【图论算法】深度优先搜索的应用
文章目录
- 深度优先搜索
- 无向图
- 双连通性
-
-
- 双连通以及割点的概念
- 找出图中割点的算法
- 一个例子
-
- 欧拉回路
-
-
- 认识欧拉回路
- 找出欧拉回路的算法
- 一个例子
-
- 有向图
- 查找强分支
- dfs简单应用--部分和问题
深度优先搜索
深度优先搜索(depth-first search)是对先序遍历(preorder traversal)的推广。我们从某个顶点 v 开始处理 v,然后递归地遍历所有邻接到 v 的顶点。
对一棵树的所有顶点的访问需 O(|E|) 时间。对任意图进行该过程时则需要考虑避免圈的出现。为此,当访问一个顶点 v 的时候,由于当时已经到了该点处,因此可以标记该点是访问过的,并且对于尚未被标记的所有邻接顶点递归调用深度优先搜索。该方法保证每条边只访问一次,所以只要使用邻接表,则执行遍历的总时间就是 O(|E|+|V|)。
//深度优先搜索模板(伪代码)
void Graph:dfs(Vertex v)
{
v.visited=true;
for each Vertex w adjacent to v
if(!w.visited)
dfs(w);
}
无向图
无向图是连通的,当且仅当从任一节点开始的深度优先搜索访问到每一个节点。 我们以图形来描述深度优先生成树(depth-first spanning tree) 的步骤。该树的根为 A,是第一个被访问的节点。图中每条边 (v, w) 都出现在树上。如果当处理 (v, w) 时发现 w 是未被标记的,就用树的一条边来表示它。如果其已被标记,则画一条虚线,并称之为背向边 (back edge),表示这条 ‘边’ 实际上不是树的一部分。对图1 中的无向图进行 dfs 得到的深度优先生成树 如图2 所示。
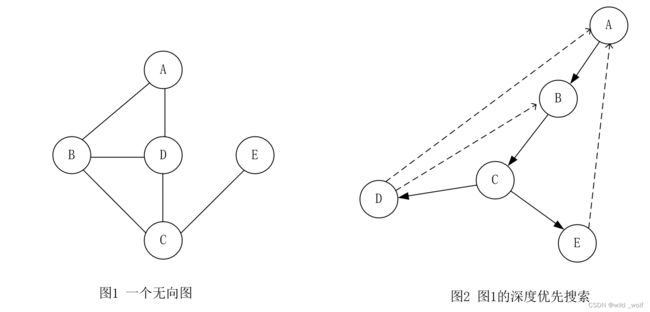
只使用树的边对该树的先序编号 (preorder numbering) 告诉我们这些顶点被标记的顺序。如果图不是连通的,那么处理所有的节点(和边)则需要多次调用 dfs,每次生成一棵树,整个集合就是深度优先生成森林(depth-first spanning forest)。
双连通性
双连通以及割点的概念
一个连通的无向图,如果不存在这样的顶点,即使得该顶点被删除之后剩下的图不再连通,那么这样的无向连通图就称为双连通(biconnected) 的。 上例中的图1 中的无向图就是双连通的。
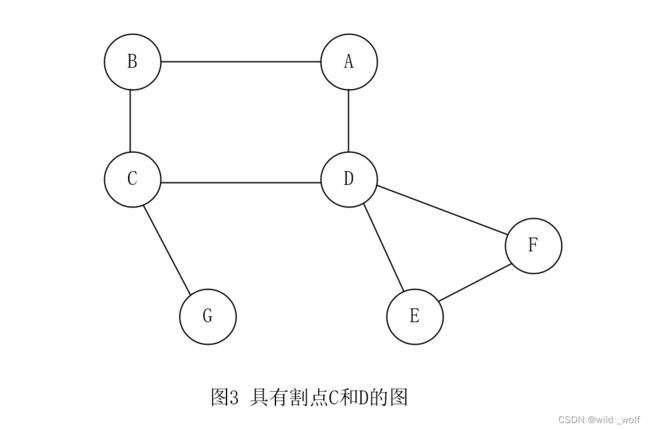
如果一个图不是双连通的,那么,将其删除使图不再连通的那些顶点叫作割点(articulation point)。 这些节点在许多应用中很重要。图3 不是双连通的:顶点C 和 D 是割点。
