什么是知识图谱?
目录
前言
1.什么是知识图谱
2.知识图谱的通用表示方式
3.知识图谱的应用
3.1搜索
3.2问答
3.3辅助大数据分析
4.知识图谱的构建
4.1流程概述
4.2知识抽取
4.3知识融合
4.4知识推理
5.知识图谱和NLP
前言
笔者总结网上关于知识图谱的相关资料并总结了一些基本概念,对于想了解这一概念的读者提供了一个新手入门的视角。
1.什么是知识图谱
本质上,知识图谱主要目标是用来描述真实世界中存在的各种实体和概念,以及他们之间的关系,因此可以认为是一种语义网络。从发展的过程来看,知识图谱是在NLP的基础上发展而来的。知识图谱和自然语言处理NLP有着紧密的联系,都属于比较顶级的AI技术。知识图谱可以用来更高的查询复杂的关联信息,从语义层面理解用户意图,改进搜索质量。
2.知识图谱的通用表示方式
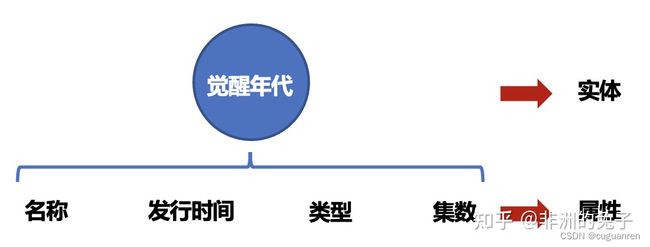
其基本组成单位是“实体—关系—实体”三元组,以及实体及其相关属性—值对,实体间通过关系相互联结,构成网状的知识结构。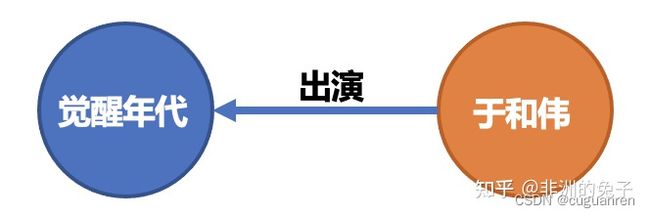
同时每个节点代表的实体还存在着一些属性,比如“《觉醒年代》”这个节点,我们可以把一些基本信息作为属性,比如影片名称、发行时间、影片类型、集数等。
3.知识图谱的应用
3.1搜索
搜索的终极目标是对万物直接进行搜索。传统搜索是靠网页之间的超链接实现网页的搜索,而语义搜索是直接对事物进行搜索,比如人、物、机构、地点等,这些事物可以来自文本、图片、视频、音频、物联网设备等。知识图谱和语义技术提供了关于这些事物的分类、属性和关系的描述,这样搜索引擎就可以直接对事物进行搜索。比如我们想知道“《觉醒年代》的导演是谁?”,那么在进行搜素时,搜索引擎会把这句话进行分解,获得“《觉醒年代》”,“导演”,再与现有的知识库中的词条进行匹配,最后展现在用面前。传统的搜索模式下,我们进行这样的搜索后得到的通常是包含其中关键词的网页链接,我们还需要在多个网页中进行筛选。可以看出基于知识图谱的搜索更加便捷与准确。
3.2问答
人与机器通过自然语言进行问答与对话也是人工智能实现的标志之一,知识图谱也广泛应用于人机问答交互中。借助自然语言处理和知识图谱技术,比如基于语义解析、基于图匹配、基于模式学习、基于表示学习和深度学习的知识图谱模型。
3.3辅助大数据分析
知识图谱也可以用于辅助进行数据分析与决策。不同来源的知识通过知识融合进行集成,通过知识图谱和语义技术增强数据之间的关联,用户可以更直观地对数据进行分析。此外知识图谱也被广泛用于作为先验知识从文本中抽取实体和关系,也被用来辅助实现文本中的实体消歧,指代消解等。
4.知识图谱的构建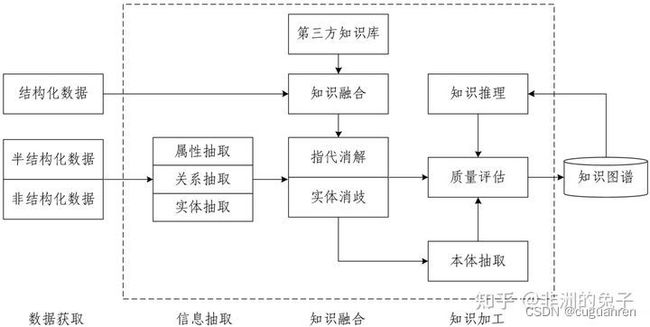
4.1流程概述
首先是获取数据,它们可以是一些表格、文本、数据库等。根据数据的类型可以分为结构化数据、非结构化数据和半结构化数据。结构化的数据为表格、数据库等按照一定格式表示的数据,通常可以直接用来构建知识图谱。非结构化的数据为文本、音频、视频、图片等,需要对它们进行信息抽取才能进一步建立知识图谱。半结构化数据是介于结构化和非结构化之间的一种数据,也需要进行信息抽取才能建立知识图谱。拿到了不同来源的数据时,需要对数据进行知识融合,也就是把代表相同概念的实体合并,将多个来源的数据集合并成一个数据集。这样就得到了最终的数据,在此基础上就可以建立相应的知识图谱了。
