目标检测实战篇1——数据集介绍(PASCAL VOC,MS COCO)
前言
前面我们讲过了目标检测的YOLO系列算法,SSD算法。从这个博文开始,我们要真实开启实战篇章。在正式介绍实战篇之前,我们需要先知道两个数据集:PASCAL VOC和COCO数据集。
一.PASCAL VOC数据集介绍

PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛,PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。PASCAL VOC挑战赛主要包括以下几类:图像分类Object Classification),目标检测(Object Detection),目标分割(Object Segmentation),行为识别(Action Classification) 等。
官方地址:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
目标检测示例:
分割:语义分割,实例分割,全景分割。
语义分割是所有物体分割出来,用相同颜色标注,实例分割是不同物体用不同颜色标注出来,全景分割是把背景也分割出来,实例分割的升级。
示例:

行为识别示例:

人体部位检测示例:

1.1怎么下载数据集
点击之后即可下载训练集和验证集。
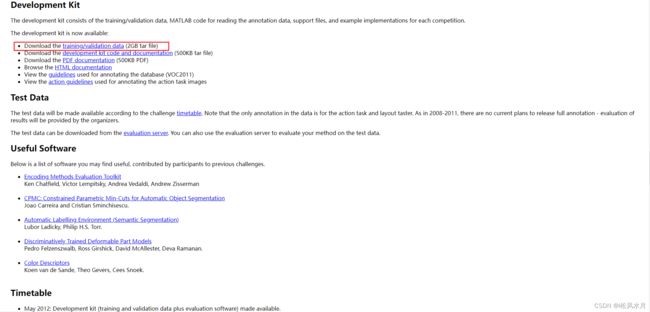
下载完之后我们可以发现Pascal VOC数据集包含20个类别,如下图。

下面我们再看下文件结构,针对目标检测,我们只需要关注Annotation,JPEGImage,和Main文件夹,Main文件下面主要关注三个文件,分别为训练集,验证集,训练集+验证集。
VOCdevkit
└── VOC2012
├── Annotations 所有的图像标注信息(XML文件)
├── ImageSets
│ ├── Action 人的行为动作图像信息
│ ├── Layout 人的各个部位图像信息
│ │
│ ├── Main 目标检测分类图像信息
│ │ ├── train.txt 训练集(5717)
│ │ ├── val.txt 验证集(5823)
│ │ └── trainval.txt 训练集+验证集(11540)
│ │
│ └── Segmentation 目标分割图像信息
│ ├── train.txt 训练集(1464)
│ ├── val.txt 验证集(1449)
