Triton部署Torch和Onnx模型,集成数据预处理
Triton部署Torch和Onnx模型
- 1. Triton Inference Server 简介
- 2. Triton安装
-
- 2.1. 预备
- 2.2. Pull triton镜像
- 3. Triton的简单测试使用
-
- 3.1 构建一个模型目录
- 3.2 为模型库生成2个测试模型 (torch和onnx)
- 3.3 启动Triton服务
- 3.4 修改triton配置
- 3.5 triton服务重启
- 3.6 测试Triton服务
-
- 3.6.1 http测试代码
- 3.6.2 GRPC测试代码
- 3.7 7. 将数据预处理和模型预测全部集成在Triton中
- 3.6.8. 测试集成预处理和模型推理的接口
1. Triton Inference Server 简介
AI 推理入门必看 | Triton Inference Server 原理入门之框架篇
- Server侧:同时支持TensorRT、ONNX、Pytorch、TensorFlow的模型托管和部署
- Client侧:http、 rest、 grpc api
- 支持CPU、GPU、Multi-GPU 异构特性
- 动态分批推理 batch size是动态的,多线程,多实例
- 模型并行推理 k8s管理不同的模型;一个模型可以供不同服务使用
- 模型库 模型文件可以存储在云端(AWS s3,谷歌云存储等)或本地文件系统,即使某一模型在Triton上已经开始运行,Triton仍然可以加载从模型库更新的新模型或新配置,这也保障了更好的模型安全性能和模型升级机制。
- 模型版本管理 一个模型文件夹下面可以放几个版本,triton可以自动化管理
- 服务器监控 Prometheus
2. Triton安装
2.1. 预备
- 安装Docker
- 直接拉triton的容器,通过容器部署,triton-inference-server
- 安装NVIDIA Container Toolkit
- Docker不能直接使用GPU,用这个连接
2.2. Pull triton镜像
- 镜像库:https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver/tags
- 选取镜像库中一个镜像下拉
终端输入:
docker pull nvcr.io/nvidia/tritonserver:22.05-py3
或者
sudo docker pull nvcr.io/nvidia/tritonserver:22.05-py3
安装成功会输出类似LOG:
7e9edccda8bc: Pull complete
a77d121c6271: Pull complete
074e6c40e814: Pull complete
Digest: sha256:1ddc4632dda74e3307e0251d4d7b013a5a2567988865a9fd583008c0acac6ac7
Status: Downloaded newer image for nvcr.io/nvidia/tritonserver:22.05-py3
nvcr.io/nvidia/tritonserver:22.05-py3
3. Triton的简单测试使用
3.1 构建一个模型目录
mkdir -p /home/triton/model_repository/<your model name>/<vision>
简单测试先使用:
mkdir -p /home/triton/model_repository/fc_model_pt/1
mkdir -p /home/triton/model_repository/fc_model_onnx/1
/home/triton/model_repository 文件目录表示模型仓库,所有的模型都在这个模型目录中。
启动容器后会将model_repository映射到tritonserver的docker镜像中。
3.2 为模型库生成2个测试模型 (torch和onnx)
import torch
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.embedding = nn.Embedding(100, 8)
self.fc = nn.Linear(8, 4)
self.fc_list = nn.Sequential(*[nn.Linear(8, 8) for _ in range(4)])
def forward(self, input_ids):
word_emb = self.embedding(input_ids)
output1 = self.fc(word_emb)
output2 = self.fc_list(word_emb)
return output1, output2
if __name__ == "__main__":
pt_path = "/home/triton/model_repository/fc_model_pt/1/model.pt"
onnx_path = "/home/triton/model_repository/fc_model_onnx/1/model.onnx"
model = SimpleModel()
ipt = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.long)
script_model = torch.jit.trace(model, ipt, strict=True)
torch.jit.save(script_model, model_path)
torch.onnx.export(model, ipt, onnx_path,
input_names=['input'],
output_names=['output1', 'output2']
)
3.3 启动Triton服务
# 建议先重启一下Docker 非必需
sudo systemctl restart docker
# 启动Tritont服务
sudo docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v /home/triton/model_repository:/models nvcr.io/nvidia/tritonserver:22.05-py3 tritonserver --model-repository=/models --strict-model-config=false
注意:上面命令中 strict-model-config=false,这个表示使用Triton自动生成模型的配置
