中文词向量:word2vec之skip-gram实现(不使用框架实现词向量模型)
代码中使用的中文语料,停用词语料,之后的英文语料:
链接:https://pan.baidu.com/s/1XshI0_zRu9NzBSiGXi8U7A
提取码:csg6
介绍
在自然语言处理任务中,首先需要考虑词如何在计算机中表示。通常,有两种表示方式:one-hot representation和distribution representation。
1. 离散表示(one-hot representation)
2. 分布式表示(distribution representation)
两者区别和关于NLP的基础可以参考其他博客和论文
论文:
1.A neural probabilistic language model
2.Efficient Estimation of Word Representations in Vector Space
3.Recurrent neural network based language model
博客:
1.图解Word2vec,读这一篇就够了 重点推荐
2.什么是词向量?(NPL入门)_mawenqi0729的博客-CSDN博客_词向量
3.[NLP] 秒懂词向量Word2vec的本质 - 知乎
4.【word2vec】算法原理 公式推导_夏目的博客-CSDN博客_word2vec公式


使用word2vec模型学习的单词的向量表示已经被证明能够携带语义信息,且在各种NLP任务中都是有用的。
本文实现的是skip-gram模型

代码实现
1.项目结构

2. 项目内容
skip_gram_en是训练英文词向量的,skip_gram_zh是训练中文词向量的。
enDemoTest和zhDemoTest分别是英文语料和中文语料。由于我的模型太过基础且没有计算优化
所以导致需要非常大的计算量。出现内存爆炸现象。所以这两个语料是我从en.txt和zh.txt随便截取的。这两个很大,我机器算不动。

可以随便找语料,然后在代码里修改参数就行。
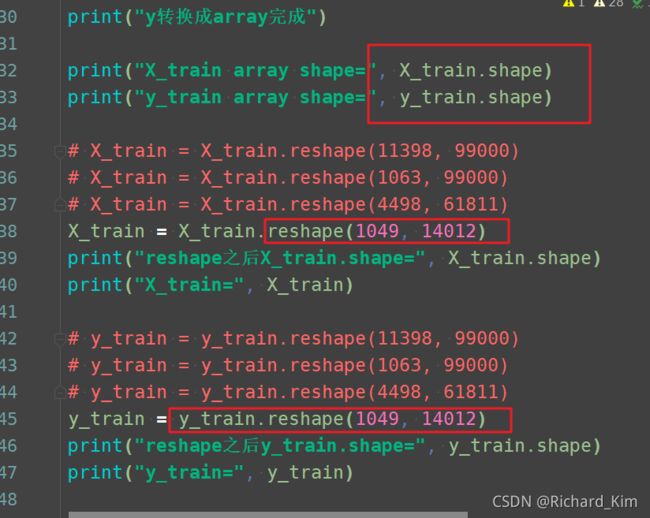
根据前面的输出结果,把红框里的数据改一下就行。
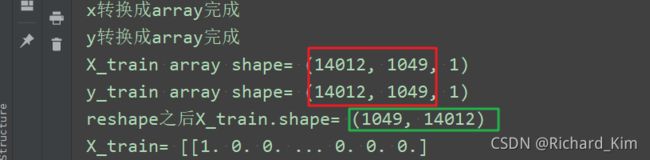
这样就不会报错了。最后转为词向量的结果保存在文件中。再用图片显示出来。
所需要的依赖要有numpy,结巴分词,sklearn,matplotlib
完整代码
#!/usr/bin/env python
# -#-coding:utf-8 -*-
# author:by ucas iie 魏兴源
# datetime:2021/10/21 13:04:43
# software:PyCharm
"""
1.下载数据or找个实验数据,进行数据预处理,
①对于中文可能有乱码问题,都使用utf-8加载
②matplotlib中文变成方框问题,使用下面代码解决
# 用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号,否则负号会显示成方块
plt.rcParams['axes.unicode_minus'] = False
2.将原词汇数据转换为字典映射,求三大参数,即word2index,index2word,word2one-hot
3.为 skip-gram模型 建立一个扫描器
4.建立并训练 skip-gram 模型
5.开始训练模型
6.结果可视化
"""
import numpy as np
import jieba
from matplotlib import pyplot as plt
from sklearn.decomposition import PCA
from tqdm import trange
from tqdm import tqdm
# 加载停用词词表
def load_stop_words():
"""
停用词是指在信息检索中,
为节省存储空间和提高搜索效率,
在处理自然语言数据(或文本)之前或之后
会自动过滤掉某些字或词
"""
with open('data/stopwords.txt', "r", encoding="utf-8") as f:
return f.read().split("\n")
# 加载文本,切词
def cut_words():
stop_words = load_stop_words()
with open('data/zhDemoTest.txt', encoding='utf8') as f:
allData = f.readlines()
result = []
for words in allData:
c_words = jieba.lcut(words)
result.append([word for word in c_words if word not in stop_words])
return result