│ └── trainval.txt 训练集+验证集(2913)
│
├── JPEGImages 所有图像文件
├── SegmentationClass 语义分割png图(基于类别)
└── SegmentationObject 实例分割png图(基于目标)
打开文件看下,VOC2012下面总共有5个文件夹。
Annotations为标注的信息,每个图像对应一个xml文件。
我们随便点开一个看下,里面都是什么样的。

下面再看下JPEGImages文件,可以看到里面放的都是图像。
再看下Imagesets,针对目标检测,主要关注的是Main文件下面的train.txt和val.txt以及trainval.txt文件。
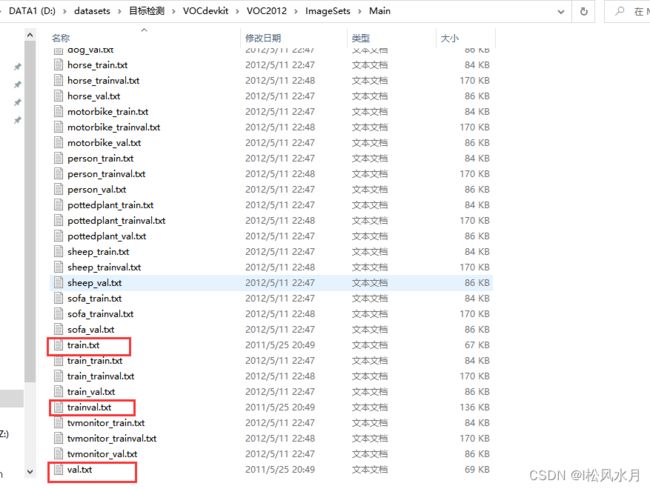
打开train.txt文件看下,里面每一行都是存放的图像的名称,需要注意的是train.txt和val.txt文件里面的文件名是互斥的。trainval.txt是将train和val.txt融合和的文件,因为在比赛的额时候需要用trainval.txt进行训练,测试的时候根据pascall voc官网提供的测试文件进行测试,2012年的测试文件是不公开的,2007的公开了。
这里你应该有个疑问,除了train.txt,val.txt,trainval.txt这三个文件,其他的文件都是干嘛的,并且都是三个文件,可以看下应该总共20个类别,每个类别都有三个文件。比如aeroplane_train.txt,aeroplane_val.txt,aeroplane_trainval.txt三个文件?我们随便打开一个看看

现在文件和标注信息都有了,那么我们应该怎么利用这些文件去载入这些图像信息呢?
一般是如下的步骤:
比如训练阶段,首先是读取Main下面的train.txt文件,获取每行信息,然后去Annotations文件夹下面去找对应的xml文件,去解析读取的文件,获取文件的高度,宽度,位置等信息,然后去JPEGImages下面去找到相应的图片,载入内存。
上面讲的是PASCAL voc已经标注好的文件,但是在实际使用的时候,含有标注信息的图像往往是没有的,这时候就需要我们自己标注图像,下面我们来介绍下怎么标注自己的目标检测数据集。网上有很多的目标目标检测工具如labelme,labelImg等,这里介绍下labelImg的用法,传送门labelImg可以生成xml文件,保持和pascal voc一样的格式,而labelme生成的是json文件。
