【计算机视觉】计算机视觉与深度学习-02-图像分类-北邮鲁鹏老师课程笔记
计算机视觉与深度学习-02-图像分类-北邮鲁鹏老师课程笔记
- 图像分类任务
- 图像分类任务应用场合
- 图像分类任务难点
-
- 视角
- 光照
- 尺度
- 遮挡
- 形变
- 背景杂波
- 类内形变
- 运动模糊
- 类别繁多
- 基于规则的分类方法
-
- 硬编码
- 数据驱动的图像分类
-
- 数据驱动的图像分类步骤
-
- 数据集构建
-
- 有标签(监督)
- 无标签(无监督)
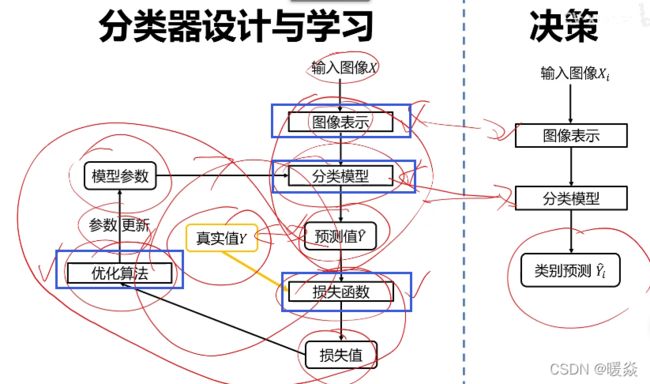
- 分类器设计与学习(关键)
-
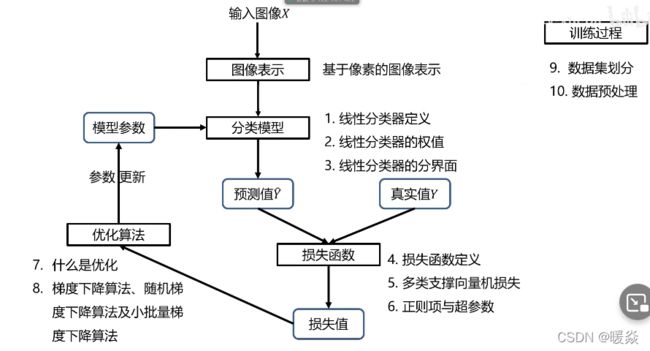
- 图像表示
-
- 像素表示
- 全局特征表示(如GIST)
-
- GIST
- 局部特征表示(如SIFT特征+词袋模型)
- 分类模型
-
- 近邻分类器
- 贝叶斯分类器
- 线性分类器
- 支撑向量机分类器
- 神经网络分类器
- 随机森林
-
- 决策树
- Adaboost
- 损失函数
-
- 0-1损失
- 多类支撑向量机损失
- 交叉熵损失
- L1损失
- L2损失
- 优化方法
-
- 一阶方法
-
- 梯度下降
- 随机梯度下降
- 小批量随机梯度下降
- 二阶方法
-
- 牛顿法
- BFGS
- L-BFGS
- 训练过程
-
- 数据集划分
- 数据预处理
- 数据增强
- 欠拟合与过拟合
-
- 减小算法复杂度
- 使用权重正则项
- 使用droput正则化
- 超参数调整
- 模型集成
- 分类器决策
- 常用的分类任务评价指标
-
- 正确率&错误率
- 线性分类器
-
- 数据集
- 图像表示(基于像素)
-
- 二进制图像(0-1)
- 灰度图像(0~255)
- 彩色图像(RGB)
- 分类模型-线性分类器
-
- 线性分类器的定义
- 线性分类器的决策
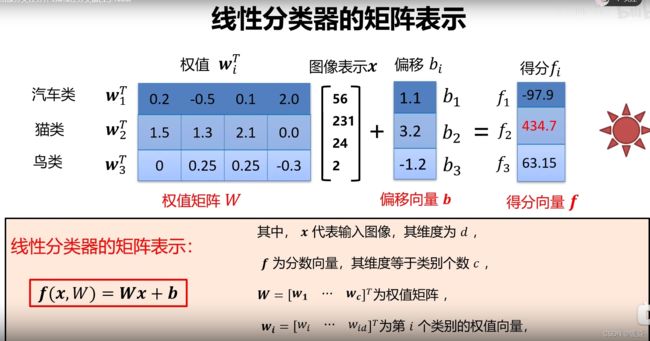
- 线性分类器的矩阵表示
- 线性分类器的权值向量
- 线性分类器的决策边界
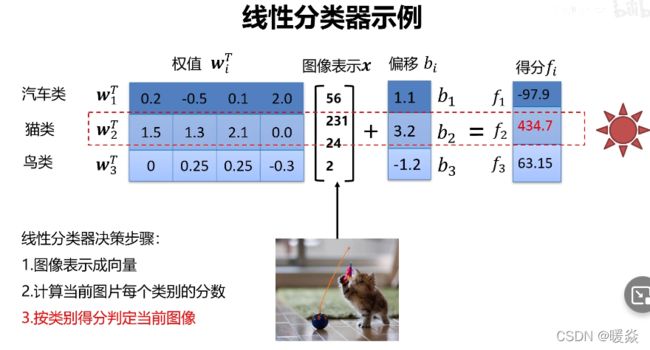
- 线性分类器示例
