最新 ICCV | 35个GAN应用主题梳理,最全GAN生成对抗论文汇总
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
在最新的视觉顶会ICCV 2021会议中,涌现出了大量基于生成对抗网络GAN的论文,广泛应用于各类视觉任务;本文在此做尽可能的梳理汇总!
下述论文已分类打包好!后台回复 ICCV (长按红字、选中复制)获取分类、按文件夹汇总好的论文集,gan起来吧!!!
梳理不易,麻烦各位看官,转发、分享、在看三连,多多鼓励小编!!!
一、GAN改进
1、Dual Contrastive Loss and Attention for GANs
使用大规模图像数据集时,生成对抗网络 (GAN) 在无条件图像生成方面效果非常不错。但生成的图像仍然很容易被甄别出来,尤其是在具有高方差的数据集(例如卧室、教堂)上。
本文提出一种新的双重对比损失,并表明通过这种损失,判别器可以学习更通用和可区分的表示来激励生成质量。此外,重新审视了注意力并在生成器中对不同的注意力块进行了广泛的实验。发现注意力仍然是成功生成图像的重要模块,即使它在最近的先进模型中未使用。最后,研究了判别器中不同的注意力架构,并提出了一个参考注意力机制。通过结合这些措施,在几个基准数据集上将FID提高了至少 17.5%,在合成场景上获得了更显著的提升(在 FID 中高达 47.5%)。

2、Dual Projection Generative Adversarial Networks for Conditional Image Generation
条件生成对抗网络 (cGAN) 扩展了无条件 GAN ,可以从样本中学习联合数据标签分布,是能够生成高保真图像的强大生成模型。训练的挑战在于将类信息合理地注入到它的生成器和判别器中。
提出了一个双投影 GAN (Dual Projection,P2GAN)学习在数据匹配和标签匹配之间取得平衡的模型;提出了一种改进的、带辅助分类的 cGAN 模型,通过最小化 f-divergence 来直接对齐假和真条件 P(class|image)。多个数据集(包括 CIFAR100、ImageNet 和 VGGFace2)的实验证明了有效性。
3、Focal Frequency Loss for Image Reconstruction and Synthesis
生成模型的不断发展,让图像重建和合成取得了显著进步。尽管如此,真实图像和生成图像之间仍可能存在差距,特别是在频域。
本研究表明缩小频域差距可以进一步改善图像重建和合成质量,提出一种新的focal frequency loss,可以作为现有空间损失的补充。
实验表明它可以在感知质量和定量方面改进流行模型(如 VAE、pix2pix 和 SPADE),在 StyleGAN2 上同样潜力极大。

4、Gradient Normalization for Generative Adversarial Networks
本文提出一种新的归一化方法:梯度归一化(GN),以解决生成式对抗网络(GANs)梯度不稳定问题。与现有的梯度惩罚和谱归一化等不同,本文的GN算法只对判别器函数施加梯度范数约束;在4个数据集上进行的大量实验表明,方法在Frechet Inception Distance和Inception Score两方面都可以有优越性。

5、F-Drop&Match: GANs with a Dead Zone in the High-Frequency Domain
生成式对抗网络缺乏精确复制自然图像高频成分的能力。为了缓解这个问题,本文引入了两种新的训练技术,称为频率下降(F-Drop)和频率匹配(F-Match)。实验证明F-Drop和F-Match的结合提高了gan在频域和空间域的生成性能。
6、Latent Transformations via NeuralODEs for GAN-based Image Editing
高保真语义图像编辑的最新进展里,很多研究工作依赖于生成模型(例如 StyleGAN)解耦的潜在空间。最近的工作表明,可通过线性移动和潜在方向来实现人脸属性的可控编辑。对于许多更复杂的变化因素,本文工作展示了可训练神经 ODE 流的非线性潜码操作的优越性。毕竟大量数据集某些属性操作仅通过线性移位操作并不简单。

7、Detail Me More: Improving GAN’s photo-realism of complex scenes
生成模型可以合成单个物体对象的逼真图像。例如,对于人脸,算法学习对人脸局部形状和阴影进行建模,即眉毛、眼睛、鼻子、嘴巴、下巴线等的变化。这是可能的,因为所有的人脸都有两个眉毛,两个眼睛、鼻子和嘴巴,大致在同一位置。然而,复杂场景的建模更具挑战性,因为场景组件及其位置因图像而异。例如,起居室包含属于许多可能类别和位置的不同数量的产品,例如,一盏灯可能存在也可能不存在于无数可能的位置。
本文提出在生成对抗网络(GAN)中添加一个“代理”模块来解决这个问题。代理任务是在图像区域中调解多个判别器的使用。例如,如果在场景的特定区域检测到或需要一盏灯,代理会为该图像块分配一个细粒度的灯判别器。这可以促使生成器学习灯的形状和阴影模型。由此产生的多细粒度优化问题能够合成具有与单个对象图像几乎相同的真实感水平的复杂场景。在几种 GAN 算法(BigGAN、ProGAN、StyleGAN、StyleGAN2)、图像分辨率(2562 到 10242)和数据集上证明了所提出的方法的通用性。方法比当下 GAN 算法有了显著改进。

8、EigenGAN: Layer-Wise Eigen-Learning for GANs
生成对抗网络 (GAN) 的不同层有不同的图像语义。很少有 GAN 模型具有明确的维度来控制特定层中表示的语义属性。
本文提出EigenGAN,能够无监督地从不同的生成器层挖掘可解释和可控的维度。代码:https://github.com/LynnHo/EigenGAN-Tensorflow

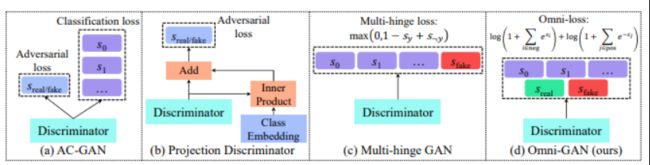
9、Omni-GAN: On the Secrets of cGANs and Beyond
条件生成对抗网络 (cGAN) 是生成高质量图像的强大工具,但现有方法大多性能不令人满意或存在模式坍塌的风险。
本文介绍 OmniGAN,是 cGAN 的一种变体,针对训练合适判别器的问题。关键是要确保判别器接受强监督并适度正则化以避免坍塌。在 ImageNet 数据集上创造了新的记录,对于 128 和 256 的图像大小,Inception 分数分别为 262.85 和 343.22,比之前的记录高出 100 多个点。
10、Towards Discovery and Attribution of Open-world GAN Generated Images
随着生成对抗网络 (GAN) 的最新进展,媒体和视觉取证需要识别生成图像。现有工作仅限于封闭集场景,无法推广到不存在训练期间的 GAN。提出一种迭代算法,由多个组件组成,包括网络训练、分布外检测、聚类、合并和细化步骤。

11、Unsupervised Image Generation with Infifinite Generative Adversarial Networks
图像生成在计算机视觉中得到大量研究,其中一项核心挑战是无监督图像生成。生成对抗网络 (GAN) 作为一种隐式方法在这个方向上取得了巨大的成功,被广泛采用。
GAN 存在模式坍塌、非结构化潜在空间、无法计算似然等问题。本文提出一种新的无监督非参数方法,称为infinite conditional GANs 或 MIC-GANs,一起解决几个 GAN 问题,旨在用简约的先验知识生成图像。github.com/yinghdb/MICGANs。
二、图像编辑-基于StyleGAN
12、StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery
受 StyleGAN 启发,最近许多工作都集中在了解如何使用 StyleGAN 的潜在空间来操纵图像生成。但为了挖掘语义上有意义的潜在表示,通常涉及到一些人工,甚至是打标签的图像数据。
这项工作探索利用最近引入的对比语言图像预训练 (CLIP) 模型,以便为 StyleGAN 图像处理开发一个基于文本的界面。提出一种将文本映射到 StyleGAN 风格空间中的方法,实现交互式文本驱动的图像操作。

13、Diagonal Attention and Style-based GAN for Content-Style Disentanglement in Image Generation and Translation
图像生成模型中的重要研究课题之一是,解耦空间内容和风格,以便对其进行单独控制。虽然 StyleGAN 可以从随机噪声中生成内容特征向量,但由此产生的空间内容控制主要针对微小的空间变化,全局内容和风格的解耦并不完全。
受对归一化和注意力的启发,提出一种新的层次自适应空间注意力(DAT)层,操纵风格和内容从粗到细的层次解耦。此外,生成器可轻松集成到 GAN逆映射框架中,从而可以灵活控制来自多域图像转换任务的内容和风格。

14、ReStyle: A Residual-Based StyleGAN Encoder via Iterative Refinement
生成对抗网络 (GAN)在无条件图像生成能力有显著提升。逆映射,将图像转化为经过训练的 GAN 的相应潜码表示,是有意义的,这样可以操纵真实图像。
这项工作提出一种新的逆映射方案,通过引入迭代细化机制,扩展当前基于编码器的逆映射方法。与当前最先进的方法相比,基于残差的编码器 ReStyle 提高了准确性,推理时间的增加可以忽略不计。https://yuval-alaluf.github.io/restyle-encoder/

