KDD 2021 | 基于深度置信度感知学习的广告投放探索方案
▐ 导读
本文主要介绍阿里妈妈外投广告团队在点击率预估领域提出的一种新模型训练方法 —— 深度置信度感知学习(Deep Uncertainty-Aware Learning),以下简称:DUAL。我们尝试在数据循环背景下看待点击率预估模型,重新理解它在广告投放过程中如何参与。在这个新视角下,我们分析了点击率预估问题中置信度的意义,并在“如何建模与利用置信度”问题上迈出了一小步。目前该项工作论文已被 KDD 2021录用,并在阿里妈妈外投业务落地,在线提升显著,欢迎交流讨论。
论文:https://arxiv.org/abs/2012.02298
▐ 点击率预估问题再思考
点击率预估(CTR Prediction)近些年在工业界和学术界中被广泛地关注和研究,已取得了长足的进展并在各种场景成功落地。最近几年,点击率预估技术主要的演进路径可以被概括为模型表示能力的进化:例如通过引入Attention、Recurrent Units、Memory、Graph Embedding等技术,使模型表示能力越来越强、越来越适合用户兴趣建模,因此带来了性能的提升。
目前业界多以监督学习的范式处理点击率模型的学习 —— 以历史数据为原材料(训练样本集),配合典型的监督学习任务目标(如分类问题中常见的交叉熵损失函数),以经验风险最小化的方式,进行模型训练。假设 为训练样本集,其中 为样本特征,通常可包含用户特征、广告特征和环境特征, , 为样本Label。模型的训练/学习则是在假设空间 中寻找使得经验风险最小化模型 ,形式化描述为:
其中 为损失函数, 为模型 的经验风险。
统计学习理论告诉我们,当训练样本和测试样本独立同分布地产生于某个数据分布 时,模型泛化误差存在上界,在这个意义下,我们认为训练得到的模型是可靠的。
数据循环问题
在实际系统中,一个常见却又容易被忽视的问题是,数据的产生过程通常并不服从于某个确定的数据分布 。如图所示:
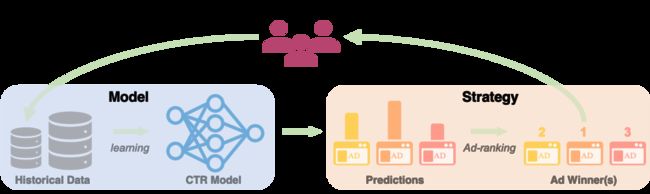
广告展示带来用户行为,而用户行为反馈形成样本,决定后续模型的学习,模型参与后续广告展示,形成循环。在这种循环下,训练样本分布和测试样本(即展示前的候选集合)分布并没有确定性的关联,这可能与上述独立同分布的假设相去甚远,从而无法保证模型的可靠性。同时,当模型部分(预估)和策略部分(排序)被分开设计时,往往因为缺乏有效的探索机制,导致模型更聚焦于局部最优。我们以一个简单的例子说明:假设目前我们为了最大化用户的点击量,每次向用户展示模型预估点击率最高的广告:
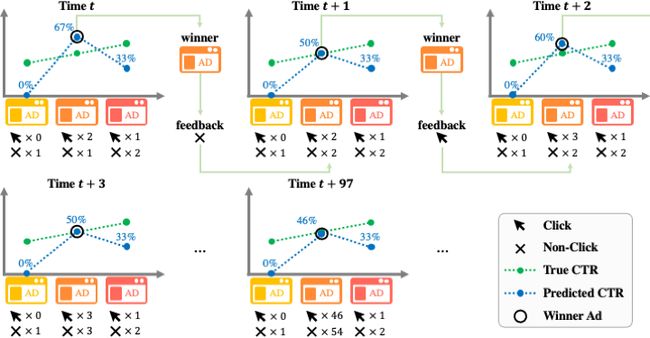
图中在每个时间点列出了当前的训练样本(即用户反馈)。蓝色和绿色虚线分别表示预估 CTR 和真实 CTR。每当具有最高预估点击率的广告获胜展现并收集新的用户反馈时,预估模型就会更新。从这个简单例子中可以发现,数据循环问题会导致中间广告始终被展现,而其他广告的点击率则始终被低估,从而系统只能采取次优解。而这个问题很显然不能够通过更好的模型表示能力解决。这种由于数据循环问题导致的缺乏探索性,在用户行为极其稀疏的广告场景中影响会更加显著,这促使我们重新思考数据循环问题下的点击率建模问题。