- 损失函数
-
- 损失函数的定义
- 多分类支撑向量机损失
- 关于损失函数的思考
-
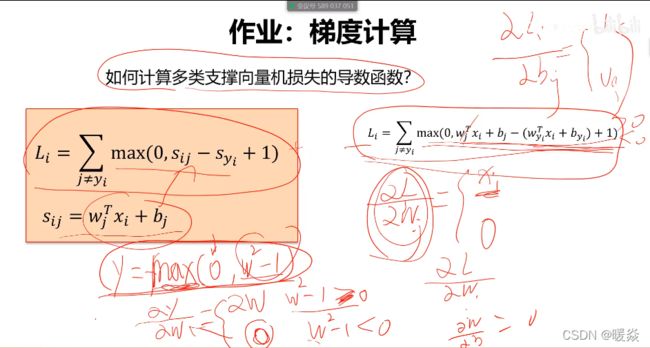
- 多类支撑向量机损失Li的最大/最小值会是多少?
- 如果初始化时w和b很小,损失L是多少?
-
- 重要应用
- 考虑所有类别(包括j=yi), 损失L,对最优参数的选择是否有影响?
- 在总损失L计算时,如果用求和代替平均,对最优参数的选择是否有影响?
- 如果使用 L i = ∑ j ≠ y i m a x ( 0 , S j − S y i + 1 ) 2 L_i=\sum_{j\neq y_i}max(0,S_j-S_{y_i}+1)^2 Li=∑j=yimax(0,Sj−Syi+1)2,对最优参数的选择是否有影响?
- 正则项与超参数
-
- 关于损失函数的思考
-
- 问题:假设存在一个W使损失函数L=0,这个W是唯一的吗?
- 问题:若存在W1和W2都使损失函数L=0,如何在W1和W2之间做选择?
- 什么是超参数?
- L2正则项
- 为什么需要正则项?
- 常用的正则项损失
- 优化算法
-
- 参数优化
- 常用优化算法
-
- 梯度下降
-
- 往哪走?
- 走多远?
- 梯度计算
-
- 数值法
- 数值梯度有什么作用
- 解析法
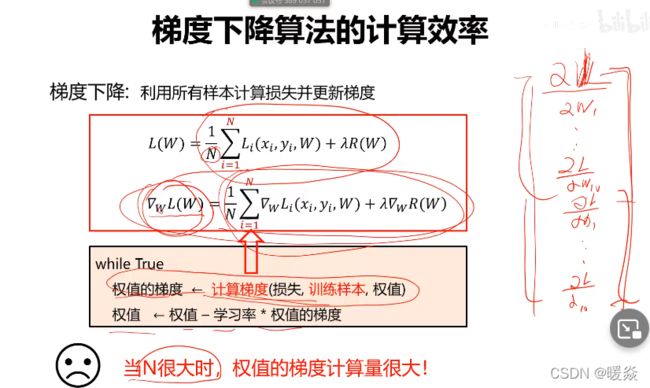
- 梯度下降算法的计算效率
- 随机梯度下降算法
- 小批量梯度下降算法
- 训练过程
-
- 数据集划分
-
- 训练集+测试集
- 训练集+验证集+测试集
- 交叉验证
-
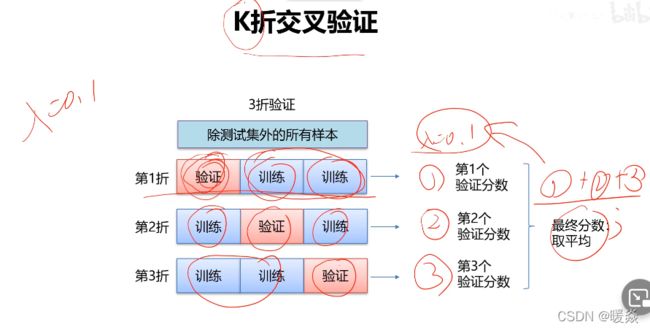
- K折交叉验证
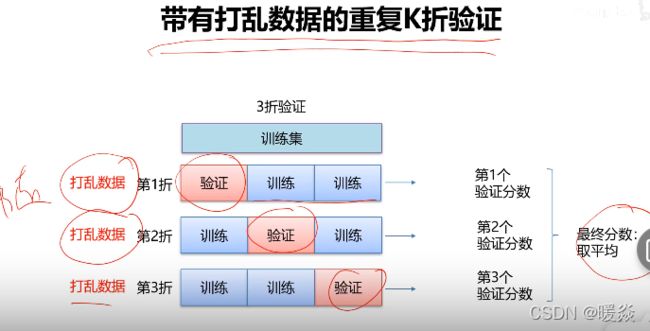
- 带打乱数据的重复K折交叉验证
- 数据预处理
-
- 去均值
- 归一化
- 去相关性
- 白化
图像分类任务
从已知的类别标签集合中为给定的输入图片选定一个类别标签。
图像分类任务是计算机视觉中的核心任务,其目标是根据图像信息中所反映的不同特征,把不同类别
的图像区分开来。
图像分类任务应用场合
百度图片搜索
商品图片识别
图像分类任务难点