三、图像编辑-逆映射
15、From Continuity to Editability: Inverting GANs with Consecutive Images
本文通过将连续图像(例如,视频帧或具有不同姿势的同一个人)引入GAN逆映射过程,大量实验表明,方法在真实图像数据集和合成数据集的重建保真度和可编辑性方面明显优于最先进的方法。源代码
https://github.com/cnnlstm/InvertingGANs_with_ConsecutiveImgs

16、GAN Inversion for Out-of-Range Images with Geometric Transformations
对图像的语义编辑,GAN 逆映射方法找到与预训练 GAN 模型域对齐的域潜码至关重要。但潜码只能用于与 GAN 模型的训练图像对齐的范围内图像。
对与 GAN 模型训练图像不对齐的、超出范围的图像,本文提出BDInvert,一种新的 GAN 逆映射方法,用于进行语义编辑。

四、图像编辑-人脸
17、A Latent Transformer for Disentangled Face Editing in Images and Videos
高质量人脸图像编辑是电影后期制作行业的挑战,需高度控制和 ID身份信息保留。此前试图解决这个问题的方法可能有人脸属性纠缠、ID丢失问题。
本文提出通过 StyleGAN 生成器的潜在空间来编辑人脸属性,训练专用的潜在转换网络,并在损失函数中加入显式解耦和ID保留损失项。并将方法推广到视频。
源代码https://github.com/InterDigitalInc/latent-transformer

五、图像编辑-语义生成
18、Collaging Class-specific GANs for Semantic Image Synthesis
提出一种高分辨率语义图像合成方法,它由一个基本图像生成器和多个特定于类的生成器组成,生成器基于分割图生成高质量图像。
为进一步提高不同对象的质量,通过特定于类展开单独训练,构建一组生成对抗网络 (GAN)。这有几个好处,包括 :每个类专用权重;每个模型更集中对齐数据;并轻松操纵场景中的特定对象。实验表明,方法可生成高分辨率高质量图像,同时特定于类的生成器具有对象级控制的灵活性。
https://yuheng-li.github.io/CollageGAN/

19、Image Synthesis via Semantic Composition
本文提出一种基于语义布局合成逼真图像的方法,方法假设对于具有相似外观的对象,它们共享相似的表示。根据它们的外观相关性建立区域之间的依赖关系,产生空间变化和相关表示。基于这些特征,提出一个通过空间条件计算(具有卷积和归一化)构造的动态加权网络。除了保留语义差异之外,给定的动态网络还增强了语义相关性,有利于全局结构和细节合成。
20、Image Synthesis from Layout with Locality-Aware Mask Adaption
针对生成以布局(一组具有对象类别的边界框)为条件的图像任务。现有方法构建布局-掩码-图像的流程,物体掩码会单独生成,形成语义分割掩码(layout-to-mask),由此生成新图像(掩码到图像)。但是,布局中的重叠框会导致对象掩膜重叠,降低清晰度并导致混乱。
本文认为生成干净且语义清晰的语义掩码非常重要,提出局部感知掩码适应 (LAMA) 模块以适应生成中重叠或附近的物体掩膜。

六、图像恢复-超分
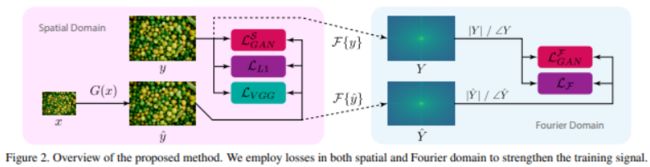
21、Fourier Space Losses for Efficient Perceptual Image Super-Resolution
许多超分辨率 (SR) 模型仅针对精度效果进行优化,模型庞大、缺乏效率。大模型在实际应用中通常不实用,本文提出新的损失函数,以从更有效的模型中实现具有高感知质量的 SR。
利用傅立叶空间监督损失来改进从丢失的高频 (HF) 内容,并设计直接在傅立叶域的判别器架构以更好地匹配目标 HF 分布。与最先进的感知 SR 方法 RankSRGAN 和 SRFlow 相比,分别快 2.4 倍和 48 倍。
七、图像恢复-反光去除
22、Location-aware Single Image Reflection Removal
本文提出一种新的基于位置感知的图像反射去除方法。网络设计了一个反射检测模块来回归概率反射置信度图,将多尺度拉普拉斯特征作为输入。
https://github.com/zdlarr/Location-aware-SIRR

23、V-DESIRR: Very Fast Deep Embedded Single Image Reflection Removal
实际生活中,图像可能会由于不需要的反射出现损坏情况,大多数现有方法要么通过妥协处理速度和内存要求来专注于恢复质量,要么专注于在非常低的分辨率下消除反射,从而限制了它们的实际部署能力。
提出一个轻量级的深度学习模型,用一种新的尺度空间架构来去除反射。方法分两个阶段处理损坏的图像,低尺度子网络 (LSSNet) 处理最低尺度,渐进推理阶段处理更高尺度。与最新的最先进算法 RAGNet 相比,速度提高了 20 倍,参数数量减少了 50 倍。

八、图像恢复-光斑去除
24、How to Train Neural Networks for Flare Removal
当相机对上了强光源时,生成的照片可能包含镜头眩光伪影。耀斑以多种模式出现(光晕、条纹、渗色、混浊等),这种外观的多样性使得消除耀斑具有挑战性。现有方案对其几何形状或亮度做强假设,因此仅适用于一小部分耀斑。且由于缺乏训练数据,尚未广泛应用于消除眩光。
本文模拟耀斑的光学原因,生成耀斑损坏和干净图像的合成对。从而使训练神经网络消除镜头眩光成为可能。实验表明,数据合成方法对于准确去除眩光至关重要,且模型可推广到不同场景、光照条件和相机的真实镜头眩光去除。

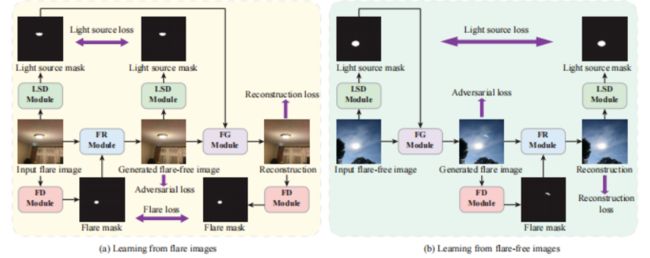
25、Light Source Guided Single-Image Flare Removal from Unpaired Data
相机内部光线的反射、散射,可能使得拍摄图像出现眩光伪影。耀斑可能以各种形状、位置和颜色出现,因此从图像中检测和完全去除它们是非常具有挑战性的。
本文首先分别检测光源区域和耀斑区域,根据光源感知引导去除耀斑伪影。通过学习两种类型区域之间的潜在关系,方法可以从图像中去除不同类型的耀斑。此外,没有使用难以收集的成对训练数据,而是提出第一个不成对的耀斑去除数据集和新的循环一致性约束,以避免手工标注成本。
九、图像恢复-去除阴影
26、DC-ShadowNet: Single-Image Hard and Soft Shadow Removal Using Unsupervised Domain-Classifier Guided Network
单图像去除阴影仍是一个悬而未决的问题。大多数现有基于学习的方法用监督学习,要大量成对的图像(阴影和相应的非阴影图像)进行训练。最近一种无监督方法 MaskShadowGAN 解决了这个限制。然而,它需要一个二值掩码来表示阴影区域,不适用于软阴影。
本文提出一种无监督的域分类器引导的阴影去除网络 DC-ShadowNet。具体来说,将阴影/无阴影域分类器集成到生成器及其判别器中,使它们能够专注于阴影区域。引入基于物理的无阴影色度、阴影鲁棒感知特征和边界平滑度的新损失。

十、图像恢复-水下图像失真去除
27、Learning to Remove Refractive Distortions from Underwater Images
水面波动、折射失真,严重降低水下场景的图像质量。提出用于恢复无失真水下图像的引导网络(DG-Net)。关键思想是使用失真图来指导网络训练。在几个真实和合成的水下图像数据集上评估,包括无人机拍摄的室外游泳池图像和手机摄像头拍摄的室内水族馆图像。

