- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
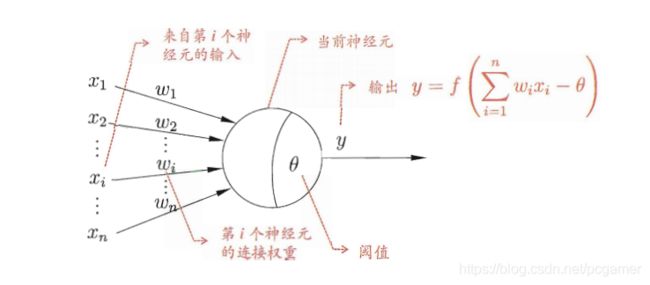
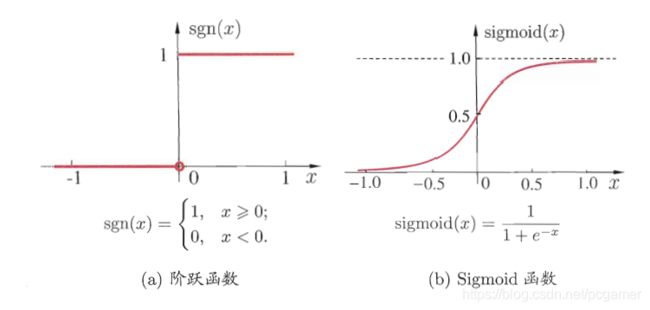
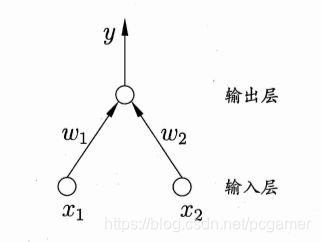
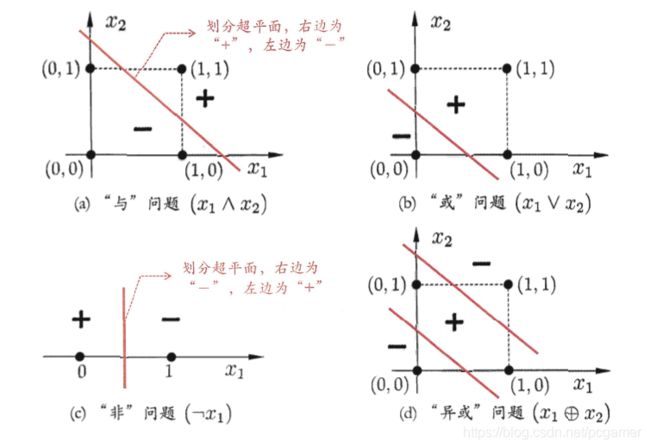
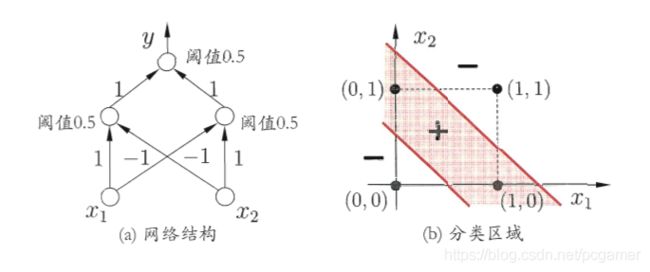
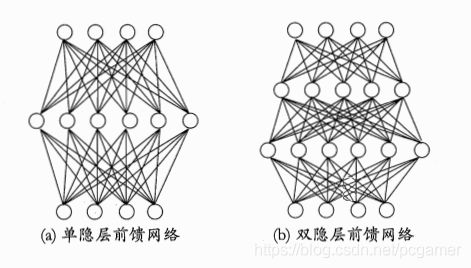
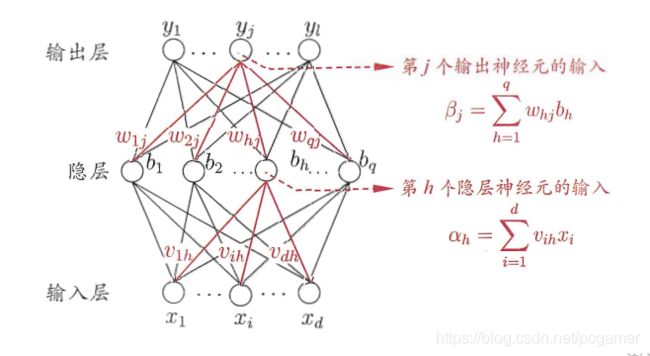
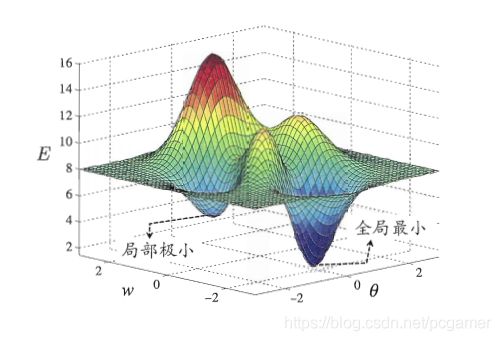
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 底层逆袭到底有多难,不甘平凡的你准备好了吗?让吴起给你说说
造命者说
底层逆袭到底有多难,不甘平凡的你准备好了吗?让吴起给你说说我叫吴起,生于公元前440年的战国初期,正是群雄并起、天下纷争不断的时候。后人说我是军事家、政治家、改革家,是兵家代表人物。评价我一生历仕鲁、魏、楚三国,通晓兵家、法家、儒家三家思想,在内政军事上都有极高的成就。周安王二十一年(公元前381年),因变法得罪守旧贵族,被人乱箭射死。我出生在卫国一个“家累万金”的富有家庭,从年轻时候起就不甘平凡
- 2020-01-25
晴岚85
郑海燕坚持分享590天2020.1.24在生活中只存在两个问题。一个问题是:你知道想要达成的目标是什么,但却不知道如何才能达成;另一个问题是:你不知道你的目标是什么。前一个是行动的问题,后一个是结果的问题。通过制定具体的下一步行动,可以解决不知道如何开始行动的问题。而通过去想象结果,对结果做预估,可以解决找不着目标的问题。对于所有吸引我们注意力,想要完成的任务,你可以先想象一下,预期的结果究竟是什
- OC语言多界面传值五大方式
Magnetic_h
iosui学习objective-c开发语言
前言在完成暑假仿写项目时,遇到了许多需要用到多界面传值的地方,这篇博客来总结一下比较常用的五种多界面传值的方式。属性传值属性传值一般用前一个界面向后一个界面传值,简单地说就是通过访问后一个视图控制器的属性来为它赋值,通过这个属性来做到从前一个界面向后一个界面传值。首先在后一个界面中定义属性@interfaceBViewController:UIViewController@propertyNSSt
- 10月|愿你的青春不负梦想-读书笔记-01
Tracy的小书斋
本书的作者是俞敏洪,大家都很熟悉他了吧。俞敏洪老师是我行业的领头羊吧,也是我事业上的偶像。本日摘录他书中第一章中的金句:『一个人如果什么目标都没有,就会浑浑噩噩,感觉生命中缺少能量。能给我们能量的,是对未来的期待。第一件事,我始终为了进步而努力。与其追寻全世界的骏马,不如种植丰美的草原,到时骏马自然会来。第二件事,我始终有阶段性的目标。什么东西能给我能量?答案是对未来的期待。』读到这里的时候,我便