找出图中割点的算法
深度优先搜索提供一种找出连通图中的所有割点的线性时间算法。首先,从图中任一顶点开始,执行深度优先搜索并在顶点被访问时给它们编号。对于每一个顶点 v,我们称其先序编号(preorder number) 为 Num(v)。然后,对于深度优先搜索生成树上的每一个顶点 v,计算编号最低的点,我们称之为 Low(v),该点可从 v 开始通过树的零条或多条边,且可能还有一条背向边而达到。
从A、B 和 C 开始的可达到最低编号顶点为顶点1(A),因为它们都能通过树的边到 D,然后再由一条背向边回到 A。可以通过对该深度优先生成树执行一次后序遍历有效地计算 Low。根据 Low 的定义可知 Low(v) 是下列各项中的最小者:
- Num(v)。即不选取边
- 所有背向边(v, w) 中的最低 Num(w),即不选取树的边而是选取一条背向边。
- 树的所有边(v, w) 中的最低 Low(w),选择树的某些边以及可能还有一条背向边。
一个例子
图4 中的深度优先搜索树首先显示先序编号,然后指出在上述法则下可达到的最低编号节点。
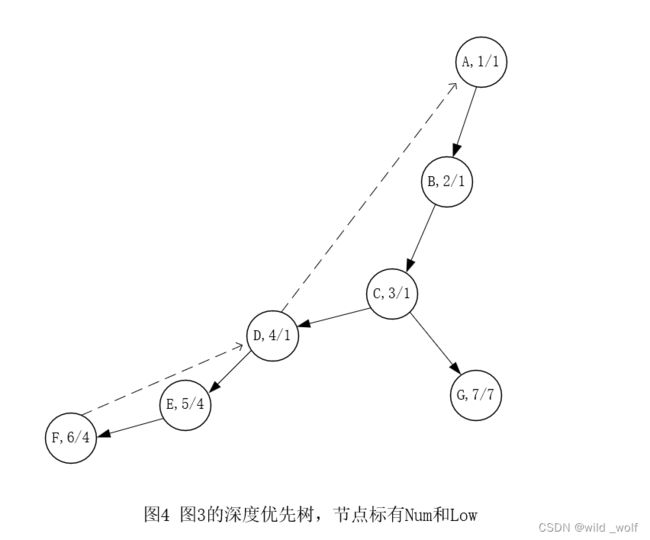
Low(v) 的计算:扫描 v 的邻接表,应用适当的法则,并记住最小者。所有的计算花费 O(|E|+|V|) 时间。
剩下的就是利用这些信息找出所有的节点。根是割点当且仅当它有多于一个的儿子,因为如果它有两个儿子,那么删除根则使得不同子树上的节点不连通;如果根只有一个儿子,那么除去该根只不过断离该根。对于任何其他顶点 v,它是割点当且仅当 v 有某个儿子 w 使得 Low(w) ≥ Num(v)。 在图4 中,D有一个儿子 E,且 Low(E) ≥ Num(D),二者都是4,对 E 来说只有一种方法到达 D 上面的任何一点,那就是通过 D。类似的,C 也是一个割点,因为 Low(G) ≥ Num©。
最后,给出该算法实现的伪代码。设 Vertex 包含数据成员 visited(初始化为false)、num、low 和 parent。为给先序遍历编号 num 赋值,还要有一个(Graph)类变量 counter,其初始化为 1。该算法可以通过执行一次先序遍历计算 Num,而后再执行一趟后序遍历计算 Low 来实现。
对顶点的 Num 赋值的例程:
/**
* 给num 赋值并计算parent
*/
void Graph::assignNum(Vertex v)
{
v.num = counter++;
v.visited = true;
for each Vertex w adjacent to v
if (!w.visited)
{
w.parent = v;
assignNum(w);
}
}
