Yolov5
摘要
Yolov5是一个基于pytorch的在在COCO数据集上进行预训练的目标检测体系结构和模型,是目前一个比较常用的目标检测模型,在现在很多实际项目中,有很好的效果,实用性较强,有模型尺寸小、部署成本低、灵活度高和检测速度快的特点。
网络结构
Focus:首先将多个slice结果Concat起来,然后将其送入CBL模块中(6.0版本以后替换成6×6卷积层)。
CSP1_X:借鉴CSPNet网络结构,该模块由CBL模块、Res unint模块以及卷积层、Concate组成。
CSP2_X:借鉴CSPNet网络结构,该模块由卷积层和X个Res unint模块Concate组成而成。
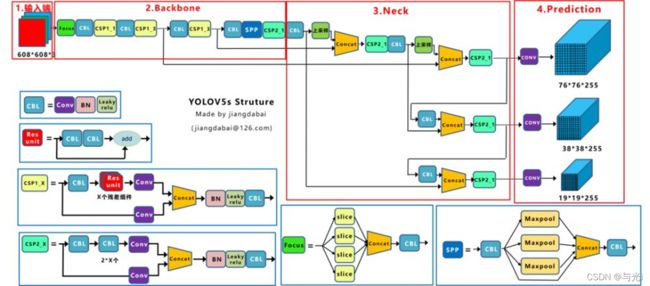
图1
创新点
输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放。
Backbone:Focus结构,CSP结构。
Neck:FPN+PAN结构。
Prediction:GIOU_Loss。
Mosaic数据增强
主要是将数据通过随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果较好。
自适应锚框计算
针对不同的数据集,都会有初始设定长宽的锚框。
在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
Yolov5中将此功能嵌入到代码中,每次训练时,自适应的计算不同训练集中的最佳锚框值。
自适应图片缩放
Yolo算法中常用416416,608608等尺寸。
缩放填充后,两端的黑边大小都不同,如果填充的比较多,则存在信息冗余,影响推理速度。yolov5对原始图像自适应的添加最少的黑边。图像高度上两端的黑边变少了,在推理时,计算量也会减少,即目标检测速度会得到提升。
注意只在检测时使用,在训练时仍使用传统填充方法。

图2
Focus
以Yolov5s的结构为例,原始6086083的图像输入Focus结构,采用切片操作,先变成30430412的特征图,再经过一次32个卷积核的卷积操作,最终变成30430432的特征图。
但是在6.1版本,这里被替换成了卷积核为6*6的卷积层,效果是一样的,但是可以适配更高版本的pytorch和cpu,提高计算速度。
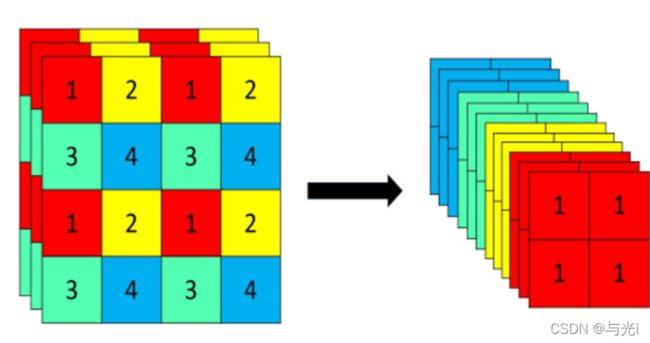
图3
两种CSP
以Yolov5s网络为例,CSP1_X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
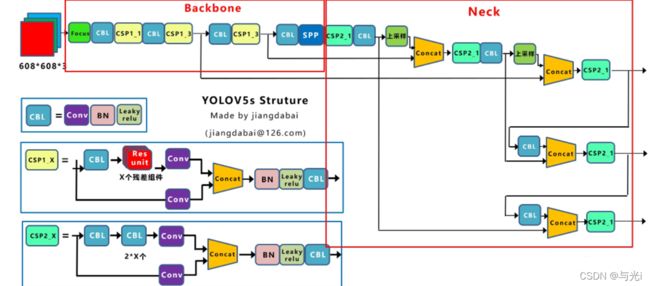
图4
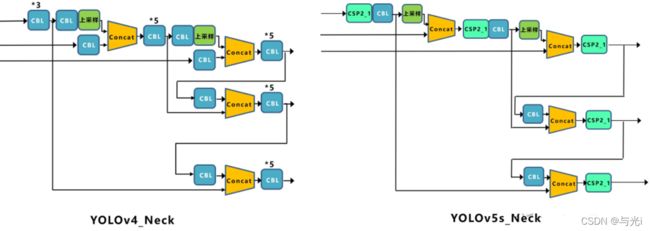
Neck
FPN+PAN的结构。
采用借鉴CSPnet设计的CSP2结构,加强网络特征融合的能力。
消除Grid敏感度
当真实目标中心点非常靠近网格的左上角点( σ ( t x ) \sigma(t_x ) σ(tx)和 σ ( t y ) \sigma(t_y ) σ(ty)应该趋近与0)或者右下角点( σ ( t x ) \sigma(t_x ) σ(tx)和 σ ( t y ) \sigma(t_y ) σ(ty)应该趋近与1)时,网络的预测值需要负无穷或者正无穷时才能取到,而这种很极端的值网络一般无法达到。
对偏移量进行了缩放从原来的(0,1)缩放到(−0.5,1.5)这样网络预测的偏移量就能很方便达到0或1。
