【毕业设计】大数据金融产品销售预测与分析系统 - python
文章目录
- 1 简介
- 2 背景
- 3 数据内容
- 4 数据分析目标
- 5 数据分析思路
- 6 数据分析
-
- 6.1 数据预处理
- 6.2 数据分析
- 7 最后
1 简介
Hi,大家好,这里是丹成学长的毕设系列文章!
对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
基于大数据分析的金融产品销售预测分析
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md
2 背景
某金融公司新推出的理财产品,预测客户是否会接受新的产品,并提高产品的销售量。
3 数据内容
根据公司提供的用户数据,包括职业、婚姻状态房产、年龄、违约情况等数据。与近期购买的详细资料,包括金额、购买频率,时间等相关数据。
4 数据分析目标
根据客户的信息,将客户进行分类打上标签,预测该用户是否会购买理财产品以及是否需要对该用户进行主动销售。
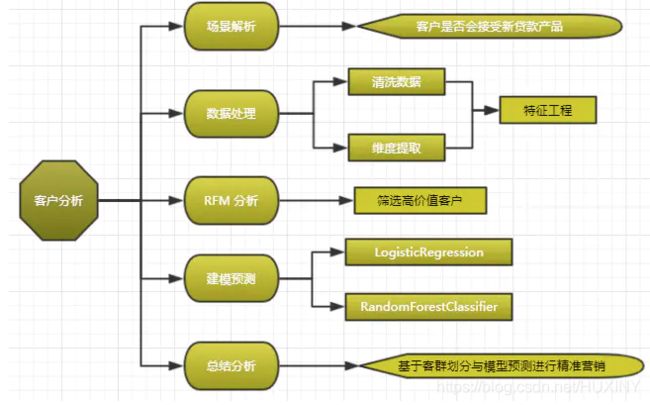
5 数据分析思路
对客户进行精准营销可以提高产品的销售。那么对产品分析转换为对客户的分析。
考虑客户是否能接受新的产品,可以从两方面着手分析。
- 依据往期客户数据进行是否购买预测,二分类回归问题。
- 根据客户价值进行划分,对高价值客户加大营销力度。
- 根据结果可以对客户进行分群划分,降低营销成本。
6 数据分析
6.1 数据预处理
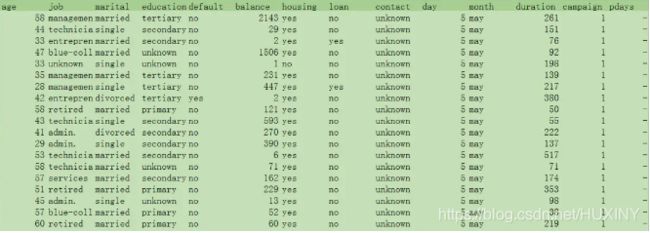
数据观察
IO1 = r'MyData\Yian_Cinformation1782.csv'
IO2= r'MyData\Yian_details1782.csv'
data1 = pd.read_csv(IO, header=None, names=(['id','name','age','job','marital','education','default','balance','housing','loan','contact','day','month','duration','campaign','pdays','previous','poutcome','address','y'])
data2 = pd.read_csv(IO2)
根据业务常识,客户基本信息删除如ID,姓名等无关维度。
还款明细提取总计金额,购买时间,购买产品数等维度。
数据清洗
客户资料文本数据较多,去除缺失的数据以免影响结果。
6.2 数据分析
文本数值化 ,本次基本信息中主要处理的是职业,学历,地址等文本信息。
data1.groupby(['job']).describe()

根据业务经验将对应的职业划分打分。
def Replace (X,columns):
a = X.groupby([columns],as_index=False)[columns].agg({'cnt':'count'})
for i in a[columns]:
X[columns] = X[columns].replace(i,a[(a[columns]== i )].index.tolist()[0])
return (X)
def Len(X,columns):
for i in X[columns]:
X[columns] = X[columns].replace(i,len(i))
return (X)
将文本转化为数值
def Sigmoid (X):
return (1.0 / (1 + np.exp(-float(X)))
数据归一化
相关性分析
数据处理之后,选择相关性最强的前17位维度进行分析观测
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
corrmat = data.corr()
k = 17
plt.figure(figsize=(12,9))
cols = corrmat.nlargest(k, 'y')['y'].index
cm = np.corrcoef(data[cols].values.T)
sns.set(font_scale=1.25,font='SimHei')
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', cmap='YlOrBr_r',annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()

提取维度
data1客户分析,将相关性较低的维度数据删除。
data2贷款记录,提取R,F,M。
import datetime as dt
now = dt.datetime(2017,11,14)
#查看交易最早-最晚日期
print(data2['Borrowing_date'].min())
print(data2['Borrowing_date'].max())
#构造交易时间间隔变量 hist
data2['hist'] = now - df['Borrowing_date']
data2['hist'].astype('timedelta64[D]')
data2['hist'] = data2['hist'] / np.timedelta64(1,'D')
data2.head()
#生成R F M 特征变量 agg()分组函数
customer = data2.groupby('customer_id').agg(['hist':'min', #Recency
'customer_id':'count', #Frequency
'tran_amount':'sum']) #Monetary
#对变量重命名
customer.rename(columns = {'hist':'recency'