如果熟悉模型配置的规范,可以先自己配置好config文件。再启动Tritont服务,对应的strict-model-config传True。
这里我们为torch版本配置config参数
在"/home/triton/model_repository/fc_model_pt" 目录下新建 config.pbtxt 文件
name: "fc_model_pt" # 模型名,也是目录名
platform: "pytorch_libtorch" # 模型对应的平台,本次使用的是torch,不同格式的对应的平台可以在官方文档找到
max_batch_size : 64 # 一次送入模型的最大bsz,防止oom
input [
{
name: "input__0" # 输入名字,对于torch来说名字于代码的名字不需要对应,但必须是__的形式,注意是2个下划线,写错就报错
data_type: TYPE_INT64 # 类型,torch.long对应的就是int64,不同语言的tensor类型与triton类型的对应关系可以在官方文档找到
dims: [ -1 ] # -1 代表是可变维度,虽然输入是二维的,但是默认第一个是bsz,所以只需要写后面的维度就行(无法理解的操作,如果是[-1,-1]调用模型就报错)
}
]
output [
{
name: "output__0" # 命名规范同输入
data_type: TYPE_FP32
dims: [ -1, -1, 4 ]
},
{
name: "output__1"
data_type: TYPE_FP32
dims: [ -1, -1, 8 ]
}
]
运行成功可以看到日志:
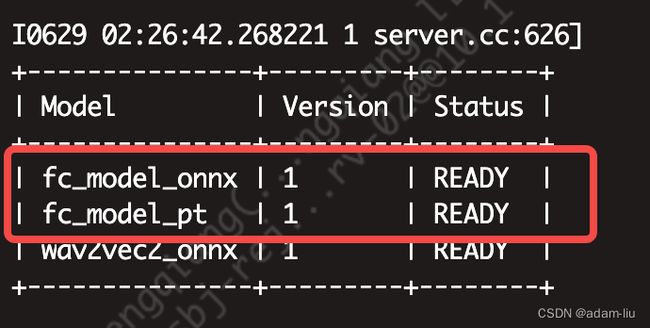

3.4 修改triton配置
由于模型是自动配置的参数,用户不知道配置参数,也不能灵活的配置。
理想情况下我们应该为每个模型创建一个 config.pbtxt 文件。
使用命令获取模型生成的配置文件:
curl localhost:8000/v2/models/<your model name>/config
#简单测试先使用:
curl localhost:8000/v2/models/fc_model_onnx/config
得到输出
{
"name": "fc_model_onnx",
"platform": "onnxruntime_onnx",
"backend": "onnxruntime",
"version_policy": {
"latest": {
"num_versions": 1
}
},
"max_batch_size": 0,
"input": [{
"name": "input",
"data_type": "TYPE_INT64",
"format": "FORMAT_NONE",
"dims": [2, 3],
"is_shape_tensor": false,
"allow_ragged_batch": false,
"optional": false
}],
"output": [{
"name": "output2",
"data_type": "TYPE_FP32",
"dims": [2, 3, 8],
"label_filename": "",
"is_shape_tensor": false
}, {
"name": "output1",
"data_type": "TYPE_FP32",
"dims": [2, 3, 4],
"label_filename": "",
"is_shape_tensor": false
}],
"batch_input": [],
"batch_output": [],
"optimization": {
"priority": "PRIORITY_DEFAULT",
"input_pinned_memory": {
"enable": true
},
"output_pinned_memory": {
"enable": true
},
"gather_kernel_buffer_threshold": 0,
"eager_batching": false
},
"instance_group": [{
"name": "fc_model_onnx",
"kind": "KIND_GPU",
"count": 1,
"gpus": [0],
"secondary_devices": [],
"profile": [],
"passive": false,
"host_policy": ""
}],
"default_model_filename": "model.onnx",
"cc_model_filenames": {},
"metric_tags": {},
"parameters": {},
"model_warmup": []
}
通过JSON的输出配置。如torch版本一样, 在"/home/triton/model_repository/fc_model_onnx" 目录下新建 config.pbtxt 文件,并修改如下:(格式要求详见model_configuration)
name: "fc_model_onnx"
platform: "onnxruntime_onnx"
max_batch_size : 0
input [
{
name: "input"
data_type: TYPE_INT64
dims: [2, 3]
}
]
output [
{
name: "output1"
data_type: TYPE_FP32
dims: [2, 3, 4]
},
{
name: "output2"
data_type: TYPE_FP32
dims: [2, 3, 8]
}
]
3.5 triton服务重启
因为有了灵活的配置文件,重新启动一下Triton
注意,如果有配置文件后,之后的每次启动都使用下面的这个命令
# 设置 strict-model-config=True 严格按config文件
sudo docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v /home/triton/model_repository:/models nvcr.io/nvidia/tritonserver:22.05-py3 tritonserver --model-repository=/models --strict-model-config=True
# 如果端口被占用 重启一下docker
sudo systemctl restart docker
3.6 测试Triton服务
3.6.1 http测试代码
