智能化软件开发微访谈·第十九期暨2022新年特辑:软件智能化开发:进展与挑战...




CodeWisdom
智能化软件开发沙龙是复旦大学CodeWisdom团队参与组织的专注于代码大数据与智能化软件开发的学术和技术沙龙,面向相关领域的学术界研究者和工业界实践者,通过各种线上和线下交流活动促进学术研究与实践技术的发展。微访谈是智能化软件开发沙龙依托沙龙微信群开展的线上交流活动,其形式是围绕某一具体话题邀请嘉宾进行在线访谈并与微信群成员互动。

软件智能化开发·进展与挑战


智能化软件开发微访谈·第十九期
暨2022新年特辑


背
景
介
绍

随着开源和企业软件项目中代码、文档等相关数据和资源的积累,数据驱动软件智能化开发逐渐成为学术界和企业界关注的一个热点问题。深度学习技术被广泛应用于代码和文档等软件开发数据分析,实现API与代码推荐、代码补全、代码生成、缺陷修复等智能化支持。软件工程、程序设计语言、人工智能等相关领域中发表了大量的研究论文,许多企业已经开始探索相关技术的实践应用,同时还涌现了一批软件智能化开发方面的初创企业。
软件智能化开发承载着软件工程领域长久以来所追求的“软件自动化”的发展目标。如今2021已成过去,2022大幕开启,软件智能化开发在研究和实践方面取得了什么样的进展,未来将向何处发展,还存在哪些问题和挑战?
围绕这些问题,本次微访谈新年特辑邀请了来自学术界和工业界的知名专家进行访谈,盘点过去一年的进展,梳理接下来的研究和实践探索方向,共同描绘软件智能化开发的未来愿景。

主
持
人

彭鑫
复旦大学计算机科学技术学院教授

访
谈
嘉
宾

谢涛
北京大学计算机学院讲席教授
高可信软件技术教育部重点实验室(北京大学)副主任

王千祥
华为云PaaS技术创新LAB主任
中国计算机学会软件工程专委副主任

张洪宇
澳大利亚纽卡斯尔大学副教授

邢振昌
澳大利亚国立大学计算机学院副教授

李戈
北京大学计算机学院副教授

楼建光
微软研究院首席研究员

熊英飞
北京大学计算机学院副教授

甄焱鲲(花名:甄子)
阿里前端委员会智能化方向负责人

张玉明
阿里巴巴高级技术专家

访
谈
主
题
软件智能化开发:进展与挑战
01
近两年软件智能化开发(包括API与代码推荐、代码补全、代码生成、缺陷修复等各个方面)在研究和实践上取得了什么样的进展?特别是有哪些突破性的进展?
02
深度学习在软件智能化开发方面得到了广泛应用,那么通过不断改进代码表示、模型设计并增大训练数据量可以在多大程度上提升软件智能化开发的水平?近一年火热的包含巨量参数的大模型在这个方面潜力如何?深度学习技术在软件智能化开发方面是否存在“天花板”?
03
知识在软件智能化开发中扮演着什么样的角色?是否有可能利用知识来提升现有的软件智能化开发水平?
04
近两年流行的低代码/无代码开发大量采用了特定领域语言(DSL)以及基于模型的可视化编程的技术路线,那么低代码/无代码开发与软件智能化开发是什么样的关系?软件智能化开发技术在低代码/无代码开发中扮演着什么样的角色?
05
现有的软件智能化开发方法和技术在研究和实践中面临着哪些问题和挑战?展望未来,软件智能化开发在理论、方法和工程上还需要取得哪些突破?未来有哪些有价值的研究和实践探索方向?