安装:
pip install labelImg -i https://pypi.tuna.tsinghua.edu.cn/simple
安装后怎么使用呢?
labelImg
labelImg [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
两种方法,一种直接使用labelImg启动,另一种是加上路径和标注类别文件,我们这里使用的是第二中方法。这里我们要首先准备一个关于类别的文件信息,打开labelImag之后,先更改文件保存目录,改为我们刚才创建的Annotataions文件夹。
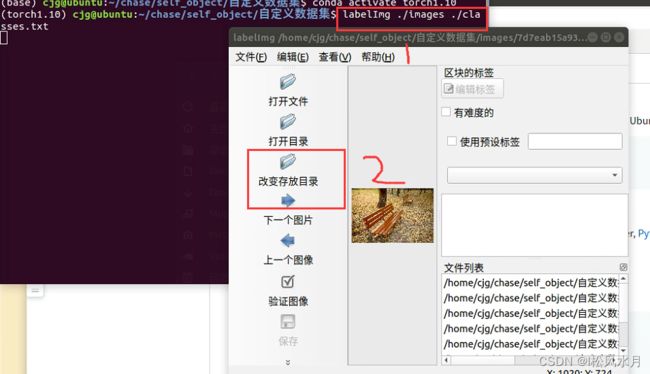
然后选中创建区块,选中图中的目标,如果觉得目标难检测,目标框好之后可以选择difficult(工具右上角),框好之后直接保存即可。
标记完之后,我们去Annotations文件夹下面看看标注信息,如下图所示。
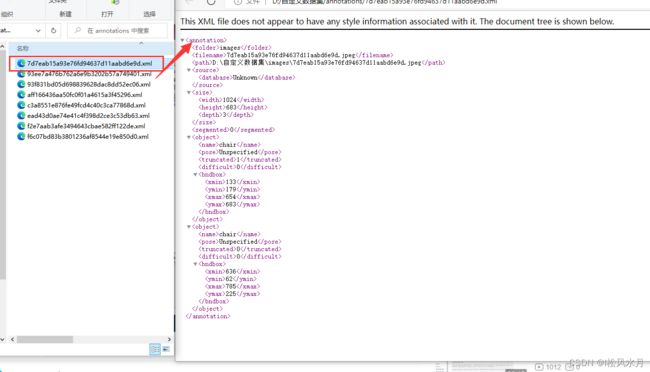
我们的图片标注号之后应该怎么去使用呢?两种方法,一种方法是把我们标注好的文件完全按照pascal voc的文件目录格式摆放,train.txt和val.txt,trainval.txt文件需要我们自己遍历文件目录生成。另一种方法是在代码中修改读取文件的路径也可以。
二.MS COCO数据集介绍

官网地址:https://cocodataset.org/
MS COCO是一个非常大的常用的目标阿检测数据库,包含了分割,检测,图像描述等任务所包含的数据集。
Object segmentation: 目标级分割Recognition in context: 图像情景识别Superpixel stuff segmentation: 超像素分割330K images (>200K labeled): 超过33万张图像,标注过的图像超过20万张1.5 million object instances: 150万个对象实例80 object categories: 80个目标类别91 stuff categories: 91个物品类别5 captions per image: 每张图像有5段情景描述250,000 people with keypoints: 对25万个人进行了关键点标注
上面的80个目标类别和91个物品类别是什么意思?stuff中包含没有明确边界的物品和对象,如天空,海洋都没有明确的边界。他们两个有什么区别?简单理解就是80是91的子类,如果我们仅仅做目标检测的话用80类的就可以了。如果是做图像分割,要用到91类的,如mask rcnn。