- 《投行人生》读书笔记
小蘑菇的树洞
《投行人生》----作者詹姆斯-A-朗德摩根斯坦利副主席40年的职业洞见-很短小精悍的篇幅,比较适合初入职场的新人。第一部分成功的职业生涯需要规划1.情商归为适应能力分享与协作同理心适应能力,更多的是自我意识,你有能力识别自己的情并分辨这些情绪如何影响你的思想和行为。2.对于初入职场的人的建议,细节,截止日期和数据很重要截止日期,一种有效的方法是请老板为你所有的任务进行优先级排序。和老板喝咖啡的好
- 直抒《紫罗兰永恒花园外传》
雷姆的黑色童话
没看过《紫罗兰永恒花园》的我莫名的看完了《紫罗兰永恒花园外传》,又莫名的被故事中的姐妹之情狠狠地感动了的一把。感动何在:困苦中相依为命的姐妹二人被迫分离,用一个人的自由换取另一个人的幸福。之后,虽相隔不知几许依旧心心念念彼此牵挂。这种深深的姐妹情谊就是令我为之动容的所在。贝拉和泰勒分别影片开始,海天之间一个孩童凭栏眺望,手中拿着折旧的信纸。镜头一转,挑灯伏案的薇尔莉特正在打字机前奋笔疾书。这些片段
- 基于社交网络算法优化的二维最大熵图像分割
智能算法研学社(Jack旭)
智能优化算法应用图像分割算法php开发语言
智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码文章目录智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码1.前言2.二维最大熵阈值分割原理3.基于社交网络优化的多阈值分割4.算法结果:5.参考文献:6.Matlab代码摘要:本文介绍基于最大熵的图像分割,并且应用社交网络算法进行阈值寻优。1.前言阅读此文章前,请阅读《图像分割:直方图区域划分及信息统计介绍》htt
- 拥有断舍离的心态,过精简生活--《断舍离》读书笔记
爱吃丸子的小樱桃
不知不觉间房间里的东西越来越多,虽然摆放整齐,但也时常会觉得空间逼仄,令人心生烦闷。抱着断舍离的态度,我开始阅读《断舍离》这本书,希望从书中能找到一些有效的方法,帮助我实现空间、物品上的断舍离。《断舍离》是日本作家山下英子通过自己的经历、思考和实践总结而成的,整体内涵也从刚开始的私人生活哲学的“断舍离”升华成了“人生实践哲学”,接着又成为每个人都能实行的“改变人生的断舍离”,从“哲学”逐渐升华成“
- 398顺境,逆境
戴骁勇
2018.11.27周二雾霾最近儿子进入了一段顺境期,今天表现尤其不错。今天的数学测试成绩喜人,没有出现以往的计算错误,整个卷面书写工整,附加题也在规定时间内完成且做对。为迎接体育测试的锻炼有了质的飞跃。坐位体前屈成绩突飞猛进,估测成绩能达到12cm,这和上次测试的零分来比,简直是逆袭。儿子还在不断锻炼和提升,唯恐到时候掉链子。跑步姿势在我的调教下,逐渐正规起来,速度随之也有了提升。今晚测试的50