# 用一个集合存储所有的词
wordList = []
# 获得word2index
word_2_index = {}
data = cut_words()
count = 0
for words in data:
for word in words:
if word not in word_2_index.keys():
word_2_index[word] = count
count += 1
wordList.append(word)
index_2_word = {}
# 获得 index2word
for word in word_2_index.keys():
index_2_word[word_2_index[word]] = word
print("word2index len= ", len(word_2_index))
print("word2index= ", word_2_index)
print("index2word len= ", len(index_2_word))
print("index2word=", index_2_word)
print("word len={},wordLsit={}".format(len(wordList), wordList))
# 传入一个词,获得其对应的one-hot向量
def getOneHotWordVec(input_word, word2Index):
"""
:param input_word: 输入的一个词,比如输入一个“政界”
:param word2Index: 字面意思
:return: 返回输入词所对应的ont-hot向量
"""
oneHot = np.zeros(shape=(len(word2Index), 1))
oneHot[word2Index[input_word]] = 1
return oneHot
# word = '目前'
# print(repr(word) + "的onehot=", getOneHotWordVec(word, word_2_index))
# 返回一个词表
def getWindows(input_word_list, window_size):
"""
:param input_word_list: 所有词的集合
:param window_size: 窗口大小表示,当前词与其他词距离为size的词
比如
words = [
'目前', '粮食', '出现', '阶段性',
'过剩', '恰好', '换', '森林', '草地',
'再造', '西部', '秀美', '山川', '\n'
]
令window_size = 3
则会返回Dataset= [('目前', '粮食'), ('目前', '出现'),
('目前', '阶段性'), ('粮食', '目前'), ('粮食', '出现'),
('粮食', '阶段性'), ('粮食', '过剩'), ('出现', '目前'),
('出现', '粮食'), ('出现', '阶段性'), ('出现', '过剩'),
('出现', '恰好'), ('阶段性', '目前'), ('阶段性', '粮食'),
('阶段性', '出现'), ('阶段性', '过剩'), ('阶段性', '恰好'),
('阶段性', '换'), ('过剩', '粮食'), ('过剩', '出现'),
('过剩', '阶段性'), ('过剩', '恰好'), ('过剩', '换'),
('过剩', '森林'), ('恰好', '出现'), ('恰好', '阶段性'),
('恰好', '过剩'), ('恰好', '换'), ('恰好', '森林'),
('恰好', '草地'), ('换', '阶段性'), ('换', '过剩'),
('换', '恰好'), ('换', '森林'), ('换', '草地'),
('换', '再造'), ('森林', '过剩'), ('森林', '恰好'),
('森林', '换'), ('森林', '草地'), ('森林', '再造'),
('森林', '西部'), ('草地', '恰好'), ('草地', '换'),
('草地', '森林'), ('草地', '再造'), ('草地', '西部'),
('草地', '秀美'), ('再造', '换'), ('再造', '森林'),
('再造', '草地'), ('再造', '西部'), ('再造', '秀美'),
('再造', '山川'), ('西部', '森林'), ('西部', '草地'),
('西部', '再造'), ('西部', '秀美'), ('西部', '山川'),
('西部', '\n'), ('秀美', '草地'), ('秀美', '再造'),
('秀美', '西部'), ('秀美', '山川'), ('秀美', '\n'),
('山川', '再造'), ('山川', '西部'), ('山川', '秀美'),
('山川', '\n'), ('\n', '西部'), ('\n', '秀美'),