视角
物体不同视角的照片,像素值有巨大差异
光照
尺度
遮挡
形变
背景杂波
照片中的背景与物体颜色相似时,不容易识别物体
类内形变
运动模糊
需要算法将运动模糊恢复
类别繁多









基于规则的分类方法
硬编码
硬编码:将输入给到函数的参数,经过函数的处理,返回结果。
通过硬编码的方法识别猫或其他类,是一件很困难的事。因为不可能预先知道所有猫的不同形态,可能图片中的猫有各种姿势,通过函数中几种固定的边缘数据,无法识别出千千万万不同光照、有遮挡等比较难识别的物体。
人脸识别可用硬编码识别,因为人脸的图片相对固定,一个嘴巴两只眼镜,但即使是这样,识别也很困难,需要adaboost等算法进行识别。
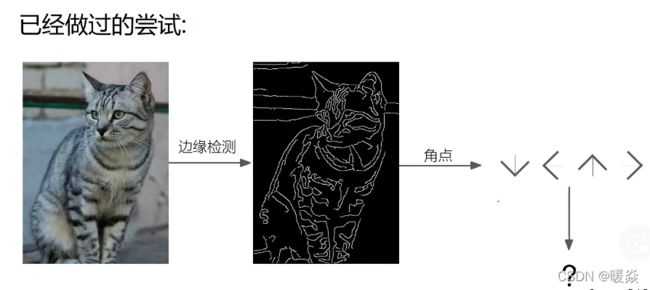
数据驱动的图像分类
数据驱动的图像分类步骤
数据集构建
有标签(监督)
无标签(无监督)
分类器设计与学习(关键)
从数据集中归纳出规律,找出数学模型及其参数。
图像表示
像素表示
全局特征表示(如GIST)
适用于风景类、室内场景、建筑等大场景类的分类。不适合有遮挡等细致问题。
GIST
从图像中抽取频率特征。
局部特征表示(如SIFT特征+词袋模型)
从图像中抽取多个有典型意义的区块,用这些区块表示整图,即使部分区块被遮挡,影响也不大。
分类模型
近邻分类器
贝叶斯分类器
线性分类器
支撑向量机分类器
神经网络分类器
随机森林
决策树
Adaboost
损失函数
0-1损失
多类支撑向量机损失
交叉熵损失
L1损失
L2损失
优化方法
迭代优化方法
一阶方法
梯度下降
随机梯度下降
小批量随机梯度下降
二阶方法
牛顿法
BFGS
L-BFGS
训练过程
数据集划分
数据预处理
数据增强
欠拟合与过拟合
减小算法复杂度
使用权重正则项
使用droput正则化
超参数调整
模型集成
分类器决策
常用的分类任务评价指标
正确率&错误率
正确率(accuracy) =分对的样本数/全部样本数
错误率(error rate) = 1 -正确率
线性分类器
数据集
图像表示(基于像素)
大多数分类算法都要求输入向量,将图像矩阵转换成向量。
二进制图像(0-1)
灰度图像(0~255)
彩色图像(RGB)
分类模型-线性分类器
线性分类器的定义
线性分类器是一种线性映射,将输入的图像特征映射为类别分数。
形式简单,易于理解
通过层级结构(神经网络)或者高维映射(支撑向量机)可以形成功能强大的非线性模型
线性分类器的决策