在广告场景的交互过程中,数据受到模型影响的主要是广告分布(用户及场景分布可以被理解为对自然流量的统计描述,与模型无关)。因此,相对于做一个联合数据分布 的假设,一个更合理的形式化描述应该将广告分布抽离出来,作为显式可控的一部分。
然而,在很多系统中,这一步被独立地抽象为策略(或排序)模块。策略模块通常假设预估模型绝对准确,从而可以得到简单直观的排序策略(例如根据 eCPM 排序、oCPX 等)。但是,这样的系统设计存在一些逻辑上的矛盾:一方面,策略模块依据模型预估决定了微观上的广告排序和宏观上的广告分布(和样本分布);另一方面,模型的学习又假设了训练&测试样本服从于某个不受系统影响的数据分布。
Contextual Bandits视角下的广告投放
为了解决上述矛盾,我们将模型与策略部分做整体考虑,以Contextual Bandits的视角考虑整个系统。具体地,我们将广告投放过程考虑为一个交互过程(如图):
在时刻 ,系统接收到用户请求的上下文信息 (包含用户特征和场景特征),
根据当前策略 ,决定展示广告,其中 为广告候选集,策略 为候选集 上的概率分布,表示给定上下文 后展示每个候选广告的概率
系统接收用户对广告 的点击反馈 ,, 表示广告 的特征;可以视为该问题的Payoff Function,此处含义为点击率
根据最新反馈集合 ,更新策略
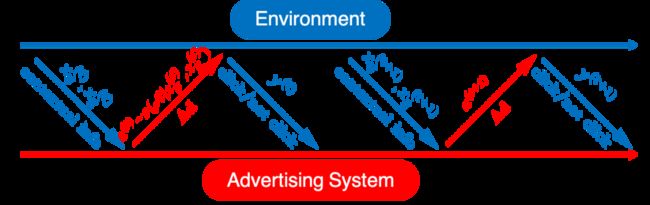
从而整个交互过程的目标为,经过 轮之后,使得累积的效用(Utility,例如广告主收益、点击量等)最大化。这里我们以 目标为例(该目标表示“点击为广告主带来的价值总和”,称为“社会福利”,其他目标可自然推广)。
如果我们将前面假设的联合数据分布 ,按照特征种类展开为用户、广告、场景特征,可以写为:。可以发现,我们放弃了关于广告分布服从于某固定分布 的假设(即 ),而是以策略 显式地建模了这一部分。
在 Contextual Bandits 问题描述中,广告分布本身(即策略 )正是解决该问题的“变量”,而不再是一个假设。事实上,以在 Contextual Bandits 问题描述系统交互过程的方式,在很多早期工作中已经被采用(例如 Lihong Li 等人的经典 WWW 2010论文 [1])。但是,早期工作更多对Payoff Function做较强的假设,例如 (即 Linear Bandits)。然而目前业界已经普遍采取深度点击率预估模型,并取得了显著效果,表明真实场景中的 Payoff Function 远非线性模型可表达。因此,我们希望将 Contextual Bandits 方法思路应用于具有复杂 Payoff Function 的场景中。在各类 Bandits 方法中,核心思想主要是,对不同 Action 的 Payoff 的不确定性进行建模,并根据该不确定性平衡其中的探索和利用(Exploration-Exploitation Trade-off)。对应到我们的具体问题,我们应该对投放不同广告的点击率的不确定性进行建模,并根据该不确定性平衡“已知高点击率”广告和“潜在高点击率”广告的投放,以达到更优的长期效用。