('\n', '山川')
]
这个距离不是远大越好,也不是越小越好,越大的话包括的范围太小了,
可能没有什么关联的词也都一起训练。范围太小的话可能导致中心词与
其他词的联系不足
:return: 词表集合
"""
Dataset = []
# 获取
length = len(input_word_list)
for i in range(length):
# 取前后n个单词
for j in range(i - window_size, i + window_size + 1, 1):
# print("j=", j)
if j < 0 or j > (length - 1) or j == i:
continue
Dataset.append((input_word_list[i], input_word_list[j]))
return Dataset
# 生成训练集
def getTrain(input_word_list, window_size, word2index):
"""
:param input_word_list: 所有词的集合,一维数组,里面存着所有词,和上面的wordList一样
:param window_size: 与中心词相关联的几个词,比如"北京"这个词,他们的前window_size个词都是相关联的
:param word2index: 词与索引的字典
:return:返回训练集合x,y
"""
X_train, y_train = [], []
Dataset = getWindows(input_word_list, window_size)
# print("Dataset=", Dataset)
batch_size = 100
for i in trange(1, 100000, batch_size):
# 每个中心词和上下文词都在当前窗口内
for centre_word, context_word in Dataset[i: i + batch_size - 1]:
# 拿到x的one-hot向量
X_train.append(getOneHotWordVec(centre_word, word2index))
y_train.append(getOneHotWordVec(context_word, word2index))
# print("X_train", X_train)
# print("y_train", y_train)
return X_train, y_train
X_train, y_train = getTrain(wordList, 3, word_2_index)
print("X_train len=", len(X_train))
print("y_train len=", len(y_train))
X_train = np.array(X_train)
print("x转换成array完成")
y_train = np.array(y_train)
print("y转换成array完成")
print("X_train array shape=", X_train.shape)
print("y_train array shape=", y_train.shape)
X_train = X_train.reshape(6392, 37956)
print("reshape之后X_train.shape=", X_train.shape)
y_train = y_train.reshape(6392, 37956)
print("reshape之后y_train.shape=", y_train.shape)
print("X_train=", X_train)
print("y_train=", y_train)
# 初始化权重矩阵,有个两个矩阵,分别是VxD 和 DxV,为什么这么定义,参考论文的原理
def weightInit(dimension, pDimension):
# 第一层矩阵初始化
W1 = np.random.randn(pDimension, dimension)
# 第一层偏置初始化
b1 = np.random.randn(pDimension, 1)
# 第二层矩阵初始化,维度和是第一个矩阵的转置
W2 = np.random.randn(dimension, pDimension)
# 第二层偏置初始化
b2 = np.random.randn(dimension, 1)
return W1, b1, W2, b2
# relu激活函数
def relu(z):
return np.maximum(0, z)
# softmax函数
def softmax(z):
ex = np.exp(z)
return ex / np.sum(ex, axis=0)
# 前向传播
def forward(x, W1, b1, W2, b2):
# 第一层前向传播即 权重与输入的x的乘积加上偏置
Z1 = np.dot(W1, x) + b1