线性分类器的矩阵表示
线性分类器的权值向量

线性分类器的决策边界
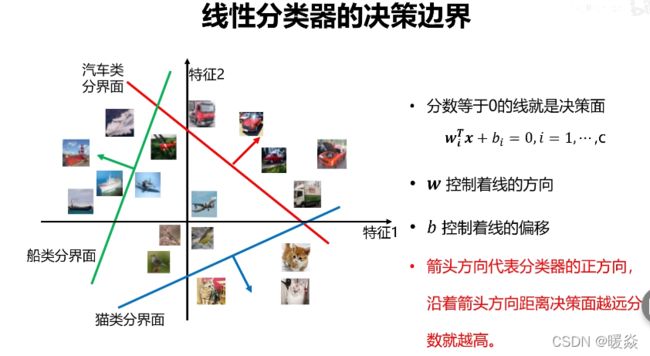
线性分类器示例
损失函数
找到最优的分类模型,还需要损失函数与优化算法的帮忙。
损失函数的定义
损失函数是一个函数,用于度量给定分类器的预测值与真实值的不一致程度,其输出通常是一一个非负实值。
其输出的非负实值可以作为反馈信号来对分类器参数进行调整,以降低当前示例对应的损失值,提升分类器的分类效果。
对分类器性能的定量表示。
损失函数搭建了模型性能与模型参数W,b之间的桥梁,指导模型参数优化。
损失值就是模型性能的描述。

