Transformer学习笔记+Vision Transformer
Transformer学习笔记+Vision Transformer
参考链接:
详解Transformer (Attention Is All You Need)
【唐宇迪】transformer算法解读及其在CV领域应用
Transformer解读(论文 + PyTorch源码)
Transfomer可以理解为将输入重新生成为集成了上下文所有相关信息的新的输出,即对输入的每一个向量做一个重构,使其不仅仅只代表自己,而是有一种全局的感觉。
self-attention(自注意力机制)
1.什么是self-attention
注意力机制核心内容是为输入向量的每个单词学习一个权重
self-attention在机器翻译领域:先提取每一个单词的意思,然后根据输出生成顺序选取所需要的信息重新生成集成了上下文信息的新的输出,支持并行计算比注意力机制效率更高。
The animal didn’t cross the street because it was too tired
The animal didn’t cross the street because it was too narrow
在两个句子中,it所指代的含义完全不同,我们为输入向量的每个单词学习一个权重时,第一个句子it中animal的权重更高,而第二个句子中street的权重更高。
2.self-attention如何计算

Q:query,要去查询的
K:key,等着被查的
V:value,实际的特征信息
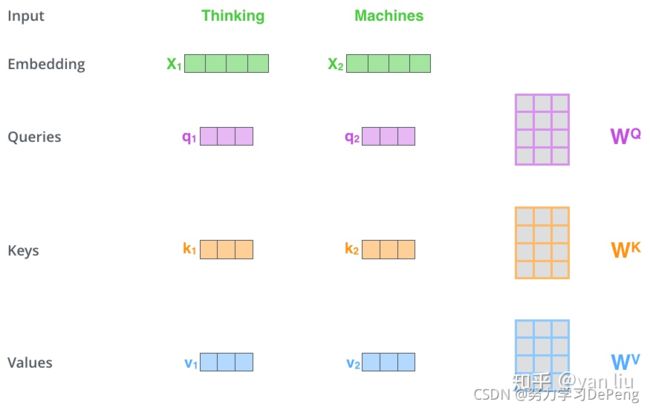
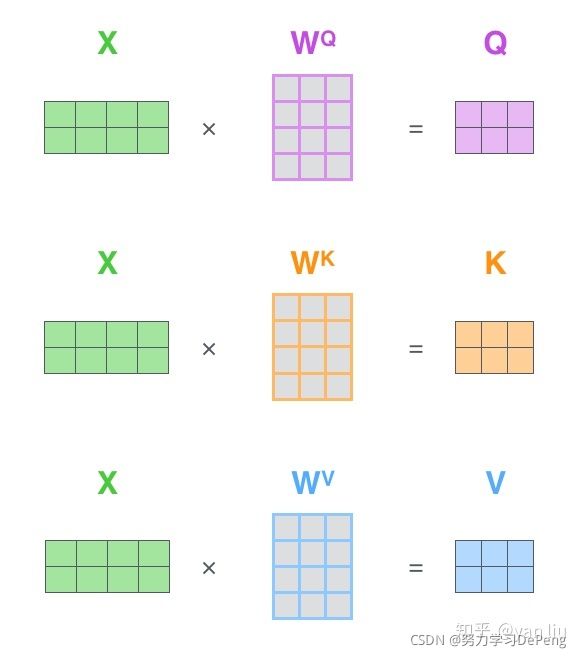
- 输入经过编码后得到向量,然后通过训练构建的三个矩阵来分别查询当前词和其他词的关系以及特征向量的表达。
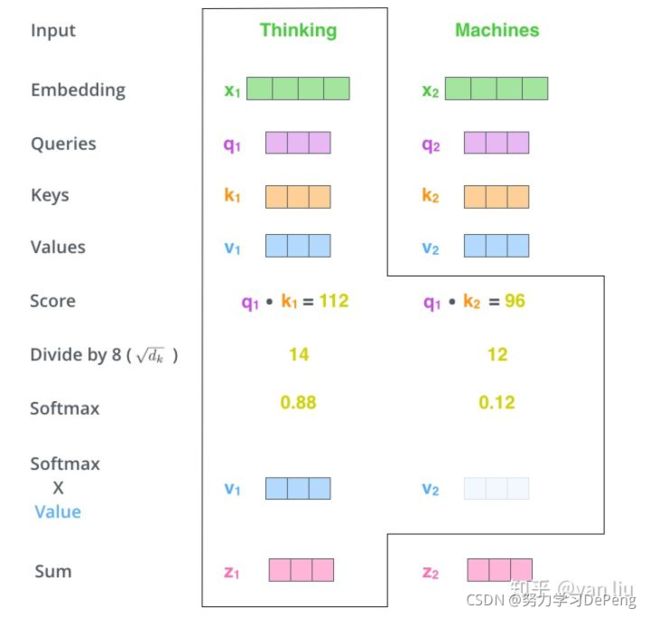
- 计算Attention,即计算每个向量所占权重value,然后通过分配集成上下文信息生成z

其中,4是因为向量维度大的话3中求内积的结果score就会大,但是不能让维度影响到每个向量所占的权重,所以需要除以8做一个归一化处理。
- 可以总结为如下图所示
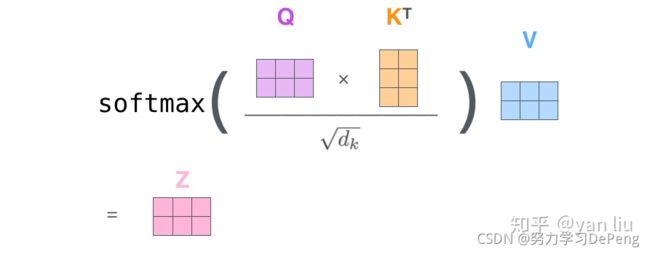
Transformer在CV中的应用(ViT)
Swin Transformer 论文详解及程序解读
[目标检测新范式]DETR — End-to-End Object Detection with Transformers
参考链接:
ViT:Vision Transformer
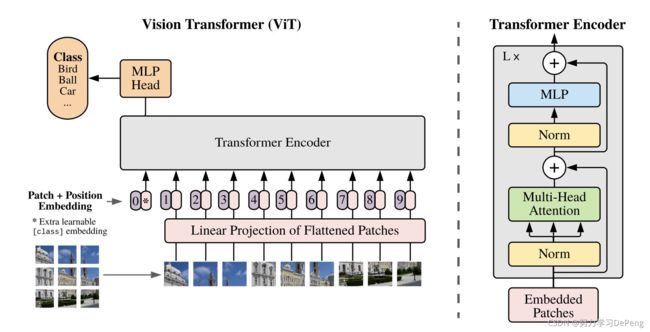
Transformer每一个新生成的value是在和全局的向量求权重,位置信息不会对它产生影响,所以在图像领域需要对分割出来的图像信息做一个编码,保留位置信息Position Embedding。
Transformer需要很大的数据量和运算资源
Multi-Head-Attention:通过不同的head得到多个特征表达,将所有的特征拼接到一起,可以通过再一层全连接来降维
不同的注意力结果得到的特征向量表达也不相同
最近参加了百度飞桨的从零开始学视觉Transformer训练营,打算在这里记录下所学到的实践部分。
参考:从零开始学视觉Transformer
ViT( Vision Transformer)
https://github.com/BR-IDL/PaddleViT
一、ViT(Vision Transformer)
import paddle
import paddle.nn as nn
import numpy as np
from PIL import Image
1. PatchEmbedding
#将图像进行切块操作,因为Transformer的本质是Seq2Seq,是对序列进行处理
class PatchEmbedding(nn.Layer):
def __init__(self, image_size=224, patch_size=16, in_channels=3, embed_dim=768, dropout=0.):
super().__init__()
n_patches = (image_size // patch_size) * (image_size // patch_size)
self.patch_embedding = nn.Conv2D(in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size)
self.dropout = nn.Dropout(dropout)
# TODO: add class token
self.class_token = paddle.create_parameter(
shape=[1, 1, embed_dim],
dtype='float32',
default_initializer=nn.initializer.Constant(0.)