- 数组去重
好奇的猫猫猫
整理自js中基础数据结构数组去重问题思考?如何去除数组中重复的项例如数组:[1,3,4,3,5]我们在做去重的时候,一开始想到的肯定是,逐个比较,外面一层循环,内层后一个与前一个一比较,如果是久不将当前这一项放进新的数组,挨个比较完之后返回一个新的去过重复的数组不好的实践方式上述方法效率极低,代码量还多,思考?有没有更好的方法这时候不禁一想当然有了!!!hashtable啊,通过对象的hash办法
- 121. 买卖股票的最佳时机
薄荷糖的味道_fb40
给定一个数组,它的第i个元素是一支给定股票第i天的价格。如果你最多只允许完成一笔交易(即买入和卖出一支股票),设计一个算法来计算你所能获取的最大利润。注意你不能在买入股票前卖出股票。示例1:输入:[7,1,5,3,6,4]输出:5解释:在第2天(股票价格=1)的时候买入,在第5天(股票价格=6)的时候卖出,最大利润=6-1=5。注意利润不能是7-1=6,因为卖出价格需要大于买入价格。示例2:输入:
- 2022-11-17
无奇君
又去了一次社康,这次是急性支气管炎……太难了。半夜就猛咳,天天咳醒,还好他戴海绵耳塞睡吵不到他,要不然对他来说也是种煎熬。一累也会猛咳,希望这次是最后一次吃药,吃完就好。又想把头发剪短了,顺便染个色。可是刚刚去看人家还没开门,不是休息日老板好佛系。理发店是个夫妻店,一年多前刚搬来的时候老板还没对象呢,当时聊天老板就说希望能找个对象一起两个人守着店都比上班强。不久后再去他已经有对象了,而且在店里帮忙
- 傍晚
小罗琳
鸟叫声在小区那边,密密稠稠,轻快而明亮,它们是归巢前互道晚安呢!金色的黄昏洋洋洒洒地飘落在房屋上,给它们镀上了一层淡淡的金边。一到黄昏,没有一个地方不是热闹的,街上的车慢慢多起来,出来散步的人也三五成群,谈笑风生。狗狗们似乎也闷坏了,撒欢地你追我赶,尽管小雨刚停,但它们的热情不减,叫着跑着,好不热闹。潮湿的空气弥漫着醉人的芬芳,楼下的杜鹃花也欣欣然张开了嘴,火红的花瓣张扬地舞动着,鲜艳欲滴,花瓣似
- 数字里的世界17期:2021年全球10大顶级数据中心,中国移动榜首
张三叨
你知道吗?2016年,全球的数据中心共计用电4160亿千瓦时,比整个英国的发电量还多40%!前言每天,我们都会创造超过250万TB的数据。并且随着物联网(IOT)的不断普及,这一数据将持续增长。如此庞大的数据被存储在被称为“数据中心”的专用设施中。虽然最早的数据中心建于20世纪40年代,但直到1997-2000年的互联网泡沫期间才逐渐成为主流。当前人类的技术,比如人工智能和机器学习,已经将我们推向
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- insert into select 主键自增_mybatis拦截器实现主键自动生成
weixin_39521651
insertintoselect主键自增mybatisdelete返回值mybatisinsert返回主键mybatisinsert返回对象mybatisplusinsert返回主键mybatisplus插入生成id
前言前阵子和朋友聊天,他说他们项目有个需求,要实现主键自动生成,不想每次新增的时候,都手动设置主键。于是我就问他,那你们数据库表设置主键自动递增不就得了。他的回答是他们项目目前的id都是采用雪花算法来生成,因此为了项目稳定性,不会切换id的生成方式。朋友问我有没有什么实现思路,他们公司的orm框架是mybatis,我就建议他说,不然让你老大把mybatis切换成mybatis-plus。mybat
- 和自己结婚,是一种怎样的体验
只如初见_2020
一个17岁谈恋爱,19岁结婚,然后离了三次婚的女人,站在台上说:“现在我结婚了,和那个一直以来,真正想在一起的人结婚了,那个人就是我自己。”她说,在我9岁前,我已经在二十几个寄养家庭中待过。我从童年到成年,就只有一个目标,不要被落下。而我实现这一目标的方式就是,我要结婚。我第一次的结婚对象,是我17岁时遇到的人。我们两年之后结了婚,当时我19岁。他是个非常好的人,来自于非常棒的家庭,他是工商管理硕
- Python开发常用的三方模块如下:
换个网名有点难
python开发语言
Python是一门功能强大的编程语言,拥有丰富的第三方库,这些库为开发者提供了极大的便利。以下是100个常用的Python库,涵盖了多个领域:1、NumPy,用于科学计算的基础库。2、Pandas,提供数据结构和数据分析工具。3、Matplotlib,一个绘图库。4、Scikit-learn,机器学习库。5、SciPy,用于数学、科学和工程的库。6、TensorFlow,由Google开发的开源机
- TDengine 签约前晨汽车,解锁智能出行的无限潜力
涛思数据(TDengine)
tdengine汽车大数据
在全球汽车产业转型升级的背景下,智能网联和新能源技术正迅速成为商用车行业的重要发展方向。随着市场对环保和智能化需求的日益增强,企业必须在技术创新和数据管理上不断突破,以满足客户对高效、安全和智能出行的期待。在这一背景下,前晨汽车凭借其在新能源智能商用车领域的前瞻性布局和技术实力,成为行业中的佼佼者。前晨汽车采用整车数据采集和全车数据打通策略,能够实时将数据推送至APP端客户。然而,这导致整体写入和
- 关于Mysql 中 Row size too large (> 8126) 错误的解决和理解
秋刀prince
mysqlmysql数据库
提示:啰嗦一嘴,数据库的任何操作和验证前,一定要记得先备份!!!不会有错;文章目录问题发现一、问题导致的可能原因1、页大小2、行格式2.1compact格式2.2Redundant格式2.3Dynamic格式2.4Compressed格式3、BLOB和TEXT列二、解决办法1、修改页大小(不推荐)2、修改行格式3、修改数据类型为BLOB和TEXT列4、其他优化方式(可以参考使用)4.1合理设置数据
- 为什么瘦子很难增胖?