coco数据集包含了所有的pascal类别,通常使用coco数据集作为预训练网络。进入MS COCO官网可以直接下载需要的数据集。

对于目标检测,我们需要下载下面的三个数据集。训练数据集,测试数据集,和对应的标注文件。如果是想训练91个类别的,可以下载2017 Stuff Trian/Val annotations这个标注文件。
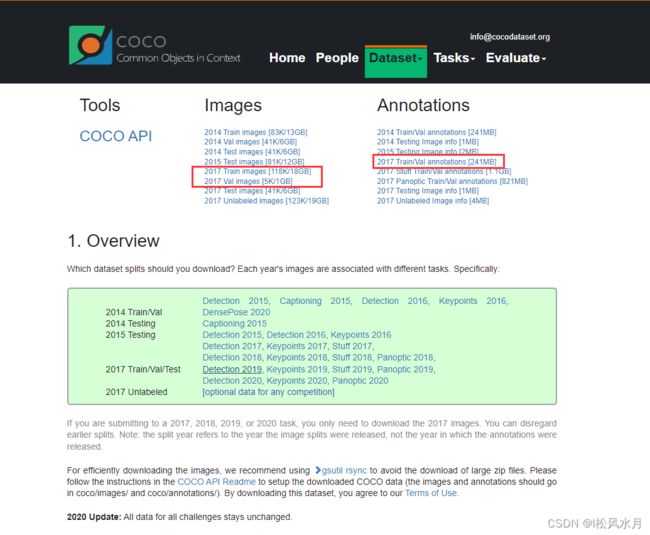
将下载好的文件解压到coco2017文件夹下面,我们只会使用到其中的四个文件,train2017,val2017,instances_train2017.json和instances_val2017.json四个文件。
├── coco2017: 数据集根目录
├── train2017: 所有训练图像文件夹(118287张)
├── val2017: 所有验证图像文件夹(5000张)
└── annotations: 对应标注文件夹
├── instances_train2017.json: 对应目标检测、分割任务的训练集标注文件
├── instances_val2017.json: 对应目标检测、分割任务的验证集标注文件
├── captions_train2017.json: 对应图像描述的训练集标注文件
├── captions_val2017.json: 对应图像描述的验证集标注文件
├── person_keypoints_train2017.json: 对应人体关键点检测的训练集标注文件
└── person_keypoints_val2017.json: 对应人体关键点检测的验证集标注文件夹
注意:如果是针对目标检测80类的话,有些图像的标注信息是空的或者是有问题的,所以在训练的时候我们需要对这些数据进行筛选,否则可能会在训练网络的时候出现目标边界框回归损失为nan的情况。上面的annotations下面总共包含6个文件,我们只需要关注其中的2个文件即可,instances_train2017.json和instances_val2017.json。instances_train2017.json对应train2017文件夹下面的所有图片的目标边界框和图像分割的标注文件,instances_val2017.json对应val2017文件夹下面的所以图片的目标边界框和图像分割的标注文件。我们来看下json文件的每个目标的json格式。官网也有给出介绍:传送门。下面我们通过pycharm来看下。
import json
# 改成你自己的路径
json_path = "D:\\迅雷下载\\annotations_trainval2017\\annotations\\instances_val2017.json"
json_labels = json.load(open(json_path, "r"))
print(json_labels["info"])
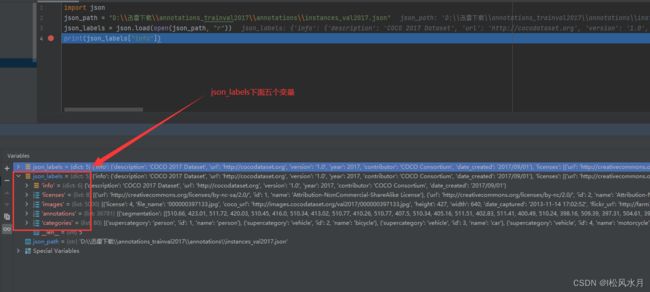
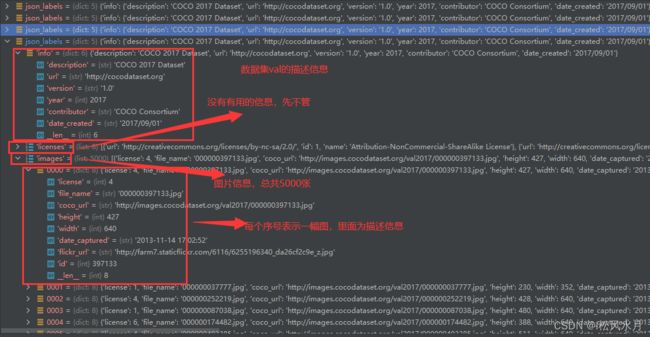
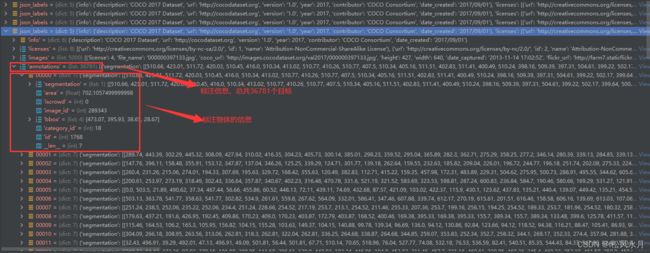
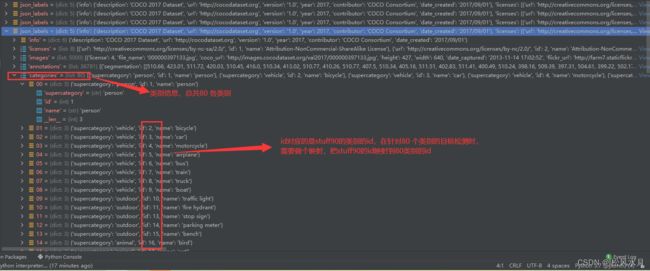
上面介绍了json标注文件的格式,下面我们再来讲下怎么读取标注文件。这里我们要使用到一个工具,pycoctools工具包。
安装方法依旧很简单
linux:
pip install pycocotools
windows
pip install pycocotools-windows
代码:
import os
from pycocotools.coco import COCO
from PIL import Image, ImageDraw
import matplotlib.pyplot as plt
json_path = "D:\\迅雷下载\\annotations_trainval2017\\annotations\\instances_val2017.json"
img_path = "D:\\迅雷下载\\val2017"
# 通过COCO载入标签文件,这里以验证集为例
coco = COCO(annotation_file=json_path)
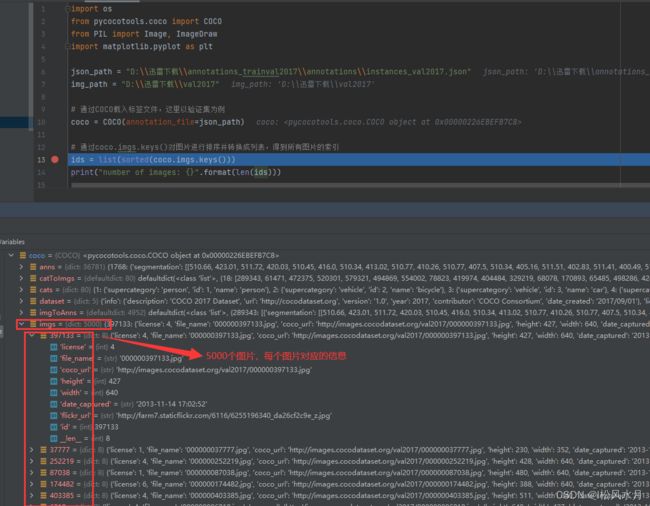
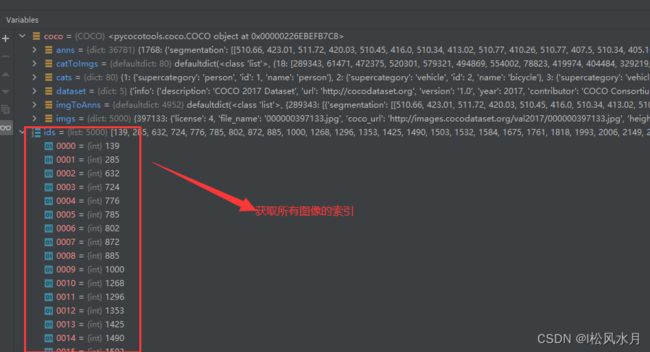
# 通过coco.imgs.keys()对图片进行排序并转换成列表,得到所有图片的索引
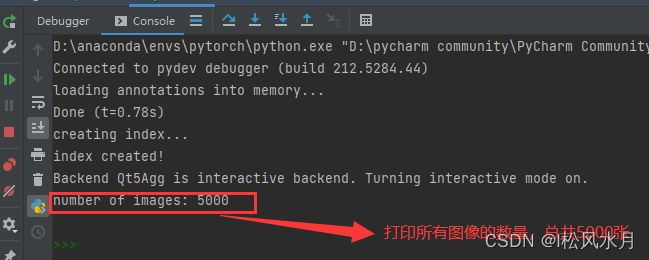
ids = list(sorted(coco.imgs.keys()))
print("number of images: {}".format(len(ids)))