计算 Low 并检验是否割点的伪代码:
/**
* 给 low 赋值,并对割点进行检测
*/
void Graph::assignLow(Vertex v)
{
v.low = v.num; //法则1
for each Vertex w adjacent v
{
if (w.num > v.num) //前向边
{
assignLow(w);
if (w.low >= v.num)
cout << v << " 是割点!" << endl;
v.low = min(v.low, w.low); //法则3
}
else
if (v.parent != w) //背向边
v.low = min(v.low, w.num); //法则2
}
}
结合上面两个例程得到 findArt,在一次深度优先搜索汇总对割点的检测:
void Graph::findArt(Vertex v)
{
v.visited = true;
v.low = v.num = counter++; //法则1
for each Vertex w adjacent v
{
if (!w.visited) //前向边
{
w.parent = v;
findArt(w);
if (w.low >= v.num)
cout << v << "是割点!" << endl;
v.low = min(v.low, w.low); //法则3
}else
if (v.parent != w) //背向边
v.low = min(v.low, w.num); //法则2
}
}
欧拉回路
认识欧拉回路
图论经典问题:在图中找出一条路径,使得该路径访问图的每条边恰好一次。该问题在1736 年由欧拉解决,它标志着图论的诞生。根据特定问题的叙述不同,这种问题通常叫作欧拉路径(Euler path)(有时称欧拉环游(Euler tour)或欧拉回路(Euler circuit))问题。虽然欧拉环游和欧拉回路问题稍有不同,但它们有相同的基本解法。
其终点必须终止在起点上的欧拉回路只有当图是连通的并且每个顶点的度(即经过顶点的边的条数) 是偶数时才可能存在。而且还可以以线性时间找出这样一条回路。
就是说,所有顶点的度均为偶数的任何连通图必然有欧拉回路。
找出欧拉回路的算法
假设知道存在一条欧拉回路,基本算法是执行一次深度优先搜索。但我们可能只访问了图的一部分而提前返回到起点。如果从起点出发的所有边均已用完,那么图中就存在有的部分遍历不到。最容易的补救方法是找出含有尚未访问的边的路径上的第一个顶点,并执行另外一次深度优先搜索。这将得到另外一条回路,我们把它拼接到原来的回路上。 继续该过程知道所有的边都被遍历到为止。
一个例子
