深度迁移度量网络 Deep Transfer Metric Learning
论文地址:Deep Transfer Metric Learning
摘要(abstract)
传统的度量学习方法同城假定训练和测试集是在相同的情景获取得到,因此假设他们的分布是一样的。但是在实际视觉识别应用中,这种假设往往不符合的。特别是当这些样本来源于不同的数据集。这篇论文提出深度迁移度量学习(DTML)方法,通过将识别知识从源域迁移到目标域。网络约束条件是:最大化类内距,以及最小化类间距;源域与目标域之间的分布散度。实验针对的是人脸识别与行人在识别。
介绍(Introduction)
如何设计一个相似函数对于计算机视觉以及模式识别任务来说是比较重要的。现存的度量学习方法主要分为两种:监督的,和非监督的。监督策略:一个低维的子空间或流形(manifold)来保存样本的几何信息。非监督策略:最大化来自不同类的样本的可分离性。因为使用了训练样本的标签信息,因此监督度量学习方法对于识别任务来说更适用。
近几年来,出现了很多监督度量学习算法。存在两个缺点:(1)大多数方法都是寻求用一个线性距离将样本转换为一个线性特征空间,以至于样本的非线性关系不能被利用,尽管核方法能够被用来解决非线性问题,这些方法仍然存在可扩展性问题,因为不能获得明确的非线性映射函数。(2)大多数方法都假设训练和测试样本是在相同环境下捕捉的以及假设分布是一样的,这种假设,在实际场景下这种假设并不成立,特别是当样本来源于不同条件下的数据集。
论文提出DTML针对跨数据集视觉识别。图1说明了方法的基本思想。
通过从打标签的源域迁移判别信息到未打标签的目标域,从而学习一组非层次线性转换。 限制条件是最大化类内距,以及最小化类间距;源域与目标域之间的分布散度在顶层网络中。为进一步利用源域的监督信息,进一步提出深度监督迁移度量学习方法(隐层和顶层的输出都被优化)。
相关工作(Related Work)
深度学习: 通常情况下,深度学习旨在从原生数据中学习层次特征表示。最近的研究表明,深度学习在很多视觉任务中都取得成功。但是,大多数都旨在通过深层模型来学习特征表示而不是相似度估算。深度学习也被用于度量学习。并且有一些方法被提出,例如:文章(Deep nonlinear metric learning with independent subspace analysis)提出一种使用堆叠独立子空间分析的非线性度量学习方法;文章(Bayesian face revisited: A joint formulation)提出判别深度度量学习方法,采用的是CNN网络,通过加强顶层网络的边界标准。这些方法假定训练和测试数据集来源于相同环境下。
迁移学习: 迁移学习旨在解决来源于源域的训练数据与目标域数据分布不同的问题。过去的几十年中,大量的迁移学习方法被提出,他们主要分为两类:基于样本的和基于特征的。基于样本的方法:学习不同的权重用于排序源域的训练样本,以便更好的在目标域中进行学习。基于特征的方法:通常学习一个公共特征空间,这个特征空间能够将从源域学习到的信息迁移到目标域。一些迁移学习技术被提出,包括域迁移支持向量机(文章:Domain transfer SVM for video concept detection),降维迁移学习(文章:Transfer learning via dimensionality reduction),迁移度量学习(文章:Transfer metric learning by learning task relationships;Transfer metric learning with semisupervised extension)。方法中的大多数只考虑了通过线性映射或者核方法最小化源域与目标域分布差异,并不能有效的的迁移知识在源域和目标域的分布相差很大的情况下,并且不能获得明确的迁移函数。在这样的情况下,我们提出深度迁移度量学习方法,通过判断距离网络的学习,在一些信息来源于源域的情况下。
DTML(深度迁移度量学习)
符号表示
源域训练数据集: X s = { ( x s i , y s i ) ∣ i = 1 , 2 , ⋯ , N s } \mathcal { X } _ { s } = \left\{ \left( \mathbf { x } _ { s i } , y _ { s i } \right) | i = 1,2 , \cdots , N _ { s } \right\} Xs={(xsi,ysi)∣i=1,2,⋯,Ns},其中 x s i 属 于 R d ( d 维 ) ; N s 表 示 样 本 个 数 , y s i 属 于 1 , 2 , 3 , . . . , C s , C s 表 示 类 的 个 数 \ x_{si}属于R^d(d维);N_s表示样本个数,y_{si}属于{1,2,3,...,C_s}, C_s表示类的个数 xsi属于Rd(d维);Ns表示样本个数,ysi属于1,2,3,...,Cs,Cs表示类的个数
目标域训练数据集:
标签训练集合: X = { ( x i , y i ) ∣ i = 1 , 2 , ⋯ , N } \mathcal { X } = \left\{ \left( \mathbf { x } _ { i } , y _ { i } \right) | i = 1,2 , \cdots , N \right\} X={(xi,yi)∣i=1,2,⋯,N}要么只包含源域样本,要么包含源域和目标域样本。在论文中,只考虑标签训练集合的样本只包括源域的情况。
深度度量学习
构建一个三层网络。通过将样本 x \ x x输入非线性转换的多层网络,从而计算每个样本 x \ x x的表示(也就是一种映射)(对于x的映射网络优点在于能够获得明确的非线性映射函数)
网络结构

