度量学习DML—Deep Metric Learning
前言
生活中对于常用的度量有欧式距离、KL散度等,但是这些度量都是人工定义的。度量学习主要目标是训练神经网络使之成为一个度量,并且该度量并非人为定义而是从数据中学来(上面可能在胡说八道,不过某种意义上也可以理解为训练了一种度量,我感觉深度学习在其中就是做了一个网络嵌入,然后根据嵌入的特征向量计算欧氏距离或者其他的距离,当然训练的目标就是使得相近的样本的嵌入特征向量的距离更近,看完后面再来看这句话就知道了)。
通常通过设计loss函数的方式使得使神经网络能够生成一个度量。常用的loss函数主要有Identity Loss、Verification Loss、Triplet loss以及OIM Loss(Online Instance Matching)。其中前三种如图1所示,最后一种下文介绍。
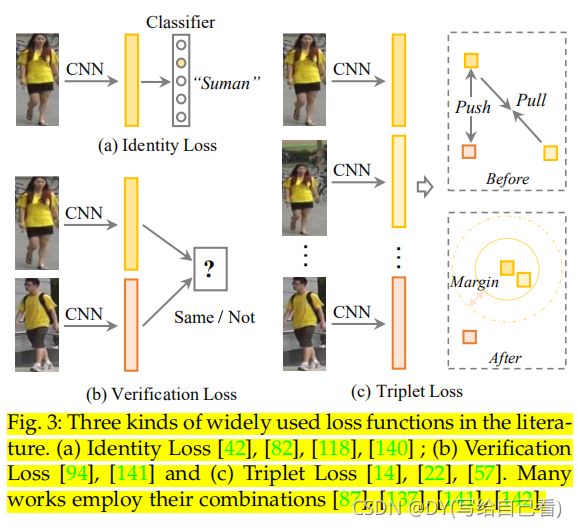 图1
图1
一、Identity Loss
Identity Loss,本质上就是人脸识别图像分类的的方法(输入输出都一模一样),如果过神经网络将几张图片分类为一个人,那么这几张图片的通过softmax后的输出肯定很接近,比如输出将图片识别为第i类,那么都是第i个输出的神经元的值最大,Identity Loss的损失函数与图像分类的损失函数相同。
二、Verification Loss
Verification Loss,如图1b所示,对于输入样本xi,CNN属于一个特征向量fi,同理对于输入xj也有一个对应的fj,设fi与fj之间的距离为dij(常常是欧式距离),同时指定一个阈值ρ,如果dij<ρ,则判定xi和xj之间的距离很近,为一个类别,否则判定为分属两个类。其损失函数定义为:
Verification Loss也有交叉熵形式:
在使用中Verificatin Loss常常与Identity Loss结合使用取得不错效果。
三、Triplet Loss
Triplet Loss,如图1c所示,首先取出三个样本点xi、xj、xk,其中xi和xj的label属于同一类别,xk属于另外一个类别,fi、fj、fk分别是对应的样本经过网络嵌入后得到的嵌入特征。Triplet Loss的主体思想就是拉近fi和fj之间的距离,拉开fi和fk之间的距离,并且希望能够达到dik-dij>ρ的地步,其中d和ρ的定义均与上文相同。其loss常常定义为:
四、OIM Loss(Online Instance Matching)
OIM Loss(Online Instance Matching)中使用了一个look up table(LUT,查询表)和一个circular queue(循环队列)。被标记过的样本称之为labeled identity,未标记的样本称之为unlabeled identity。LUT就是用来记录所有被标记过的样本labeled identity的类别特征,相当于考试考纲内的知识,是一个D*L的矩阵,D是特征的维数,L是标记过的类别数,如果样本xi属于第一类,那么就应该与LUT中的第一列的向量的距离较为接近(常常使用余弦距离,为两个向量的内积除以两个向量的模,在向量的模固定的前提下,余弦距离越大,两个向量就越接近于平行);circular queue用来记录未被标记的样本unlabeled identity的特征,相当于考试考纲外的知识,为一个D*Q的矩阵,其中D为特征维数,Q为预先定好的一个参数,表示记录最近看过的Q个unlabeled identity的特征。
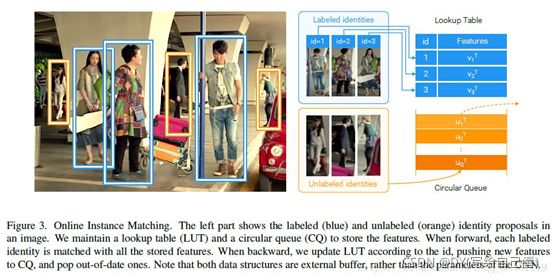
如上图,蓝色框内标记的是labeled identity,即被有label的标记过的人,黄色框内的是unlabeled identity,训练时就将一个新的unlabeled identity的嵌入特征push如circular queue,pop出一个最老的unlabeled identity的嵌入特征(也就是把它遗忘掉)。蓝色框内的图像作为神经网络的输入得到的输出,即为嵌入特征,计算嵌入特征与LUT内每一列(即类别的特征)之间的余弦距离,同时计算嵌入特征与circular queue内每一列之间的余弦距离,然后找到使得余弦距离取得最大的那一列(在向量的模固定的前提下,余弦距离越大,两个向量就越接近于平行),如果这一列是LUT中的第i列,则判定样本属于第i列对应的那一类,如果余弦距离最大的列来自于circular queue的第j列,则判定样本是之前训练时未标记未学习的unlabeled identity,与之前见过的第j列的unlabeled identity比较接近,不属于我们判断的LUT内的类别。
因此属于LUT第i列所属的类的概率为(vi为LUT第i列,uk为circular queue第k列):
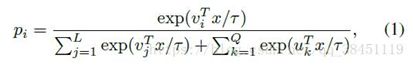 属于circular queue第i列的unlabeled identity所属类的概率为:
属于circular queue第i列的unlabeled identity所属类的概率为: 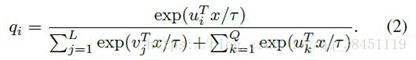 其中两式中的τ控制了概率分布的平缓程度,实验中设置为0.1(其中的vi和ui我感觉应该都会做个标准化标为单位向量,具体的没有读论文,此处只为猜测)。优化目标设置为:
其中两式中的τ控制了概率分布的平缓程度,实验中设置为0.1(其中的vi和ui我感觉应该都会做个标准化标为单位向量,具体的没有读论文,此处只为猜测)。优化目标设置为:  至于为什么不直接用普通的softmax,原因有:
至于为什么不直接用普通的softmax,原因有:
- 类别太多,而每类的正样本太少,使得训练很难
- 无法利用unlabeled identities,因为他们没有标签
LUT每训练一次,都会进行一次更新,如果训练的样本属于第t类,则:
参考
Ye M, Shen J, Lin G, et al. Deep learning for person re-identification: A survey and outlook[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
https://my.oschina.net/u/4339883/blog/3478799
https://www.pianshen.com/article/284729729/