【C语言数组】一维数组,二维数组详解,数组传参,变长数组,这篇文章让你更全面的认识数组。
前言:
大家好,我是良辰丫,今天带大家全面认识一下C语言里面的数组,大家是不是满怀期待呢?嘿嘿嘿,别着急,我们往下看,感受C语言数组的魅力!!!
要么出众,要么出局。
乾坤未定,你我皆是黑马。

目录
- 1、一维数组
-
- 1.1 一维数组的创建
- 1.2 一维数组下标
- 1.3 一维数组的初始化
- 1.4 一维数组的使用
- 1.5 一维数组在内存中的存储
-
- 1.5.1 内存图演示
- 1.5.2 代码演示
- 1.6 数组的复制
- 2、二维数组
-
- 2.1 二维数组的创建
- 2.2 二维数组的初始化
- 2.3 二维数组的使用
- 2.4 二维数组在内存中的存储
-
- 2.4.1 内存图演示
- 2.4.2 代码演示
- 3、数组越界
- 4、数组作为函数传参
-
- 4.1冒泡排序错误设计
- 4.2 数组名
- 4.3 冒泡排序正确实现
- 5、常量数组
-
- 5.1 了解常量数组
- 5.2 常量数组的好处
- 6、变长数组
1、一维数组
- 保存一组成绩的数据,数据多的时候难道要创造那么多变量吗,于是乎,就引入了数组,便捷的管理一组相同类型的数据。那么数组是什么呢?别着急,我们慢慢来了解。
- 数组是具有多个数据值的数据结构,并且具有相同的数据类型
简而言之,数组是一组相同类型元素的集合。
1.1 一维数组的创建
格式:
类型 数组名[常量表达式];int arr1[10]; char arr2[10];
注意:
- 数组创建,在C99标准之前(99年发布的C语言标准), [] 中要给一个常量才可以,不能使用变量。在C99标准支持了变长数组的概念,数组的大小可以使用变量指定,但是数组不能初始化。但是vs编译器里面还是不支持变长数组,牛客网做题平台支持。
- 创建时指定类型,变量名,以及元素个数。
- 一般来说,数组为type类型的数组我们就叫type数组,比如int类型数组我们可以称之为int数组或者整型数组。
1.2 一维数组下标
为了存取特定的某个元素,可以使用数组下标以及下标引用操作符[],n个元素的数组,数组的洗标范围为0~n-1,为什么是这个范围呢?设计者这样设计的规则,哈哈,超过这个范围就会越界,可能出现各种各样的问题。概念听起来有点糊涂,那我们举例进行说明。

int arr[5]={1,2,3,4,5};
printf("%d",arr[4]);

arr[4]就把第五个元素打印出来。如果打印arr[5],就会越界。
1.3 一维数组的初始化
要想使用数组必须对其进行初始化,接下来看几个一维数组的初始化。
int arr1[10] = {1,2,3};
int arr2[] = {1,2,3};
int arr3[4] = {1,2,3,4};
char arr4[3] = {'a',98, 'c'};
char arr5[] = {'a','b','c'};
char arr6[] = "abcdef";
解读:
- arr1定义10个元素,初始化3个值,剩余值默认为0。
- arr2元素个数为空,后面初始化3个数值,默认元素个数为3。
- arr3定义4个元素,初始化4个数值。
- arr4为字符类型的数组,98为b的ASCII码值,打印第二位的字符时,也可以把b打印出来。
- 未定义数组个数,后面初始化3个元素,数组大小默认定义为3。
数组在创建的时候如果想不指定数组的确定的大小就得初始化。数组的元素个数根据初始化的内容来确
定。
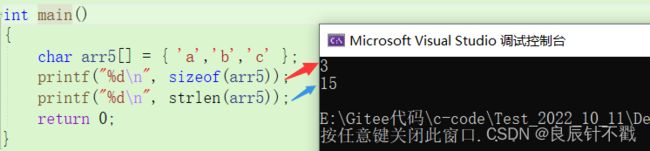
1个char类型的字符所占空间大小为1个字节,sizeof计算的是字符空间大小,3个元素空间大小为3,但是strlen的输出结果为什么是15呢?
strlen统计的是\0之前元素的个数,该数组中未定义\0,那么直到找到内存中的\0,因此该输出为默认值。- arr[5]中补充一个字符\0时,strlen的结果就成了3,大家脑海中的疑惑也就基本消失了吧!
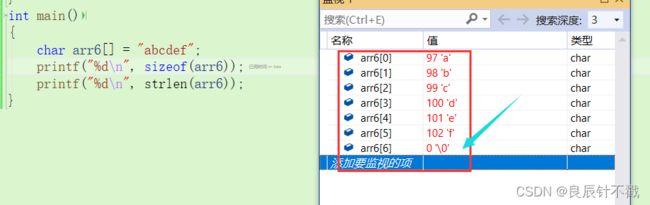
- arr[6]未定义数组个数,大家猛然一看后面初始化6个元素,其实不然,这是以字符串的形式定义数组,后面默认有一个\0,那么它就有7个元素,大家一定要注意细节,学会对比学习。看解释有点蒙的话,那就代码演示一下喽。
- 理论不行咱们就来实践验证一下。
从内存中我们可以看到,arr[6]中存放\0;