因此,为了解决上述 Contextual Bandits 问题,关键点在于解决建模点击率预估的置信度问题。
▐ 深度置信度感知学习
在深度模型中,对其预测的不确定性进行建模,有两类主要的方法:集成学习(Bagging等)和贝叶斯神经网络(PBP等)。但是在工业级点击率预估场景,上述方法的应用都变得十分困难,主要难点在于如何兼顾通用性和高效性。
通用性:需要无缝兼容各业务线任意结构的生产模型,点击率预估模型近些年在表示能力方面取得了显著的进展,需要站在巨人的肩膀上在预估点击率同时给出置信度估计;
高效性:需要尽可能减少在线的计算和存储诉求,能在实际意义上高效地提供在线置实时置信度服务。
这两个特性在过去的实践中很难同时满足。受到贝叶斯方法与深度学习技术最新进展的启发,我们将深度模型的表示能力和高斯过程的函数分布建模能力相结合,提出DUAL(Deep Uncertainty-Aware Learning)方法,得以兼顾通用性和高效性。
主要思路
我们将点击率模型视为点击率随输入特征变化的函数 。在贝叶斯视角下,点击率预估的不确定性可以通过函数 的不确定性来刻画。首先,我们定义函数 ,这里借助了 Sigmoid 函数的逆函数,主要目的是将点击率值 转换到实数值,以便函数建模。我们假设函数 的先验分布为 ,先验分布表达了我们对函数 的先验认识,例如点击率随特征连续、光滑变化等。在获得数据样本 后,通过贝叶斯推断,可以得到 的后验分布(表达我们对函数 的后验认识):
具体地,我们假设了 的先验分布为高斯过程(常见的函数先验),即:
并根据点击样本Label的二值性,对Label 定义 Logistic 似然函数:,其中 为 Sigmoid 函数。
根据高斯过程的定义(任意有限多个点处函数值联合分布为高斯分布),训练样本 和测试样本 处的函数值服从联合高斯分布:
其中, , , 是 矩阵,。进而结合训练样本Label 的似然,有联合分布:
从中我们可以推断出预测点击率 的后验分布,从而得到我们需要的不确定性:
但是,直接使用高斯过程建模点击率会遇到两个挑战:
表示能力:如何针对稀疏+高维特征设计核函数?如何结合表示学习的新进展?
计算效率:如何在大规模数据下进行贝叶斯推断?计算/存储复杂度如何?
Deep Kernel — 在隐空间中进行高斯过程建模
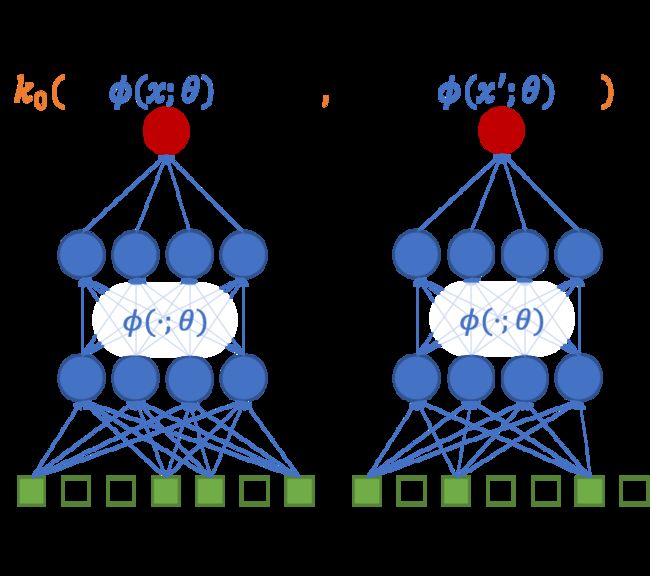
表示能力上,在上述建模中引入深度结构,是复用现有点击率模型迭代成果的关键。因此,我们结合高斯过程的基础核函数 和深度结构表示能力 ,定义深度核:
也可以理解为我们在深度结构映射后的隐空间中进行高斯过程建模。通过深度核方法,我们可以兼容任意结构的深度学习模型,这带来了很强的通用性。
高斯过程的稀疏变分推断
从计算效率的角度,高斯过程在点击率问题上应用有两个主要困难:
小批量计算困难:高斯过程在计算后验分布时计算量大,在原始版本中,计算复杂度在 ;同时,由于后验分布 不易通过小批量样本得到无偏估计,在广告场景的大规模数据下无法进行有效计算;
非共轭分布:点击率问题中似然模型 为伯努利分布,与高斯先验非共轭,导致后验分布没有解析形式。