多分类支撑向量机损失
 为什么加1?-- 加1是边界,减小边界附近噪声的影响
为什么加1?-- 加1是边界,减小边界附近噪声的影响
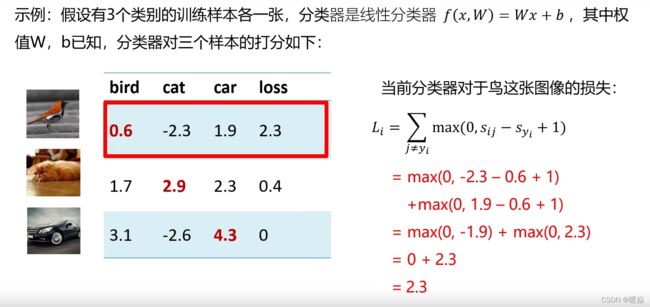
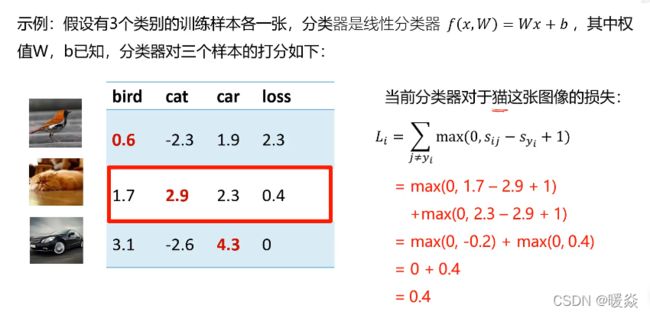
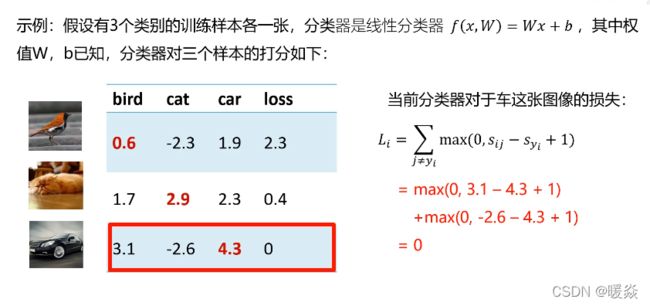

关于损失函数的思考

多类支撑向量机损失Li的最大/最小值会是多少?
最大:正无穷;最小:0;
如果初始化时w和b很小,损失L是多少?
w和b很小时,Sij和Syi都很小且Sij-Syi约为0,那么
单样本的多类支撑向量机损失:Li=N-1;(N为样本类别数量)
损失函数:L=N-1; (N为样本类别数量)
重要应用
将w和b初始化为很小的值时,可以检测算法的编码是否有错误,若Li和L都为N-1,说明编码美语错误;
考虑所有类别(包括j=yi), 损失L,对最优参数的选择是否有影响?
没有影响
在总损失L计算时,如果用求和代替平均,对最优参数的选择是否有影响?
去掉1/N,相当于所有模型参数组合对应的损失函数值都放大N倍,对最优参数的选择没有影响。
如果使用 L i = ∑ j ≠ y i m a x ( 0 , S j − S y i + 1 ) 2 L_i=\sum_{j\neq y_i}max(0,S_j-S_{y_i}+1)^2 Li=∑j=yimax(0,Sj−Syi+1)2,对最优参数的选择是否有影响?
有影响,考虑100倍放大为10000,而0.01倍缩小为0.0001。
正则项与超参数
关于损失函数的思考
问题:假设存在一个W使损失函数L=0,这个W是唯一的吗?
答案:不唯一(见下面的例子)
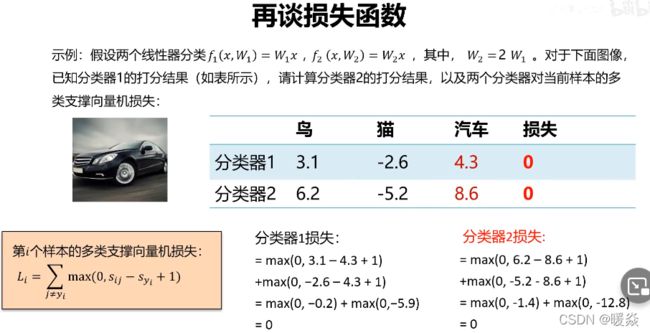
问题:若存在W1和W2都使损失函数L=0,如何在W1和W2之间做选择?
答案:添加正则项损失。正则损失会使损失函数L唯一,不会出现多个w对应L都为0的情况。
注:实际问题中,L很多情况下不为0。这里只是将L=0作为一种极端情况考虑。

