pytorch 多GPU训练
代码库地址: mnist
目录
普通单机单卡训练流程
分布式训练需要的改动
horovod方式
普通单机单卡训练流程
以mnist为例,主要包括数据加载、模型构建、优化器和迭代训练等部分
import argparse
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from datetime import datetime
from tqdm import tqdm
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def train(gpu, args):
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size,shuffle=True, num_workers=0,pin_memory=True)
start = datetime.now()
for epoch in range(args.epochs):
if gpu == 0:
print("Epoch: {}/{}".format(epoch+1, args.epochs))
pbar = tqdm(train_loader)
for images, labels in pbar:
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if gpu == 0:
msg = 'Loss: {:.4f}'.format(loss.item())
pbar.set_description(msg)
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=2, type=int, help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes')
parser.add_argument('--epochs', default=10, type=int, metavar='N', help='number of total epochs to run')
args = parser.parse_args()
train(0, args)
if __name__ == '__main__':
main()![]()
在2080Ti上训练2个epoch耗时1分12秒.
DDP分布式训练
需要的改动 0.引入必须的库
import os
import torch.multiprocessing as mp
import torch.distributed as dist1.修改main函数
def main():
parser = argparse.ArgumentParser()
...
args = parser.parse_args()
args.world_size = args.gpus * args.nodes
if args.world_size > 1:
os.environ['MASTER_ADDR'] = '127.0.0.1' #
os.environ['MASTER_PORT'] = '8889' #
mp.spawn(train, nprocs=args.gpus, args=(args,)) #
else:
train(0, args)2.初始化通信库
def train(gpu, args):
if args.world_size > 1:
rank = args.nr * args.gpus + gpu
dist.init_process_group(backend='nccl', init_method='env://', world_size=args.world_size, rank=rank)3.送给每个node的数据需要打乱,有请DistributedSampler
if args.world_size > 1:
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset,num_replicas=args.world_size,rank=rank)
shuffle = False
else:
train_sampler = None
shuffle = True
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size,shuffle=shuffle, num_workers=0,pin_memory=True,sampler=train_sampler)这里我们首先计算出当前进程序号:
rank = args.nr * args.gpus + gpu,然后就是通过dist.init_process_group初始化分布式环境,其中backend参数指定通信后端,包括mpi, gloo, nccl,这里选择nccl,这是Nvidia提供的官方多卡通信框架,相对比较高效。mpi也是高性能计算常用的通信协议,不过你需要自己安装MPI实现框架,比如OpenMPI。gloo倒是内置通信后端,但是不够高效。init_method指的是如何初始化,以完成刚开始的进程同步;这里我们设置的是env://,指的是环境变量初始化方式,需要在环境变量中配置4个参数:MASTER_PORT,MASTER_ADDR,WORLD_SIZE,RANK,前面两个参数我们已经配置,后面两个参数也可以通过dist.init_process_group函数中world_size和rank参数配置。其它的初始化方式还包括共享文件系统(https://pytorch.org/docs/stable/distributed.html#shared-file-system-initialization)以及TCP(https://pytorch.org/docs/stable/distributed.html#tcp-initialization),比如采用TCP作为初始化方法init_method='tcp://10.1.1.20:23456',其实也是要提供master的IP地址和端口。注意这个调用是阻塞的,必须等待所有进程来同步,如果任何一个进程出错,就会失败。
完整代码, 搜索add可快速直达修改的地方
import argparse
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from datetime import datetime
from tqdm import tqdm
# add 0
import os
import torch.multiprocessing as mp
import torch.distributed as dist
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def train(gpu, args):
# add 2
if args.world_size > 1:
rank = args.nr * args.gpus + gpu
dist.init_process_group(backend='nccl', init_method='env://', world_size=args.world_size, rank=rank)
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
# add 3
if args.world_size > 1:
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset,num_replicas=args.world_size,rank=rank)
shuffle = False
else:
train_sampler = None
shuffle = True
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size,shuffle=shuffle, num_workers=0,pin_memory=True,sampler=train_sampler)
start = datetime.now()
for epoch in range(args.epochs):
if gpu == 0:
print("Epoch: {}/{}".format(epoch+1, args.epochs))
pbar = tqdm(train_loader)
for i, (images, labels) in enumerate(pbar):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if gpu == 0:
msg = 'Loss: {:.4f}'.format(loss.item())
pbar.set_description(msg)
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=2, type=int, help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes')
parser.add_argument('--epochs', default=10, type=int, metavar='N', help='number of total epochs to run')
args = parser.parse_args()
# add 1
args.world_size = args.gpus * args.nodes
if args.world_size > 1:
os.environ['MASTER_ADDR'] = '127.0.0.1' #
os.environ['MASTER_PORT'] = '8889' #
mp.spawn(train, nprocs=args.gpus, args=(args,)) #
else:
train(0, args)
if __name__ == '__main__':
main()
耗时缩小到了48秒,还是很显著的.
horovod方式
Horovod是一个专注于分布式训练的深度学习框架,通过Horovod可以为Tensorflow、Keras、Pytorch和MXNet提供分布式训练的能力。使用Horovod进行分布式训练主要能给我们带来两个好处:
- 易用性:仅需要通过几行代码的修改,就可以将单机的Tensorflow、Keras、Pytorch或MXNet的代码更改为同时支持单机单卡、单机多卡、多机多卡的训练代码
- 高性能:高性能主要体现在扩展性上,一般的训练框架随着worker的增加(尤其是在node增加)训练性能会逐渐下降(主要是由于node间网络通信性能比较低引起);Horovod在128机4 P100 25Gbit/s的RoCE网络条件下,Inception V3 和 ResNet-101均可以获得90%的扩展效率。