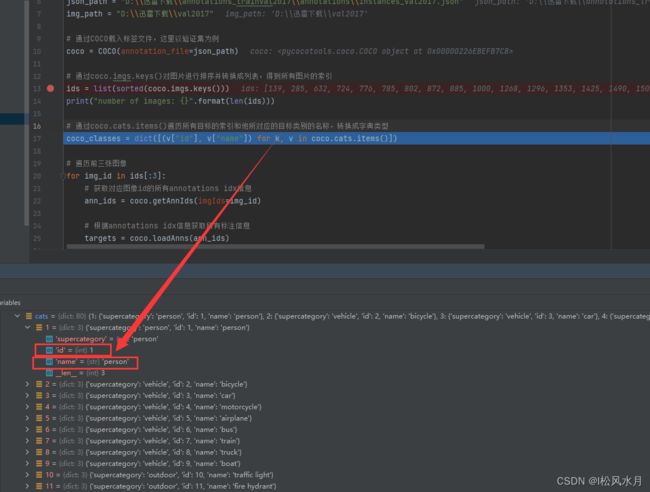
# 通过coco.cats.items()遍历所有目标的索引和他所对应的目标类别的名称,转换成字典类型
coco_classes = dict([(v["id"], v["name"]) for k, v in coco.cats.items()])
# 遍历前5张图像,绘制图片的标注信息
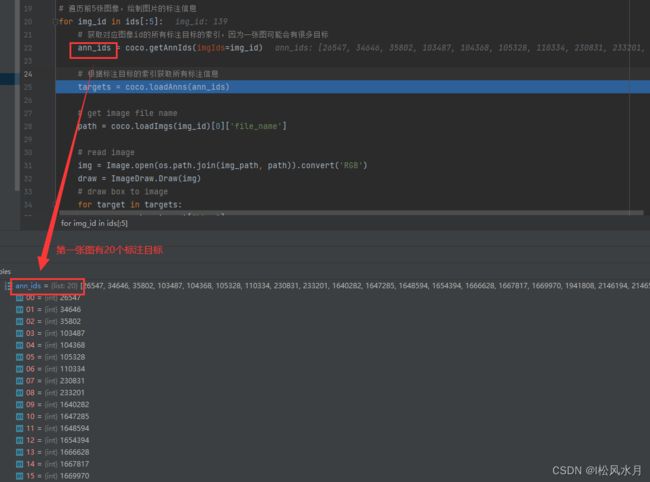
for img_id in ids[:5]:
# 获取对应图像id的所有标注目标的索引,因为一张图可能会有很多目标
ann_ids = coco.getAnnIds(imgIds=img_id)
# 根据标注目标的索引获取所有标注信息
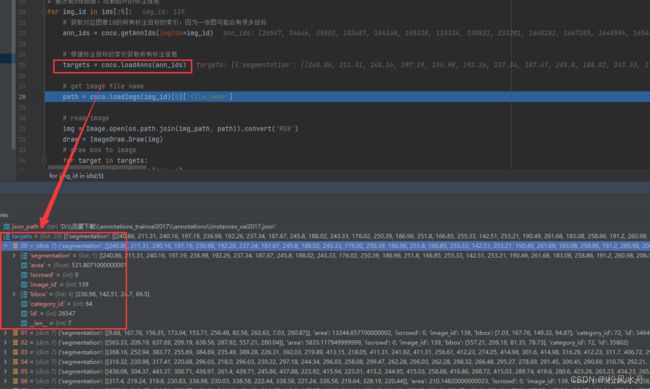
targets = coco.loadAnns(ann_ids)
# 获取图片的名称
path = coco.loadImgs(img_id)[0]['file_name']
# 读取图片
img = Image.open(os.path.join(img_path, path)).convert('RGB')
draw = ImageDraw.Draw(img)
# 对每张图片遍历每个目标绘制bbox信息
for target in targets:
x, y, w, h = target["bbox"]
x1, y1, x2, y2 = x, y, int(x + w), int(y + h)
draw.rectangle((x1, y1, x2, y2))
draw.text((x1, y1), coco_classes[target["category_id"]])
# show image
plt.imshow(img)
plt.show()

结果展示:
上面介绍了怎么是使用标注文件,下面我们再来介绍下目标检测中的mAP怎么验证。官网对此也有介绍,传送门。
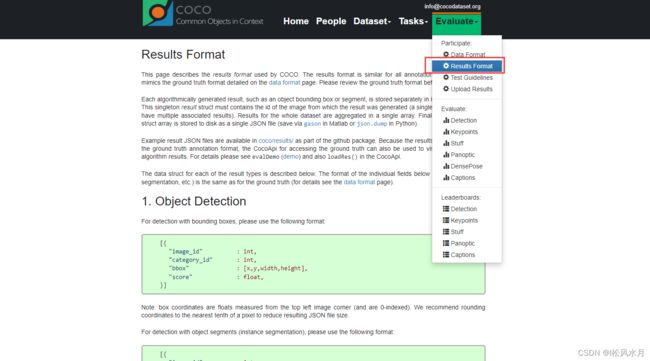
每种任务都有给定的格式要求,对于目标检测,我们最终预测的结果需要保存成如下的数据格式写入json文件:
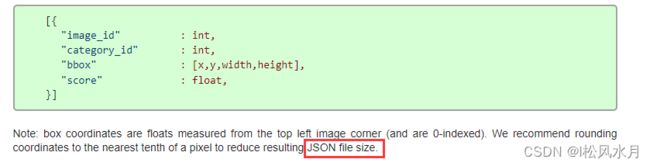
从上面的格式可以看到他是一个list列表的形式,每个元素是个字典,对应检测到的目标,如上面展示的是包含四个信息的目标,注意上面的category_id对应的是stuff91的目标类别,score表示预测目标的概率。
