【支持向量机】最大间隔超平面及Matlab代码
线性可分
在特征空间中,有两个训练样本可以通过一条直线区分开,则称为线性可分。而在特征空间大于等于四维时,分开训练样本的平面,称为超平面。
我们定义一条直线方程: ω 1 x 1 + ω 2 x 2 + b = 0 ω_1x_1+ω_2x_2+b=0 ω1x1+ω2x2+b=0
权重: ω 1 , ω 2 ω_1,ω_2 ω1,ω2 偏置: b b b
⇒ { ω 1 x 1 + ω 2 x 2 + b > 0 ( i ∈ 1 ~ n , y i > 1 ) ω 1 x 1 + ω 2 x 2 + b < 0 ( i ∈ 1 ~ n , y i < 1 ) ⇒ \left\{ \begin{array}{c} ω_1x_1+ω_2x_2+b>0 &(i∈1~n,y_i>1) \\ ω_1x_1+ω_2x_2+b<0 &(i∈1~n,y_i<1)\\ \end{array} \right. ⇒{ω1x1+ω2x2+b>0ω1x1+ω2x2+b<0(i∈1~n,yi>1)(i∈1~n,yi<1)
我们规定 y y y为训练样本的标签。
⇒ { y i = { − 1 , + 1 } x i = [ x i 1 , x i 2 ] T ⇒ \left\{ \begin{array}{c} y_i=\{ -1,+1 \}\\ x_i=\begin{gathered} \begin{bmatrix} x_{i1} , x_{i2} \end{bmatrix}^T \end{gathered}\\ \end{array} \right. ⇒{yi={−1,+1}xi=[xi1,xi2]T
假设:
x = [ x i 1 x i 2 ] T ω = [ ω i 1 ω i 2 ] T x=\begin{bmatrix} x_{i1}\\ x_{i2} \end{bmatrix}^Tω=\begin{bmatrix} ω_{i1}\\ ω_{i2} \end{bmatrix}^T x=[xi1xi2]Tω=[ωi1ωi2]T
上述样本关系即可转化为:
⇒ { ω T x i + b > 0 ( i ∈ 1 ~ n , y i > 1 ) ω T x i + b < 0 ( i ∈ 1 ~ n , y i < 1 ) ⇒ \left\{ \begin{array}{c} ω^Tx_i+b>0 &(i∈1~n,y_i>1) \\ ω^Tx_i+b<0 &(i∈1~n,y_i<1)\\ \end{array} \right. ⇒{ωTxi+b>0ωTxi+b<0(i∈1~n,yi>1)(i∈1~n,yi<1)
我们可以得到一个严格的数学定义来判断训练样本是否线性可分:
y i ( ω T x i + b ) > 0 y_i(ω^Tx_i+b)>0 yi(ωTxi+b)>0
最大间隔
在二分类的情况下,如果一个数据集是线性可分的,即存在一个超平面将两个类别完全分开,那么一定存在无数多个超平面将这两个类别完全分开。
在机器学习中,我们不仅得关注训练误差,而且需要关注期望损失。在下图中,靠近训练样本的超平面,对噪声的影响是非常敏感的。如果噪声大于最小距离,那么分类就会出错。我们称:这个超平面的鲁棒性较差。
为了使这个超平面更具鲁棒性,我们会去找最佳超平面,以最大间隔把两类样本分开的超平面,也称之为最大间隔超平面。

最优化问题
SVM 想要的就是找到各类样本点到超平面的距离最远,也就是找到最大间隔超平面。通过上述条件可以得知,分开训练样本的最优超平面需具有三个特性:
- 可以分开两类训练样本;
- 平移这个超平面,使它刚好擦过特征空间中的样本点时,这些样本点称为支撑向量,且支持向量到超平面有最大化间隔(margin);
- 最大间隔的超平面应处于间隔中心,到所有支持向量距离相等。
任意超平面可以用下面这个线性方程来描述:
ω T x + b = 0 ω^Tx+b=0 ωTx+b=0
二维空间点 ( x , y ) (x,y) (x,y)到直线 A x + B y + C = 0 Ax+By+C=0 Ax+By+C=0的距离公式是:
∣ A x + B y + C ∣ A 2 + B 2 \frac{|Ax+By+C|}{\sqrt{A^2+B^2}} A2+B2∣Ax+By+C∣
根据 ∣ y i ∣ = 1 ⇒ y ( ω T x + b ) = ∣ ω T + b ∣ |y_i|=1⇒y(ω^Tx+b)=|ω^T+b| ∣yi∣=1⇒y(ωTx+b)=∣ωT+b∣,拓展到n维空间后,点 x = ( x 1 , x 2 … x n ) x=(x_1,x_2…x_n) x=(x1,x2…xn)到直线 ω T x + b = 0 ω^Tx+b=0 ωTx+b=0的距离为:
d = y ( ω T x + b ) ∣ ∣ ω ∣ ∣ = ∣ ω T x + b ∣ ∣ ∣ ω ∣ ∣ d=\frac{y(ω^Tx+b)}{|{|ω||}}\\=\frac{|ω^Tx+b|}{|{|ω||}} d=∣∣ω∣∣y(ωTx+b)=∣∣ω∣∣∣ωTx+b∣
其中
∣ ∣ ω ∣ ∣ = ω 1 2 + … ω n 2 ||ω||=\sqrt{ω^2_1+…ω^2_n} ∣∣ω∣∣=ω12+…ωn2
根据:
s . t . : y i ( ω T x i + b ) > 0 s.t. :y_i(ω^Tx_i+b)>0 s.t.:yi(ωTxi+b)>0
⇒ ∃ γ > 0 , y i ( ω T x i + b ) = γ ⇒\exists \gamma >0,y_i(ω^Tx_i+b)=\gamma ⇒∃γ>0,yi(ωTxi+b)=γ
对超平面进行缩放:
∃ ( ω , b ) ⇒ ( α ω , α b ) \exists (ω,b)⇒(\alpha ω,\alpha b) ∃(ω,b)⇒(αω,αb)