我的狗毛毛
我是个标准的瘦子,168,100斤。用一句通俗的话来讲,我连马甲线都瘦出来了(体脂含量比较低)。但是我反而很羡慕那些比较丰满的女人,我的理想是再增重十五斤,练成前凸后翘的魔鬼身材。为此我开始纠正自己不规律的作息,吃高热量的食物,减少运动量,能坐着绝不站着,能躺着绝不坐着。但是结果却没有丝毫变化。我一直很苦恼,直到最近在网上看到一个视频,英国的某个研究机构做了一个实验,想要知道瘦子能否在高热量的食物
- Python实现简单的机器学习算法
master_chenchengg
pythonpython办公效率python开发IT
Python实现简单的机器学习算法开篇:初探机器学习的奇妙之旅搭建环境:一切从安装开始必备工具箱第一步:安装Anaconda和JupyterNotebook小贴士:如何配置Python环境变量算法初体验:从零开始的Python机器学习线性回归:让数据说话数据准备:从哪里找数据编码实战:Python实现线性回归模型评估:如何判断模型好坏逻辑回归:从分类开始理论入门:什么是逻辑回归代码实现:使用skl
- 【从浅识到熟知Linux】Linux发展史
Jammingpro
从浅学到熟知Linuxlinux运维服务器
归属专栏:从浅学到熟知Linux个人主页:Jammingpro每日努力一点点,技术变化看得见文章前言:本篇文章记录Linux发展的历史,因在介绍Linux过程中涉及的其他操作系统及人物,本文对相关内容也有所介绍。文章目录Unix发展史Linux发展史开源Linux官网企业应用情况发行版本在学习Linux前,我们可能都会问Linux从哪里来?它是如何发展的。但在介绍Linux之前,需要先介绍一下Un
- 生于八十年代--我的姐姐
自南向北
姐姐大我四岁,幸亏有了她,才有了我。要是头一个是男孩,估计在家里就是另一个孩子了。在我儿时的记忆里,姐姐是一下子蹦出来的,为什么这么说?因为在我五六岁前的印象里是没有她的,五六岁后就突然出现在了我家。上学前的那段时间我俩一直在一起,母亲白天上班,把午饭准备好后,就出门了。屋里就留下两个孩子,由着我们在田间地头,屋前河边到处转悠,现在想来是危险至极,但是在当时却也没有旁的办法。生活是第一位的,父亲在
- 2022-12-25
罗平凤a98
让自己优秀起来吧睡觉前对今年的复盘。这一年有的变化是什么呢?不自知的开始难受。今年是我长这么大以来最难受,也将是我最难忘的一年吧!内卷到将近步入抑郁的一年。坚持了八年的工作在这个疫情情况下步入了进退两难的地步。再次回头才发现一直都在做着单线的收资,效益好就不太内卷。不好,那这一年就是坐着动荡的过山车,心惊胆战。这活法是不是太过于被动了??上有老下有小,关键压力都在这个中年期体现出来了,回头看看自己
- 读书笔记|《遇见孩子,遇见更好的自己》5
抹茶社长
为人父母意味着放弃自己的过去,不要对以往没有实现的心愿耿耿于怀,只有这样,孩子们才能做回自己。985909803.jpg孩子在与父母保持亲密的同时更需要独立,唯有这样,孩子才会成为孩子,父母才会成其为父母。有耐心的人生往往更幸福,给孩子留点余地。认识到养儿育女是对耐心的考验。为失败做好心理准备,教会孩子控制情绪。了解自己的底线,说到底线,有一点很重要,父母之所以发脾气,真正的原因往往在于他们自己,
- 春雨 · 心境
jinlinglq
春捂秋冻,谁都知晓。清明前,南京的气温逼近30℃,这样就不能再去“捂”了,否则就会让人怀疑你身上穿的真是租来的了。可是,一场清明时节的春雨又让爬高的温度如过山车般地下降,今天气温已然呈个位数了。昨日在家,我还说起南京的俗语:三月三,冻得把眼翻。意思是,即使到了农历三月三,南京还是会有低温来临。母亲更正道:错了,应该是“三月三,冻得把衣翻”。农历的三月三要是冻得把眼翻,那还得了?其实是把收起的冬衣从
- 2024.8.22 Python,链表两数之和,链表快速反转,二叉树的深度,二叉树前中后序遍历,N叉树递归遍历,翻转二叉树
RaidenQ
python链表开发语言
1.链表两数之和输入:l1=[2,4,3],l2=[5,6,4]输出:[7,0,8]解释:342+465=807.示例2:输入:l1=[0],l2=[0]输出:[0]示例3:输入:l1=[9,9,9,9,9,9,9],l2=[9,9,9,9]输出:[8,9,9,9,0,0,0,1]昨天的这个题,用自己的办法写的麻烦的要死,然后刚才一看chat归类的办法,感觉自己像个智障。classListNode
