【跨模态】【对比学习】CLIP:文本监督CV的预训练(2021)
文章目录
- 前言
- 一、整体架构
-
- 1.训练
- 2.测试(迁移学习zero shot)
- 3.prompt engineering and ensembling
- 二、实验
-
- 1.few-shot与zero-shot的对比
- 2.Representation Learning
- 3.模型的泛化性
- 三、局限性和不足
- 四、拓展应用:DALL-E 与 DALL-E2
-
- 1.DALL-E
- 2.DALL-E2
- 五、拓展应用(三篇CVPR2022论文):
-
- 1.ActionCLIP
- 2.CLIP-Event
- 3.CLIPSeg
前言
提示:CLIP 也属于对比学习、跨模态和zero shot
CLIP:Contrastive Language-Image Pre-Training
论文:Learning Transferable Visual Models From Natural Language Supervision
地址:https://arxiv.org/abs/2103.00020
代码:github.com/OpenAI/CLIP(仅开源测试)
CLIP算是在 跨模态训练无监督 中的开创性工作,作者在开头梳理了CV方向的训练方式,从有监督的训练,到弱监督训练,再到最终的无监督训练。这样训练的好处在于可以避免的有监督的 categorical label的限制,具有zero-shot性质,极大的提升了模型的实用性能。
zero-shot:是指零样本学习,在别的数据集上学习好了,直接迁移做分类;
作者提到早在2017年之后就陆续有工作提出和本文类似的想法,但是他们的数据大小都太小了,导致没有很好的结果。作者单独收集了一份含有4亿份数据的大数据集,才得以得到很好的效果。此外作者提到prompt engineering and ensembling也是一个值得研究的方向,也就是生成的template如果能够结合对应的dataset的特征,相当于给予模型额外的信息。
为什么CLIP要采用对比学习的方法:
OpenAI是一家从来不愁计算资源的公司,他们喜欢将一切都gpt化(就是做生成式模型);但是以往的工作表明(ResNeXt101-32x48d, Noisy Student EfficientNet-L2),训练资源往往需要很多,何况这些都只是在ImageNet上的结果,只是1000类的分类任务,而CLIP要做的是开发世界的视觉识别任务,所以训练的效率对于自监督的模型至关重要;而如果任务改为给定一张图片去预测一个文本(或者给定一个文本去预测一张图片),那么训练效率将会非常低下(因为一个图片可能对应很多种说法,一个文本也对应着很多种场景);通过从预测任务改为只预测某个单词到只选出配对的答案,模型的训练效率一下提升了4倍;

一、整体架构
1.训练
contarstive pretrain

作者团队收集的4亿的图片文本对作为训练样本,称之为WIT(WebImage Text);在一个batch中输入32768个图片文本对,【 I_1 , T_1 】,则是第一个图像文本对,模型的目的是使这两个特征尽量相似,而与别的特征尽量远离。
训练阶段伪代码为:

1.一个图片经过Image_encoder得到特征I_f ,一个文本经过text_encoder得到特征T_f ;
2.两个特征分别经过不同的FC层(目的是将单模态的特征转化为多模态,因为图片的 特征可能本身就与文本的不一致,需要转换,但是这里没接激活函数,因为作者发现在多模态下接不接都一样);
3.再做一次L2归一化;
4.计算余弦相似度,得到logits;
5.logits与GT计算交叉熵目标函数(这里的GT就是一个单位阵,因为目标是配对样本之间相似性最强为1,而其他为0);
6.最后将图片的loss与文本的loss加起来求平均;
backbone:
文本采用Transformer;
图像方面可选5种ResNets(ResNet-50,ResNet-101,3个EfficientNet的变体,ResNet-50x4,ResNet-50x16,ResNet-50x64), 三种VIT(分贝是VIT-B/32,VIT-B/16,VIT-L/14)
2.测试(迁移学习zero shot)
之前自监督、无监督的方法,主要研究特征学习能力,模型的目标是学习泛化性能好的特征,但在下游任务中,还是需要有标签数据做微调。作者想仅训练一个不需微调的模型。
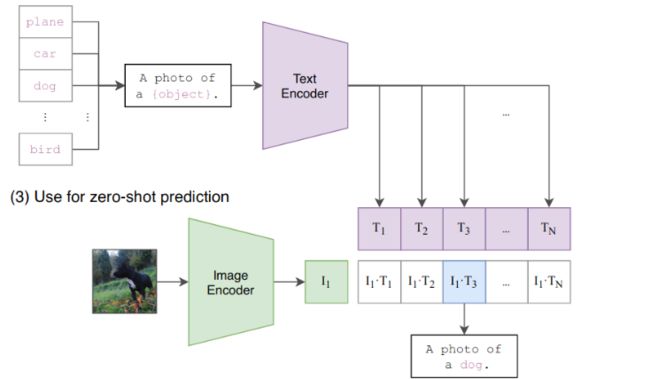
将要做的分类以填空的形式填进一句话中,以ImageNet为例就是1000句话输入Text Encoder得到输出;
将要识别的图片经过Image Encoder得到图片输出,比较文本的输出与图片的输出,选择最相似的那句话就是图片的类别;
3.prompt engineering and ensembling
Prompt是提示的意思,对模型进行微调和直接做推理时有效;加入这个prompt engineering and ensembling,准确度上升了1.3%
1.由于一个word 具有多义性(polysemy),图片和文字匹配容易出错,所以作者将word放在语境中,来提高匹配度;
2.另一个问题是,在预训练的时候,匹配的文本一般都是一个句子,很少出现一个单词的情况,如果推理的时候,每次进来的是一个单词,可能就存在distribution gap的问题,抽出来的特征可能就不好。
基于这两个问题,提出了prompt template,利用这个模板“A photo of a {label}.” 把单词变成一个句子, 避免出现distribution gap
作者还尝试集成多个zero shot classifiers,即prompt ensembling ,作为提高性能的另一种方式。这些分类器是在不同的上下文提示下得到的,比如“A photo of a big {label}" 和”A photo of a small {label}"。,这比单个的default prompt 提高了3.5%的性能。
最后在CLIP中,总共用了80个prompt template之多。prompt_Engineering_for_ImageNet.ipynb 列出了使用的这80个context prompts,比如有"a photo of many {}"适合包含多个物体的情况,"a photo of the hard to see {}"可能适合一些小目标或比较难辨认的目标。
二、实验
大范围数据集结果:
做了27个数据集的分类任务,baseline是ResNet-50,ResNet-50是有监督模型在各个数据集上训练好的, 然后两个模型在其他数据集上zero-shot;

在大多数分类任务,给车、食物等做分类的问题上CLIP都表现的很好, 但是在DTD这种纹理进行分类或CLEVRCounts给物体计数的任务,对于CLIP无监督模型来说就很难了;所以作者认为在这些更难的数据集做few-shot可能比zero-shot更好;
1.few-shot与zero-shot的对比
few-shot也是将back-blone冻住,训练分类头;
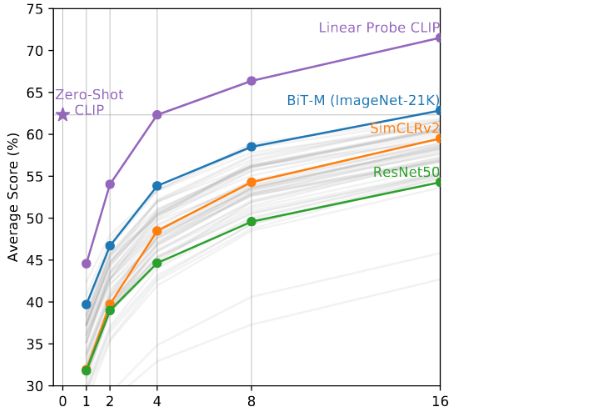
横坐标是指在每个类别中选出了几个训练样本,纵坐标就是模型的准确率了(在20个数据集上的平均结果,因为有7个数据集中有些训练样本不足16个);
因为别的模型不是多模态的,所以只能从1-shot开始;
其中,BiT-M是google中bit transfer的一个模型,专门为迁移学习量身定做的,而zero-shot的CLIP直接与few-shot的BiT-M打成平手;
而CLIP可以从zero-shot开始;
可以看出当学习样本很少的时候CLIP few-shot的表现还不如zero-shot;
2.Representation Learning
为了证明Pre-Train的成功,CLIP将预训练好的模型在下游任务中做了Linear probe,就是模型主体冻住,只调Linear分类头,因为这样不用太多的调参,也能证明模型的特征学的好不好;