公式:
b x = ( 2 ⋅ σ ( t x ) − 0.5 ) = c x b_x=(2\cdot \sigma(t_x)-0.5)=c_x bx=(2⋅σ(tx)−0.5)=cx
b y = ( 2 ⋅ σ ( t y ) − 0.5 ) = c y b_y=(2\cdot \sigma(t_y)-0.5)=c_y by=(2⋅σ(ty)−0.5)=cy
b w = p w ⋅ ( 2 ⋅ σ ( t w ) ) 2 b_w=p_w\cdot(2\cdot\sigma(t_w))^2 bw=pw⋅(2⋅σ(tw))2
b h = p h ⋅ ( 2 ⋅ σ ( t h ) ) 2 b_h=p_h\cdot(2\cdot\sigma(t_h))^2 bh=ph⋅(2⋅σ(th))2
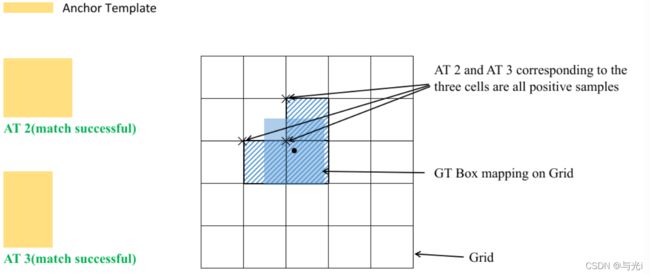
正负样本的匹配
先去计算每个GT Box与对应的Anchor Templates模板的高宽比例,即:
r w = w g t / w a t r_w = w_{gt} / w_{at} rw=wgt/wat
r h = h g t / h a t r_h = h_{gt} / h_{at} rh=hgt/hat
然后统计这些比例和它们倒数之间的最大值,这里可以理解成计算GT Box和Anchor Templates分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小):
r w m a x = m a x ( r w , 1 / r w ) r_w^{max} = max(r_w, 1 / r_w) rwmax=max(rw,1/rw)
r h m a x = m a x ( r h , 1 / r h ) r_h^{max} = max(r_h, 1 / r_h) rhmax=max(rh,1/rh)
接着统计 r w m a x r_w^{max} rwmax和 r h m a x r_h^{max} rhmax之间的最大值,即宽度和高度方向差异最大的值:
r m a x = m a x ( r w m a x , r h m a x ) r^{max} = max(r_w^{max}, r_h^{max}) rmax=max(rwmax,rhmax)
如果GT Box和对应的Anchor Template的 r m a x r^{max} rmax小于阈值anchor_t(在源码中默认设置为4.0),即GT Box和对应的Anchor Template的高、宽比例相差不算太大,则将GT Box分配给该Anchor Template模板。假设对某个GT Box而言,其实只要GT Box满足在某个Anchor Template宽和高的0.25×0.25倍和4.0×4.0倍之间就算匹配成功。

其余步骤和YOLOv4中一致:
将GT投影到对应预测特征层上,根据GT的中心点定位到对应Cell,注意图中有三个对应的Cell。因为网络预测中心点的偏移范围已经调整到了( − 0.5 , 1.5 ) (-0.5, 1.5)(−0.5,1.5),所以按理说只要Grid Cell左上角点距离GT中心点在( − 0.5 , 1.5 ) (−0.5,1.5)(−0.5,1.5)范围内它们对应的Anchor都能回归到GT的位置处。这样会让正样本的数量得到大量的扩充。
则这三个Cell对应的AT2和AT3都为正样本。