- 骑昆明到北海—119 砚山县
61清风i
从十年前第一次长途骑行青海湖开始每年一次长途骑行看风景,尝各地美食,探访异域文化,记录途中美食美景美事,已逐渐形成习惯。每年春季详细规划好线路,夏季出行,2020年因为疫情迟迟不能确定线路和行程。总算到了暑期疫情逐渐消失,规划了50多天的云南昆明—广西北海计划。本次行程从云南昆明出发到广西北海市结束,五十一天骑行二千多公里线路昆明-官渡古镇-环滇池--澄江市一抚仙湖—路居镇--江川区--通海县—龙
- 关于旗正规则引擎下载页面需要弹窗保存到本地目录的问题
何必如此
jsp超链接文件下载窗口
生成下载页面是需要选择“录入提交页面”,生成之后默认的下载页面<a>标签超链接为:<a href="<%=root_stimage%>stimage/image.jsp?filename=<%=strfile234%>&attachname=<%=java.net.URLEncoder.encode(file234filesourc
- 【Spark九十八】Standalone Cluster Mode下的资源调度源代码分析
bit1129
cluster
在分析源代码之前,首先对Standalone Cluster Mode的资源调度有一个基本的认识:
首先,运行一个Application需要Driver进程和一组Executor进程。在Standalone Cluster Mode下,Driver和Executor都是在Master的监护下给Worker发消息创建(Driver进程和Executor进程都需要分配内存和CPU,这就需要Maste
- linux上独立安装部署spark
daizj
linux安装spark1.4部署
下面讲一下linux上安装spark,以 Standalone Mode 安装
1)首先安装JDK
下载JDK:jdk-7u79-linux-x64.tar.gz ,版本是1.7以上都行,解压 tar -zxvf jdk-7u79-linux-x64.tar.gz
然后配置 ~/.bashrc&nb
- Java 字节码之解析一
周凡杨
java字节码javap
一: Java 字节代码的组织形式
类文件 {
OxCAFEBABE ,小版本号,大版本号,常量池大小,常量池数组,访问控制标记,当前类信息,父类信息,实现的接口个数,实现的接口信息数组,域个数,域信息数组,方法个数,方法信息数组,属性个数,属性信息数组
}
&nbs
- java各种小工具代码
g21121
java
1.数组转换成List
import java.util.Arrays;
Arrays.asList(Object[] obj); 2.判断一个String型是否有值
import org.springframework.util.StringUtils;
if (StringUtils.hasText(str)) 3.判断一个List是否有值
import org.spring
- 加快FineReport报表设计的几个心得体会
老A不折腾
finereport
一、从远程服务器大批量取数进行表样设计时,最好按“列顺序”取一个“空的SQL语句”,这样可提高设计速度。否则每次设计时模板均要从远程读取数据,速度相当慢!!
二、找一个富文本编辑软件(如NOTEPAD+)编辑SQL语句,这样会很好地检查语法。有时候带参数较多检查语法复杂时,结合FineReport中生成的日志,再找一个第三方数据库访问软件(如PL/SQL)进行数据检索,可以很快定位语法错误。
- mysql linux启动与停止
墙头上一根草
如何启动/停止/重启MySQL一、启动方式1、使用 service 启动:service mysqld start2、使用 mysqld 脚本启动:/etc/inint.d/mysqld start3、使用 safe_mysqld 启动:safe_mysqld&二、停止1、使用 service 启动:service mysqld stop2、使用 mysqld 脚本启动:/etc/inin
- Spring中事务管理浅谈
aijuans
spring事务管理
Spring中事务管理浅谈
By Tony Jiang@2012-1-20 Spring中对事务的声明式管理
拿一个XML举例
[html]
view plain
copy
print
?