我们采用高斯过程的稀疏变分推断(Sparse Variational Gaussian Process)解决上述困难,主要思想为:利用变分推断方法,以由 个诱导点(Inducing Point) 诱导的高斯过程后验分布,近似真实后验分布,将推断问题转化为优化问题,来解计算困难和非共轭问题。
诱导点可以粗略地被理解为“带权重的虚拟数据样本”,它的意义是对训练样本集的一个“高度抽象概括”。这样,在具有相同先验知识(先验分布)的情况下,将少量诱导点视为数据样本推断出的后验知识(后验分布)与根据真实样本样本推断出的后验知识相似,从而实现以简驭繁(如图)。

具体地,记 ,我们可以写出 , 和 的联合分布
取变分分布 ,其中 ,通过最小化KL散度 ,可以求解出 得到近似后验分布 。从而,我们有:
其中,预测数据点击率分布的均值和方差为:
目标函数
在变分推断方法中, 散度目标函数通常可转化为一个等价的 ELBO(Evidence Lower BOund),过程如下:
即,最小化上述 散度等价于最大化 ELBO(蓝色部分)。在上面的ELBO目标中,由于 是高斯分布,期望部分可在采用重参数化技巧(Reparametrization Trick)的基础上,通过蒙特卡洛估计/高斯积分(Gaussian quadrature)计算。ELBO中的求和形式,让我们可以轻松地通过小批量数据得到梯度的无偏估计,得以在大规模数据集上高效地训练。
实践技巧
隐空间中参数化诱导点
我们观察到诱导点 总是出现在Deep Kernel中, ,因此我们直接在隐空间参数化 以替代原空间的诱导点 ,参见下图。
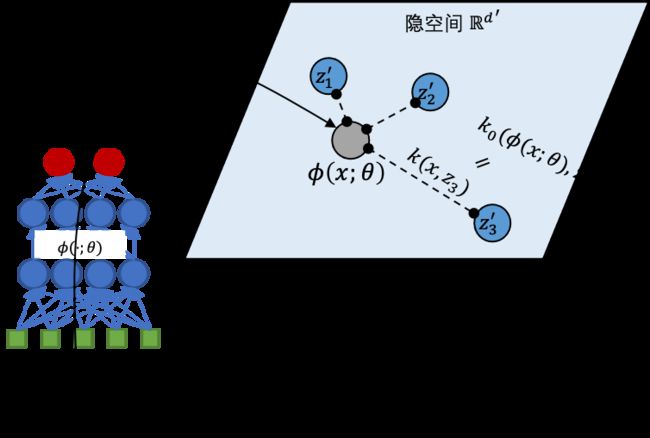
隐空间中约束诱导点位置
在隐空间中直接参数化诱导点节省了很多参数,但是带来了另一个问题:当我们随机初始化诱导点和神经网络参数时,很可能导致数据样本在隐空间中和诱导点初始距离很远,在使用 RBF 等 Kernel 时,容易引发梯度消失导致训练失败。一种优化思路是三阶段训练,先训练深度模型的高维特征表示部分(借助辅助目标函数),然后固定该部分作为 Deep Kernel 再进行高斯过程的稀疏变分推断,最后再联合训练整体 Fine-tune。但是这会降低训练效率,在大规模数据集上的训练成本很高。
显然,在一个较好的建模中,不应该存在这样一个诱导点,它远离所有的数据样本(否则总可以将它置于数据更密集的区域提升 分布表示能力)。因此,我们希望通过对数据样本和诱导点的位置关系进行约束来解决上述问题。受 K-means 的启发,我们设计了一种类似聚类目标的正则化约束,约束每个数据样本与距离最近的一个诱导点的平方距离:
通过这一技巧,DUAL 方法极大提高了训练效率和训练稳定性。
在线Inference加速
观察点击率后验分布的均值和方差的计算表达式,可以发现仅 需要在线计算,而 和 均可离线计算并存储。
通过这个技巧,除去 Deep 部分以外计算复杂度为 ,参数量 ,在线 Inference 中 GP 部分的计算量和参数量几乎等同于一层全连接网络。
▐ 基于DUAL的探索策略
现在,我们的点击率预估从点估计 变成了分布估计 ,因此我们就有了关于预估置信度的表达。受Bandit方法启发,我们提出两种考虑置信的 平衡广告投放过程中的探索和利用问题,从而实现更优的长期效用。
