣G∩C∣/∣G∣,候选集合的尺寸 (CSSR) \text{(CSSR)} (CSSR)则是通过 ∣ C ∣ / ∣ A × B ∣ |C|/|A\times B| ∣C∣/∣A×B∣来衡量。理想情况下,期望有高 recall \text{recall} recall、低 CCSR \text{CCSR} CCSR以及低的运行时间。
1. Recall \text{Recall} Recall和 CSSR \text{CSSR} CSSR
首先从 Recall \text{Recall} Recall和 CSSR \text{CSSR} CSSR来评估8种深度学习解决方案。因此,绘制了 R-C(recall-candidate set size ration) \text{R-C(recall-candidate set size ration)} R-C(recall-candidate set size ration)曲线,展示了 vector pairing \text{vector pairing} vector pairing模块中这两个量如何随着top-k变换的。
1.1 结构化数据
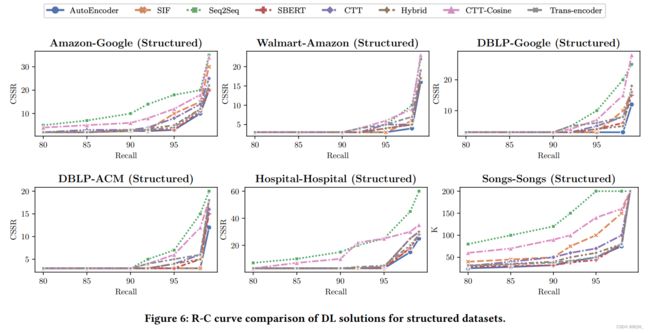
上图是6个结构化数据的 R-C \text{R-C} R-C曲线。除了Song-Song数据集外, x x x轴是 recall \text{recall} recall, y y y轴是 CSSR \text{CSSR} CSSR。由于Song-Song数据集的尺寸非常大,会导致 CSSR \text{CSSR} CSSR很小。因此,该数据集上只报告 K \text{K} K,随着 K K K的增加, recall \text{recall} recall和 CSSR \text{CSSR} CSSR也会增加。 R-C \text{R-C} R-C曲线越接近右下角表示效果越好,因为其对应着更小的候选集尺寸以及更高的召回。
上图也展示了8个解决方案能够在相对小的候选集上实现高的召回。 Autoencoder \text{Autoencoder} Autoencoder在所有数据集上都实现了最好的表现。 Hybrid \text{Hybrid} Hybrid尽管在所有数据集上表现都不错,但是仅在 Walmart-Amazon \text{Walmart-Amazon} Walmart-Amazon上实现了最好的效果。消融实验表明这是因为使用近似训练数据的质量导致的。 Seq2Seq \text{Seq2Seq} Seq2Seq在结构化和dirty数据集上被其他解决方案显著超越,包括 SIF \text{SIF} SIF。这是由于在结构化和dirty数据集中的tuples相对较短。在这些表格中不同属性值的数量有限。此外,结构化数据集中不存在训练信息,不同于文本数据集。相反,在文本数据集中词表要大很多,其中 Seq2Seq \text{Seq2Seq} Seq2Seq表现的也更好。
1.2 Textual数据
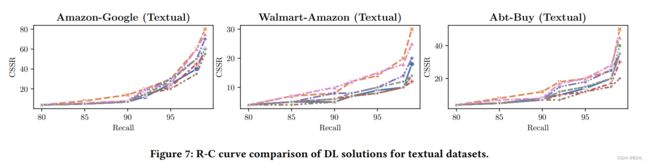
上图展示了textual数据集上的 R-C \text{R-C} R-C曲线。各种解决方案的效果非常相似, R-C \text{R-C} R-C曲线也彼此接近。相比于结构化数据,这些 R-C \text{R-C} R-C曲线离右下角更远。这意味着对于这些包含长文本属性的数据集来说,深度学习方案从这些tuple中抽取有用的信息并生成好的blocking结果更具有挑战性。然后,正如后面的实验展示的,该场景中深度学习方法仍然优于非深度学习方法。图中显示 Hybrid \text{Hybrid} Hybrid的平均结果是最好的,捕获交叉元组信息有助于生成更好的元组嵌入。 SBERT \text{SBERT} SBERT表示也非常好。有趣的是, Autoencoder \text{Autoencoder} Autoencoder仅使用元组的信息就接近第三名。
1.3 Dirty数据

上图展示了dirty数据集上的 R-C \text{R-C} R-C曲线,这些数据是都结构化数据进行综合破坏后得到的。
作者在dirty数据集的两个不同的变体上执行了实验。图8展示了dirty数据集中的 R-C \text{R-C} R-C曲线,这些数据是对结构化数据进行综合破坏后得到的。
2. Runtime
下面会在运行时间方面评估解决方案,主要专注在tuple嵌入模块的训练时间和向量匹配模块的时间。
2.1 tuple嵌入模块的训练时间

上表展示了每个数据集的训练时间,其中 SIF \text{SIF} SIF不涉及学习, SBERT \text{SBERT} SBERT使用预训练模型。 Seq2Seq \text{Seq2Seq} Seq2Seq的训练时间比其他方法的时间高一个数量级。不幸的是, LSTMs \text{LSTMs} LSTMs由于其天然的序列属性无法轻易的并行化。其他的一些解决方案非常高效,并且在大数据集上能够很好的缩放。 Autoencoder \text{Autoencoder} Autoencoder在结构化和dirty数据上效果最好,特别是训练有效性上。
2.2 向量匹配模块
基于 FAISS \text{FAISS} FAISS的向量匹配模块,在 GPU \text{GPU} GPU加速下除了 Song-Song \text{Song-Song} Song-Song数据集以外,生成候选的时间都小于1分钟, Song-Song \text{Song-Song} Song-Song则小于35分钟。
3. 现有深度学习解决方案比较

已知有三个用于blocking的深度学习解决方案: DeepER \text{DeepER} DeepER、 AutoBlock \text{AutoBlock} AutoBlock和 DeepBlock \text{DeepBlock} DeepBlock。 DeepBlock \text{DeepBlock} DeepBlock只使用了少量的 DL \text{DL} DL,并在一篇4页的论文中进行了描述,没有足够的细节进行实现。 DeepER \text{DeepER} DeepER的效果显然差于本文的解决方案。最终,选择比较本文方案与 AutoBlock \text{AutoBlock} AutoBlock。 AutoBlock \text{AutoBlock} AutoBlock使用标注数据集来学习tuple的嵌入。对于每个tuple,其使用 LSH \text{LSH} LSH来从候选中检索出top-K个最近邻。
上图展示了 AutoBlock \text{AutoBlock} AutoBlock、 Autoencoder \text{Autoencoder} Autoencoder和 Hybrid \text{Hybrid} Hybrid的结果。实验会重复5次并报告平均召回。曲线 AB-5 \text{AB-5} AB-5、 AB-10 \text{AB-10} AB-10和 AB-15 \text{AB-15} AB-15展示了使用5%、10%和15%标注数据训练 AutoBlock \text{AutoBlock} AutoBlock的结果。 Autoencoder \text{Autoencoder} Autoencoder和 Hybrid \text{Hybrid} Hybrid的效果都优于 AutoBlock \text{AutoBlock} AutoBlock。此外,还评估了 AutoBlock \text{AutoBlock} AutoBlock的变体 AB-Hy \text{AB-Hy} AB-Hy,其使用 Hybrid \text{Hybrid} Hybrid生成的近似标注数据来训练 AutoBlock \text{AutoBlock} AutoBlock。这个变体接近 Hybrid \text{Hybrid} Hybrid,但仍然低于两种接近方案。