【目标检测】yolo系列:从yolov1到yolov5之YOLOv2详解及复现
YOLO v2
Yolov2论文链接:YOLO9000: Better, Faster, Stronger
yolov2的改进
从Yolov2论文的标题可以直观看到就是Better、Faster、Stronger。Yolov1发表之后,计算机视觉领域出现了很多trick,例如批归一化、多尺度训练等等,v2也尝试借鉴了R-CNN体系中的anchor box,所有的改进提升,下面逐一介绍。
1. Batch Normalization(批归一化)*
检测系列的网络结构中,BN逐渐变成了标配。在Yolo的每个卷积层中加入BN之后,mAP提升了2%,并且去除了Dropout。
2. Dimension Clusters(Anchor Box的宽高由聚类产生)
这里是yolov2的一个创新点。在v2中,Anchor Box的宽高不经过人为手动获取,而是将训练数据集中的矩形框全部拿出来,用k-means聚类的方式学习得到先验框的宽和高,目的使得大框小框的损失同等衡量。例如使用5个Anchor Box,那么k-means聚类的类别中心个数设置为5。
聚类必须要定义聚类点( 矩形框(w, h) )之间的距离函数,使用(1-IOU)数值作为两个矩形框的的距离函数,如下函数所示:
d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) d(box, centroid) = 1 - IOU(box, centroid) d(box,centroid)=1−IOU(box,centroid)
聚类的结果发现,聚类中心的目标框和以前手动选取的不大一样,更多的是较高、较窄的目标框。聚类结果也有了更好的性能。
3. Box Regression(框回归)
YOLOv2对框回归过程进行了改进,过去的框回归过程,由于对 t x t_{x} tx和 t y t_{y} ty参数没有约束,使得回归后的目标框可以位移到任意位置,这也导致YOLO的框回归中存在不稳定性。改进的做法为引入sigmid函数,对预测的 x x x 和 y y y进行约束。
YOLOv2在框回归时,为每一个目标框预测5个参数: t x t_{x} tx, t y t_{y} ty, t w t_{w} tw, t h t_{h} th, t o t_{o} to,调整的计算公式为:
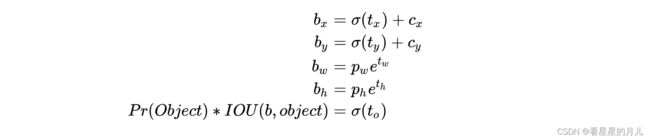
- c x c_{x} cx, c y c_{y} cy为格子的左上角坐标(行列值), p w p_{w} pw, p h p_{h} ph为anchor原始的宽度。
- 当 t x = 0 t_{x}=0 tx=0时, σ ( t x ) = 0.5 \sigma(t_x)=0.5 σ(tx)=0.5, b x b_{x} bx刚刚好位于格子中间。
- t w t_{w} tw, t h t_{h} th用来控制宽高的缩放, t o t_{o} to用来表达置信度信息。
通过使用sigmod函数,将偏移量的范围限制到0到1之间,使得预测框的中心坐标总位于格子内部,减少了模型的不稳定性。
另外,YOLOv2的分类置信度不再共享,每个anchor单独预测。即每一个anchor得到C+5 的预测值。
4. Fine-Grained Features(细粒度特征)
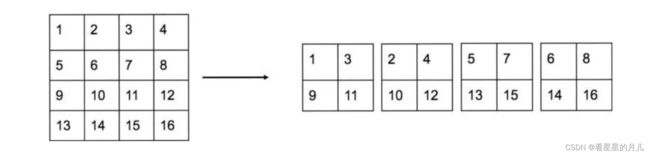
在26 * 26的特征图,经过卷积层等,变为13 * 13的特征图后,作者认为损失了很多细粒度的特征,如图所示,导致小尺寸物体的识别效果不佳,所以在此加入了passthrough层。
passthrough层在预测时使用,将网络中间层的特征图输出(具体见下图),将降采样时同一位置的像素分解成4个子图,concat合并起来。变换后通道数变为4倍,降采样2倍。如从512×26×26变为2048×13×13,在这一次操作中不损失细粒度特征。
passthrough层的使用,融合了较高分辨率下的特征信息。
5. Multi-Scale Training(多尺寸训练)
Yolov2的网络结构中只有卷积层与池化层,为了增加网络的鲁棒性,YOLOv2在训练过程中可以动态调整网络的输入大小,同时相应地调整网络的结构以满足输入。整个网络的降采样倍数为32,只要输入的特征图尺寸为32的倍数即可(如果网络中有全连接层,就不是这样了)。所以Yolo v2可以使用不同尺寸的输入图片训练。