1.4 一维数组的使用
#include 注意:
- 数组是使用下标来访问的,下标是从0开始。
- 数组的大小可以通过计算得到。

1.5 一维数组在内存中的存储
1.5.1 内存图演示

1.5.2 代码演示

仔细观察输出的结果,我们知道,随着数组下标的增长,元素的地址,也在有规律的递增。
结论:
数组在内存中是连续存放的。
1.6 数组的复制
简单看一下数组的复制问题,让大家对一维数组有更深的了解。

上面数组arr1里面的数据复制给了arr2。
2、二维数组
想必通过上面的描述,大家对一维数组有了一定的了解,接下来,让我们瞧一瞧二维数组。一维数组成线,二维数组成面。
2.1 二维数组的创建
int arr[3][4];
char arr[3][5];
double arr[2][4];
2.2 二维数组的初始化
int arr[3][4] = {1,2,3,4};
int arr[3][4] = {{1,2},{4,5}};
int arr[][4] = {{2,3},{4,5}};
注意:
二维数组如果有初始化,行可以省略,列不能省略。
2.3 二维数组的使用
代码块1

上面创建了一个二维数组,每一行用大括号括起来,这样看起来更清晰一点,当然,大家也可以不用括号括起来。
代码块2

但是,如果数据参差不齐,必须要用括号,看下面的例子。
代码块3

2.4 二维数组在内存中的存储
2.4.1 内存图演示
从下图我们可以了解到,二维数组也是连续存放的,但为了有视觉体验,我们做题的时候还是行列分开进行分析,内存中的布局我们了解即可,平时使用就按照行和列分开进行。

2.4.2 代码演示

从上面的代码以及运行结果,我们更能清晰的了解到二维数组的内存也是连续存放的。
3、数组越界
- 数组的下标是有范围限制的,越界是一个比较严重的问题,越界就是超过了该数组的管辖范围,可能不会报错,但会导致结果不准确。编译器的不同,越界引起的问题也不一样,我们只需了解即可,切记不要越界
- 数组的下规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
- C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就是正确的,所以程序员写代码时,最好自己做越界的检查。
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
for(i=0; i<=10; i++)
{
printf("%d\n", arr[i]);//当i等于10的时候,越界访问了
}
return 0;
}
还是要注意下标取值范围,避免越界。减少不必要的麻烦,重要的事情要多次说,大家一定要注意每一个细节哦,细节决定成败。
4、数组作为函数传参
往往我们在写代码的时候,会将数组作为参数传个函数,数组传参是相当重要的,数组传参涉及到一些函数知识点,下一篇文章会详解函数的,接下来我们来看看数组如何传参。以冒泡排序为例子讲一下数组传参思想。
4.1冒泡排序错误设计
//代码1:
#include 这样很显然不能正常排序,看着代码没问题呀,怎么就导致错误的结果呢?调试分析后我们了解到 函数内部的 sz 为1。此时我们恍然大悟,数组作为函数传参,不是把整个数组传递过去。那数组名传参传递的是什么呢?不要着急,我们往下看。
4.2 数组名