)
# TODO: add position embedding
self. position_embedding = paddle.create_parameter(
shape=[1, n_patches+1, embed_dim],
dtype='float32',
default_initializer=nn.initializer.TruncatedNormal(std=.02)
)
def forward(self, x):
# [n, c, h, w]
# TODO: forward
class_tokens = self.class_token.expand([x.shape[0], -1, -1])
x = self.patch_embedding(x)
x = x.flatten(2)
x = x.transpose([0, 2, 1])
x = paddle.concat([class_tokens, x], axis=1)
return x
2. Encoder
class Encoder(nn.Layer):
def __init__(self, embed_dim, depth):
super().__init__()
layer_list = []
for i in range(depth):
encoder_layer = EncoderLayer()
layer_list.append(encoder_layer)
self.layers = nn.LayerList(layer_list)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
for layer in self.layers:
x = layer(x)
x = self.norm(x)
return x
2.1 MLP 多层感知机
class Mlp(nn.Layer):
def __init__(self, embed_dim, mlp_ratio, dropout=0.):
super().__init__()
self.fc1 = nn.Linear(embed_dim, int(embed_dim * mlp_ratio))
self.fc2 = nn.Linear(int(embed_dim * mlp_ratio), embed_dim)
self.act = nn.GELU()
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
2.2 注意力机制
class Attention(nn.Layer):
"""multi-head self attention"""
def __init__(self, embed_dim, num_heads, qkv_bias=True, dropout=0., attention_dropout=0.):
super().__init__()
self.num_heads = num_heads
self.head_dim = int(embed_dim / num_heads)
self.all_head_dim = self.head_dim * num_heads
self.scales = self.head_dim ** -0.5
self.qkv = nn.Linear(embed_dim,
self.all_head_dim * 3)
self.proj = nn.Linear(embed_dim, embed_dim)
self.dropout = nn.Dropout(dropout)
self.attention_dropout = nn.Dropout(attention_dropout)
self.softmax = nn.Softmax(axis=-1)
def transpose_multihead(self, x):
# x: [N, num_patches, all_head_dim] -> [N, n_heads, num_patches, head_dim]
new_shape = x.shape[:-1] + [self.num_heads, self.head_dim]
x = x.reshape(new_shape)
x = x.transpose([0, 2, 1, 3])
return x
def forward(self, x):
B, N, _ = x.shape #B=batch_size N=num_patchs
qkv = self.qkv(x).chunk(3, -1)
# [B, N, all_head_dim] * 3
q, k, v = map(self.transpose_multihead, qkv)
# q, k, v : [B, num_heads, N, head_dim]
attn = paddle.matmul(q, k, transpose_y=True)
attn = self.scales * attn
attn = self.softmax(attn)
attn = self.dropout(attn)
#attn = [B, num_heads, N, N]
out = paddle.matmul(attn, v)
# out = [B, num_heads, N, head_dim]
out = out.transpose([0, 2, 1, 3])