其中横坐标是一次前向过程的计算量,纵坐标是分类准确度;
可以看出CLIP是在计算量与准确度方面trade-off做的最好的一个模型;
3.模型的泛化性
当数据有distribution shift的时候,模型的表现如何,这是CLIP最惊艳的结果:
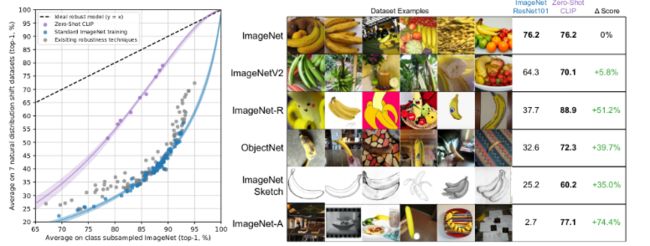
可以看出CLIP在数据分布的偏移样本上,远远超过ResNet101,而且结果保持地依旧稳健;
三、局限性和不足
平均来看,CLIIP可以和机械模型(ResNet-50(在ImageNet上训练))持平, 若继续增加数据集和模型规模,CLIP性能可以继续提高,但是代价很大(需提高计算和数据的高效性。
zreo-shot结果并不好
在细分类数据集上,CLIP效果低于(有监督训练)ResNet-50(baseline网络);
CLIP无法处理抽象概念,如数数任务,或者判断一个监控画面是正常还是异常;
在很多领域,CLIP性能和瞎猜差不多;
若数据集中的data 已经 out-of-distribution,那么CLIP-model泛化照样差;(在MNIST数据集上,CLIP准确率仅有88%; 因为作者收集的数据集有4亿个样本,但没有和MINIS长得像的,所以MINIS数据集对于CLIP来说就是out-of-distribution数据集);
CLIP不能高效利用数据
训练了epoch = 32,每个epoch过4亿个图片,跑了128亿张图片,如果一秒一张需要405年;数据用量多,作者希望减少数据用量,(三种方案: 数据增强,自监督,伪标签)用所有数据进行训练,调整很多次模型结构和超参数,才得出好结果,且每次用ImageNet数据集作为指导。所以CLIP并非做出真正的zero-shot工作。(选择偏差)
爬取图片未清洗和审查语言无法描述太复杂的概念
论文中总结的不足:(很少有论文写自己的不足,赞一个)

四、拓展应用:DALL-E 与 DALL-E2
1.DALL-E
DALL-E是CLIP的下游应用,给文本描述,可以生成对应图像:
![]()
萝卜在遛狗:

其基本原理为 VQGAN + CLIP。VQGAN(由VAE改进) 相当于生成器,CLIP相当于判别器,计算文本特征与生成图像特征的相似度(相似表明生成的图像质量高)。VQGAN 基本原理如下图,先利用特征字典codebook将图像特征离散化(即在codebook中查找最接近的特征,作为图像某一patch特征),在decoder阶段利用CLIP计算离散的图像特征与文本特征关系(文本特征本就是离散的word)。其中,codebook可利用Transformer结构进行监督学习。

DALL-E 生成图像过程,类似于GPT中预测下一个token过程。根据输入的初始图像(也可以是噪音)和文本,来得到输出图像。具体参数是256维文本 token 与 1024维图像 token。输入transformer结构中。

由于项目未开源,可以试试以下的非官方源:
![]()
2.DALL-E2
分辨率达到1024,是4倍dalle,还可编辑图像属性。可登录openai.com/dall-e-2 查看demo

甚至一些人类世界没有的东西(扩展与泛化能力很强,毕竟学习了4亿数据)

五、拓展应用(三篇CVPR2022论文):
1.ActionCLIP
论文:ActionCLIP :A new paradigm for Video Action Recognition

2.CLIP-Event
论文:CLIP-Event:Connecting Text and Images with Event Structures
将事件中的人与动作链接起来,相当于先通过文本抽取一些关系组合,再与图像进行配对

- 如图左,先从文本中抽像出一些单元组:


- 定义正负样本
正样本就是抽取的事件,负样本为替换的其他事件,也可替换动作主体。

能区别不同检测目标与事件的关系信息:

3.CLIPSeg
论文地址:https://arxiv.org/abs/2112.10003
代码地址:https://github.com/timojl/clipseg