从下往上,输入层,隐层,输出层。参数为 W ( m ) , b ( m ) \ W^{(m)},b{(m)} W(m),b(m). 假设有 M + 1 \ M+1 M+1层网络,在第 m \ m m层有 p ( m ) \ p^{(m)} p(m)个单元数, m = 1 , 2 , . . . , M \ m=1,2,...,M m=1,2,...,M。第 m \ m m层的映射函数为 f ( m ) \ f^{(m)} f(m).

参数:![]() ;
;![]() ;权重矩阵,偏置。 φ \varphi φ表示激活函数。第一层,设定 h ( 0 ) = x , p ( 0 ) = d \ h^{(0)}=x, p^{(0)}=d h(0)=x,p(0)=d。对于一对样本 X i , X j \ X_i,X_j Xi,Xj,样本最后的表示为 f ( m ) ( x i ) , f ( m ) ( x j ) \ f^{(m)}(x_i), f^{(m)}(x_j) f(m)(xi),f(m)(xj).距离度量可以通过计算平方欧式距离。
;权重矩阵,偏置。 φ \varphi φ表示激活函数。第一层,设定 h ( 0 ) = x , p ( 0 ) = d \ h^{(0)}=x, p^{(0)}=d h(0)=x,p(0)=d。对于一对样本 X i , X j \ X_i,X_j Xi,Xj,样本最后的表示为 f ( m ) ( x i ) , f ( m ) ( x j ) \ f^{(m)}(x_i), f^{(m)}(x_j) f(m)(xi),f(m)(xj).距离度量可以通过计算平方欧式距离。
![]()
根据图像嵌入框架,对于顶层网络的所有训练样本的输出使用边缘费雪分析准则,提出强监督深度深度度量学习方法,优化函数如下:

α \alpha α为自由参数,且 α > 0 \alpha>0 α>0,平衡因子。 ∣ ∣ Z ∣ ∣ F \ ||Z||_F ∣∣Z∣∣F表示F-范数(各项元素的绝对值平方的总和)。 γ \gamma γ为正规范化参数。 S c ( m ) \ S^{(m)}_c Sc(m); S b ( m ) \ S^{(m)}_b Sb(m);分别表示类内的紧致度,类间的可分离性。定义如下:
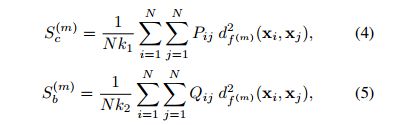
P i j \ P_{ij} Pij:对于任意样本 x j \ x_j xj,它对 x i \ x_i xi分类影响的概率。 k \ k k反映了相似度。 P i j \ P_ij Pij为1,如果 x j \ x_j xj是 x i \ x_i xi前 k 1 \ k_1 k1个类内近邻的话,否则为0。 Q i j \ Q_ij Qij为1,如果 x j \ x_j xj是 x i \ x_i xi前 k 2 \ k_2 k2个类间近邻的话,否则为0。
深度迁移度量学习
所给的目标域与源域的数据分布往往是不同的。为了减小分布差距,使得目标域与源域之间的概率分布尽可能地接近是很有必要的。因此,文章在 m \ m m层中将MMD(最大化均值差异)用于测量分布差异。定义如下:
结合3,6式,构建的DTML优化目标为: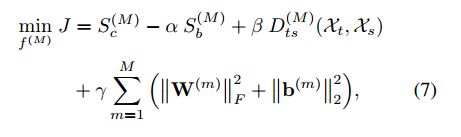
其中 β \beta β大于等于0,为规范化参数。使用随机梯度下降法来获取参数 W ( m ) 和 b ( m ) \ W^{(m)}和b^{(m)} W(m)和b(m).
计算方法如下: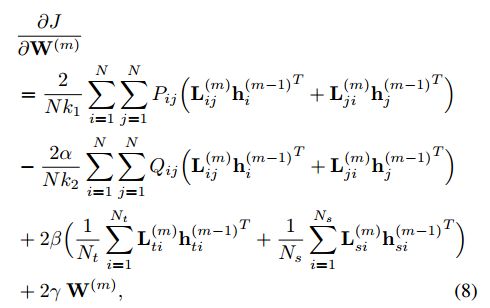
更新方程如下:
具体算法如下:
DSTML
式子(7)只考虑了顶层网络训练样本的监督信息,而忽略的隐含层的判别信息,因此文章将每一层的监督信息都考虑进来,进而优化问题变为:

顶层参数 W ( m ) 和 b ( m ) \ W^{(m)}和b^{(m)} W(m)和b(m)的计算
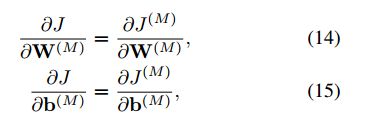
其他层,即 m = 1 , 2 , . . . M − 1 m=1,2,...M-1 m=1,2,...M−1层的计算方法是:


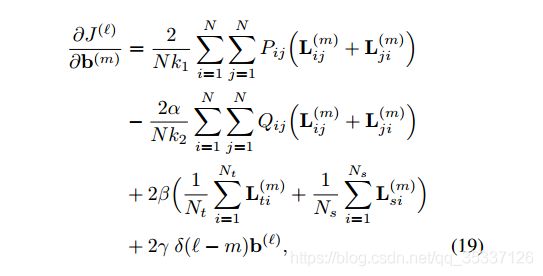
上式子中: 只 有 当 x = 0 时 , δ ( x ) = 1 , 其 他 值 δ ( x ) = 0 只有当x=0时,\delta(x)=1,其他值\delta(x)=0 只有当x=0时,δ(x)=1,其他值δ(x)=0
更新方程为: 在 1 ≤ m ≤ ℓ − 1 1\leq m\leq ℓ-1 1≤m≤ℓ−1

实验
人脸识别
数据库:
- LFW(常用于测试人脸识别的准确率):数据来源于网络,有13233张图片,5749个人。其中1680个人拥有>=2张的图片。将数据集10组非重叠数据;并使用10折交叉验证来评估方法的性能。
- 包含99773张,人数为2995。其中2065人至少有15张图像。
LFW和WDref数据集没有重叠。在文章的实验中,用于学习判别度量网络的样本来源于WDref,1500人,每人十张图像。 - 源域:WDref; 目标域:LFW
实验设置 - 对于每张图像,采用LBP特征表示图片每一张图像(LBP:局部二值模式,用于描述图像局部特征的算子)。首先提取LBP描述符,提取五个不同规模的面部域。级联为5900维的特征向量;利用PCA(主要成分分析)将维度降到500维(映射在源域数据中学习的);论文采用三层网络,每一层的结点数,从底层到顶层500–>400–>300.非线性激活函数选用的时tanh;
- 参数的初始化; α , β , γ , ω ( 1 ) , τ , k 1 , k 2 \alpha,\beta,\gamma,\omega^{(1)},\tau,k_1,k_2 α,β,γ,ω(1),τ,k1,k2分别为: 0.1 , 10 , 0.1 , 1 , 0 , 5 , 10 0.1, 10, 0.1, 1, 0, 5, 10 0.1,10,0.1,1,0,5,10; 学习率 λ = 0.2 , \lambda=0.2, λ=0.2,通过乘以 0.95 0.95 0.95来减少 λ \lambda λ的值。 W ( m ) W^{(m)} W(m)对角线为 1 1 1,其他元素为 0 0 0的矩阵。偏差 b ( m ) b^{(m)} b(m)全为 0 0 0。
- 结果:论文方法与其他方法的比较,STML是DTML的特殊情况,即使用的激活函数为线性激活函数 φ ( x ) = x \varphi ( x ) = x φ(x)=x
图1: 就平均识别率来说,DSTML相对于DTML来说提高了 1.7 % 1.7\% 1.7%。
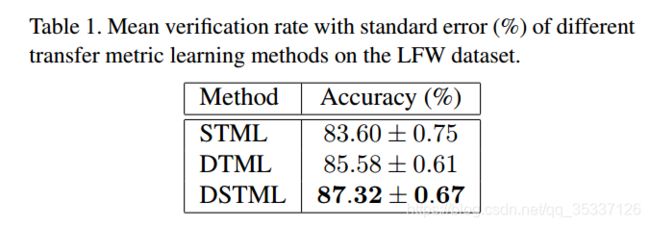
图2:
有知识迁移的与没有知识迁移的方法比较。 β = 0 \beta = 0 β=0则可表示没有迁移。

图4:ROC曲线,受试者工作特征曲线
说明迁移度量学习方法比其他方法表现好。
行人重识别
- 行人重识别的目标在于识别在不一样环境下通过不同摄像头下的行人。这个任务是比较有挑战性的。
- 源域标签信息只在模型学习阶段使用。
数据库:
- VIPeR:632个行人,每个行人有两张图像,且视角变化为90度。
- i-LIDS:119个行人,每个行人有2-8张图。总共476张。来源于机场的5个摄像头。
- CAVIAR:1220张图,72个参与者,来自两个摄像头,每个行人包括10~20张图片。
- 3DPeS:1011图像,192个行人,8个摄像头,每个行人至少出现在3个摄像头中。
实验设置
- 所有的图片规模都是 128 × 48 128\times48 128×48
- 对于每张图片,利用两种特征描述符,颜色以及条纹直方图。
- 具体过程:
- 每张图分为6块非重叠水平条纹。
- 对于每一个条纹,提取8个通道的直方图(每个通道提取16个直方图)。[8个通道包括RGB(R,G,B),YUV(Y,U,V),HSV(H,S)注:Y-明亮度,U-色度,V-浓度; H-色相,S-饱和度,V-明度。]
- 计算8个邻居,16个邻居下的均值LBP。
-对每张图级联从这些条纹提取的颜色以及直方图组成2580的特征向量。 - PCA在源域数据上学习。应用于目标域上,减少其特征向量的维度。
- 采用single-shot 实验设置去随机将数据集分离为训练集和测试集。重复10次。
- 每一轮,#test个测试集。随机选择每个人的一张图像作为图像库,剩余的用作探测图像。
- 三层网络:单元个数从底层到顶层是200–>200->100;
- 参数设定: k 1 , k 2 = 3 , 10 k_1,k_2 = 3, 10 k1,k2=3,10
- 结果:表3到表6;L1,L2为基准方法(第一、二范数计算目标域中探测图像和画廊图像的距离。)DTML表现更好。可以看到DSTML在大多数案例中获得最好的性能。
结论
本篇论文提出了DTML方法针对跨数据视觉识别。通过学习层次非线性转换,从源域迁移判别信息到目标域。论文方法比其他存在的线性度量学习方法表现好。为进一步利用判别信息,提出DSTML方法,即在隐层和输出层都加入判别信息。实验证明,方法性能好。