动态卷积&&条件卷积
最近了解到了动态卷积的这一概念,觉得使用动态卷积来替换常规卷积能够减少很多的计算量,所以便记录一下有关动态卷积三篇论文的学习笔记。
目录
一:CondConv: Conditionally Parameterized Convolutions for Efficient Inference
二:Dynamic Convolution: Attention over Convolution Kernels
三:Omni dimensional dynamic convolution
一:CondConv: Conditionally Parameterized Convolutions for Efficient Inference
卷积是当前CNN网络的基本构成单元之一,其有一个基本的假设就是卷积参数对所有样例共享。本文提出了一种动态卷积,它可以为每一个样例学习一个特定的卷积核参数。
以往的CNN的性能提升更多源自于模型尺寸和容量的提升以及更大的数据集。但是模型尺寸的进一步提升会加大计算开销。
作者提出了一种条件参数卷积来解决上述问题,通过计算卷积核参数打破了传统的静态卷积的特性。作者将CondConv中的卷积核参数化为多个专家知识的线性组合(其中![]() 是通过梯度下降学习的加权系数):
是通过梯度下降学习的加权系数):![]() 为更有效的提升模型容量,在网络设计中可以提升专家数量,同时专家知识只需要进行一次组合,这就可以在提升模型容量的同时保持高效。
为更有效的提升模型容量,在网络设计中可以提升专家数量,同时专家知识只需要进行一次组合,这就可以在提升模型容量的同时保持高效。
方法
在传统的卷积中,卷积核参数经训练确定且对所有输入样本一视同仁,而在动态卷积CondConv中卷积核参数通过对输入的变换得到,这个过程可以用公式表述为:
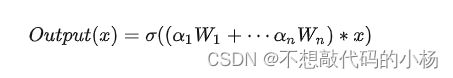
其中![]() 是一个样本依赖加权参数。在动态卷积ConConv中,每个卷积核
是一个样本依赖加权参数。在动态卷积ConConv中,每个卷积核 具有与标准卷积核参数相同的维度。
具有与标准卷积核参数相同的维度。
常规卷积容量提升依赖于卷积核尺寸与通道数的提升,这将进一步提升网络的整体计算,而CondConv则只需要在执行卷积计算之前通过多个专家对输入样本计算加权卷积核。关键的是,每个卷积核只需计算一次并作用于不同位置即可。这意味着:通过提升专家数据量达到提升网络容量的目的,而代码仅仅是很小的推理耗时:每个额外参数仅需一次乘加。
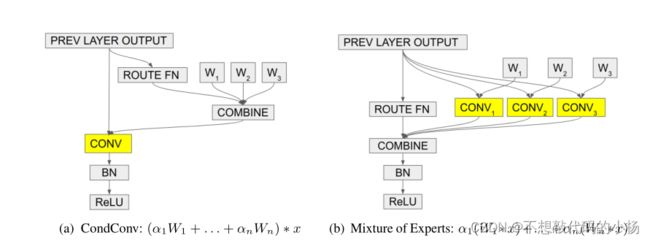
本文提出的方法如图(a)。图中的ROUTE FN指的是Routing Function可以理解为一个注意力机制相当于GAP+FC+Sigmod。在图(b)中,不同的W相当于不同的权重,不同的卷积核。每一条路径就是一个专家,然后通过Combine加权操作。但是这样计算量过大。但是作者证明了图(a)图(b)两种方法是等效的但是本文提出的图(a)方法节省了很多计算开销。
总结
总而言之,作者在静态卷积之外提出一种条件参数卷积:CondConv。它打破了静态卷积的假设:卷积核对所有输入“一视同仁”。这为提升模型容量同时保持高效推理打开了一个新的方向:提升卷积核生成函数的尺寸与复杂度。由于卷积核参数仅需计算一次,相比卷积计算,这些额外的计算量可以忽略。也就是说:提升卷积核生成的计算量要远比添加更多卷积或更多通道数高效
第二篇文章是在第一篇文章的基础上进一步完善了动态卷积的概念
二:Dynamic Convolution: Attention over Convolution Kernels