<?xml version="1.0" encoding="UTF-8"?>&nb
- php中隐形字符65279(utf-8的BOM头)问题
alxw4616
php中隐形字符65279(utf-8的BOM头)问题
今天遇到一个问题. php输出JSON 前端在解析时发生问题:parsererror.
调试:
1.仔细对比字符串发现字符串拼写正确.怀疑是 非打印字符的问题.
2.逐一将字符串还原为unicode编码. 发现在字符串头的位置出现了一个 65279的非打印字符.
- 调用对象是否需要传递对象(初学者一定要注意这个问题)
百合不是茶
对象的传递与调用技巧
类和对象的简单的复习,在做项目的过程中有时候不知道怎样来调用类创建的对象,简单的几个类可以看清楚,一般在项目中创建十几个类往往就不知道怎么来看
为了以后能够看清楚,现在来回顾一下类和对象的创建,对象的调用和传递(前面写过一篇)
类和对象的基础概念:
JAVA中万事万物都是类 类有字段(属性),方法,嵌套类和嵌套接
- JDK1.5 AtomicLong实例
bijian1013
javathreadjava多线程AtomicLong
JDK1.5 AtomicLong实例
类 AtomicLong
可以用原子方式更新的 long 值。有关原子变量属性的描述,请参阅 java.util.concurrent.atomic 包规范。AtomicLong 可用在应用程序中(如以原子方式增加的序列号),并且不能用于替换 Long。但是,此类确实扩展了 Number,允许那些处理基于数字类的工具和实用工具进行统一访问。
- 自定义的RPC的Java实现
bijian1013
javarpc
网上看到纯java实现的RPC,很不错。
RPC的全名Remote Process Call,即远程过程调用。使用RPC,可以像使用本地的程序一样使用远程服务器上的程序。下面是一个简单的RPC 调用实例,从中可以看到RPC如何
- 【RPC框架Hessian一】Hessian RPC Hello World
bit1129
Hello world
什么是Hessian
The Hessian binary web service protocol makes web services usable without requiring a large framework, and without learning yet another alphabet soup of protocols. Because it is a binary p
- 【Spark九十五】Spark Shell操作Spark SQL
bit1129
shell
在Spark Shell上,通过创建HiveContext可以直接进行Hive操作
1. 操作Hive中已存在的表
[hadoop@hadoop bin]$ ./spark-shell
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Welcom
- F5 往header加入客户端的ip
ronin47
when HTTP_RESPONSE {if {[HTTP::is_redirect]}{ HTTP::header replace Location [string map {:port/ /} [HTTP::header value Location]]HTTP::header replace Lo
- java-61-在数组中,数字减去它右边(注意是右边)的数字得到一个数对之差. 求所有数对之差的最大值。例如在数组{2, 4, 1, 16, 7, 5,
bylijinnan
java
思路来自:
http://zhedahht.blog.163.com/blog/static/2541117420116135376632/
写了个java版的
public class GreatestLeftRightDiff {
/**
* Q61.在数组中,数字减去它右边(注意是右边)的数字得到一个数对之差。
* 求所有数对之差的最大值。例如在数组
- mongoDB 索引
开窍的石头
mongoDB索引
在这一节中我们讲讲在mongo中如何创建索引
得到当前查询的索引信息
db.user.find(_id:12).explain();
cursor: basicCoursor 指的是没有索引
&
- [硬件和系统]迎峰度夏
comsci
系统
从这几天的气温来看,今年夏天的高温天气可能会维持在一个比较长的时间内
所以,从现在开始准备渡过炎热的夏天。。。。
每间房屋要有一个落地电风扇,一个空调(空调的功率和房间的面积有密切的关系)
坐的,躺的地方要有凉垫,床上要有凉席
电脑的机箱
- 基于ThinkPHP开发的公司官网
cuiyadll
行业系统
后端基于ThinkPHP,前端基于jQuery和BootstrapCo.MZ 企业系统
轻量级企业网站管理系统
运行环境:PHP5.3+, MySQL5.0
系统预览
系统下载:http://www.tecmz.com
预览地址:http://co.tecmz.com
各种设备自适应
响应式的网站设计能够对用户产生友好度,并且对于
- Transaction and redelivery in JMS (JMS的事务和失败消息重发机制)
darrenzhu
jms事务承认MQacknowledge