它的安装非常简单,pip install horovod即可
通过Horovod编写分布式训练代码,一般为6个步骤:
- 添加
hvd.init()来初始化Horovod; - 为每个worker分配GPU,一般一个worker process对应一个GPU,对应关系通过rank id来映射。例如pytorch中为torch.cuda.set_device(hvd.local_rank())
- 随着world_size的变化,batch_size也在变化,因此我们也要随着world_size的变化来调整lr,一般为原有的lr 值乘以world_size;
- 将原有深度学习框架的optimizer通过horovod中的hvd.DistributedOptimizer进行封装;
- rank 0 将初始的variable广播给所有worker: hvd.broadcast_parameters(model.state_dict(), root_rank=0)
- 仅在worker 0上进行checkpoint的save
完整代码,可搜索add一键直达修改的地方
import argparse
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
from datetime import datetime
from tqdm import tqdm
# add 0
import horovod.torch as hvd
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def train(gpu, args):
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
# add 2
if hvd.size() > 1:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
shuffle = False
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters(), op=hvd.Average)
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)
else:
train_sampler = None
shuffle = True
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size,shuffle=shuffle, num_workers=0, sampler=train_sampler, pin_memory=True)
start = datetime.now()
for epoch in range(args.epochs):
if gpu == 0:
print("Epoch: {}/{}".format(epoch+1, args.epochs))
if gpu == 0:
pbar = tqdm(train_loader)
else:
pbar = train_loader
for images, labels in pbar:
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if gpu == 0:
msg = 'Loss: {:.4f}'.format(loss.item())
pbar.set_description(msg)
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=2, type=int, help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int, help='ranking within the nodes')
parser.add_argument('--epochs', default=10, type=int, metavar='N', help='number of total epochs to run')
args = parser.parse_args()
# add 1
hvd.init()
train(hvd.local_rank(), args)
if __name__ == '__main__':
main()启动命令:
# Horovod 1 单机训练
#horovodrun -np 1 -H localhost:1 python train_horovod.py
# Horovod 2 双卡训练
horovodrun -np 2 -H localhost:2 python train_horovod.py
# Horovod 4 四卡训练
#horovodrun -np 4 -H localhost:4 python train_horovod.py
这种方式下双卡仅需41秒

虽然单卡的速度没有变快,但是处理任务的worker多了,吞吐就上去了,4卡仅需要20秒

分布式训练之旅 PyTorch分布式训练简明教程
PyTorch分布式训练基础--DDP使用
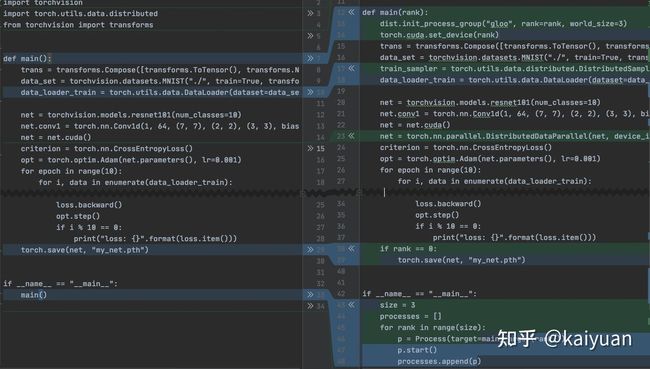
主要变动的位置包括:
1. 启动的方式引入了一个多进程机制;
2. 引入了几个环境变量;
3. DataLoader多了一个sampler参数;
4. 网络被一个DistributedDataParallel(net)又包裹了一层;
5. ckpt的保存方式发生了变化。
Pytorch - 分布式通信原语(附源码)
Pytorch - 多机多卡极简实现(附源码)
Pytorch - DDP实现分析
Pytorch - 使用Horovod分布式训练
Pytorch - Horovod分布式训练源码分析