我们对上面的结果简单分析一下
- arr与&arr[0]的地址相同,他们分别加1后地址仍然相同,这就验证了我们心中的猜想,数组名是首元素的地址。
- 对arr解引用后的结果为数组中的第一个元素,这更加验证了数组名是首元素的地址。
结论:
数组名是首元素地址,但是有两个例外。
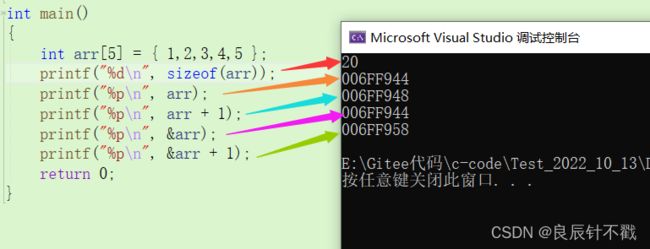
从上面的运算结果,我们应该可以看出猫腻。
- sizeof(数组名),计算整个数组的大小,sizeof内部单独放一个数组名,数组名表示整个数组。
- &数组名,取出的是数组的地址。&数组名,数组名表示整个数组。
除此1,2两种情况之外,所有的数组名都表示数组首元素的地址。
4.3 冒泡排序正确实现
当数组传参的时候,实际上只是把数组的首元素的地址传递过去了。
所以即使在函数参数部分写成数组的形式: int arr[] 表示的依然是一个指针【后续详解指针,听不懂没关系】: int *arr 。那么,函数内部的 sizeof(arr) 结果是4。那么我们如何正确实现冒泡排序呢?
//代码2
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{
int i = 0;
for(i=0; i<sz-1; i++)
{
int j = 0;
for(j=0; j<sz-i-1; j++)
{
if(arr[j] > arr[j+1])
{
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}
}
}
int main()
{
int arr[] = {3,1,7,5,8,9,0,2,4,6};
int sz = sizeof(arr)/sizeof(arr[0]);
bubble_sort(arr, sz);
for(int i=0; i<sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
把数组的大小作为参数传过去就可以实现冒泡排序了,是不是很神奇呢?大家可以自己去敲一敲冒泡排序的代码,感受一下神奇的数组。
5、常量数组
5.1 了解常量数组
想必上面的内容许多小伙伴们已经了如指掌了,但是常量数组的概念大家是不是第一次见呢?嘿嘿嘿,让我们来简单认识一下这个新概念吧!

const修饰的数组,数组中的数据就不能被修改了,一修改就会报错。因此呢!我们把const修饰的数组叫做常量数组。
5.2 常量数组的好处
- 表明程序并不想改变数组中的数据,const里面存放固定的数据。
比如扑克牌游戏,里面的扑克牌不可改变。- 有助于编译器发现错误,它会告诉编译器,此数组中数据为常量,不可被修改。
6、变长数组
在上面一维数组中我们简单引入了一下变长数组,变长数组是c99引进来的新概念,那么变长数组究竟是什么,我们往下看。
变长数组中的变并不是指我们可以修改数组的大小,而是指的是创建数组时,我们可以使用变量作为数组的大小。
需要注意的是:
- 变长数组只能是局部变量数组。
- 变长数组不能在定义的时候进行初始化。
- 变长数组必须是自动存储类别,也就是不能使用extern和static存储类别说明文。
- 变长数组不等于动态数组,本质上还是静态数组,,也就是说,数组的长度在变量的整个生命周期中是不可变的。
- 变长数组只能是局部变量,且是自动存储类型,因此,变长数组分配在栈上。
- 好多编译器不支持变长数组,比如我们常用的vs就不支持变长数组,支持c99标准的编译器才支持变长数组,刷题网站牛客网支持变长数组。
int m = 2;
int n = 2;
int arr[m][n]={1,2,3,4};//这样写对吗?
上面代码当然不对了,变长数组不能在定义的时候进行初始化。
想使用变长数组,先定义,然后再一一赋值。
下面为牛客网中变长数组的使用,并没有报错,说明牛客网是支持变长数组的。

变长数组了解即可:
变长数组的内容了解即可,不用深究,大家知道有这个概念就行了,变长数组这个知识点用的少。
后言:
想必读了上面内容,大家对数组的认识也更深了,感谢大家的观看,我会再接再厉,不断更新各种编程语言的教程,承蒙厚爱,多多支持。