十一、图像恢复-修复
28 WaveFill: A Wavelet-based Generation Network for Image Inpainting
图像修复旨在用逼真的内容完成图像缺失或损坏的区域。当前流行的方法通过使用生成对抗网络重建具有较好感知质量的结果。但重建损失和对抗性损失侧重于合成不同频率的内容,简单地将它们一起应用通常会导致频率间的冲突。
本文引进WaveFill,基于小波修复,将图像分解为多个频段,并分别明确地填充每个频段中的缺失区域。WaveFill 使用离散小波变换 (DWT) 分解图像,自然地保留空间信息。它将L1重建损失应用于分解的低频段,将对抗性损失应用于高频段,从而在完成空间域图像的同时有效地减轻频间冲突。为了解决不同频段的修复不一致问题并融合具有不同统计数据的特征,设计一种新的归一化方案,可有效对齐和融合多频特征。大量实验表明WaveFill 在定性和定量上的优越性

29 Painting from Part
本文研究基于图像的局部去绘制、修复图像,涉及图像内修复和外修复。为充分利用来自局部区域的信息和来自全局域(数据集)的信息,提出一种新的绘制方法,包括三个阶段 : 噪声重启、特征重绘、局部细化,利用特征级别、局部区域级别、生成对抗网络的强大表示能力来绘制整个图像。
https://github.com/zhenglab/partpainting

30 High-Fidelity Pluralistic Image Completion with Transformers
卷积神经网络 (CNN)在图像补全(Image completion)方面取得了巨大进步。但由于一些固有特性(例如,局部归纳先验),CNN 在理解全局结构或支持多元补全方面表现不佳。最近,transformer 展示了在建模长期关系和生成不同结果方面的能力,但计算复杂度太大,阻碍处理高分辨率图像。
本文使用transformer 进行外观先验重建,使用 CNN 进行纹理补充

31 Image Inpainting via Conditional Texture and Structure Dual Generation
通过引入结构先验,深度生成方法在图像修复方面取得了相当大的进展。然而,由于在结构重建过程中缺乏与图像纹理的适当交互,目前的解决方案无法处理大损坏的情况,并且通常会出现失真结果。
本文提出一种用于图像修复的新型双流网络,以耦合方式进行结构约束的纹理合成,以及纹理引导的结构重建,可以更好地相互利用以获得更合理的生成。此外,为增强全局一致性,设计双向门控特征融合(Bi-GFF)模块来交换和组合结构和纹理信息,并开发上下文特征聚合(CFA)模块。CelebA、Paris StreetView 和 Places2 数据集上的定性和定量实验证明了所提出方法的优越性。
https://github.com/Xiefan-Guo/CTSDG
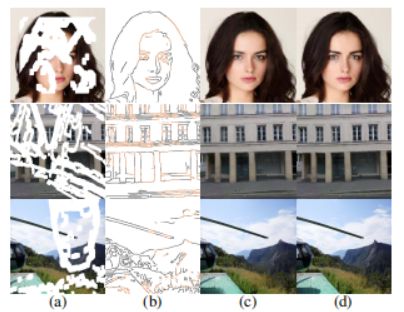
32 Learning High-Fidelity Face Texture Completion without Complete Face Texture
对于人脸纹理补全,通常用多视图成像系统或 3D 扫描的一些完整纹理进行监督学习。本文尝试在不使用任何完整纹理情况下完成人脸纹理补全,以无监督方式、利用大量不同的人脸图像(例如,FFHQ)训练模型。
提出DSD-GAN,在 UV 空间和图像空间中应用两个判别器,以互补的方式学习结构和纹理细节。

33 Learning a Sketch Tensor Space for Image Inpainting of Man-made Scenes
本文研究修复人造场景的任务。由于难以保留图像的视觉模式,例如边缘、线条和连接点,因此并不简单。
为此本文用于修复人造场景的 Sketch Tensor (ST) 空间,为促进结构细化,提出一种多尺度修复(MST)网络,新的编码器-解码器结构:编码器从输入图像中提取线条和边缘,将它们投影到 ST 空间中。从这个空间,解码器学习恢复输入图像。大量实验验证有效性。

34 Parallel Multi-Resolution Fusion Network for Image Inpainting
传统的深度图像修复方法基于自编码器架构,其中图像的空间细节将在下采样过程中丢失,导致生成结果不佳。此外,自编码器架构的深层结构信息和浅层纹理信息不能很好地集成。为此,设计了一个具有多分辨率partial convolution的并行多分辨率修复网络,其中低分辨率分支专注于全局结构,而高分辨率分支专注于局部纹理细节。实验结果表明,方法可有效地融合结构和纹理信息,比最先进的方法产生更逼真的结果。
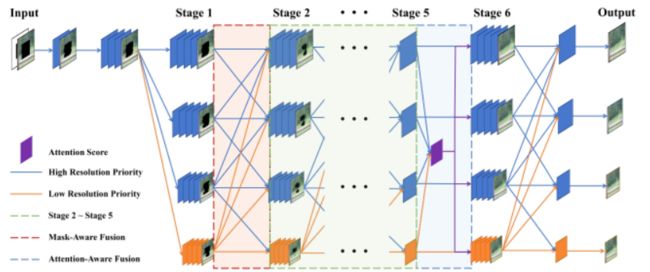
35 CR-Fill: Generative Image Inpainting with Auxiliary Contextual Reconstruction
最近的图像修复方法使用注意力机制层来促使生成器从已知区域借用特征块来完成缺失区域。由于缺少对缺失区域和已知区域之间对应关系的监督信号,可能无法找到合适的参考特征,导致结果出现伪影。此外,它在推理过程中计算整个特征图的成对相似度,带来不小的计算开销。
为此,提出辅助上下文重建任务的联合训练,无注意力的生成器同样可以学习到这种借用周边特征去修复的能力,使得输出也合理。辅助分支可以看作是一个可学习的损失函数,即命名为上下文重建(contextual reconstruction ,CR)损失,其中查询参考特征相似性和基于参考的重建器与修复生成器联合优化。
实验结果表明,所提出的修复模型在定量和视觉性能方面优于最先进的模型。
https://github.com/zengxianyu/crfill

十二、图像检测-异常检测
36 Learning Unsupervised Metaformer for Anomaly Detection
图像异常检测 (Anomaly detection,AD) ,解决图像异常的分类或定位问题。本文解决基于重建的图像 AD 方法的两个关键问题,即模型适应性和重建差异性。前者将 AD 模型概括为处理广泛的对象类别,而后者为定位异常区域提供了有用的线索。
方法核心是一个无监督的通用模型,称为 Metaformer,利用元学习模型参数来实现高模型适应能力和实例感知注意力来强调用于定位异常区域的焦点区域,即探索 这些感兴趣区域的重建差距。用工业图像 MVTec AD 数据集上的 SOTA 结果证明方法有效性。

十三、图像检测-拼接伪造
37 Reality Transform Adversarial Generators for Image Splicing Forgery Detection and Localization
许多伪造图像在图像编辑工具和卷积神经网络 (CNN) 的帮助下变得越来越逼真,实际场景中,需要验证侦测这些伪造图像的能力。生成和检测伪造图像的过程与生成对抗网络 (GAN) 的原理类似。
由于伪造图像的修图过程需要抑制篡改伪影并保留结构信息,可视为图像风格变换,本文提出一种假到真变换的“生成器GT” ;为了检测篡改区域,还提出一种基于多解码器单任务策略的定位“生成器GM” 。通过对抗训练两个生成器,模拟伪造者和验证者之间的对抗。

十四、图像检测-deepfake
38 Artificial Fingerprinting for Generative Models: Rooting Deepfake Attribution in Training Data
生成对抗网络( GANs )的不断发展,逼真图像生成已达到一个新的质量水平。但这种深度伪造的恶意使用,引发人们对视觉错误信息的忧虑。
针对deep fake 检测和反检测,本文寻求一种可持续的方案。通过引入人工指纹的模型,方法简单有效:首先将人工指纹嵌入到训练数据中,这种指纹可从训练数据转移到模型生成中,出现在生成的数据。
实验表明指纹解决方案( 1 )适用于各种前沿生成模型,( 2 )导致生成质量的副作用可以忽略不计,( 3 )对图像级和模型级的扰动保持鲁棒性,( 4 )难以被对手检测到,( 5 )将深度伪造的检测和归属转换为琐碎的任务,并优于最近的最先进的基线。

39 Joint Audio-Visual Deepfake Detection
Deep fakes (“深度学习”+“伪造”)中,包含有比如算法生成的视频等数据。虽然它们可能多是娱乐之用,但也可能被滥用于伪造演讲和传播错误信息。
检测伪造的数据已产生一些方法、以及数据集,而音频(如合成语音从文本到语音或语音转换系统)和关联的视频音频模式则一直相对匮乏。
这项工作提出一种新的视觉/听觉 deep fake 联合检测任务,并表明利用视觉和听觉模式之间的内在关系可以帮助 deep Fake 检测。