知识图谱通过知识推理等技术能够获得新的知识,所以通过知识推理可以不断完善现有的知识图谱。
4.2知识抽取
知识抽取主要针对非结构数据,方法主要包括:实体识别、关系抽取、属性抽取等。
结构化数据:目前结构化的数据时最主要的知识来源。针对结构化的数据,知识图谱通常可以直接利用和转化,形成基础数据集,再利用知识图谱补全技术进一步扩展知识图谱。
非结构化数据:针对文本型数据这种非结构化数据,知识获取的方式主要包括实体识别、关系抽取、属性抽取等。具体的方法又包括基于特征模版的方法、基于核函数的监督学习方法、基于深度学习的方法等。
1)实体识别
实体识别指在一段文本中识别哪些词代表实体,并打上标签(进行分类)。
例如“演员于和伟出演了电视剧《觉醒年代》”这句话中,“于和伟”和“《觉醒年代》”就是两个实体,将他们识别出来之后会分别给“于和伟”打上“演员”的标签,给“《觉醒年代》”打上“电视剧的标签”。
2)关系抽取
识别文本(或其他数据)中实体之间的关系。
例如“演员于和伟出演了电视剧《觉醒年代》”这句话中,“出演”为“演员于和伟”与“电视剧《觉醒年代》”之间的关系。
4.3知识融合
当我们想建立一个知识图谱,需要从多个来源获取数据,这些来源不同的数据可能会存在交叉、重叠,同一个概念、实体可能会反复出现,知识融合的目的就是把表示相同概念的实体进行合并,把来源不同的知识融合为一个知识库。
知识融合的主要任务包括实体消歧和指代消解,它们都用来判断知识库中的同名实体是代表同一含义、是否有其他实体也表示相同含义。实体消歧专门用于解决同名实体产生歧义的问题,通常采用聚类法、空间向量模型、语义模型等。指代消解则为了避免代词指代不清的情况
4.4知识推理
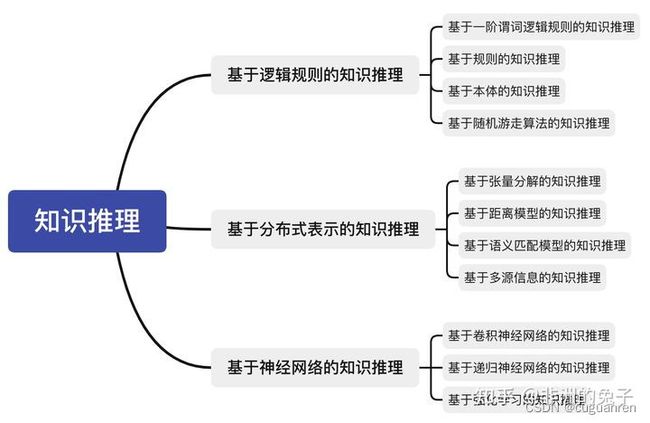
基于知识图的知识推理旨在识别错误并从现有数据中推断新结论。通过知识推理可以导出实体间的新关系,并反馈以丰富知识图,从而支持高级应用。鉴于知识图的广泛应用前景,大规模知识图的知识推理研究成为近年来自然语言处理领域的一个研究热点。
5.知识图谱和NLP
目前,知识图谱在自然语言处理领域有两大类的应用:
1)搜索和问答领域。
2)自然语言理解类的场景,比如在具体的机器翻译领域,句法分析相关的工作。
知识图谱在NLP中的应用: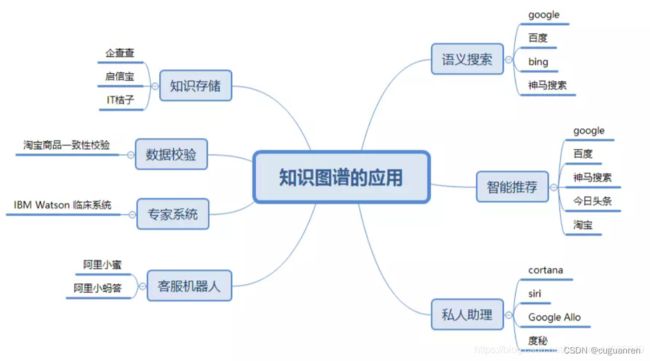
从上图可以看出,在NLP领域,知识图谱的应用主要集中在搜索和推荐领域,问答系统(其本质也是搜索和推荐的延伸)。在语义搜索这一块,知识图谱的搜索不同于常规的搜索,常规的搜索是根据keyword找到对应的网页集合,然后通过Page Rank等算法去给网页集合内的网页进行排名,然后展示给用户;基于知识图谱的搜索是在已有的图谱知识库中遍历知识,然后将查询到的知识返回给用户,通常如果路径正确,查询出来的知识只有1个或几个,并且相当精准。在问答系统中,系统同样会首先在知识图谱的帮助下对用户使用自然语言提出的问题进行语义分析和句法分析,进而将其转化成结构化形式的查询语句,然后在知识图谱中查询答案。
参考知识图谱入门——认识知识图谱