# out = [B, N, num_heads, head_dim]
out = out.reshape([B, N, -1])
# out = [B, N, all_head_dim]
out = self.proj(out)
# dropout
return out
2.3 EncoderLayer
class EncoderLayer(nn.Layer):
def __init__(self, embed_dim=768, num_heads=4, qkv_bias=True, mlp_ratio=4.0, dropout=0., attention_dropout=0.):
super().__init__()
self.attn_norm = nn.LayerNorm(embed_dim)
self.attn = Attention(embed_dim, num_heads)
self.mlp_norm = nn.LayerNorm(embed_dim)
self.mlp = Mlp(embed_dim, mlp_ratio)
def forward(self, x): #PreNorm
h = x
x = self.attn_norm(x)
x = self.attn(x)
x = h + x
h = x
x = self.mlp_norm(x)
x = self.mlp(x)
x = h + x
return x
3. VisualTransformer
class VisualTransformer(nn.Layer):
def __init__(self,
image_size=224,
patch_size=16,
in_channels=3,
num_classes=1000,
embed_dim=768,
depth=3,
num_heads=8,
mlp_ratio=4,
qkv_bias=True,
dropout=0.,
attention_dropout=0.,
droppath=0.):
super().__init__()
self.patch_embedding = PatchEmbedding(image_size, patch_size, in_channels, embed_dim)
self.encoder = Encoder(embed_dim, depth)
self.classifier = nn.Linear(embed_dim, num_classes) #class_token 全连接层,输出分类结果
def forward(self, x):
# x:[B, N, h, w]
x = self.patch_embedding(x)
#print(x.shape)
x = self.encoder(x)
#print(x.shape)
x = self.classifier(x[:,0])
#print(x.shape)
return x
def main():
vit = VisualTransformer()
print(vit)
paddle.summary(vit, (4, 3, 224, 224)) # must be tuple
if __name__ == "__main__":
main(
ViT网络结构
VisualTransformer(
(patch_embedding): PatchEmbedding(
(patch_embedding): Conv2D(3, 768, kernel_size=[16, 16], stride=[16, 16], data_format=NCHW)
(dropout): Dropout(p=0.0, axis=None, mode=upscale_in_train)
)
(encoder): Encoder(
(layers): LayerList(
(0): EncoderLayer(
(attn_norm): LayerNorm(normalized_shape=[768], epsilon=1e-05)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, dtype=float32)
(proj): Linear(in_features=768, out_features=768, dtype=float32)
(dropout): Dropout(p=0.0, axis=None, mode=upscale_in_train)
(attention_dropout): Dropout(p=0.0, axis=None, mode=upscale_in_train)
(softmax): Softmax(axis=-1)
)
(mlp_norm): LayerNorm(normalized_shape=[768], epsilon=1e-05)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, dtype=float32)
(fc2): Linear(in_features=3072, out_features=768, dtype=float32)
(act): GELU(approximate=False)
(dropout): Dropout(p=0.0, axis=None, mode=upscale_in_train)
)
)
(1): EncoderLayer(