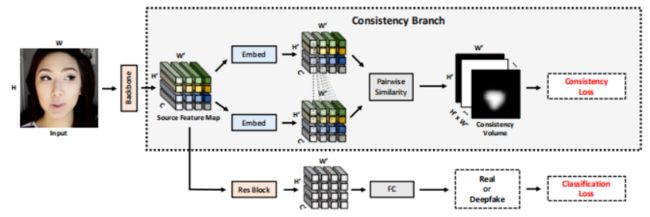
40 Learning Self-Consistency for Deepfake Detection
提出一种新方法检测模型伪造的图像。引入了一种新的表示学习方法,称为:成对一致性学习( PCL ),训练卷积网络来提取这些源特征,并检测深度假图像。方法还提出一种新的图像合成方法,为 PCL提供训练数据。
七个主流数据集上的实验结果表明了方法的有效性。
十五、图像分割
41 Unsupervised Segmentation incorporating Shape Prior via Generative Adversarial Networks
无监督的图像分割算法,由于光照变化和遮挡等干扰因素,对象边界效果并不理想。提出一种无监督的图像分解算法,获得鲁棒的内在表示。使用简单而说明性的合成示例和用于图像分割的基准数据集,证明所提出算法的有效性和鲁棒性。

42 InSeGAN: A Generative Approach to Segmenting Identical Instances in Depth Images
提出 InSeGAN,无监督的 3D 生成对抗网络 (GAN),用于在深度图像中分割刚性物体实例。使用合成分析方法,设计了一种新的 GAN 架构来合成多实例深度图像,并对每个实例进行独立控制。
InSeGAN 接收一组代码向量(例如,随机噪声向量),每个向量编码一个对象的 3D 姿态,该对象由学习的隐式对象模板表示。生成器有两个不同的模块。第一个模块,实例特征生成器,使用每个编码姿势将隐式模板转换为每个对象实例的特征图表示。第二个模块,深度图像渲染器,聚合第一个模块输出的所有单实例特征图并生成多实例深度图像。鉴别器将生成的多实例深度图像与真实深度图像的分布区分开来。为进行实例分割,提出一个实例姿势编码器,它学习接收生成的深度图像并为所有对象实例重现姿势代码向量。
为评估,引入了一个新的合成数据集“Insta-10”,它由 100,000 张深度图像组成,每个图像有 5 个来自 10 个类别的对象实例。在 Insta10 以及真实世界嘈杂深度图像上的实验表明,InSeGAN 实现了最先进的性能。

十六、图像外插值-图像延展-外推
43 SemIE: Semantically-aware Image Extrapolation
提出一种语义感知的新范式来执行图像外修复(image extrapolation),从而可以添加新的对象实例。此前方法局限于只能扩展图像中已存在的对象。但所提出的方法不仅关注(i)扩展已经存在的对象,还关注(ii)基于上下文在扩展区域中添加新对象。
对于给定的图像,首先使用语义分割方法获得对象分割图;分割图被输入网络以计算外推语义分割和相应的全景分割图。输入图像和获得的分割图进一步用于生成最终的图像。对 Cityscapes 和 ADE20K 卧室数据集进行实验,并表明在 FID 等指标的优越性。
https://semie-iccv.github.io/
十七、图像转换
44、 SPatchGAN: A Statistical Feature Based Discriminator for Unsupervised Image-to-Image Translation
对于无监督的图像到图像转换,提出一种判别器架构专注于统计特征而不是单个patch感受野。与现有方法对生成器施加越来越多的约束不同,方法通过简化框架促进了形状变形并增强细节。
所提出的方法在各种具有挑战性的应用中优于现有模型,包括自拍到动漫、男性到女性和眼镜去除等应用。

45、 Dual Transfer Learning for Event-based End-task Prediction via Pluggable Event to Image Translation
事件相机(Event cameras )是一种新型传感器,可感知每像素强度变化并输出具有高动态范围和较少运动模糊的异步事件流。已经表明,事件本身可以用于任务学习,例如语义分割,基于类似编码器解码器的网络等。然而,由于稀疏特性且主要反映边缘信息,仅依靠解码器很难恢复原始细节。此外,大多数方法仅依靠逐像素损失进行监督,这可能不足以充分利用稀疏事件的视觉细节,从而导致不太理想的性能。
本文提出简单而灵活的双流框架,称为双迁移学习(Dual Transfer Learning,DTL),以有效提高最终任务的性能,而不会增加额外的推理成本。所提出的方法由三部分组成:事件到终端任务学习(EEL)分支、事件到图像转换(EIT)分支和迁移学习(TL)模块。通过语义分割和深度估计等任务的显著性能提升来证明这种方法的强大表示学习。

46、 Bridging the Gap between Label- and Reference-based Synthesis in Multi-attribute Image-to-Image Translation
图像到图像转换 (image-to-image translation,I2IT) 模型将目标标签或参考图像作为输入,并将源转换到指定的目标域风格。这两种类型的合成,无论是基于标签的还是基于参考的,都有很大的不同。特别地,基于标签的合成反映了目标域的共同特征,而基于参考的合成则表现出与参考相似的特定风格。本文旨在弥合它们在多属性 I2IT 任务中的差距,设计了基于标签和参考的编码模块(reference-based encoding modules,LEM 和 REM)来比较域差异。
首先将源图像和目标标签(或参考)转移到一个公共嵌入空间中,然后将两个嵌入简单地融合在一起,形成潜码 Srand(或 Sref),可以反映领域风格的差异,并由 SPADE 注入到生成器的每一层。为了将 LEM 和 REM 联系起来,使两种结果互惠互利,鼓励两种潜码接近,并在它们上设置前向和后向转换之间的循环一致性。
此外,Srand 和 Sref 之间的插值也用于合成额外的图像。实验表明,基于标签和基于参考的合成确实是相互促进的,因此可以从 LEM 获得多样化的结果,以及具有相似参考风格的高质量结果。
https://github.com/huangqiusheng/BridgeGAN

47、 Frequency Domain Image Translation: More Photo-realistic, Better Identity-preserving
基于 GAN 的图像转换方法取得了重大进展。然而,现有方法缺乏保留源域“ID身份”的能力,这使得生成的图像过度被参考目标域影响,失去原有重要的结构特征。
为此,提出一种新的频域图像转换 (FDIT) 框架,利用频率信息来增强图像生成过程。将图像分解为低频和高频分量,其中高频特征捕获类似于身份的对象结构,训练目标有助于在像素空间和傅里叶光谱空间中保存频率信息。在五个大型数据集和多个任务中广泛评估 FDIT表明了方法的优越性。

48、 Harnessing the Conditioning Sensorium for Improved Image Translation
域转换里,我们可能希望图像继承“内容”图像的某些属性(例如布局、语义或几何),而继承“风格”图像的风格(例如纹理、照明)。任务主要方法是学习解耦的“内容”和“风格”表示。
但这并不简单,因为用户希望保留的内容取决于他们的想法。因此,本文根据现成的预训练模型提取的条件信息来定义“内容”。然后,使用一组易于优化的重建目标来训练风格提取器和图像解码器。各种高质量预训练模型和简单的训练流程使方法可直接应用于众多领域和“内容”的定义。

49、 Instance-wise Hard Negative Example Generation for Contrastive Learning in Unpaired Image-to-Image Translation
对比学习Contrastive learning在非配对图像到图像转换中显示出巨大的潜力,但有时转换结果很差,且内容结构上没有保留较好的一致性。
本文发现负样本(negative example)在图像转换对比学习的性能中起着关键作用。以往方法中的负样本是从源图像中不同位置的patch中随机抽取的,不能有效地将正样本推到靠近查询样本的位置。为此提出在非配对图像到图像转换 (NEGCUT) 中用于对比学习的实例化硬负样本生成,训练一个生成器在线生成负样本。三个基准数据集的实验表明,与以前的方法相比,所提出的 NEGCUT 框架性能更优。
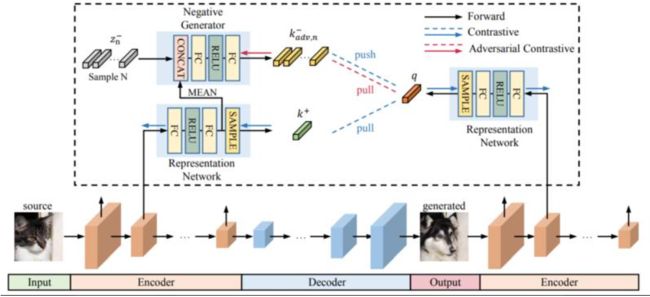
50、 Online Multi-Granularity Distillation for GAN Compression
生成对抗网络 (GAN) 在生成图像方面取得了较大成功,但由于计算成本和内存使用消耗较大,它们在资源受限的设备上部署起来并不简单。尽管最近压缩 GAN 也有进展,但仍存在潜在的模型冗余,可以进一步压缩。
为此提出在线多粒度蒸馏(OMGD)方案来获得轻量级 GAN,这有助于生成具有低计算需求的高保真图像。首次尝试推广面向 GAN 的压缩的单阶段在线蒸馏,其中逐步提升的教师生成器有助于改进基于无判别器的学生生成器。互补的教师生成器和网络层提供全面和多粒度的概念,以从不同维度增强视觉保真度。四个基准数据集的实验结果表明,OMGD 成功地在 Pix2Pix 和 CycleGAN 上压缩了 40 倍 MAC 和 82.5 倍参数,而没有损失图像质量,OMGD 为在资源受限的设备上部署实时图像转换提供了一种可行的解决方案。
https://github.com/bytedance/OMGD