# 添加一个rule函数
Z1 = relu(Z1)
# 第二层前向传播即 上一层的输出作为当前层的输入与当前权重的乘积,再加上第二层的偏置值
Z2 = np.dot(W2, Z1) + b2
# 将第二层的输出值经过softmax函数,得到概率值
ypred = softmax(Z2)
return Z1, Z2, ypred
# 误差计算
def errorCalculation(y, ypred, m):
error = -(np.sum(np.multiply(y, np.log(ypred)))) / m
return error
# 反向传播
def backProp(W1, b1, W2, b2, Z1, Z2, y, ypred, x):
dW1 = np.dot(relu(np.dot(W2.T, ypred - y)), x.T)
db1 = relu(np.dot(W2.T, ypred - y))
dW2 = np.dot(ypred - y, Z1.T)
db2 = ypred - y
return dW1, db1, dW2, db2
# 模型训练
def model(x, y, epoches=10, learning_rate=0.00001):
# x的行列数
dimension = x.shape[0]
m = x.shape[1]
# 生成词向量维度,300表示生成的词向量用300行数字表示这个词
pDimension = 300
W1, b1, W2, b2 = weightInit(dimension, pDimension)
error = []
for i in tqdm(range(epoches)):
Z1, Z2, ypred = forward(x, W1, b1, W2, b2)
error.append(errorCalculation(y, ypred, m))
dW1, db1, dW2, db2 = backProp(W1, b1, W2, b2, Z1, Z2, y, ypred, x)
# 更新权重和偏置
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
print("error=", error)
return ypred, error, W1, W2
# 传入训练集和epoch次数,以及学习率
ypred, error, W1, W2 = model(X_train, y_train, 10, 0.00001)
W = np.add(W1, W2.T) / 2
print("W=", W)
# 生成词嵌入字典,即{单词1:词向量1,单词2:词向量2...}的格式
word_2_vec = {}
for word in word_2_index.keys():
# 词向量矩阵中某个词的索引所对应的那一列即为所该词的词向量
word_2_vec[word] = W[:, word_2_index[word]]
print("word2vec=", word_2_vec)
pca = PCA(n_components=2)
principalComponents = pca.fit_transform(W.T)
# 降维后在生成一个词嵌入字典,即即{单词1:(维度一,维度二),单词2:(维度一,维度二)...}的格式
word2ReduceDimensionVec = {}
for word in word_2_index.keys():
word2ReduceDimensionVec[word] = principalComponents[word_2_index[word], :]
# 将生成的字典写入到文件中,字符集要设定utf8,不然中文乱码
with open("zh_vector.txt", 'w', encoding='utf-8') as f:
for key in word_2_index.keys():
f.write('\n')
f.writelines('"' + str(key) + '":' + str(word_2_vec[key]))
f.write('\n')
# 将词向量可视化
plt.figure(figsize=(20, 20))
# 只画出1000个,太多显示效果很差
count = 0
for word, wordvec in word2ReduceDimensionVec.items():
if count < 1000:
plt.scatter(wordvec[0], wordvec[1])
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号,否则负号会显示成方块
plt.annotate(word, (wordvec[0], wordvec[1]))
count += 1
plt.show()
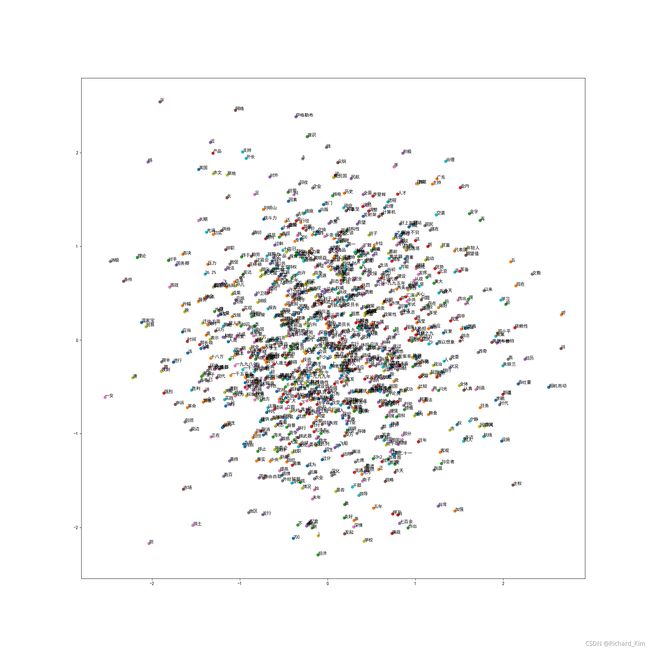
最后的画图结果:
输出的文件:
