【菜菜的sklearn课堂笔记】逻辑回归与评分卡-重要参数penalty & C
视频作者:菜菜TsaiTsai
链接:【技术干货】菜菜的机器学习sklearn【全85集】Python进阶_哔哩哔哩_bilibili
正则化是用来防止模型过拟合的过程,常用的有L1正则化和L2正则化两种选项。这个增加的范式,被称为“正则项”,也被称为"惩罚项"。损失函数改变,基于损失函数的最优化来求解的参数取值必然改变,我们以此来调节模型拟合的程度。
其中L1范式表现为参数向量中的每个参数的绝对值之和,L2范数表现为参数向量中的每个参数的平方和的开方值。
J ( θ ) L 1 = C ⋅ J ( θ ) + ∑ j = 1 p ∣ θ j ∣ ( j ≥ 1 ) J ( θ ) L 2 = C ⋅ J ( θ ) + ∑ j = 1 p ( θ j ) 2 ( j ≥ 1 ) \begin{aligned} J(\theta)_{L1}&=C \cdot J(\theta)+\sum\limits_{j=1}^{p}|\theta_{j}|\quad (j \geq 1)\\ J(\theta)_{L2}&=C \cdot J(\theta)+\sqrt{\sum\limits_{j=1}^{p}(\theta_{j})^{2}}\quad (j \geq 1) \end{aligned} J(θ)L1J(θ)L2=C⋅J(θ)+j=1∑p∣θj∣(j≥1)=C⋅J(θ)+j=1∑p(θj)2(j≥1)
其中 J ( θ ) J(\theta) J(θ)是损失函数, C C C是用来控制正则化程度的超参数, p p p是方程中特征的总数, θ j \theta_{j} θj代表每一个参数,在这里 j j j要大于等于1,因为我们参数向量 θ \theta θ中的一个参数是 θ 0 \theta_{0} θ0,而截距通常是不参与正则化的
sklearn当中,常数项C是在损失函数的前面,通过调控损失函数本身的大小,来调节对模型的惩罚。
在许多书籍和博客中,大家可能也会见到如下的写法:
J ( θ ) L 1 = J ( θ ) + 1 2 b 2 ∑ j ∣ θ j ∣ J ( θ ) L 2 = J ( θ ) + θ T θ 2 σ 2 \begin{aligned} J(\theta)_{L1}&=J(\theta)+ \frac{1}{2b^{2}}\sum\limits_{j}^{}|\theta_{j}|\\ J(\theta)_{L2}&=J(\theta)+ \frac{\theta^{T}\theta}{2\sigma^{2}} \end{aligned} J(θ)L1J(θ)L2=J(θ)+2b21j∑∣θj∣=J(θ)+2σ2θTθ
其实和上面我们展示的式子的本质是一模一样的。在大多数教材和博客中,常数项是乘以正则项,通过调控正则项来调节对模型的惩罚。
L1正则化和L2正则化虽然都可以控制过拟合,但它们的效果并不相同。当正则化强度逐渐增大(即C逐渐变小),参数 θ \theta θ的取值会逐渐变小,但L1正则化会将参数压缩为0,L2正则化只会让参数尽量小,不会取到0,也就是所说的L1正则化会产生稀疏解。
部分的正则化方法是在经验风险或者经验损失 L e m p L_{emp} Lemp(emprirical loss)上加上一个结构化风险,结构化风险用参数范数惩罚 Ω ( θ ) \Omega(\theta) Ω(θ),用来限制模型的学习能力、通过防止过拟合来提高泛化能力。
所以总的损失函数(也叫目标函数)为:
J ( θ ; X , y ) = L e m p ( θ ; X , y ) + α Ω ( θ ) J(\theta; X, y) = L_{emp}(\theta; X, y) + \alpha\Omega(\theta) J(θ;X,y)=Lemp(θ;X,y)+αΩ(θ)
其中 X X X是输入数据, y y y是标签, θ \theta θ是参数, α ∈ [ 0 , + ∞ ] \alpha \in [0,+∞] α∈[0,+∞]是用来调整参数范数惩罚与经验损失的相对贡献的超参数,当 α = 0 α=0 α=0时表示没有正则化, α α α越大对应该的正则化惩罚就越大。对于L1正则化(其中 ω \omega ω是模型的参数) 有:
Ω ( θ ) = ∣ ∣ ω ∣ ∣ 1 \Omega(\theta) = ||\omega||_{1} Ω(θ)=∣∣ω∣∣1
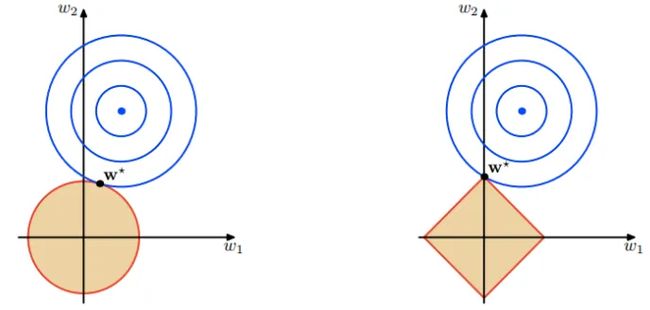
面中的蓝色轮廓线是没有正则化损失函数的等高线,中心的蓝色点为最优解,左图、右图分别为L2、L1正则化给出的限制。
可以看到在正则化的限制之下,L2正则化给出的最优解 ω ∗ \omega∗ ω∗是使解更加靠近原点,也就是说L2正则化能降低参数范数的总和。L1正则化给出的最优解 ω ∗ \omega∗ ω∗是使解更加靠近某些轴,而其它的轴则为0,所以L1正则化能使得到的参数稀疏化作者:自由星人布丁
链接:机器学习-L1正则化为什么会产生稀疏解 - 知乎 (zhihu.com)文章还有更详细的数学上的推导关于L1范数约束会得到稀疏的解
在L1正则化在逐渐加强的过程中,携带信息量小的、对模型贡献不大的特征的参数,会比携带大量信息的、对模型有巨大贡献的特征的参数更快地变成0,所以L1正则化本质是一个特征选择的过程,掌管了参数的“稀疏性”。因此,如果特征量很大,数据维度很高,我们会倾向于使用L1正则化。由于L1正则化的这个性质,逻辑回归的特征选择可以由Embedded嵌入法来完成。
相对的,L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大的特征的参数会非常接近于0。
通常来说,如果我们的主要目的只是为了防止过拟合,选择L2正则化就足够了。但是如果选择L2正则化后还是过拟合,模型在未知数据集上的效果表现很差,就可以考虑L1正则化。
而两种正则化下C的取值,都可以通过学习曲线来进行调整。
LogisticRegression(
["penalty='l2'", 'dual=False', 'tol=0.0001', 'C=1.0', 'fit_intercept=True', 'intercept_scaling=1', 'class_weight=None', 'random_state=None', "solver='warn'", 'max_iter=100', "multi_class='warn'", 'verbose=0', 'warm_start=False', 'n_jobs=None'],
)
# penalty:可以输入"l1"或"l2"来指定使用哪一种正则化方式,不填写默认"l2"。
# 注意,若选择"l1"正则化,参数solver仅能够使用求解方式”liblinear"和"saga“;若使用“l2”正则化,参数solver中所有的求解方式都可以使用。
# C:C正则化强度的倒数,必须是一个大于0的浮点数,不填写默认1.0,即默认损失函数与正则项的比值是1:1。C越小,损失函数会越小,模型对损失函数的惩罚越重,正则化的效力越强,参数θ会逐渐被压缩得越来越小。
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
data = load_breast_cancer()
X = data.data
y = data.target
X.shape
---
(569, 30)
lrl1 = LR(penalty="l1",solver="liblinear",C=0.5,max_iter=1000)
lrl2 = LR(penalty="l2",solver="liblinear",C=0.5,max_iter=1000)
lrl1 = lrl1.fit(X,y)
lrl1.coef_ # 各个特征所对应的参数
# 注意返回的是二维array
---
array([[ 3.98754228, 0.03153078, -0.13532423, -0.01620142, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , 0.50383838, 0. , -0.07126945, 0. ,
0. , 0. , 0. , 0. , 0. ,
0. , -0.24537614, -0.12838236, -0.01442535, 0. ,
0. , -2.0550076 , 0. , 0. , 0. ]])
(lrl1.coef_ != 0).sum() # l1正则化可能会把部分特征系数压缩成0
---
10
lrl2 = lrl2.fit(X,y)
lrl2.coef_
---
array([[ 1.60607308e+00, 9.80640554e-02, 5.51538489e-02,
-4.80814634e-03, -9.75651764e-02, -2.97883054e-01,
-4.58633029e-01, -2.27937385e-01, -1.40149921e-01,
……
-4.37780410e-01, -4.31445382e-01, -8.46315361e-02]])
(lrl2.coef_ != 0).sum()
---
30
可以看见,当我们选择L1正则化的时候,许多特征的参数都被设置为了0,这些特征在真正建模的时候,就不会出现在我们的模型当中了,而L2正则化则是对所有的特征都给出了参数。
究竟哪个正则化的效果更好呢
l1 = []
l2 = []
l1test = []
l2test = []
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
for i in np.linspace(0.05,2,19):
lrl1 = LR(penalty="l1",solver="liblinear",C=i,max_iter=1000) # 也有random_state
lrl2 = LR(penalty="l2",solver="liblinear",C=i,max_iter=1000)
lrl1 = lrl1.fit(Xtrain,Ytrain)
l1.append(accuracy_score(lrl1.predict(Xtrain),Ytrain))
l1test.append(accuracy_score(lrl1.predict(Xtest),Ytest))
lrl2 = lrl2.fit(Xtrain,Ytrain)
l2.append(accuracy_score(lrl2.predict(Xtrain),Ytrain))
l2test.append(accuracy_score(lrl2.predict(Xtest),Ytest))
graph = [l1,l2,l1test,l2test]
color = ['green','k','lightgreen','gray']
label = ['L1','L2','L1test','L2test']
plt.figure(figsize=(6,6))
for i in range(len(graph)):
plt.plot(np.linspace(0.05,2,19),graph[i],color[i],label=label[i])
plt.legend(loc='lower right') # 也可以写plt.legend(loc=4)
plt.xlabel('Parameter C')
plt.show()
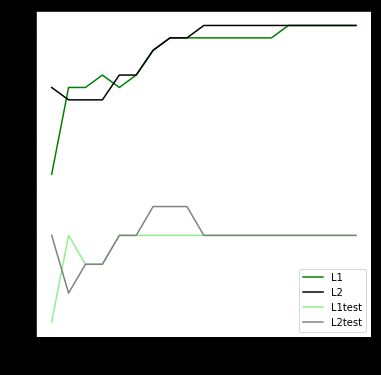
可见,至少在乳腺癌数据集下,两种正则化的结果区别不大。但随着C的逐渐变大,正则化的强度越来越小,模型在训练集和测试集上的表现都呈上升趋势,直到C=0.8左右,训练集上的表现依然在走高,但模型在未知数据集上的表现开始下跌,这时候就是出现了过拟合。我们可以认为,C设定为0.8会比较好。
在实际使用时,基本就默认使用l2正则化,如果感觉到模型的效果不好,那就换L1试试看。
这里说一下matplotlib相关的
# 在我们show之前,所有画图都在同一个画布上 # 当我们show之后,再进行画图,不会再之前的画布上 # 如果在show之后有创建新画布则用创建的画布 # 如果没有,默认创建画布(这么做不规范,画布没有任何设置,主要不好理解) plt.figure(figsize=(3,2)) # 就像本例,我们设置画布figsize=(3,2) for i in range(2): plt.plot(np.linspace(0.05,1,19),graph[i],color[i],label=label[i]) plt.legend(loc='lower right') # 也可以写plt.legend(loc=4) plt.show() # 第一次show的时候figsize=(3,2)被用掉了,新的画图就要默认用创建画布