51、 Rethinking the Truly Unsupervised Image-to-Image Translation
当前,图像转换模型都需要图像级别(即输入-输出对)或集合级别(即域标签)的监督信息。但集合级别的监督也可能较难标注。
本文研究在完全无监督之下,处理图像转换问题,而不需要配对图像或者域标签信息。为此,提出一个真正无监督的图像转换模型(unsupervised image-to-image translation,TUNIT),同时学习分离图像域并完成图像转换。实验结果表明,我们的模型与使用全标签训练的集合级监督模型相比具有可比甚至更好的性能,在各种数据集上泛化良好,并且对超参数的选择具有鲁棒性。此外,TUNIT 可以很容易地扩展到具有少量标记数据的半监督学习。

52、 Scaling-up Disentanglement for Image Translation
图像转换方法,通常是为了编辑控制一组标记的属性(在训练时作为监督,例如域标签),同时保持其它未标记的属性不变。当前方法要么可以实现解耦属性,但视觉保真度较低;要么是可以完成视觉上较好的转换效果,但没有解耦属性。
这项工作提出OverLORD,一个用于分离标记和未标记属性以及合成高保真图像的框架,由两个阶段组成。解耦:通过潜在优化学习解耦表示。与以前的方法不同,我们不依赖对抗性训练或任何架构偏见。合成:训练前馈编码器以推断学习属性并以对抗方式调整生成器以提高感知质量。当标记和未标记的属性相关时,建模一个额外的表示来解释相关属性并改善解耦效果。方法涵盖多种设置,如解耦标记的属性、姿势和外观、形状和纹理等。与此前方法相比,提供更好的转换质量和多样性。

53、 Semantically Robust Unpaired Image Translation for Data with Unmatched Semantics Statistics
不成对的图像转换应用里,很多时候要求保留输入内容的语义结构。由于不知道源域和目标域之间内在固有的不匹配语义分布,现有方法(即基于 GAN)可能会输出不理想的效果。特别是,虽然产生视觉上合理的输出,但学习模型通常会转换输入的语义结构。
为了在不使用额外监督信息情况下解决这个问题,提出强制转换后的输出在语义上保持不变。输入的微小感知变化,本文称之为“语义鲁棒性”的属性。通过优化鲁棒性损失 w.r.t. 由于输入的多尺度特征空间扰动,方法有效地减少了语义翻转,并产生在数量和质量上都优于现有转换方法。
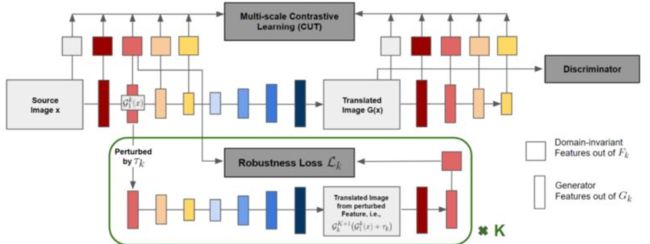
54、 TransferI2I: Transfer Learning for Image-to-Image Translation from Small Datasets
图像转换应用近年来已得到大量研究,已经可以生成较逼真的图像。但在应用于小数据集领域时仍面临重大挑战。现有方法使用迁移学习进行图像转换,但需要从头开始学习数百万个参数。本文提出一种新的图像转换迁移学习 (TransferI2I)方法,将学习过程解耦为图像生成步骤和转换步骤。
第一步,提出两种新技术:源-目标域初始化(source-target initialization)和适配器层(adaptor layer)的自初始化。前者在源数据和目标数据上微调预训练的生成模型(例如 StyleGAN);后者允许在不需要任何数据的情况下初始化所有非预训练的网络参数。这些技术为转换步骤提供了更好的初始化。
此外引入一种辅助 GAN,进一步促进训练。对三个数据集(动物面孔、鸟类和食物)的广泛实验表明,方法优越。
https://github.com/yaxingwang/TransferI2I

55、Unaligned Image-to-Image Translation by Learning to Reweight
无监督图像转换,学习的是从源域到目标域的映射,且不使用配对图像进行训练。无监督图像转换的一个基本前提假设是两个域是对齐的,例如,对于 selfie2anime 任务,动漫(自拍)域必须只包含可以转换成另一个域中的某些图像的动漫(自拍)脸部图像。但收集对齐域的数据很费力。
本文考虑两个未对齐域之间的图像转换任务,提出基于重要性重新加权来选择图像,并开发一种方法来学习权重并同时自动执行转换。实验表明了所提方法的优越性。
56、Sketch Your Own GAN
素描可能是传达视觉概念的最普遍的方式,能否通过绘制单个示例样本来创建深度生成模型?传统上,创建 GAN 模型需要收集大规模的样本数据集和深度学习的专业知识。
这项工作提出了一种 GAN Sketching 方法,用一个或多个草图样本重新打造GAN,且训练容易。模型的输出通过跨域对抗性损失来匹配用户草图。此外,探索了不同的正则化方法来保持原始模型的多样性和图像质量。
实验表明,方法可以匹配草图指定的形状和姿势,同时保持真实性和多样性。最后,展示了一些应用,包括潜在空间插值和图像编辑。
https://github.com/PeterWang512/GANSketching

十八、文字生成图像
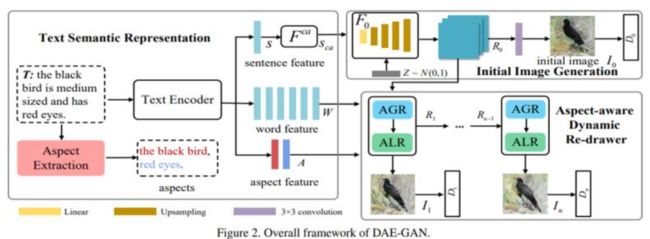
57、 DAE-GAN: Dynamic Aspect-aware GAN for Text-to-Image Synthesis
文本转换生成图像是指,从给定的文本描述中生成图像,保持照片真实性和语义一致性。此前方法通常使用句子特征嵌入去生成初始图像,然后用细粒度的词特征嵌入对初始效果进行细化。
文本中包含的“aspect”信息(例如,红色的眼)往往连带几个词,这对合成图像细节信息至关重要。如何更好地利用文本到图像合成中的aspect信息仍是一个未解决的挑战。本文提出一种动态 Aspect-awarE GAN (DAE-GAN),从多个粒度(包括句子级、词级和aspect级)全面地表示文本信息。
此外,受人类学习行为的启发,开发一种用于图像细化的新型 Aspectaware Dynamic Re-drawer (ADR)。最后设计相应的匹配损失函数来保证不同层次的文本图像语义一致性。在CUB-200 和 COCO上的实验证明了方法的优越性和合理性。
十九、说话人生成
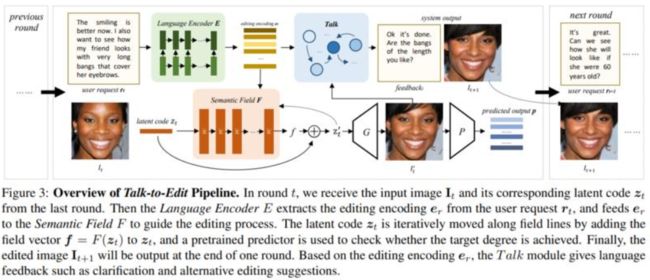
58、 Talk-to-Edit: Fine-Grained Facial Editing via Dialog
人脸编辑是视觉和图形中的重要任务。现有方法无法提供与用户自然交互的连续且细粒度的编辑模式(例如,将微微笑脸编辑为大笑脸)。
这项工作提出Talk-to-Edit,一个交互式编辑框架,通过用户和系统之间的对话执行细粒度的属性操作。主要想法是在 GAN 潜在空间中模拟一个连续的“语义场”。1)与以往的作品将编辑视为在潜在空间中遍历直线不同,这里的细粒度编辑被表述为在语义场上找到尊重细粒度属性景观的弯曲轨迹。2)每一步的“曲率”是位置特定的,由输入图像以及用户的语言请求决定。3)为了让用户参与有意义的对话,系统通过考虑用户请求和语义场的当前状态来生成语言反馈。还贡献了 CelebA-Dialog,一个视觉语言人脸编辑数据集,以促进大规模研究。具体来说,每张图像都有手动注释的细粒度属性注释以及自然语言中基于模板的文本描述。广泛的定量和定性实验证明了框架在以下方面的优越性:1)细粒度编辑的平滑度,2)身份/属性保存,3)视觉真实感和对话流畅度。
https://www.mmlab-ntu.com/project/talkit/
59、 HeadGAN: One-shot Neural Head Synthesis and Editing
近来,基于单张参考图像来完成人脸重现任务的研究已有一定进展。但在照片逼真度方面仍表现不佳,或者无法较好保留身份ID信息,或者没有完全迁移驱动的姿势和表情。
本文提出HeadGAN,根据 3D 人脸表征进行合成,可以从任何驱动视频中提取并适应参考图像的脸部几何形状,将身份与表情分离。通过利用音频特征作为补充输入来进一步改进嘴部动作。
https://michaildoukas.github.io/HeadGAN/