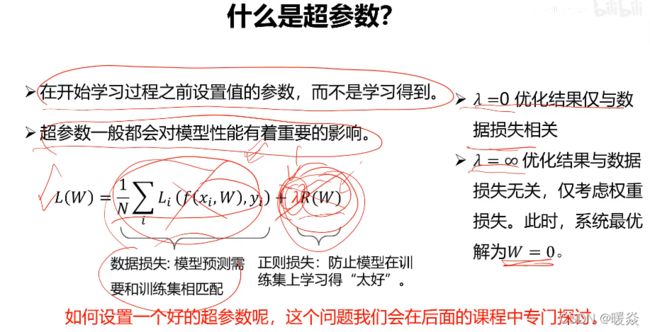
什么是超参数?
在开始学习过程之前设置值的参数,而不是学习得到。
超参数一般都会对模型性能有着重要的影响。
L2正则项

为什么需要正则项?
正则损失会使损失函数L唯一,不会出现多个w对应L都为0的情况。
正则让模型有了偏好,通过设置正则项,使得可以在多个损失函数为0的模型参数中选出最优的模型参数。
防止模型过拟合。
常用的正则项损失

优化算法
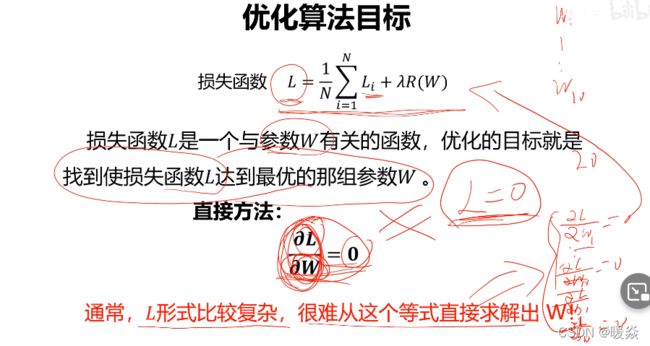
参数优化
参数优化是机器学习的核心步骤之一, 它利用损失函数的输出值作为反馈信号来调整分类器参数,以提升分类器对训练样本的预测性能。
常用优化算法
梯度下降
一种简单而高效的迭代优化方法。
往哪走?
负梯度方向
走多远?
步长决定,即学习率
梯度计算

数值法
每个W都需要计算一次,计算量大,近似值,不精确。

数值梯度有什么作用
求梯度时一般使用解析梯度,而数值梯度主要用于解析梯度的正确性校验(梯度检查)。
解析法
非近似值,而是精确值,速度快,但是导数函数推导易错。

梯度下降算法的计算效率
随机梯度下降算法

小批量梯度下降算法
 iteration、batch-size、epoch是为了更好的描述算法效率。
iteration、batch-size、epoch是为了更好的描述算法效率。
batch-size:10
iteration:10
则总共迭代了100个样本
batch-size:100
iteration:1
也总共迭代了100个样本
所以,论文中,一般用epoch描述迭代样本情况。
1个epoch需要N/m次迭代,N是样本总数,m是批量大小。