缩放对于超平面并无影响,规定 γ = 1 \gamma =1 γ=1,使 ∣ ω T x + b ∣ = 1 |ω^Tx+b|=1 ∣ωTx+b∣=1
⇒ { 1 ∣ ∣ ω ∣ ∣ = d y i ( ω T x i + b ) = 1 ⇒ \left\{ \begin{array}{c} \frac{1}{||ω||}=d \\ y_i(ω^Tx_i+b)=1 \end{array} \right. ⇒{∣∣ω∣∣1=dyi(ωTxi+b)=1
再做一个变化:
m a x 1 ∣ ∣ ω ∣ ∣ ⇔ m i n ∣ ∣ ω ∣ ∣ 2 2 max\frac{1}{||ω||}⇔min\frac{||ω||^2}{2} max∣∣ω∣∣1⇔min2∣∣ω∣∣2
所以得到最优化问题是:
⇒ { m i n ∣ ∣ ω ∣ ∣ 2 2 y i ( ω T x i + b ) > 1 ⇒ \left\{ \begin{array}{c} min\frac{||ω||^2}{2} \\ y_i(ω^Tx_i+b)>1 \end{array} \right. ⇒{min2∣∣ω∣∣2yi(ωTxi+b)>1
Matlab代码
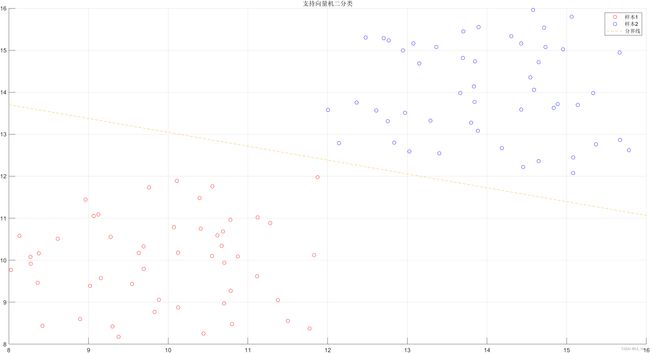
%% 线性可分数据用支持向量机分类,其求解采用二次规划函数
clc;clear;
% 初始化数据集
random_1 = unifrnd(8,12,100,2);
random = [random_1(1:50,:);random_1(51:100,:)+4];
y = [zeros(50,1)-1;ones(50,1)]; % 标签数据
X = random; % 特征数据
% 可视化
scatter(random(1:50,1),random(1:50,2),'red')
hold on
grid on
scatter(random(51:100,1),random(51:100,2),'blue')
%% 采用Matlab自带的二次规划函数求解问题
% 构建二次系数矩阵H
H = [];
for i =1:length(X)
for j = 1:length(X)
H(i,j) = X(i,:)*(X(j,:))'*y(i)*y(j);
end
end
% 构造一次项系数f
f = zeros(length(X),1)-1;
A = [];b = []; % 不等式约束
Aeq = y';beq = 0; % 等式约束
ub = [];lb = zeros(length(X),1); % 自变量范围
[x,fval] = quadprog(H,f,A,b,Aeq,beq,lb,ub);
% x表示自变量的解,以及在x处的函数值
% 将很小的x直接赋值为0
x(x < 1e-5) = 0;
% 利用求解得到x求解系数w
w = [0,0];
[a,~] = find(x~=0); % 找到可以求解b的值
temp = 0;
for i = 1:length(X)
w = w + x(i)*y(i)*X(i,:);
temp = temp + x(i)*y(i)*X(i,:)*X(a(1),:)';
end
% 计算偏置系数
b = y(a(1)) - temp;
% 数据可视化
k = - w(1)/w(2); % 构造截距式
b_ = -b/w(2); % 构造系数b
m = 8:2:16; % 生成一些点
n = k*m+b_;
plot(m,n,'--')
n_2 = k*m+b_+1/w(2);
hold on
plot(m,n_2,'--')
n_3 = k*m+b_-1/w(2);
plot(m,n_3,'--');
grid on
title('支持向量机二分类')
legend('样本1','样本2','分界线')
% 添加文本说明可视化
% 获取支持向量下标
Vctor_index = find(x~=0);
% 对下标进行分类
Vctor_length = length(Vctor_index); % 获取支持向量的个数
category_1 = []; % 定义第一类
category_2 = []; % 定义第二类
% 对支持向量的下标进行遍历然后一一分类
for i =1:Vctor_length
if y(Vctor_index(i))==-1
category_1 = [category_1;Vctor_index(i)];
else
category_2 = [category_2;Vctor_index(i)];
end
end
% 分类进行可视化
%绘制第一类category_1,用红色填充
scatter(X(category_1,1),X(category_1,2),'filled','r','HandleVisibility','off')
t1 = text(X(category_1,1)+0.1,X(category_1,2)-0.1,'支持向量','Color','red');
t1.Color = 'red';
% 绘制第二类category_2,用蓝色填充
scatter(X(category_2,1),X(category_2,2),'filled','blue','HandleVisibility','off')
t2 = text(X(category_2,1)+0.1,X(category_2,2)-0.1,'支持向量','Color','blue');
% 计算支持向量到超平面的距离
D_1 = abs(w*X(category_1(1),:)'+ b)/norm(w,2);
D_2 = abs(w*X(category_2(1),:)'+ b)/norm(w,2);
disp(['正类支持向量到超平面的距离为',num2str(D_1)])
disp(['负类支持向量到超平面的距离为',num2str(D_2)])