(attn_norm): LayerNorm(normalized_shape=[768], epsilon=1e-05)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, dtype=float32)
(proj): Linear(in_features=768, out_features=768, dtype=float32)
(dropout): Dropout(p=0.0, axis=None, mode=upscale_in_train)
(attention_dropout): Dropout(p=0.0, axis=None, mode=upscale_in_train)
(softmax): Softmax(axis=-1)
)
(mlp_norm): LayerNorm(normalized_shape=[768], epsilon=1e-05)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, dtype=float32)
(fc2): Linear(in_features=3072, out_features=768, dtype=float32)
(act): GELU(approximate=False)
(dropout): Dropout(p=0.0, axis=None, mode=upscale_in_train)
)
)
(2): EncoderLayer(
(attn_norm): LayerNorm(normalized_shape=[768], epsilon=1e-05)
(attn): Attention(
(qkv): Linear(in_features=768, out_features=2304, dtype=float32)
(proj): Linear(in_features=768, out_features=768, dtype=float32)
(dropout): Dropout(p=0.0, axis=None, mode=upscale_in_train)
(attention_dropout): Dropout(p=0.0, axis=None, mode=upscale_in_train)
(softmax): Softmax(axis=-1)
)
(mlp_norm): LayerNorm(normalized_shape=[768], epsilon=1e-05)
(mlp): Mlp(
(fc1): Linear(in_features=768, out_features=3072, dtype=float32)
(fc2): Linear(in_features=3072, out_features=768, dtype=float32)
(act): GELU(approximate=False)
(dropout): Dropout(p=0.0, axis=None, mode=upscale_in_train)
)
)
)
(norm): LayerNorm(normalized_shape=[768], epsilon=1e-05)
)
(classifier): Linear(in_features=768, out_features=1000, dtype=float32)
)
----------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
============================================================================
Conv2D-9 [[4, 3, 224, 224]] [4, 768, 14, 14] 590,592
PatchEmbedding-9 [[4, 3, 224, 224]] [4, 197, 768] 152,064
LayerNorm-57 [[4, 197, 768]] [4, 197, 768] 1,536
Linear-105 [[4, 197, 768]] [4, 197, 2304] 1,771,776
Softmax-25 [[4, 4, 197, 197]] [4, 4, 197, 197] 0
Dropout-82 [[4, 4, 197, 197]] [4, 4, 197, 197] 0
Linear-106 [[4, 197, 768]] [4, 197, 768] 590,592
Attention-25 [[4, 197, 768]] [4, 197, 768] 0
LayerNorm-58 [[4, 197, 768]] [4, 197, 768] 1,536
Linear-107 [[4, 197, 768]] [4, 197, 3072] 2,362,368
GELU-25 [[4, 197, 3072]] [4, 197, 3072] 0
Dropout-84 [[4, 197, 768]] [4, 197, 768] 0
Linear-108 [[4, 197, 3072]] [4, 197, 768] 2,360,064
Mlp-25 [[4, 197, 768]] [4, 197, 768] 0
EncoderLayer-25 [[4, 197, 768]] [4, 197, 768] 0
LayerNorm-59 [[4, 197, 768]] [4, 197, 768] 1,536