考虑图5 中的例子,容易看出,这个图有一个欧拉回路。设从顶点5 开始,我们遍历 5、4、10 、5,此时已无路可走,图的大部分都还未遍历到。情况如图6 所示。
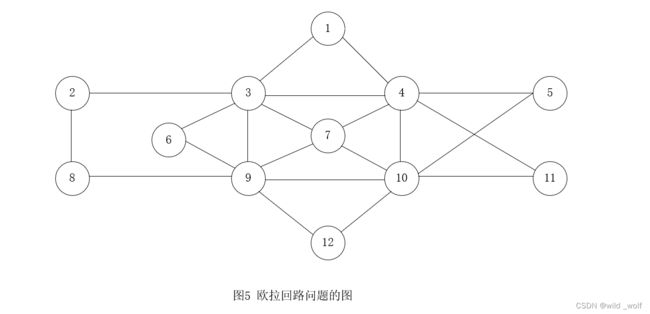
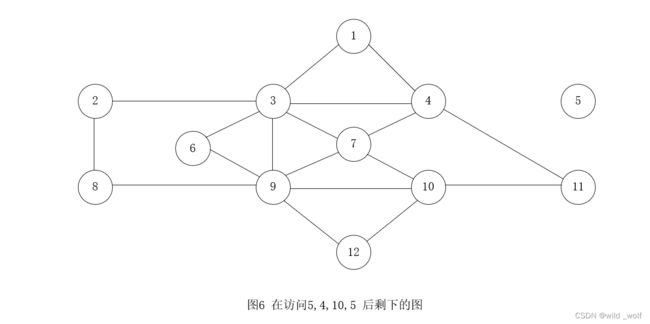
此时,我们从顶点4 继续进行,它仍然还有没用到的边。结果,一次深度优先搜索又得到路径 4, 1, 3, 7 , 4, 11, 10, 7, 9, 3, 4。如果把这条路径拼接到前面的路径 5, 4 ,10, 5 上,那么就得到一条新的路径 5, 4, 1, 3, 7 , 4, 11, 10, 7, 9, 3, 4 ,10, 5。
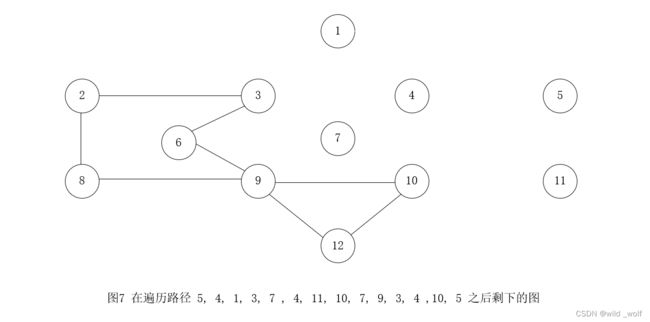
注意在图7 中,所有的顶点的度必然都是偶数,因此,我们保证能够找到一个圈再拼接上。具有未被访问的边的路径上的下一个顶点是顶点 3 ,此时可能的回路可以是 3, 2, 8, 9, 6, 3。当拼接进来以后,得到路径 5, 4, 1, 3, 2, 8, 9, 6, 3, 7 , 4, 11, 10, 7, 9, 3, 4 ,10, 5。
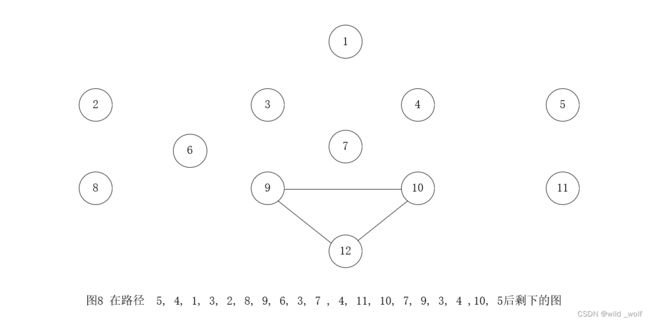
剩下的图在图8 中。在该路径上,具有未遍历边的下一个顶点是9,算法找到回路 9, 12, 10, 9。当把它拼接到当前路径时,得到回路 5, 4, 1, 3, 2, 8, 9, 12 ,10, 9, 6, 3, 7 , 4, 11, 10, 7, 9, 3, 4 ,10, 5。 此时所有的边都被遍历到,算法终止,我们就得到这样一条欧拉回路。
为使拼接简单,应该把路径作为一个链表保留。为避免重复扫描邻接表,对于每个邻接表必须保留一个指针,该指针指向最后扫描到的边。当一个路径拼接进来时,必须从拼接点开始搜索新顶点,从这个新顶点再进行下一轮的深度优先搜索。这将保证在整个算法期间对顶点搜索阶段所进行的全部工作量为 O(|E|)。若使用适当的数据结构,则算法的运行时间为 O(|E|+|V|)。
另外,一个非常相似的问题是在无向图中寻找一个简单圈,使该圈通过图的每一个顶点。这个问题称为哈密尔顿圈问题(Hamiltonian cycle problem)。
有向图
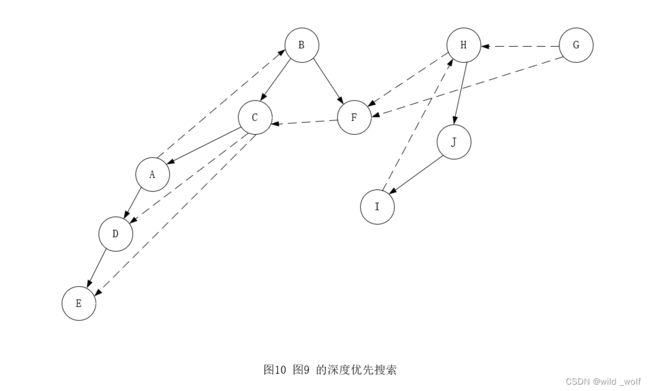
利用与无向图相同的思路,也可以通过深度优先搜索以线性时间遍历有向图。如果有向图不是强连通的,那么从某个节点开始的深度优先搜索可能访问不到所有的节点。这种情况下,我们在某个未做标记的节点处开始,反复执行深度优先搜索,直到所有的节点都被访问到。作为例子,考虑图9 所示的有向图。
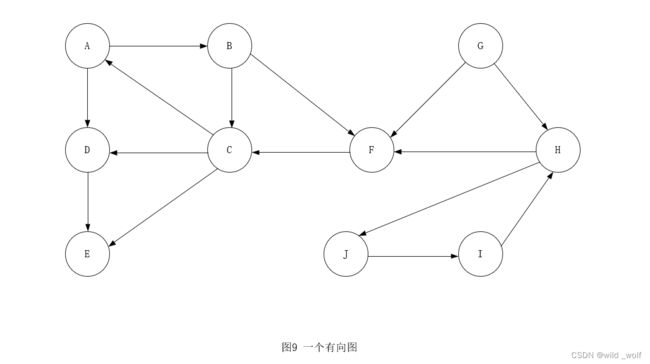