训练过程
数据集划分
训练集+测试集
训练集:训练模型,寻找最优分类器
测试集:评估模型,评测泛化能力
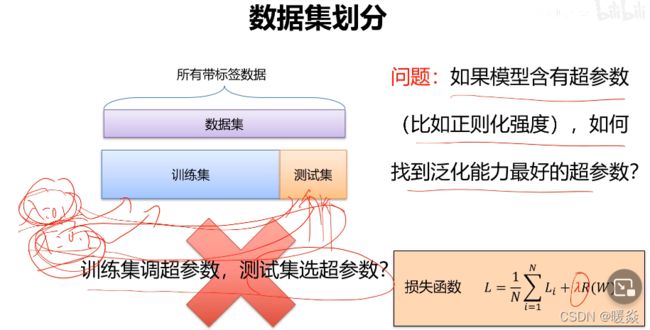 缺点:使用训练集学习分类器参数,测试集选超参数,测试集数据暴露。
缺点:使用训练集学习分类器参数,测试集选超参数,测试集数据暴露。
训练集+验证集+测试集
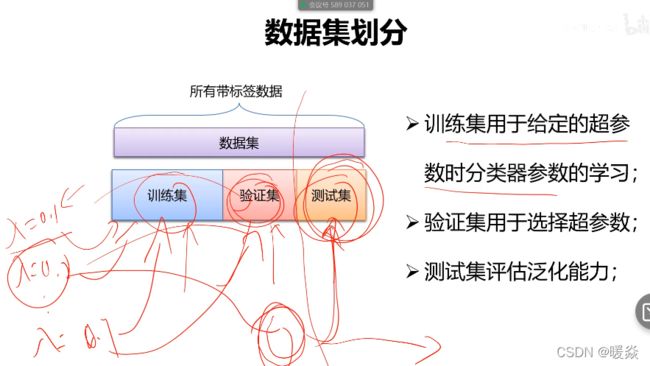
交叉验证
问题:如果数据很少,那么可能验证集包含的样本就太少, )从而无法在统计,上代表数据。
这个问题很容易发现:如果在划分数据前进行不同的随机打乱,最终得到的 模型性能差别很大,那么就存在这个问题。
接下来会介绍K折验证与重复的K折验证,它们是解决这一问题的两种方法。
K折交叉验证
带打乱数据的重复K折交叉验证
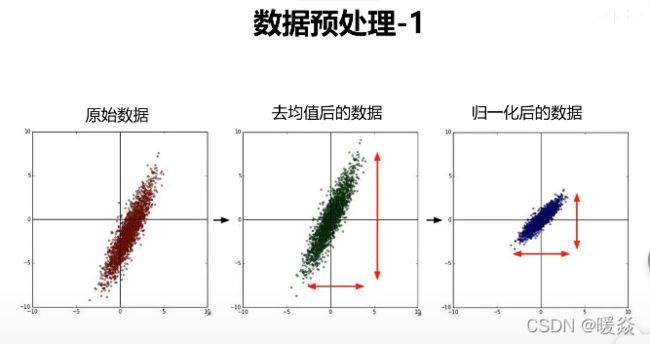
数据预处理
去均值
x=x-均值
例如数据都是10000上下且均值为10000,可以将所有数据减去均值10000,数据就会在一个几百几千的范围内
归一化
x=(x-u)/方差
例如x轴单位为吨,y轴单位为毫米,则在x轴上数据密度比较大,不容易分析,将所有数据进行归一化
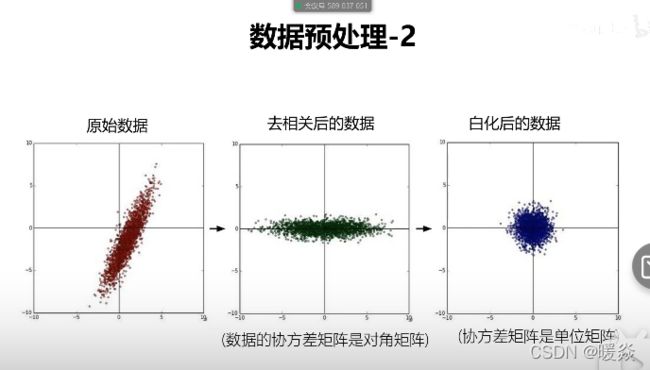
去相关性
原始数据中x变大y也变大,x和y有相关性,有时候要只单独讨论x或只单独讨论y,就需要去掉x,y的相关性,x变化,y不会随着变化。
例如:高纬度情况下,有几个不需要考虑的维度,就将这几个维度与需要研究的维度去相关性,即降维。
白化
在去相关的基础上进行归一化。
 ## 线性分类器例题
## 线性分类器例题
Linear Classification Loss Visualization