Torch版本
import numpy as np
import tritonclient.http as httpclient
triton_client = httpclient.InferenceServerClient(url="localhost:8000", verbose=False)
model_name = "fc_model_pt"
inputs = [
httpclient.InferInput('input__0', [2, 3], "INT64")
]
outputs = [
httpclient.InferRequestedOutput('output__0'),
httpclient.InferRequestedOutput('output__1')
]
inputs[0].set_data_from_numpy(np.random.randint(0, high=5, size=(2, 3)))
results = triton_client.infer(model_name=model_name, inputs=inputs, outputs=outputs)
print(results.as_numpy("output__0"))
print(results.as_numpy("output__1"))
onnx版本
import numpy as np
import tritonclient.http as httpclient
triton_client = httpclient.InferenceServerClient(url="localhost:8000", verbose=False)
model_name = "fc_model_onnx"
inputs = [
httpclient.InferInput('input', [2, 3], "INT64")
]
outputs = [
httpclient.InferRequestedOutput('output1'),
httpclient.InferRequestedOutput('output2')
]
inputs[0].set_data_from_numpy(np.random.randint(0, high=5, size=(2, 3)))
results = triton_client.infer(model_name=model_name, inputs=inputs, outputs=outputs)
print(results.as_numpy("output1"))
print(results.as_numpy("output2"))
3.6.2 GRPC测试代码
torch版本
import numpy as np
import tritonclient.grpc as grpcclient
triton_client = grpcclient.InferenceServerClient(url="localhost:8001", verbose=False)
model_name = "fc_model_pt"
inputs = [
grpcclient.InferInput('input__0', [2, 3], "INT64")
]
outputs = [
grpcclient.InferRequestedOutput('output__0'),
grpcclient.InferRequestedOutput('output__1')
]
inputs[0].set_data_from_numpy(np.random.randint(0, high=5, size=(2, 3)))
results = triton_client.infer(model_name=model_name, inputs=inputs, outputs=outputs)
print(results.as_numpy("output__0"))
print(results.as_numpy("output__1"))
onnx版本
import numpy as np
import tritonclient.grpc as grpcclient
triton_client = grpcclient.InferenceServerClient(url="localhost:8001", verbose=False)
model_name = "fc_model_onnx"
inputs = [
grpcclient.InferInput('input', [2, 3], "INT64")
]
outputs = [
grpcclient.InferRequestedOutput('output1'),
grpcclient.InferRequestedOutput('output2')
]
inputs[0].set_data_from_numpy(np.random.randint(0, high=5, size=(2, 3)))
results = triton_client.infer(model_name=model_name, inputs=inputs, outputs=outputs)
print(results.as_numpy("output1"))
print(results.as_numpy("output2"))
3.7 7. 将数据预处理和模型预测全部集成在Triton中
在模型库(/home/triton/model_repository)新建Python backend的model
mkdir -p /home/triton/model_repository//
简单测试先使用:
mkdir -p /home/triton/model_repository/custom_model/1
在custom_model/1/ 目录下新建 model.py文件。
model.py 中需要提供三个接口:initialize, execute, finalize。其中 initialize和 finalize是模型实例初始化、模型实例清理的时候会调用的。如果有 n 个模型实例,那么会调用 n 次这两个函数。
import json
import numpy as np
import triton_python_backend_utils as pb_utils
class TritonPythonModel:
"""Your Python model must use the same class name. Every Python model
that is created must have "TritonPythonModel" as the class name.