60、Learned Spatial Representations for Few-shot Talking-Head Synthesis
提出了一种新的方法来进行少样本说话人生成。虽然最近相关工作已有一定进展,但产生的效果里无法保留源图像中主体身份ID信息。
本文假设这是每个个体人在单潜码中的纠缠表示所导致,提出将其分别解耦为其空间和风格细节方面。

61、 MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement
本文提出一种从语音生成3D全脸驱动的方法。现有音频驱动的人脸驱动方法无法产生准确和合理的协同发音,或者有依赖于特定于人的局限。
为此提出一种通用音频驱动的人脸驱动方法,可以为整个人脸实现高度逼真的运动合成结果。方法核心是解耦潜在空间,它基于一种新颖的跨模态损失来解开音频相关和音频不相关的信息,确保了高度准确的嘴唇运动,同时还合成了与音频信号无关的面部部分的合理动画,例如眨眼和眉毛运动。
https://github.com/facebookresearch/meshtalk

62、 FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning
本文提出一种说话人生成方法,以音频信号为输入,以目标短视频剪辑为参考,合成具有自然嘴形运动、头部姿势和眨眼与目标人脸般的视频。
注意到,生成人脸属性不仅包括与语音高度相关的显式属性,例如唇部动作,还包括与输入音频相关性较弱的隐式属性,例如头部姿势和眨眼。为了对不同人脸属性与输入音频之间的这种复杂关系进行建模,提出了一种人脸隐式属性学习生成对抗网络(FACIAL-GAN),它集成了语音感知、上下文感知和身份感知信息来合成 3D 面部动画和嘴唇、头部姿势和眨眼的逼真动作。然后, Rendering-toVideo 网络将渲染的人脸图像和眨眼的注意力图作为输入,以生成逼真的输出视频帧。

二十、风格迁移
63、 DRB-GAN: A Dynamic ResBlock Generative Adversarial Network for Artistic Style Transfer
提出一种用于艺术风格迁移的动态 ResBlock 生成对抗网络(DRB-GAN)。风格码被建模为连接风格编码网络和迁移网络的动态 ResBlocks 的共享参数。
在编码网络中,融入了风格的类感知注意机制;在迁移网络中,多个 Dynamic ResBlocks 来整合风格码和提取的 CNN 语义特征,然后输入到空间实例归一化(SWLIN)解码器,实现艺术风格迁移。
https://github.com/xuwenju123/DRB-GAN

64、 Diverse Image Style Transfer via Invertible Cross-Space Mapping
图像风格迁移可以将艺术风格迁移到任意照片上,以创建新颖的艺术图像。尽管风格迁移本质上是一个不适定问题,但现有方法通常假设某种唯一结果,而无法捕获潜在可能的完整分布。
本文提出一个多样化的图像风格迁移(DIST)方案,该方案通过执行可逆的跨空间映射来实现多样性。具体来说,由三个分支组成:解耦分支、逆向分支和风格化分支。
解耦分支可以分解内容空间和风格空间;逆映射分支则可以完成输入噪声向量与艺术图像风格空间之间的可逆映射;风格化分支渲染风格化输入的内容图像。

二十一、虚拟试衣
65、FashionMirror: Co-attention Feature-remapping Virtual Try-on with Sequential Template Poses
虚拟试穿任务引起了越来越多的关注。现有技术专注于通过扭曲衣服和在语义分割的帮助下融合像素级别的信息来解决此任务。但语义分割比较耗时,且随着时间的推移容易导致错误累积。此外,在像素级别而不是特征级别扭曲信息会限制性能(例如,无法生成不同的视图)。相比之下,在特征层面融合信息可以通过卷积进一步细化得到最终结果。
基于这些假设,提出了一个协同注意力的特征重映射框架( co-attention feature-remapping framework),即 FashionMirror,它根据驱动姿势序列分两个阶段生成试穿结果。在第一阶段,考虑源人体图像和目标试穿衣服来预测移除掩膜和试穿衣服的掩膜,以取代预处理的语义分割,减少推理时间。在第二阶段,首先通过移除掩膜对源人体上的衣服进行移除,并扭曲试穿衣服掩膜上的衣服特征,且调节以适应下一帧的人。同时预测来自连续 2D 姿势的光流,并将源人类扭曲到特征级别的下一帧。然后,在每一帧中增强服装特征并获取人体特征,以生成具有时空平滑度的真实试穿结果。定性和定量结果都表明了FashionMirror 的优越性。

66、Dressing in Order: Recurrent Person Image Generation for Pose Transfer, Virtual Try-on and Outfit Editing
本文提出了一个灵活的人物生成框架,称为 Dressing in Order (DiOr),它支持 2D 姿势转换、虚拟试穿和时尚编辑任务。DiOr 的关键是一种循环生成流水线,可以将衣服按顺序穿在一个人身上,这样以不同的顺序试穿相同的衣服就会产生不同的外观。
系统可以产生现有工作无法实现的着装效果,包括服装的不同相互作用(例如,将上衣塞进下装或叠穿),以及多件相同类型的服装的分层(例如,将夹克套在衬衫套上) T恤)。DiOr 明确编码每件衣服的形状和质地,使这些元素可以单独编辑。姿势转移和修复的联合培训有助于生成服装的细节保存和连贯性。

67、Structure-transformed Texture-enhanced Network for Person Image Synthesis
姿势引导的虚拟试穿指的是,基于姿势迁移任务下,去修改服饰。这是两个人物图像合成中的常见任务,具有很强的相关性和相似性。但大多数现有方法将它们视为两个单独的任务,并没有探索它们之间的相关性。此外,由于较大的错位和遮挡,这两项任务具有挑战性,因此这些方法中的大多数容易产生不清晰的人体结构和模糊的细粒度纹理。
本文设计一个结构转换的纹理增强网络来生成高质量的人物图像并构建两个任务之间的关系。由两个模块组成:结构转换渲染器和纹理增强风格器(structure-transformed renderer and texture enhanced stylizer)。大量实验表明,方法在两项任务上的优越性。

二十二、图像编辑-文本引导
68、Language-Guided Global Image Editing via Cross-Modal Cyclic Mechanism
通过语言请求来自动编辑图像可以大大节省繁重的手工工作,且对摄影新手友好。
本文专注于语言引导的全局图像编辑任务。现有工作存在数据集数据分布不平衡和不足的问题,因此无法很好地理解语言请求。为了解决这个问题,使用图像生成器创建一个循环,方法是创建一个称为编辑描述网络 (EDNet) 的新模型,该模型预测给定一对图像的编辑嵌入。鉴于循环,提出了几种增强策略,以帮助模型在不平衡数据集的情况下理解各种编辑请求。此外,还提出了图像请求注意(IRA)模块,当图像在不同区域需要不同的编辑程度时,该模块可以在空间上自适应地编辑图像,以及对此的新评估指标比传统像素损失(例如 L1)更语义和合理的任务。对两个基准数据集的广泛实验证明了方法的有效性。

二十三、图像编辑-单样本
69、Image Shape Manipulation from a Single Augmented Training Sample
本文提出 DeepSIM,一种基于单张图像的条件生成模型。本文认为数据增强是实现单图像训练的关键,并将薄板样条 (TPS) 的使用作为有效的增强。
网络学习在图像的原始表征与图像本身之间进行映射,而原始表征的选择对操作的易用性和表现力有影响,可以是自动的(例如边缘)、手动的(例如分割)或混合的,例如分割的边缘。操作时,生成器通过修改原始输入表示并将其映射到网络来进行复杂的图像更改。

二十四、开集识别
70、OpenGAN: Open-Set Recognition via Open Data Generation
实际应用中,机器学习系统需要分析与训练数据不同的测试数据。在 K-way 分类中,这也被表述为开集识别,其核心是区分 K 个闭集类之外的开集数据的能力。
开放集识别的两个概念上优雅的想法是:1)通过利用一些异常数据作为开放集来学习开集与闭集的二分类判别器,以及 2)使用 GAN 无监督学习闭集数据分布。由于对异常数据的过度拟合,对各种开放测试数据的泛化能力很差,这些异常值不太可能详尽地代表开集情况。后者效果不佳,GAN 训练不稳定。
本文提出OpenGAN,在一些真实异常数据上精心挑选的 GAN 判别器已经达到非常不错的水准;用对抗性合成的“假”数据增加了可用的真实开放训练集。最重要的,它在封闭世界 K-way 网络计算的特征上构建判别器。大量实验表明,OpenGAN 明显优于之前方法。