JMS Message Delivery Reliability and Acknowledgement Patterns
http://wso2.com/library/articles/2013/01/jms-message-delivery-reliability-acknowledgement-patterns/
Transaction and redelivery in
- Centos添加硬盘完全教程
dcj3sjt126com
linuxcentoshardware
Linux的硬盘识别:
sda 表示第1块SCSI硬盘
hda 表示第1块IDE硬盘
scd0 表示第1个USB光驱
一般使用“fdisk -l”命
- yii2 restful web服务路由
dcj3sjt126com
PHPyii2
路由
随着资源和控制器类准备,您可以使用URL如 http://localhost/index.php?r=user/create访问资源,类似于你可以用正常的Web应用程序做法。
在实践中,你通常要用美观的URL并采取有优势的HTTP动词。 例如,请求POST /users意味着访问user/create动作。 这可以很容易地通过配置urlManager应用程序组件来完成 如下所示
- MongoDB查询(4)——游标和分页[八]
eksliang
mongodbMongoDB游标MongoDB深分页
转载请出自出处:http://eksliang.iteye.com/blog/2177567 一、游标
数据库使用游标返回find的执行结果。客户端对游标的实现通常能够对最终结果进行有效控制,从shell中定义一个游标非常简单,就是将查询结果分配给一个变量(用var声明的变量就是局部变量),便创建了一个游标,如下所示:
> var
- Activity的四种启动模式和onNewIntent()
gundumw100
android
Android中Activity启动模式详解
在Android中每个界面都是一个Activity,切换界面操作其实是多个不同Activity之间的实例化操作。在Android中Activity的启动模式决定了Activity的启动运行方式。
Android总Activity的启动模式分为四种:
Activity启动模式设置:
<acti
- 攻城狮送女友的CSS3生日蛋糕
ini
htmlWebhtml5csscss3
在线预览:http://keleyi.com/keleyi/phtml/html5/29.htm
代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>攻城狮送女友的CSS3生日蛋糕-柯乐义<
- 读源码学Servlet(1)GenericServlet 源码分析
jzinfo
tomcatWebservlet网络应用网络协议
Servlet API的核心就是javax.servlet.Servlet接口,所有的Servlet 类(抽象的或者自己写的)都必须实现这个接口。在Servlet接口中定义了5个方法,其中有3个方法是由Servlet 容器在Servlet的生命周期的不同阶段来调用的特定方法。
先看javax.servlet.servlet接口源码:
package
- JAVA进阶:VO(DTO)与PO(DAO)之间的转换
snoopy7713
javaVOHibernatepo
PO即 Persistence Object VO即 Value Object
VO和PO的主要区别在于: VO是独立的Java Object。 PO是由Hibernate纳入其实体容器(Entity Map)的对象,它代表了与数据库中某条记录对应的Hibernate实体,PO的变化在事务提交时将反应到实际数据库中。
实际上,这个VO被用作Data Transfer
- mongodb group by date 聚合查询日期 统计每天数据(信息量)
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
/* 1 */
{
"_id" : ObjectId("557ac1e2153c43c320393d9d"),
"msgType" : "text",
"sendTime" : ISODate("2015-06-12T11:26:26.000Z")
- java之18天 常用的类(一)
Luob.
MathDateSystemRuntimeRundom
System类
import java.util.Properties;
/**
* System:
* out:标准输出,默认是控制台
* in:标准输入,默认是键盘
*
* 描述系统的一些信息
* 获取系统的属性信息:Properties getProperties();
*
*
*
*/
public class Sy
- maven
wuai
maven
1、安装maven:解压缩、添加M2_HOME、添加环境变量path
2、创建maven_home文件夹,创建项目mvn_ch01,在其下面建立src、pom.xml,在src下面简历main、test、main下面建立java文件夹
3、编写类,在java文件夹下面依照类的包逐层创建文件夹,将此类放入最后一级文件夹
4、进入mvn_ch01
4.1、mvn compile ,执行后会在