"""
def initialize(self, args):
"""`initialize` is called only once when the model is being loaded.
Implementing `initialize` function is optional. This function allows
the model to intialize any state associated with this model.
Parameters
----------
args : dict
Both keys and values are strings. The dictionary keys and values are:
* model_config: A JSON string containing the model configuration
* model_instance_kind: A string containing model instance kind
* model_instance_device_id: A string containing model instance device ID
* model_repository: Model repository path
* model_version: Model version
* model_name: Model name
"""
# You must parse model_config. JSON string is not parsed here
self.model_config = model_config = json.loads(args['model_config'])
# Get output__0 configuration
output0_config = pb_utils.get_output_config_by_name(
model_config, "output__0")
# Get output__1 configuration
output1_config = pb_utils.get_output_config_by_name(
model_config, "output__1")
# Convert Triton types to numpy types
self.output0_dtype = pb_utils.triton_string_to_numpy(output0_config['data_type'])
self.output1_dtype = pb_utils.triton_string_to_numpy(output1_config['data_type'])
def execute(self, requests):
"""
requests : list
A list of pb_utils.InferenceRequest
Returns
-------
list
A list of pb_utils.InferenceResponse. The length of this list must
be the same as `requests`
"""
output0_dtype = self.output0_dtype
output1_dtype = self.output1_dtype
responses = []
# Every Python backend must iterate over everyone of the requests
# and create a pb_utils.InferenceResponse for each of them.
for request in requests:
# get input request tensor
in_0 = pb_utils.get_input_tensor_by_name(request, "input__0")
# model inferencece clent
inference_request = pb_utils.InferenceRequest(
model_name='fc_model_pt',
requested_output_names=['output__0', 'output__1'],
inputs=[in_0])
# model forward
inference_response = inference_request.exec()
# get output tensor
out_tensor_0 = pb_utils.get_output_tensor_by_name(inference_response, 'output__0')
out_tensor_1 = pb_utils.get_output_tensor_by_name(inference_response, 'output__1')
# to response
inference_response = pb_utils.InferenceResponse(output_tensors=[out_tensor_0, out_tensor_1])
responses.append(inference_response)
return responses
def finalize(self):
"""`finalize` is called only once when the model is being unloaded.
Implementing `finalize` function is OPTIONAL. This function allows
the model to perform any necessary clean ups before exit.
"""
print('Cleaning up...')
在custom_model/目录下新建 config.pbtxt文件。编写config
name: "custom_model"
backend: "python"
input [
{
name: "input__0"
data_type: TYPE_INT64
dims: [ -1, -1 ]
}
]
output [
{
name: "output__0"
data_type: TYPE_FP32
dims: [ -1, -1, 4 ]
},
{
name: "output__1"
data_type: TYPE_FP32
dims: [ -1, -1, 8 ]
}
]
3.6.8. 测试集成预处理和模型推理的接口
import numpy as np
import tritonclient.grpc as grpcclient
triton_client = grpcclient.InferenceServerClient(url="localhost:8001", verbose=False)
model_name = "custom_model"
inputs = [
grpcclient.InferInput('input__0', [2, 3], "INT64")
]
outputs = [
grpcclient.InferRequestedOutput('output__0'),
grpcclient.InferRequestedOutput('output__1')
]
inputs[0].set_data_from_numpy(np.random.randint(0, high=5, size=(2, 3)))
results = triton_client.infer(model_name=model_name, inputs=inputs, outputs=outputs)
print(results.as_numpy('output__0'))
print(results.as_numpy('output__1'))
或者使用接口测试
import requests
import numpy as np
request_data = {
"inputs": [{
"name": "input__0",
"shape": [1, 2],
"datatype": "INT64",
"data": [[1, 2]]
}],
"outputs": [{"name": "output__0"}, {"name": "output__1"}]
}
res = requests.post(url="http://localhost:8000/v2/models/fc_model_pt/versions/1/infer",json=request_data).json()
# 单独跑fc_model_pt forward
print(res)
res = requests.post(url="http://localhost:8000/v2/models/custom_model/versions/1/infer",json=request_data).json()
# 跑preprocess+inference
print(res)