DUAL-UCB(Upper Confidence Bound):使用点击率的置信区间上界进行广告排序,形式化描述为:
其中 和 表示在 处预估值 后验分布的均值和方差, 是用于平衡探索和利用程度的超参数。
DUAL-TS(Thompson Sampling):使用点击率的后验分布的随机采样作为点击率估计,对广告进行排序,形式化描述为:
关于 UCB 和 TS 方法的分析和原理,这里就不展开说明了。直观上,两种方法都鼓励不确定性较高的广告被展示,因而具备探索的能力;同时,当广告展示次数上升时,不确定性下降,因此在低质量广告上的探索次数&成本可控,不会造成大量浪费。
▐ 实验结果
我们在阿里妈妈外投广告业务场景和多个公开数据上证明了 DUAL 方法的有效性。我们首先观察了将 DUAL 和几种深度 CTR 预估模型结构相结合的性能。然后我们验证了基于 DUAL 的探索策略对最大化长期目标的有效性。
CTR预估准度实验
DUAL可以看做一个模块组件,无缝接入到现有深度CTR预估模型中,以提供额外的不确定性预估。为了验证DUAL是否会损害原始的CTR预估模型的性能,我们在Amazon数据集Books和Electronics进行了实验,对比原深度CTR模型和加上DUAL后的深度CTR模型的性能。结果如表1、表2所示,我们发现,DUAL并不会损害原有模型的预估性能,反而带来了略微的提升。同时,在业务数据集中也能观察到AUC指标持平。

DUAL探索效率实验
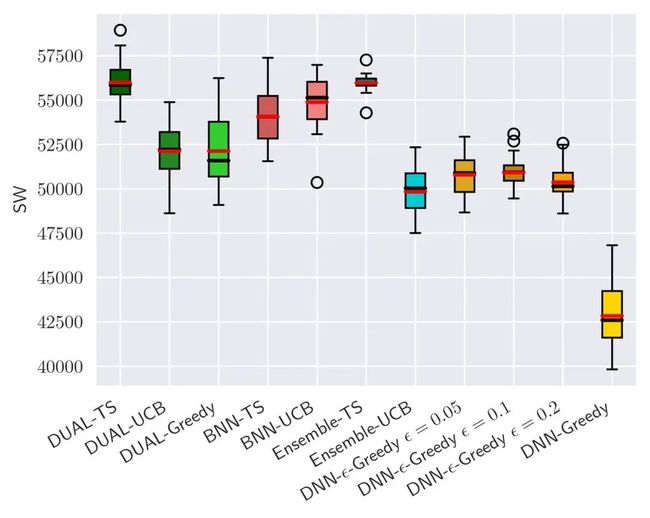
DUAL方法的目标是提供点击率预估的不确定性的估计,用以提供高效平衡探索和利用的能力,突破数据循环,带来长期收益提升。为此,我们在Yahoo! R6B数据集上进行了DUAL探索效率对比实验,实验结果如图所示,DUAL-TS显著优于所对比的其他方法,特别是对比无探索的DNN-Greedy(代表典型系统),提升了30.7%。
▐ 总结与展望
简单总结,我们提出了一个新的 CTR 预估模型训练方法 DUAL,在给出预估的同时,还能给出预估的不确定性;同时它能够兼容任意的深度 CTR 模型结构,可以无缝接入各个业务模型;并且几乎不需要额外的在线计算和存储资源;基于 DUAL 我们有提出了置信度感知的探索策略,能够优化长期的收益。
对于数据循环和探索与利用问题,我们的工作只是一个初步的尝试。在实际的系统中,还有很多其他环节都参与到了数据循环当中。显然,数据循环是整个系统层面的问题,如何联动各个模块在系统层面进行探索与利用,将是一个极具挑战的任务,也是接下来我们努力的方向。
最后,欢迎感兴趣的同学加入我们!
简历投递邮箱:[email protected]
参考文献
[1] Li, Lihong, et al. "A contextual-bandit approach to personalized news article recommendation." Proceedings of the 19th international conference on World wide web. 2010.
END

欢迎关注「阿里妈妈技术」,了解更多~

疯狂暗示↓↓↓↓↓↓↓