作者使用的训练方法是,在每10个batch之后,就将图片resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如输入图片是320 * 320,那么输出格点是10 * 10,如果每个格点的先验框个数设置为5,那么共输出500个预测结果;如果输入图片大小是608 * 608,输出格点就是19 * 19,共输出1805个预测结果。
网络结构
YOLOv2中使用了一种新的基础网络结构,基于Googlenet,名为Darknet-19。拥有19个卷积层和5个Max Pooling层,网络中使用了Batch Normalization来加快收敛。
v2中移除了v1最后的两层全连接层,全连接层计算量大,耗时久。v2主要是各种trick引入后的效果验证,建议不必纠结于v2的网络结构。
训练过程
主要的训练过程为:
(1)先使用ImageNet数据集对Darknet-19进行分类训练,输入图片大小为224×224,包含标准的数据扩充方式。
(2)将输入图片大小调整为448×448,进行fine-tune。
(3)去掉分类的输出层,添加上文提到的目标检测输出层,进行目标检查的训练。
YOLOv2在上述训练的基础上,又进行了一个联合训练,额外使用只包含标签信息的数据集来进行分类训练,扩大网络可以预测的物体种类数,使其变得更加强大,即YOLO9000。
使用教程
源码地址(pytorch版本):https://github.com/longcw/yolo2-pytorch
(注意,该项目不再维护,并且可能和yolo4后的项目不兼容)
注 1: 这仍然是一个实验项目。VOC07 测试 mAP 约为 0.71(在 VOC07+12 trainval 上训练)。
注意 2: 建议使用torch.utils.data.Dataset编写自己的数据加载器, 因为multiprocessing.Pool.imap即使没有足够的内存空间也不会停止。
Installation and demo
- Clone仓库
- 下载训练模型的权重文件 yolo-voc.weights.h5 (link updated) 并且在demo.py中设置其路径。
- 运行demo.py.
Training YOLOv2
可以在任意数据集上训练yolov2,这边,将以VOC2007/2012数据集为示例。
1. 下载训练、验证、测试数据和 VOCdevkit并解压
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tar
2. 数据集结构目录按如下组织
$VOCdevkit/ # development kit
$VOCdevkit/VOCcode/ # VOC utility code
$VOCdevkit/VOC2007 # image sets, annotations, etc.
# ... and several other directories ...
3. 下载预训练模型
下载预训练模型darknet19,然后在yolo2-pytorch/cfgs/exps/darknet19_exp1.py.中设置路径。
4. 可视化训练过程
要使用 TensorBoard,需要在 yolo2-pytorch/cfgs/config.py 中设置 use_tensorboard = True 并安装 TensorboardX。 Tensorboard 日志将保存在训练/运行中。
5. 运行训练代码:python train.py.
Evaluation
在yolo2-pytorch/cfgs/config.py中设置把训练好的模型的路径。
然后运行预测代码。
Training on your own dataset
如果需要在自己的数据集上训练,前向传递要求向网络提供乳腺癌 4 个参数:
- im_data - 图像数据。
- 这应该是 C x H x W 格式,其中 C 对应于图像的颜色通道,H 和 W 分别是高度和宽度。颜色通道应为 RGB 格式。
- 使用 utils/im_transform.py 中提供的 imcv2_recolor 函数来预处理图像。 此外,请确保图像已调整为 416 x 416 像素
- gt_boxes - numpy 数组的列表,其中每个数组的大小为 N x 4,其中 N 是图像中的特征数。 每行中的四个值应对应于 x_bottom_left、y_bottom_left、x_top_right 和 y_top_right。
- gt_classes - numpy 数组的列表,其中每个数组包含一个整数值,对应于 gt_boxes 中提供的每个边界框的类
- dontcare - 列表的列表