在顶点 B 任意地开始深度优先搜索。访问顶点 B, C, A, D, E 和 F。然后,在某个未访问的顶点再重新开始。任意地,在顶点 H 处开始,访问 J 和 I。最后,访问 G 点。则最终得到的遍历序列为:B, C, A, D, E, F, H, J, I, G。其对应的深度优先搜索树如图10 所示。
深度优先搜索的一种用途是检测一个有向图是否是无圈图,法则如下:一个有向图是无圈图当且仅当它没有背向边。此外,拓扑排序也可以用来确定一个图是否是无圈图。进行拓扑排序的另一种方法是通过深度优先生成森林的后序遍历给顶点指定拓扑编号 N, N-1, … , 1。只要图是无圈的,这种排序就是一致的。
查找强分支
通过执行两次深度优先搜索,可以测试一个有向图是否是强联通的,如果它不是强连通的,那么实际上可以得到顶点的一些子集,它们到自身是强连通的。
首先,在输入图G 上执行一次深度优先搜索。通过对深度优先生成森林的后序遍历将 G 的顶点编号,然后再把 G 的所有的边反向,形成 Gr。图11 代表图9 所示的图 G 的 Gr。
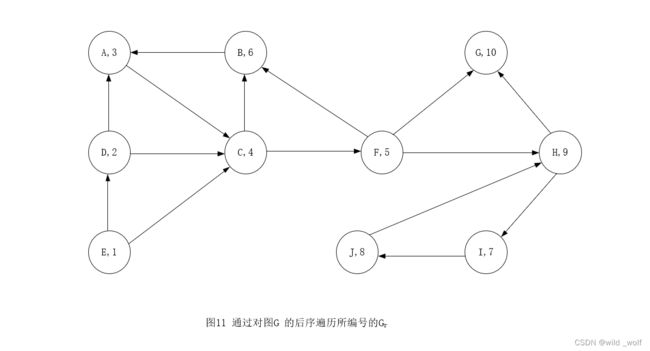
该算法通过对 Gr 执行一次深度优先搜索而完成,新的深度优先搜索总是在编号最高的顶点开始。于是,在顶点 G 开始对 Gr 的深度优先搜索,G 的编号是10。但该顶点不通向任何顶点,因此下一次搜索在 H 点开始。这次调用访问 I 和 J。下一次调用在 B 点开始并访问 A、C 和 F。此后的调用是 dfs(D) 以及最终调用 dfs(E)。在该深度优先生成森林中的每棵树均形成一个强连通的分支。因此,对于这个例子,这些强连通分支为 {G}, {H, I, J}, {B, A, C, F}, {D} 和 {E}。
dfs简单应用–部分和问题
给定整数 a1, a2, …, an,判断是否可以从中选出若干数,使它们的和恰好为k。
解题代码
//输入
int a[MAX_N];
int n,k;
//已经从前i项得到了和sum,然后对于i项之后的进行分支
bool dfs(int i,int sum){
//如果前i项都计算过了,则返回sum是否与k相等
if(i==n) return sum==k;
//不加a[i]
if(dfs(i+1,sum)) return true;
//加a[i]
if(dfs(i+1,sum+a[i]) return true;
//无论是否加上a[i]都不能凑成k就返回false
return false;
}
void solve(){
if(dfs(0,0)) printf("Yes\n");
else printf("No\n");
}
创作不易,如果这篇【文章】有帮助到你,希望可以给作者点个赞,您的鼓励是我最大的动力!