常见机器学习模型(一)—— 贝叶斯分类器
十大经典模型
在正式开始之前我们先来看一下十大经典的机器学习模型,这些模型给后来的机器学习发展奠定了基础,后续的发展也总能看到它们的影子,
- 分类算法:C4.5,朴素贝叶斯(Naive Bayes),SVM,KNN,Adaboost,CART。(有监督学习,有label)
- 聚类算法:K-Means,EM。(无监督学习,无label)
- 关联分析:Apriori。(啤酒和尿布放在一起销量更好的经典案例)
- 连接分析:PageRank。(找节点与边,获得对应权重)
在此也列出常用算法所使用的工具包,以便后续查阅:
| 算法 | 工具 |
|---|---|
| 决策树 | from sklearn.tree import DecisionTreeClassifier |
| 朴素贝叶斯 | from sklearn.naive_bayes import MultinomialNB |
| SVM | from sklearn.svm import SVC |
| KNN | from sklearn.neighbors import KNeighborsClassifier |
| Adaboost | from sklearn.ensemble import AdaBoostClassifier |
| K-Means | from sklearn.cluster import KMeans |
| EM | from sklearn.mixture import GMM |
| Apriori | from efficient_apriori import apriori |
| PageRank | import networkx as nx |
贝叶斯定理
贝叶斯是为了解决“逆向概率”问题而提出来一种方法,后来被我们称之为贝叶斯定理。他想找出一种方法:尝试在没有太多可靠证据的情况下,怎样做出更加符合数学逻辑的推测?
正向概率,比较容易理解,比如我们已经知道袋子里面有N 个球,不是黑球就是白球,其中M个是黑球,那么把手伸进去摸一个球,就能知道摸出黑球的概率是多少 => 这种情况往往是上帝视角,即了解了事情的全貌再做判断。
逆向概率,贝叶斯则从实际场景出发,提了一个问题:如果我们事先不知道袋子里面黑球和白球的比例,而是通过我们摸出来的球的颜色,能判断出袋子里面黑白球的比例么?
先验概率,通过经验来判断事情发生的概率。
后验概率,就是发生结果之后,推测原因的概率。
条件概率,事件A 在另外一个事件B已经发生条件下的发生概率,表示为P(A|B)
简单的贝叶斯公式:
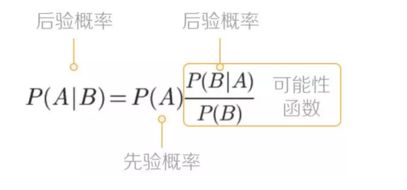
那么这个东西可以怎么理解呢?
可以去看这个问题下面的回答:怎样用非数学语言讲解贝叶斯定理(Bayes’s theorem)?
其中有一个关于“一个女生冲你笑之后喜欢你的概率”问题,理解起来会轻松很多。看完这个你应该能明白贝叶斯公式背后的思想:
我们先根据以往经验预估一个“先验概率P(A),然后加入新的信息(实验结果B),这样有了新的信息后,我们对事件A的预测就更加准确,即:
后验概率(新信息出现后的A概率) = 先验概率(A概率) x 可能性函数(新信息带来的调整)
贝叶斯学派的观点是,概率是个主观值,完全就是我们自己的判断,我可以先估计一个初始概率,然后每次根据出现的新情况,掌握的新信息,对这个初始概率进行修正,随着信息的增多,我就会慢慢逼近真实的概率。这个方法完美的解决了频率派的两个问题,我不用等样本累积到一定程度,先猜一个就行动起来了,因为我有修正大法,而且我也不关心是不是“足够多”,反正我一直在路上。
那么上面的贝叶斯公式你怎么记呢?
你可以这样来看:
P ( B ) ⋅ P ( A ∣ B ) = P ( A ) ⋅ P ( B ∣ A ) P(B)\cdot P(A|B)=P(A)\cdot P(B|A) P(B)⋅P(A∣B)=P(A)⋅P(B∣A)
稍微一变形就是我们的贝叶斯公式了。
再通过一个例子我们来感受一下这个定理带给我们的认知上的改变:
假设有一种病叫做“贝叶死”,它的发病率是万分之一,即10000 人中会有1个人得病。现有一种测试可以检验一个人是否得病的准确率是99.9%,它的误报率是0.1%
那么,如果一个人被查出来患有“叶贝死”,实际上患有的可能性有多大?
(查出患有“贝叶死”的准确率是99.9%,是不是实际上患“贝叶死”的概率也是99.9%?)
在10000个人中,还存在0.1%的误查的情况,也就是10个人没有患病但是被诊断成阳性。当然10000个人中,也确实存在一个患有贝叶死的人,他有99.9%的概率被检查出来
可以粗算下,患病的这个人实际上是这11个人里面的一员,即实际患病比例是1/11≈9%,那怎么通过贝叶斯的原理来求解后验概率呢?
假设:A 表示事件 “测出为阳性”, B1 表示“患有贝叶死”, B2 表示“没有患贝叶死”
患有贝叶死的情况下,测出为阳性的概率为P(A|B1)=99.9%
没有患贝叶死,但测出为阳性的概率为P(A|B2)=0.1%
患有贝叶死的概率为 P(B1)=0.01%
没有患贝叶死的概率P(B2)=99.99%
那么我们检测出来为阳性,而且是贝叶死的概率P(B1,A)=P(B1)*P(A|B1)=0.01%*99.9%=0.00999% ≈0.01%
P(B1,A)代表的是联合概率,同样我们可以求得P(B2,A)=P(B2)*P(A|B2)=99.99%*0.1%=0.09999% ≈0.1%
那么,检查为阳性的情况下,患有贝叶死的概率,即P(B1|A):
检查出是阳性的条件下,但没有患有贝叶死的概率为:
0.01%+0.1%均出现在了P(B1|A)和P(B2|A)的计算中作为分母,称之为论据因子,也相当于一个权值因子。
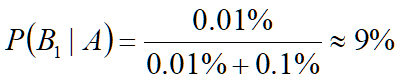
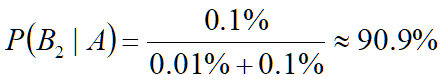
通过上面的例子我们可以总结出贝叶斯公式:
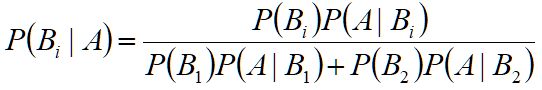
从而我们可以得到通用的贝叶斯公式:

朴素贝叶斯
朴素贝叶斯,它是一种简单但极为强大的预测建模算法。之所以称为朴素贝叶斯,**是因为它假设每个输入变量是独立的。**这个假设很硬,现实生活中根本不满足,但是这项技术对于绝大部分的复杂问题仍然非常有效。
朴素贝叶斯模型由两种类型的概率组成:
1、每个类别的概率P(Cj);
2、每个属性的条件概率P(Ai|Cj)。
什么是类别概率:
假设我有7个棋子,其中3个是白色的,4个是黑色的。那么棋子是白色的概率就是3/7,黑色的概率就是4/7 => 这个是类别概率
什么是条件概率:
假设我把这7个棋子放到了两个盒子里,其中盒子A里面有2个白棋,2个黑棋;盒子B里面有1个白棋,2个黑棋;那么在盒子A中抓到白棋的概率就是1/2,抓到黑棋的概率也是1/2。
=> 这个就是条件概率,也就是在某个条件(比如在盒子A中)下的概率
朴素贝叶斯分类器
离散值处理
举例说明:
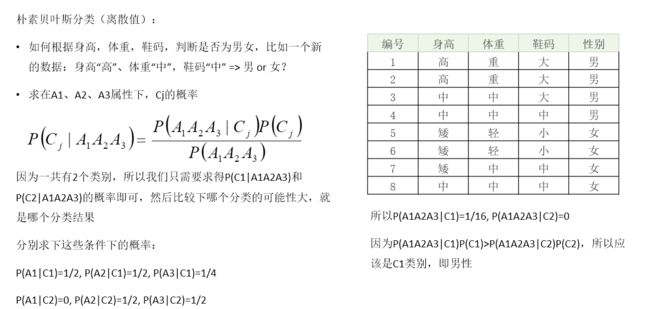
可以看到离散值的处理是直接求某一事件发生概率相乘之后对比大小得出结果。
连续值处理
举例说明:

可以看出,连续值的处理上它并没有将连续值分段划分成离散值然后处理,而是直接求了一个正态分布的概率密度。在此需要补充的是我们用的sklearn中有三种分布:正态分布、多项式分布、贝努力分布(0-1分布)。
贝叶斯分类器的应用与训练
那么总的来说,朴素贝叶斯分类器能做什么了?
朴素贝叶斯分类器常用于文本分类,文本过滤、情感预测、推荐系统等,尤其是对于英文等语言来说,分类效果很好。
朴素贝叶斯分类器的训练与实践大概分为三个步骤:
准备阶段,需要确定特征属性,属性值以及label => 训练集。
训练阶段,输入是特征属性和训练样本,输出是分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率。
应用阶段,使用分类器对新数据进行分类。
如下图:

具体实现可以参见我的后续文章。
参考文章:
朴素贝叶斯分类:原理朴素贝叶斯分类:原理
怎样用非数学语言讲解贝叶斯定理(Bayes’s theorem)?