动态卷积中的Attention模块来源于SENet,它可以自动学习到不同通道特征的重要程度,生成对应的权重,这相当于一种注意力机制。
与SENet不同的是,动态卷积处理的对象是卷积核,按权重相加,而后者是处理特征图,对每一个特征图乘上一个权重。
基本思路
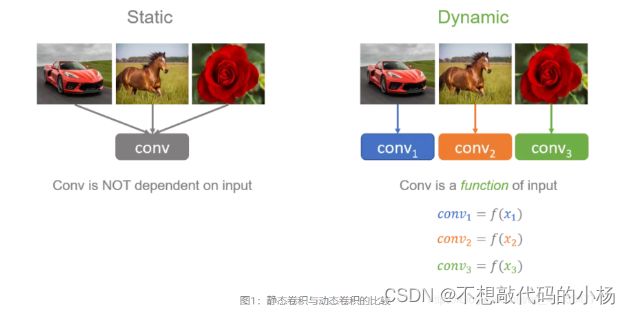
动态卷积的基本思路就是根据输入图像,自适应的调整卷积参数,如下图所示,静态卷积用同一个卷积核对所有输入图像做相同的操作,而动态卷积会对不同的图像(如汽车,马,花)做出调整,用更适合的卷积参数进行处理,简单来说卷积核是输入的函数。
方法
传统的卷积可以看出是静态的:
![]()
而本文的动态卷积感知器的概念可以表达为:
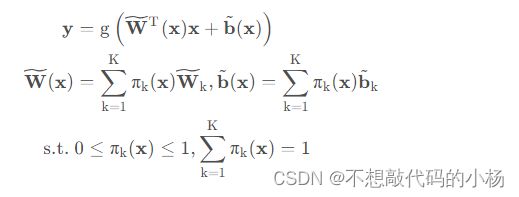
其中![]() 分别是K个网络的权重参数。
分别是K个网络的权重参数。
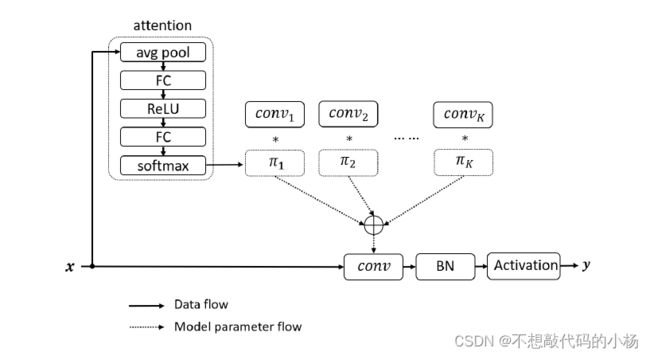
聚合的意思是将K个卷积核根据权重![]() 按元素求和,得到处理后的卷积核
按元素求和,得到处理后的卷积核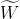 ,
,![]() .由于
.由于![]() 的生成是非线性的,所以动态卷积具有更强的表达能力,流程图如下:
的生成是非线性的,所以动态卷积具有更强的表达能力,流程图如下:
x是卷积网络中前一层的特征图,“attention”模块中输入的是本层的卷积核,经过SENet的操作,得到权重π(k),与con 分别作积并求和得到聚合的卷积核这个卷积核再对输入x处理得到本层的特征图y。
分别作积并求和得到聚合的卷积核这个卷积核再对输入x处理得到本层的特征图y。
本文的动态卷积没有在每层上使用单个卷积核,而是根据注意力动态的聚合多个并行的卷积核。注意力会根据输入动态的调整每个卷积核的权重,从而生成自适用的动态卷积
由于需要同步优化所有卷积核,会带来训练上的困难,针对训练上的问题本文提出了两个改进。如下图所示:
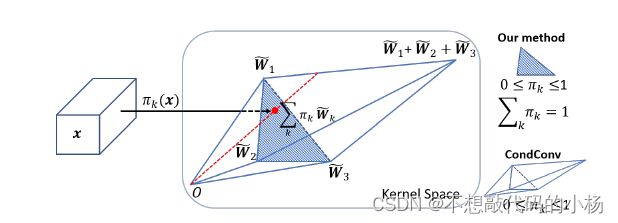
假设![]() 是三个卷积核,当
是三个卷积核,当 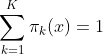 时聚合的卷积核将映射到阴影三角形中,这缩小了范围,从而有利于训练。
时聚合的卷积核将映射到阴影三角形中,这缩小了范围,从而有利于训练。
另外关于 Softmax 归一化函数引入热度(temperature)的参数:
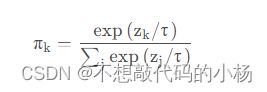
当 变很大的时候,
变很大的时候,![]() 的分布将更加集中。通常情况下τ等于1,这使得
的分布将更加集中。通常情况下τ等于1,这使得![]() 的分布较为分散,其对应的卷积核
的分布较为分散,其对应的卷积核![]() 能够得到优化而较小的值对应的
能够得到优化而较小的值对应的![]() 得不到优化。因此将训练初期设置较大的τ值,随着训练的进行再将这个值减小。
得不到优化。因此将训练初期设置较大的τ值,随着训练的进行再将这个值减小。
三:Omni dimensional dynamic convolution
对于每一个卷积层,学习一个静态的卷积是卷积神经网络的通用做法,前面两篇论文也是对动态卷积进行了一定程度的研究。其学习了N个卷积核的线性组合,并对其进行注意力加权,给不同的卷积核以不同的权重。但这些工作仅仅关注了卷积核数单一一维的信息,忽略了诸如卷积大小,输入,输出通道数等这些信息。本文提出了一种全维度动态卷积,采用多维注意力和并行策略。将普通卷积替换成这种全维度的动态卷积能够大幅提升性能。
