【目标检测-YOLO】YOLOv5 Test-Time Augmentation (TTA) 教程
This guide explains how to use Test Time Augmentation (TTA) during testing and inference for improved mAP and Recall with YOLOv5 . UPDATED 25 January 2022.
Before You Start
Clone repo and install requirements.txt in a Python>=3.7.0 environment, including PyTorch>=1.7. Models and datasets download automatically from the latest YOLOv5 release.
git clone https://github.com/ultralytics/yolov5 # clone cd yolov5 pip install -r requirements.txt # install
Test Normally
Before trying TTA we want to establish a baseline performance to compare to. This command tests YOLOv5x on COCO val2017 at image size 640 pixels. yolov5x.pt is the largest and most accurate model available. Other options are yolov5s.pt, yolov5m.pt and yolov5l.pt, or you own checkpoint from training a custom dataset ./weights/best.pt. For details on all available models please see our README table.
$ python val.py --weights yolov5x.pt --data coco.yaml --img 640 --half
Output:
val: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.65, task=val, device=, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
YOLOv5 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
Fusing layers...
Model Summary: 476 layers, 87730285 parameters, 0 gradients
val: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2846.03it/s]
val: New cache created: ../datasets/coco/val2017.cache
Class Images Labels P R [email protected] [email protected]:.95: 100% 157/157 [02:30<00:00, 1.05it/s]
all 5000 36335 0.746 0.626 0.68 0.49
Speed: 0.1ms pre-process, 22.4ms inference, 1.4ms NMS per image at shape (32, 3, 640, 640) # <--- baseline speed
Evaluating pycocotools mAP... saving runs/val/exp/yolov5x_predictions.json...
...
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.504 # <--- baseline mAP
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.688
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.546
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.351
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.551
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.644
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.382
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.628
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.681 # <--- baseline mAR
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.524
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.735
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.826Test with TTA
Append --augment to any existing val.py command to enable TTA, and increase the image size by about 30% for improved results. Note that inference with TTA enabled will typically take about 2-3X the time of normal inference as the images are being left-right flipped and processed at 3 different resolutions, with the outputs merged before NMS. Part of the speed decrease is simply due to larger image sizes (832 vs 640), while part is due to the actual TTA operations.
$ python val.py --weights yolov5x.pt --data coco.yaml --img 832 --augment --half
手段
- 增大输入图像大小30%,如640 vs 832
- left-right flipped
- 3 different resolutions
- the outputs merged before NMS
结果:和正常比慢 2-3X
Output:
val: data=./data/coco.yaml, weights=['yolov5x.pt'], batch_size=32, imgsz=832, conf_thres=0.001, iou_thres=0.6, task=val, device=, single_cls=False, augment=True, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True
YOLOv5 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
Fusing layers...
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
Model Summary: 476 layers, 87730285 parameters, 0 gradients
val: Scanning '../datasets/coco/val2017' images and labels...4952 found, 48 missing, 0 empty, 0 corrupted: 100% 5000/5000 [00:01<00:00, 2885.61it/s]
val: New cache created: ../datasets/coco/val2017.cache
Class Images Labels P R [email protected] [email protected]:.95: 100% 157/157 [07:29<00:00, 2.86s/it]
all 5000 36335 0.718 0.656 0.695 0.503
Speed: 0.2ms pre-process, 80.6ms inference, 2.7ms NMS per image at shape (32, 3, 832, 832) # <--- TTA speed
Evaluating pycocotools mAP... saving runs/val/exp2/yolov5x_predictions.json...
...
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.516 # <--- TTA mAP
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.701
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.562
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.361
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.564
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.656
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.388
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.640
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.696 # <--- TTA mAR
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.553
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.744
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.833Inference with TTA
detect.py TTA inference operates identically to val.py TTA: simply append --augment to any existing detect.py command:
$ python detect.py --weights yolov5s.pt --img 832 --source data/images --augment
Output:
detect: weights=['yolov5s.pt'], source=data/images, imgsz=832, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=True, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False
YOLOv5 v5.0-267-g6a3ee7c torch 1.9.0+cu102 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
Downloading https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.pt to yolov5s.pt...
100% 14.1M/14.1M [00:00<00:00, 81.9MB/s]
Fusing layers...
Model Summary: 224 layers, 7266973 parameters, 0 gradients
image 1/2 /content/yolov5/data/images/bus.jpg: 832x640 4 persons, 1 bus, 1 fire hydrant, Done. (0.029s)
image 2/2 /content/yolov5/data/images/zidane.jpg: 480x832 3 persons, 3 ties, Done. (0.024s)
Results saved to runs/detect/exp
Done. (0.156s)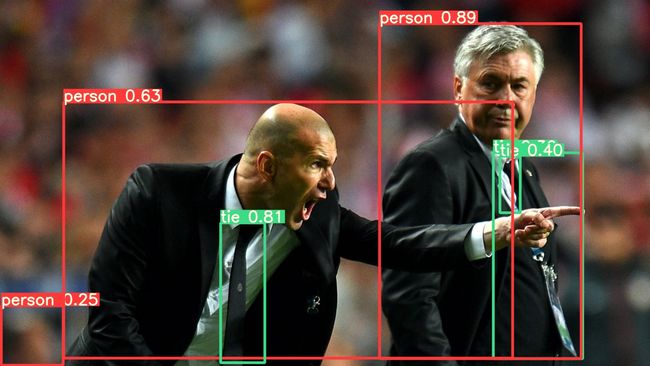
PyTorch Hub TTA
TTA is automatically integrated into all YOLOv5 PyTorch Hub models, and can be accessed by passing augment=True at inference time.
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5m, yolov5x, custom
# Images
img = 'https://ultralytics.com/images/zidane.jpg' # or file, PIL, OpenCV, numpy, multiple
# Inference
results = model(img, augment=True) # <--- TTA inference
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.Customize
You can customize the TTA ops applied in the YOLOv5 forward_augment() method here:
yolov5/models/yolo.py
def forward_augment(self, x):
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self.forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
return torch.cat(y, 1), None # augmented inference, train Environments
YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
- Google Colab and Kaggle notebooks with free GPU:colab YOLOv5 | Kaggle
- Google Cloud Deep Learning VM. See GCP Quickstart Guide
- Amazon Deep Learning AMI. See AWS Quickstart Guide
- Docker Image. See Docker Quickstart Guide Docker Hub
Status
CI CPU testing - passing
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training (train.py), validation (val.py), inference (detect.py) and export (export.py) on MacOS, Windows, and Ubuntu every 24 hours and on every commit.
总结:
主要关注推理时候使用TTA 以及 自定义 TTA 。但是TTA在实际部署时候好像并不会使用,打比赛时候可能都会用。
手段
- 增大输入图像大小30%,如640 vs 832
- left-right flipped
- 3 different resolutions
- the outputs merged before NMS
结果:和正常比慢 2-3X
$ python detect.py --weights yolov5s.pt --img 832 --source data/images --augment