Linear-109 [[4, 197, 768]] [4, 197, 2304] 1,771,776
Softmax-26 [[4, 4, 197, 197]] [4, 4, 197, 197] 0
Dropout-85 [[4, 4, 197, 197]] [4, 4, 197, 197] 0
Linear-110 [[4, 197, 768]] [4, 197, 768] 590,592
Attention-26 [[4, 197, 768]] [4, 197, 768] 0
LayerNorm-60 [[4, 197, 768]] [4, 197, 768] 1,536
Linear-111 [[4, 197, 768]] [4, 197, 3072] 2,362,368
GELU-26 [[4, 197, 3072]] [4, 197, 3072] 0
Dropout-87 [[4, 197, 768]] [4, 197, 768] 0
Linear-112 [[4, 197, 3072]] [4, 197, 768] 2,360,064
Mlp-26 [[4, 197, 768]] [4, 197, 768] 0
EncoderLayer-26 [[4, 197, 768]] [4, 197, 768] 0
LayerNorm-61 [[4, 197, 768]] [4, 197, 768] 1,536
Linear-113 [[4, 197, 768]] [4, 197, 2304] 1,771,776
Softmax-27 [[4, 4, 197, 197]] [4, 4, 197, 197] 0
Dropout-88 [[4, 4, 197, 197]] [4, 4, 197, 197] 0
Linear-114 [[4, 197, 768]] [4, 197, 768] 590,592
Attention-27 [[4, 197, 768]] [4, 197, 768] 0
LayerNorm-62 [[4, 197, 768]] [4, 197, 768] 1,536
Linear-115 [[4, 197, 768]] [4, 197, 3072] 2,362,368
GELU-27 [[4, 197, 3072]] [4, 197, 3072] 0
Dropout-90 [[4, 197, 768]] [4, 197, 768] 0
Linear-116 [[4, 197, 3072]] [4, 197, 768] 2,360,064
Mlp-27 [[4, 197, 768]] [4, 197, 768] 0
EncoderLayer-27 [[4, 197, 768]] [4, 197, 768] 0
LayerNorm-63 [[4, 197, 768]] [4, 197, 768] 1,536
Encoder-9 [[4, 197, 768]] [4, 197, 768] 0
Linear-117 [[4, 768]] [4, 1000] 769,000
============================================================================
Total params: 22,776,808
Trainable params: 22,776,808
Non-trainable params: 0
----------------------------------------------------------------------------
Input size (MB): 2.30
Forward/backward pass size (MB): 310.08
Params size (MB): 86.89
Estimated Total Size (MB): 399.26
----------------------------------------------------------------------------
二、DeiT
DeiT解决的最大的问题:
- ViT模型性能被大幅度提高了
- ViT模型能用8卡甚至4卡训练了
DeiT能够取得更好的效果的改进方法:
- Better Hyperparameter(更好的超参数设置)
- Data Augmentation(多个数据增广)
- Distillation(知识蒸馏)
三、DETR
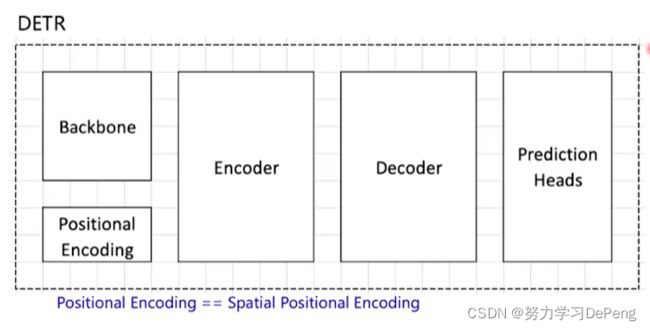
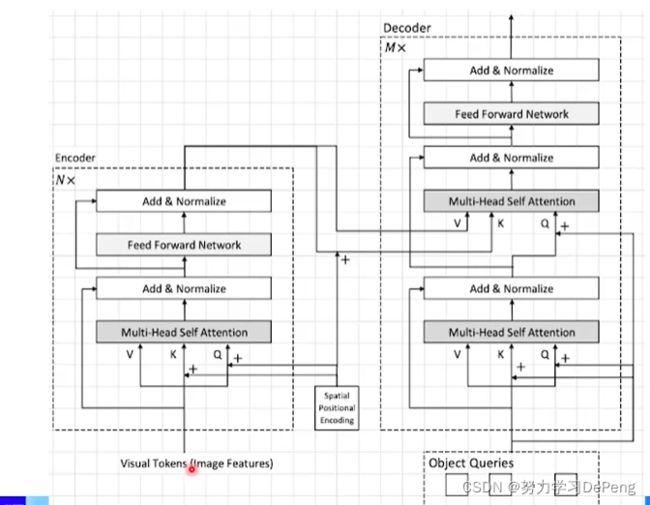
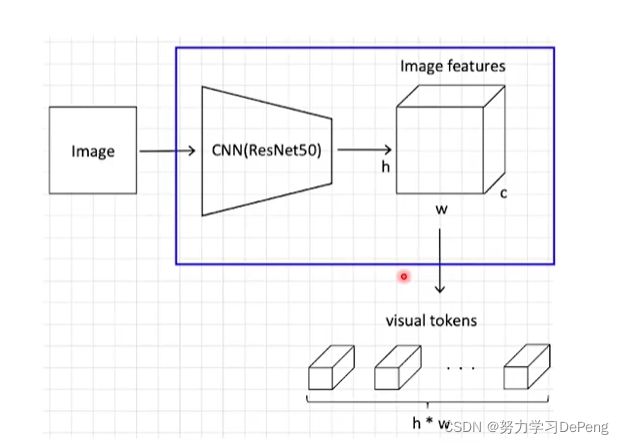
1.Backbone
相当于ViT中的Patch Embedding
2. Encoder
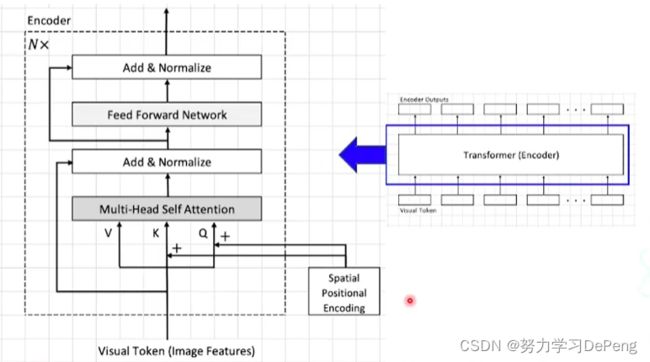
3. Decoder
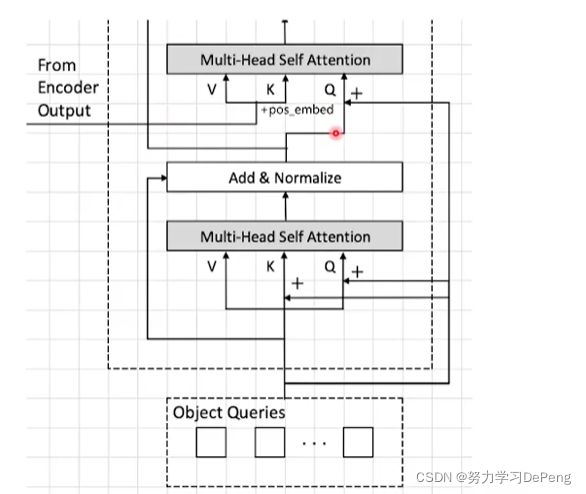
4.Prediction Heads
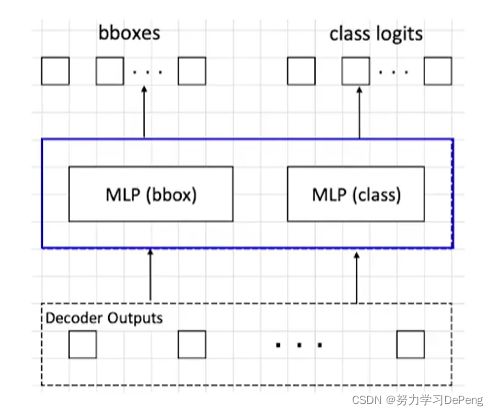
注:
Positional Encoding

Decoder output

DETR可以没有Decoder
ICCV2021
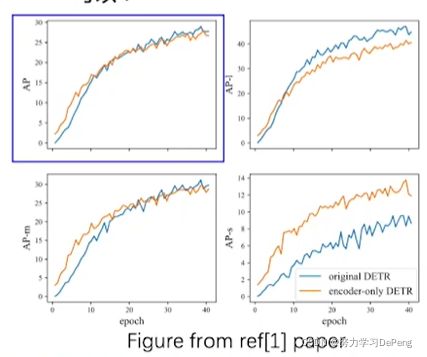
大物体,中等物体,小物体