image_id记录该目标所属图像的id(int类型)category_id记录预测该目标的类别索引,注意这里索引是对应stuff中91个类别的索引信息(int类型)bbox记录预测该目标的边界框信息,注意对应目标的[xmin, ymin, width, height] (list[float]类型)score记录预测该目标的概率(float类型)
将预测结果保存成json文件
以一个预测结果为例:将每个预测结果都写成字典形式,将他们的结果放入列表再写成json文件。
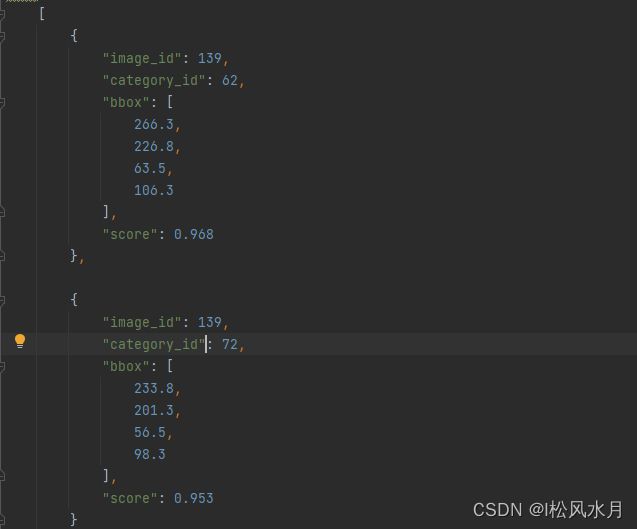
写成json文件
import json
results = [] # 所有预测的结果都保存在该list中
# write predict results into json file
json_str = json.dumps(results, indent=4)
with open('predict_results.json', 'w') as json_file:
json_file.write(json_str)
跟coco2017里面写好的验证集json文件进行对比来计算mAP
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
# accumulate predictions from all images
# 载入coco2017验证集标注文件
coco_true = COCO(annotation_file="/data/coco2017/annotations/instances_val2017.json")
# 载入网络在coco2017验证集上预测的结果
coco_pre = coco_true.loadRes('predict_results.json')
coco_evaluator = COCOeval(cocoGt=coco_true, cocoDt=coco_pre, iouType="bbox")
coco_evaluator.evaluate()
coco_evaluator.accumulate()
coco_evaluator.summarize()
关于具体怎么测试,后面我们介绍代码实战的时候再详细介绍。
关于pascal voc和ms coco 数据集的介绍部分基本上讲完了,欢迎各位大佬批评指正。