访
谈
记
录
Question 1
近两年软件智能化开发(包括API与代码推荐、代码补全、代码生成、缺陷修复等各个方面)在研究和实践上取得了什么样的进展?特别是有哪些突破性的进展?
谢涛:
在问题所罗列的方向上,后面李戈老师在代码补全上可以深入介绍一下这两年在这个方向上的进展。在API与代码推荐和缺陷修复上,我觉得这两年是有着增量式的进展,说不上突破性进展。在API与代码推荐上,我觉得获得大进展的一个拦路虎是是否且如何能给到推荐引擎足够、充分的输入(显式的比如待实现的代码功能等、隐式的比如待实现代码周边的上下文等),二是是否且如何能让使用推荐引擎的开发者理解并“明智地”从推荐结果中选择出是开发者真正需要的API与代码。缺陷修复有着类似的拦路虎:一是是否且如何能获得足够强大的测试用例(既包括测试数据又包括测试预言,后者尤其是难点)来判定生成的修复是不是“靠谱”,二是(在不能完全信任测试用例的情况下)是否且如何能让开发者理解并“明智地”接受/拒绝生成的修复。
在所列的几个方面,突破性的进展可能来自于代码生成。虽然代码生成也同样面临类似上面提到的拦路虎,基于大代码深度学习的微软GitHub的Copilot(https://copilot.github.com/)可以算是一个很吸引学术界和产业界眼球的进展。其让人比较惊叹的效果展现了预训练大模型应用到自动代码的进展。当然,其离在广泛领域达到产业界实用的目标还挺远,这个方向倒是让人眼睛一亮,往下走会很有希望。
观点讨论
@彭鑫(复旦大学):嗯,看起来软件工程领域在应用深度学习技术方面取得了一些进展,但可能突破性的进展可能还很难说。谢涛老师指出了两个根本性的困难。
@彭鑫(复旦大学):@谢涛@北京大学 两个拦路虎应该分别对应:用户(程序员)所能提供的输入(问题规约)以及对输出的消化吸收
@熊英飞(北京大学):@谢涛@北京大学
>> 一是是否且如何能获得足够强大的测试用例(既包括测试数据又包括测试预言,后者尤其是难点)来判定生成的修复是不是“靠谱”,二是(在不能完全信任测试用例的情况下)是否且如何能让开发者理解并“明智地”接受/拒绝生成的修复。
一号问题是修复社区一直在做的,主要是用各种统计模型估计补丁的概率,返回靠谱概率最高的。二号问题我们今年有一篇ICSME的论文专门讨论如何辅助程序员接受/拒绝生成的修复。
张洪宇:
谢谢彭老师。我认为这两年软件智能化开发方面的研究取得了很大进展,我们看到一些较新的深度学习技术,如预训练模型,自监督学习,小样本学习,元学习,对比学习,强化学习,多模态,多任务学习等等,被应用在各种软件智能化开发任务中(如代码表示,代码推荐,注释生成,缺陷修复等),取得了不错的效果。不过这些工作大部分是渐进式的改进工作,目前看还没有明显的“突破性的”进展。
邢振昌:
我提一下自己比较关注的两方面进展(应该还算不上突破性)吧。
一个是知识图谱方法在智能软件开发中应用。这个方向我从五六年前开始探索,和彭老师,夏老师有很多合作,研发了一些软件工程领域知识图谱构建方法和一些软件领域应用,比如基于知识图谱的智能问答,API/code推荐,API误用检测等等。刚刚段老师也转了两个知识图谱技术专利数量截屏,看起来也做了很多这方向的工作。不过相比于研究了10几年的data-driven方法,知识图谱方法还比较初步,但对智能开发有独特的贡献,比如可解释性分析。
另一个点是围绕人机交互GUI的智能分析,尤其是研发了non-intrusive的,就是不依赖app instrumentation的GUI分析技术,来提取和理解GUI components,structures,and semantics,从而支持软件生命周期中GUI设计,实现,测试和使用。我们团队在这个方向也有些工作,一些tool prototype可以在http://uied.online/尝试。从我个人体验来说,相对于围绕代码的工作,GUI分析的工作,往往会被认为是HCI community的事,投稿SE经常被认为是out of scope。我个人觉得GUI分析应该受到更多重视,因为是影响软件服务end users的。
李戈:
我今儿准备的回答都比较简单:
==取得了什么样的进展?==
关键词:【明显】
在研究上,AI新技术使技术指标【明显】提升;
在实践上,科研成果的实用性【明显】强;
观点讨论
@彭鑫(复旦大学):@李戈·北京大学 李戈老师总体乐观
熊英飞:
我来回答一下我熟悉的代码生成和缺陷修复领域吧。
基于自然语言的代码生成上,最近两年最显著的进展是各种大型预训练模型开始碾压之前的各种传统方法,代表工作是微软的Copilot,有试用过的同行应该能体会到其强大的生成能力。之前很多人研究什么样的神经网络结构最适合代码、如何把各种人类的知识嵌入神经网络,最后发现在大数据和大参数模型面前这些都不重要,数据和算力碾压一切。
在缺陷修复上,由于修复数据还做不到像代码数据那样丰富和易获取,所以暂时没有出现碾压型的预训练模型。不过,在缺陷修复上最近两年的一个明显趋势也是基于神经网络的缺陷修复正在取代传统修复方法。在两年内出现了十多篇采用神经网络进行缺陷修复的论文,其中,我们发表在FSE2021的Recoder是首个超过了传统启发式方法的神经网络缺陷修复方法,标志着基于神经网络的方法开始成为缺陷修复方法的主流。
观点讨论
@彭鑫(复旦大学):@熊英飞(北京大学) 熊老师的论断“最后发现在大数据和大参数模型面前这些都不重要,数据和算力碾压一切”
王千祥:
我谈一下企业界的2个主要进展。一个是关于代码生成的,一个是关于缺陷修复的,与熊老师回答的点相同:
1、代码生成方面,微软21年6月底推出的Copilot 我觉得可以算是一个突破性进展。 刚才谢涛老师和熊英飞老师都提到了。10月份的Github Universe 2021上,Github声称内部团队的30% 的新代码是在Copilot的帮助下完成的。而且Github社区中,Copilot的用户留存率超过了50%。不过Copilot生成的代码也受到了一些挑战。尤其是,纽约大学的一项研究发现,在一些场景中Copilot所撰写的代码中40%存在网络安全缺陷。
2、缺陷检查与修复方面,亚马逊20年7月推出了CodeGuru。亚马逊认为机器学习将使开发人员从日常的工作中解脱出来,比如代码审查和Bug修复等繁重工作,并且使他们能够更加专注于创造。亚马逊CTO Werner Vogels在21年12月发表的年度技术趋势预测中认为:人工智能支持的软件开发将占据主导地位。
楼建光:
我认同洪宇的说法,也是觉得基于深度学习的技术在代码搜索、推荐、代码补全、代码生成、代码修复等多个方面都取得了长足进步。特别是最近一年多,基于transformer深度网路的预训练超大规模模型展现出惊人的能力,例如非常著名的GPT-3自然语言模型可以生成非常逼真的自然语言文章,而基于相同架构的超大规模模型Codex在代码补全和代码生成上也取得了前所未有的准确率(在HumanEval上做到28%左右的Pass@1和72%左右的Pass@100)。Github推出的基于CodeX技术的Copilot编程助手测试版已经面向全球用户发布试用,其效果着实惊艳。其代码补全可以达到函数级,对于常用的行数少于20行的函数,其准确度已经挺高。基于预训练模型对领域特定语言(例如SQL)的精调模型已经可以做到比较实用的水平。我们研究组已经把成果成功放到Excel中,支持用户通过自然语言来分析Excel中的表格数据。
观点讨论
@彭鑫(复旦大学):@楼建光 嗯,上次在北京听你说了,很受震动
@李戈·北京大学:@楼建光 同时可以关注百度的2000亿参数模型——文心
@楼建光 :@李戈·北京大学 谢谢,他们开源了么?
@李戈·北京大学:@楼建光 我今儿也问了这个问题,但最终也没搞清楚。应该是以某种形式开源吧。
甄焱鲲:
总体来讲,近两年的大趋势是朝着大模型、大规模数据预训练发展。在大多数任务上,取得最好结果的基本都是预训练模型,包括CodeBERT、GraphCodeBERT、CodeGPT等。可以参考一下CodeXGLUE榜单。代码补全:表现最好的基本是预训练模型,比较少有方法和模型上的改进。现在的代码补全正在向着一句、多句的补全发展。实际工具有VS Code中的IntelliCode (FSE 2020)、基于GPT3的GitHub Copilot。GitHub Copilot实际体验非常好,能够补全大段的代码,可以说是第一个能够补全大段代码的实际效果可用的工具。代码生成:除了预训练模型之外,还有一些对方法和模型的改进。基于序列的生成近两年有由粗到细两步式生成(semantic scaffolds, ACL 2020)。基于树的生成包括对TranX模型的改进(ML-TranX, TranX-RL等)、TreeGen(AAAI 2020)、基于path的生成(Structural Language Model, ICML 2020)。但这一任务本身比较难,总体来说没有非常大的、突破性的进展。(如果把整句、多句代码补全也当做代码生成的话,Copilot也可以算代码生成在实际应用上的一个突破性进展)缺陷预测、定位与修复:这一领域由于数据集基本都很小,大部分工作都是对方法和模型的优化。总体来说,预测、定位和修复上进展都算不上有突破性的进展,修复方面有一些基于程序合成的方法进展不错,可以参考北大熊英飞老师组的一些工作:Generalizable Synthesis Through Unification,Black-Box Algorithm Synthesis — Divide-and-Conquer and More,Synthesizing Efficient Dynamic Programming Algorithms。
观点讨论
@甄焱鲲:imgcook.com 的设计稿生成代码也取得了不错的进展,在这里分享一些数据