二十五、人脸识别
71、SynFace: Face Recognition with Synthetic Data
随着最近深度神经网络的成功,人脸识别取得了显著进展。但收集用于人脸识别的大规模真实世界训练数据具有挑战性,尤其是由于标签噪声和隐私问题。同时,现有的人脸识别数据集通常是从网络图像中收集的,缺乏对属性(例如姿势和表情)的详细注释,因此对不同属性对人脸识别的影响研究很少。
本文使用合成人脸图像(即 SynFace)解决人脸识别中的上述问题。具体来说,探讨使用合成和真实人脸图像训练的最先进的人脸识别模型之间的性能差距。然后,分析性能差距背后的根本原因,例如,较差的类内变化以及合成和真实人脸图像之间的域差距。受此启发,设计了具有身份混合 (IM) 和域混合 (DM) 的 SynFace,以缩小上述性能差距,展示了合成数据在人脸识别方面的巨大潜力。
此外,通过可控的人脸合成模型,可以轻松管理合成人脸的不同因素,包括姿势、表情、光照、身份数量和每个身份的样本。因此,还对合成人脸图像进行了系统的实证分析,以提供一些关于如何有效利用合成数据进行人脸识别的见解。

72、Learning Facial Representations from the Cycle-consistency of Face
人脸在许多方面会有很大的变现差异,例如身份、表情、姿势和妆容。因此,从人脸图像中解耦和提取这些特征是一个巨大的挑战,尤其是在无监督的情况下。
这项工作将人脸特征中的循环一致性作为监督信号引入,以从未标记的人脸图像中学习人脸的表征。通过叠加人脸运动一致性和身份一致性约束来实现学习。人脸运动一致性的主要思想是,给定一张有表情的人脸,可以通过去除表情,并进行重建回原始人脸。身份一致性通过特征重新规范化去除身份特征得到平均脸,并通过将个人属性添加到平均脸来重新恢复到原始脸。
在训练时,模型学习解耦两种不同的人脸表示,以用于执行循环一致的重建。在测试时,评估各种任务的人脸表征效果,包括表情识别和头部姿势回归。还可以将学习到的表征直接应用于识别、正面化和图像到图像的转换。
https://github.com/JiaRenChang/FaceCycle

73、Teacher-Student Adversarial Depth Hallucination to Improve Face Recognition
提出“师生生成对抗网络 (TS-GAN, Teacher-Student Generative Adversarial Network) ”从单个 RGB 图像生成深度图像,以提高人脸识别系统的性能。为泛化到未知的数据集,设计教师模块和学生模块。
教师本身由一个生成器和一个判别器组成,以监督的方式学习输入 RGB 和对应的深度图像之间的潜在映射。
学生由两个生成器(一个与教师共享)和一个判别器组成,它从没有可用配对深度信息的新 RGB 数据中学习,以提高泛化能力。然后可以在运行时使用经过充分训练的共享生成器从 RGB 中产生虚拟的深度信息,以用于人脸识别等下游应用。
人脸识别实验表明,与单一 RGB 模态相比,性能提高 +1.2%、+2.6% 和 +2.6%( IIITD、EURECOM 和LFW 数据集)。
https://github.com/hardikuppal/teacher-student-gan.git

二十六、少样本生成
74、LoFGAN: Fusing Local Representations for Few-shot Image Generation
给定新的、训练未知的类别里的少数可用图像,少样本图像生成,旨在为该类别生成更多数据。以前工作试图通过使用可调整的加权系数来融合这些图像。然而从全局角度来看,不同图像之间存在严重的语义错位,使得生成质量和多样性较差。
为此提出 LocalFusion Generative Adversarial Network (LoFGAN),将这些可用的图像作为一个整体来使用,而是首先将它们随机分成一个基本图像和几个参考图像。接下来,LoFGAN 基于语义相似性匹配基础图像和参考图像之间的局部表示,并用最接近的相关局部特征替换局部特征。这样,LoFGAN 可以在更细粒度的水平上产生更逼真、更多样化的图像,同时享受语义对齐的特性。此外,还提出了一种局部重建损失,可以提供更好的训练稳定性和生成质量。对三个数据集进行了广泛的实验,这成功地证明了方法在数据有限的情况下用于少量图像生成和下游视觉应用的有效性。

二十七、实例可控生成
75、Multi-Class Multi-Instance Count Conditioned Adversarial Image Generation
本文提出一种条件生成对抗网络(GAN),它可以从给定的类中生成指定数量目标对象的图像。这需要两个基本能力:(1)能够在给定复杂约束的情况下生成高质量图像;(2)能够计算给定图像中每个类别的对象实例。
提出的模型通过基于计数的条件以及回归子网络对StyleGAN2 架构进行了模块化扩展,以计算训练期间每个类生成的对象数量。在对三个不同数据集的实验中,表明即使在复杂背景存在的情况下,所提出的模型也能根据给定的多类计数条件学习生成图像。
特别是,提出了一个新的数据集 CityCount,它源自 Cityscapes 街景数据集,以在具有挑战性且实际相关的场景中评估方法。

二十八、视图合成
76、Infifinite Nature: Perpetual View Generation of Natural Scenes from a Single Image
在给定单个图像的情况下,对应于任意长的相机轨迹新视图生成。这极具挑战,远超出了当前视图合成方法的能力。视频生成方法生成长序列的能力也有限。
本文将几何和图像合成集成在一个迭代的“渲染、细化和重复”框架中,允许在数百帧后覆盖更 long-range 的生成。方法可以从一组单目视频序列中训练出来。还提出了一个沿海场景的航拍镜头数据集,并将方法与最近的视图合成和条件视频生成基线进行比较,表明所提方法的优越性。
https://infinite-nature.github.io/

二十九、细粒度生成
77、Semi-Supervised Single-Stage Controllable GANs for Conditional Fine-Grained Image Generation
当前效果较好的深度生成模型,通过设计多层级的模型结构、多个阶段的合成来提高细粒度图像的生成质量。
为减轻模型设计和训练的复杂程度,提出一种单阶段可控 GAN (SSCGAN),用于在半监督的情形中进行条件细粒度的图像合成。细粒度的对象类别可能具有细微的区别和共享属性,考虑三个变化因素:类无关的内容、跨类的属性和类别语义信息,并将它们与不同的变量相关联。为确保变量间的解耦,最大化类无关变量和合成图像之间的互信息,将真实数据映射到生成器的潜在空间以执行跨类属性的一致性正则化,并将基于类语义的正则化合并到判别器的特征空间。
SSC-GAN 在多个细粒度数据集上实现了最先进的半监督图像合成结果。

三十、细粒度检索
78、Retrieve in Style: Unsupervised Facial Feature Transfer and Retrieval
本文提出风格检索(RIS,Retrieve in Style),一种用于在真实图像上进行人脸特征迁移和检索的无监督框架。
最近的一些工作显示了通过利用 StyleGAN 潜在空间的解耦特性,可以完成局部的人脸特征迁移。RIS做以下改进:1) 引入更有效的特征解耦。2)免去对每幅图像超参数调整的需要。3)使用分离的人脸特征(例如眼睛)实现细粒度的人脸检索。
本文声称这是第一个在如此精细级别上展开检索人脸图像的工作。
https://github.com/mchong6/RetrieveInStyle

79、Face Image Retrieval with Attribute Manipulation
本文介绍一种新的人脸图像检索框架,通过指定对人脸属性期望修改的调整向量和为不同属性分配不同重要性级别的偏好向量来对输入查询进行增强。例如,用户可以要求检索与查询图像相似但具有不同头发颜色的图像,并且在结果中可选是否需要佩戴眼镜。
为了实现这一点,提出通过在 StyleGAN 的潜在空间中学习一组稀疏和正交的基向量来解耦各种属性相对应的语义。然后根据属性之间的差异来分解人脸图像之间的差异,为属性分配偏好,并调整查询中的属性。方法的有效性,已通过在人脸图像检索任务中实现最先进的结果来得到了验证。

三十一、解耦学习
80、GAN-Control: Explicitly Controllable GANs
提出一个训练 GAN 的框架,可以显式控制生成的人脸图像,通过设置确切的属性(例如年龄、姿势、表情等)来控制生成的图像。大多数控制 GAN 生成图像的方法是在标准 GAN 训练后隐式获得的潜在空间以解耦属性来实现部分控制的。这些方法能够改变某些属性的相对强度,但不能明确设置它们的值。还有一些方法利用可变形 3D 人脸模型 (3DMM) 来实现 GAN 中的细粒度控制能力。
与这些方法不同,本文方法不受 3DMM 参数限制,且可以扩展到人脸领域之外。使用对比学习获得具有明确解耦的潜在空间的GAN。在人脸领域,展示了对身份、年龄、姿势、表情、头发颜色和照明的控制。还展示了在绘画肖像和狗图像生成领域的控制能力。证明了方法在定性和定量上都实现了最先进的性能。

81、Video Autoencoder: self-supervised disentanglement of static 3D structure and motion
提出一种视频自动编码器,以自监督方式从视频中学习 3D 结构和相机姿态的解耦表示。
解耦的表征可以应用于一系列任务,包括新视图合成、相机姿态估计和通过运动跟踪生成视频。在几个大型自然视频数据集上评估方法,并在域外图像上显示泛化结果。
https://zlai0.github.io/VideoAutoencoder/

三十二、可解释性
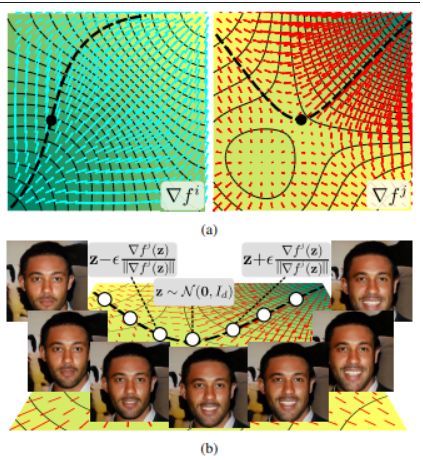
82、WarpedGANSpace: Finding non-linear RBF paths in GAN latent space
这项工作研究的是,以无监督方式在预训练 GAN 的潜在空间中发现可解释路径的问题,从而提供一种直观且简单的方法来控制潜在的生成因素。
代码和预训练模型https://github.com/chi0tzp/WarpedGANSpace
83、Toward a Visual Concept Vocabulary for GAN Latent Space
本文介绍了一种用于构建在 GAN 潜在空间中表示的视觉概念。方法由三个部分组成:(1)基于层选择性自动识别感知显著的方向;(2) 用自然语言描述对这些方向进行人工标记;(3) 将这些标记信息分解为词汇。实验表明,方法学习的概念词汇是可靠且可组合的,并能够对图像风格和内容进行细粒度操作。

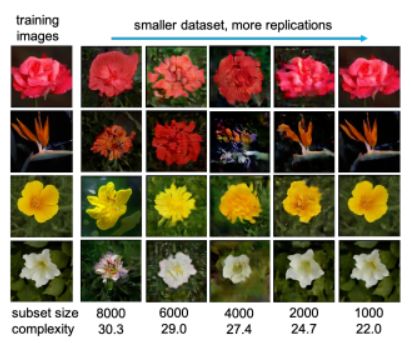
84、When do GANs replicate? On the choice of dataset size
GAN 的生成,有没有可能是直接去复制训练图像?
尽管已经在理论上或经验上确定了许多因素,但数据集大小和复杂性对 GAN 是否发生复制的影响仍然未知。借助 BigGAN 和 StyleGAN2 ,在数据集 CelebA、Flower 和 LSUN-bedroom 上,本文表明数据集大小及其复杂性在 GAN 复制和生成图像的感知质量中起着重要作用。
85、Explaining in Style: Training a GAN to explain a classifier in StyleSpace
图像分类模型可能取决于图像里多种不同的语义属性。对分类器决策的解释方面,需要发现和可视化这些属性。本文提出的StylEx,通过训练生成模型来具体解释构成分类器决策的多个属性。
关于StyleGAN 的 StyleSpace,众所周知,它可以在图像中生成具有语义意义的维度。然而,由于标准 GAN 训练不依赖于分类器,它可能无法表示那些对分类器决策很重要的属性,而 StyleSpace 的维度可能表示不相关的属性。为此提出了一个包含分类器模型的 StyleGAN 训练程序,以学习特定于分类器的 StyleSpace。然后从该空间中选择解释性属性。
将 StylEx 应用于多个领域,包括动物、树叶、面部和视网膜图像,展示了如何以不同的方式修改图像以更改其分类器输出。实验表明,该方法可以找到与语义匹配的属性。

三十三、隐私保护
86、Personalized and Invertible Face De-identification by Disentangled Identity Information Manipulation
智能手机和监控摄像头在内的智能设备的普及,导致更严重的隐私问题。“去识别( De-identification)”被认为是通过隐藏或替换身份信息的过程来保护视觉隐私的有效工具。
大多数现有的去识别方法都有一些限制,因为它们主要关注保护过程并且通常不可逆。本文提出一种基于深度生成模型的可逆去识别方法,其主要思想是引入用户特定密码和可调节的参数来控制身份变化的方向和程度。

87、Towards Face Encryption by Generating Adversarial Identity Masks
社交媒体和网络共享的时代,数据隐私和安全性越来越受到关注。本文开发一种可以加密个人照片的技术,以便它们可以保护用户免受未经授权的人脸识别系统的侵害,但在视觉上与人类的原始版本保持一致。
为了实现这一点,提出了一种有针对性的身份保护迭代方法(TIP-IM)来生成可以覆盖在人脸图像上的对抗性身份掩码,从而可以在不牺牲视觉质量的情况下隐藏原始身份。大量实验表明,在实际测试场景下,TIP-IM 针对各种最先进的人脸识别模型提供了 95% 以上的保护成功率。

三十四、医学图像
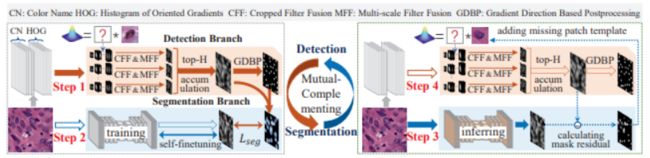
88、Mutual-Complementing Framework for Nuclei Detection and Segmentation in Pathology Image
细胞核的检测和分割是病理图像中的基本分析操作,从中得出的评估是癌症诊断的重要评判标准之一。手动分割细胞核既昂贵又耗时。更重要的是,由于外观变化大、细胞核连体重叠、组织结构退化严重,细胞核的准确分割检测具有挑战性。监督方法高度依赖大量带注释的样本。现有的两种无监督方法在退化样本上容易失败。
本文提出一种用于病理图像中的细胞核检测和分割的相互补充框架 (MCF)。MCF的两个分支以相互补充的方式进行训练,其中检测分支补充分割分支的伪掩模,而渐进训练的分割分支通过计算预测掩模和检测结果之间的掩模残差来补充缺失的核模板。大量实验表明MCF的有效性。
89、Long-Term Temporally Consistent Unpaired Video Translation from Simulated Surgical 3D Data
非配对视频转换的研究主要集中在通过调节相邻帧来实现短期时间一致性。对于从模拟到逼真的序列转换,有关基础几何的可用信息为实现跨视图的全局一致性可以提供信息。
本文提出将不成对的图像转换与神经渲染相结合,模拟转换为逼真手术腹部场景。通过引入全局可学习纹理和光照不变的视图一致性损失,方法可完成任意视图的一致转换,实现一致性良好的视频合成效果。
代码和数据http://opencas.dkfz.de/video-sim2real/

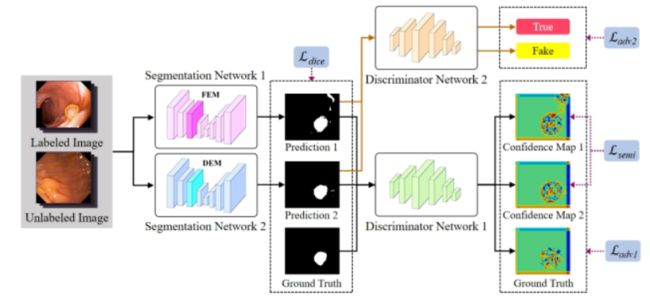
90、Collaborative and Adversarial Learning of Focused and Dispersive Representations for Semi-supervised Polyp Segmentation
结肠镜息肉图像的自动分割是计算机辅助诊断结直肠癌的重要步骤。近年来报道的大多数息肉分割方法都是基于全监督的深度学习方法。然而,医生在诊断期间对息肉图像进行打标注成本极高。
本文提出一种新的半监督息肉分割方法,通过协作和对抗学习的聚焦(focused)和分散(dispersive )表示学习模型,处理息肉位置和形状的多样性。此外,判别器在对抗性训练框架中生成的置信度图显示了利用未标记数据和提高分割网络性能的有效性。
对两个著名的息肉数据集Kvasir-SEG 和 CVC-Clinic DB进行了广泛的实验,结果证明了方法的有效性和先进性。
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
一顿午饭外卖,成为CV视觉的前沿弄潮儿!
超110篇!CVPR 2021最全GAN论文汇总梳理!
超100篇!CVPR 2020最全GAN论文梳理汇总!
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