'customer_id':'frequency'
'tran_amount':'monetary'},inplace = True)
特征工程
验衍生出新的维度。
- a. 统计每个客户使用的不同产品量,1列(目的:分析产品总数与是否购买关联)
- b.统计每个客户近期的产品购买频率。(目的:分析客户的近期的资金需求量)
- c. 统计客户借款金额与还款的差值。(目的:分析客户贷款产品的需求度)
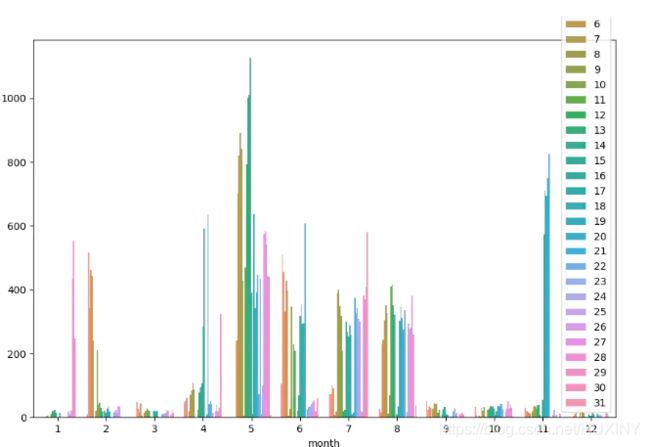
对已有数据进行观测分析
eg:分析借贷时间可以针对销售时间进行调整。
plt.subplots(figsize=(12,9))
sns.countplot(x='month',,hue='day',data=data1)
特征筛选
本次维度较少,但是为了提高模型预测准确率,对数据进行特征整合。
考虑因子分析与主成分分析,根据模型准确率选择使用。
RMF分析
K-Means聚类算法对客户数据进行分群
from sklearn.externals import joblib
from sklearn.cluster import KMeans
k=5
kmodel=KMeans(n_clusters=k,n_jobs=4)
kmodel.fit(customer)
r1=pd.Series(kmodel.labels_).value_counts()
r2=pd.DataFrame(kmodel.cluster_centers_)
r3=pd.Series(['group1','group2','group3','group4','group5',])
r=pd.concat([r3,r1,r2],axis=1)
r.columns=['聚类类别','聚类个数']+list(customer.columns)
r.to_csv(KMeans_result,encoding = 'utf_8_sig',index=False)
通过观测客户数及聚类中心,划分客户分类。
labels = np.array(list(customer.columns))
dataLenth = 5
r4=r2.T
r4.columns=list(customer.columns)
fig = plt.figure()
y=[]
for x in list(customer.columns):
dt= r4[x]
dt=np.concatenate((dt,[dt[0]]))
y.append(dt)
ax = fig.add_subplot(111, polar=True)
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False)
angles = np.concatenate((angles, [angles[0]]))
ax.plot(angles, y[0], 'b-', linewidth=2)
ax.plot(angles, y[1], 'r-', linewidth=2)
ax.plot(angles, y[2], 'g-', linewidth=2)
ax.plot(angles, y[3], 'y-', linewidth=2)
ax.plot(angles, y[4], 'm-', linewidth=2)
plt.rcParams['font.sans-serif']=['SimHei']
ax.legend(r3,loc=1)
ax.set_thetagrids(angles * 180/np.i, labels, fontproperties="SimHei")
ax.set_title("Customer_loan", va='bottom', fontproperties="SimHei")
ax.grid(True)
plt.show()
综合分析
根据2次结果综合考虑,将5类客户打上标签,划分价值群。
预测建模
二分类问题考虑逻辑回归与随机森林进行训练。
交叉验证
from sklearn import cross_validation
X = data1
Y1 = X['y']
X1 = X.drop(['y'],axis = 1)
X1_train, X1_test, y1_train, y1_test = \
cross_validation.train_test_split( X1, Y1, test_size=0.3, random_state=0)
设置early stop round 提前停止迭代参数,防止过拟合,其他参数采用随机搜索寻优。
def LR(X_train, X_test, y_train, y_test):
from sklearn.linear_model import LogisticRegression
lor = LogisticRegression(penalty='l1',C=100,multi_class='ovr')
lor.fit(X_train, y_train)
predicted= lor.predict(X_test)
score = accuracy_score(y_test, predicted)
return (score)
def RF(X_train, X_test, y_train, y_test):
from sklearn.ensemble import RandomForestClassifier
model= RandomForestClassifier(n_estimators=100)
model.fit(X_train, y_train)
predicted= model.predict(X_test)
score = accuracy_score(y_test, predicted)
return (score)