普通卷积层操作是将输入与一个静态的卷积层相乘得到输出。而动态卷积如下式,与输出通道个数n相同的n个卷积核(![]() ),乘上根据输入特征计算的权重
),乘上根据输入特征计算的权重![]() 加权求和,得到最终的输出特征。
加权求和,得到最终的输出特征。
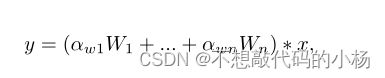
前面两篇文章都采用了 改进的SE注意力结构作为权重![]() 的计算方式,不同的是第一篇CondConv采用的是Sigmod激活函数,而DyConv采用Softmax函数来计算。
的计算方式,不同的是第一篇CondConv采用的是Sigmod激活函数,而DyConv采用Softmax函数来计算。
而本文认为,计算动态卷积的卷积核和计算![]() 的注意函数
的注意函数![]() ,共有4个维度(卷积核大小k*k,输入通道数,输出通道数,和卷积核个数)。CondConv和DyConv通过注意力函数
,共有4个维度(卷积核大小k*k,输入通道数,输出通道数,和卷积核个数)。CondConv和DyConv通过注意力函数![]() 为卷积计算出注意力标量
为卷积计算出注意力标量![]() ,这同时意味着的每个输出通道有着相同的注意力值(也就是除了卷积核数量这一维,其他维度都具有相同的权重)说明这两种动态卷积不能充分利用四个维度。
,这同时意味着的每个输出通道有着相同的注意力值(也就是除了卷积核数量这一维,其他维度都具有相同的权重)说明这两种动态卷积不能充分利用四个维度。
本文设计的全维度的动态卷积计算公式如下:
![]()
![]() 与之前的动态卷积相同。
与之前的动态卷积相同。![]() 分别是三个新引入的注意力,代表卷积核空间维度,输入通道维度,输出通道维度,这四个注意力标量是通过一个多头注意力模块
分别是三个新引入的注意力,代表卷积核空间维度,输入通道维度,输出通道维度,这四个注意力标量是通过一个多头注意力模块![]() 来计算的。下图展示了四个类型的注意力乘以n个卷积核的过程,输入x按照空间位置维度,通道维度(输入维度),过滤器维度(输出通道)和卷积核维度来逐步计算乘以卷积核,使得输入能获取丰富的上下文信息。
来计算的。下图展示了四个类型的注意力乘以n个卷积核的过程,输入x按照空间位置维度,通道维度(输入维度),过滤器维度(输出通道)和卷积核维度来逐步计算乘以卷积核,使得输入能获取丰富的上下文信息。
具体操作如下图所示:
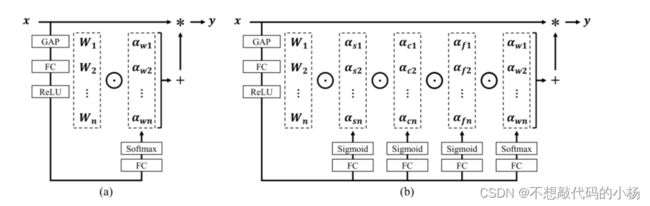
如上图,本文提出的ODConv继续沿用SE注意力的计算方式,将输入x通过通道平均池化GAP将x压缩到输入通道长度的特征向量中,然后通过全连接层FC将特征向量映射到低维度空间,压缩率为1/16,Relu函数激活,之后分为4个头部分支,每个分支具有k*k,![]() *1,
*1,![]() *1和n*1的全连接层输出,通过Sigmoid激活函数或Softmax激活函数归一化生成
*1和n*1的全连接层输出,通过Sigmoid激活函数或Softmax激活函数归一化生成![]() 四个维度下的权重,其中Softmax函数采用温度系数τ来训练
四个维度下的权重,其中Softmax函数采用温度系数τ来训练
总的来说这第三篇动态卷积的论文提出了一种全维度的动态卷积(ODConv)来提高深度CNN的表示能力。ODConv利用多维度的注意力机制,沿着卷积核空间所有的四个维度并行的学习卷积核的四种注意力类型,并逐步将这些注意力权重应用到相应的卷积核当中,这可以大大增强CNN基本卷积操作的特征提取能力。