张玉明:
谢谢 彭老师。在我看来软件智能化开发近两年发展相对于以往还是很迅速的,主要体现在各云厂商都加大了对这方面的投入,使其从学术界研究逐步转向为实践应用。比较有代表性的正如大家上面都提到的如微软的GitHub Copilot,使过去的单token补全直接过渡到了片段级代码补全。其次一些IDE内置的智能化开发功能以及最近阿里云发布的Cosy(为我们自己打个广告:))都表明AI在实际软件开发场景下正快速落地,这个过程主要得益于BERT、GPT等大规模预训练模型的出现和应用。
Question 2
深度学习在软件智能化开发方面得到了广泛应用,那么通过不断改进代码表示、模型设计并增大训练数据量可以在多大程度上提升软件智能化开发的水平?近一年火热的包含巨量参数的大模型在这个方面潜力如何?深度学习技术在软件智能化开发方面是否存在“天花板”?
谢涛:
我的总体回答是:在适合采用基于大训练数据量的深度学习的若干软件智能化开发任务上,水平提升的程度会随着深度学习技术的进步(比如最近的大模型)和训练数据量的增大而比较大幅度地提升。在这些任务上,我很看好大模型的潜力。不过深度学习技术在软件智能化开发方面也存在“天花板”。如下我展开解释。
首先,我们各种软件智能化开发任务里面只是有一些是可以被转化为分类问题(比如代码克隆检测、代码缺陷检测等)或者是特定的生成问题(比如代码补全、代码生成、代码注释生成等),这些任务可能会适合采用基于大训练数据量的深度学习。而还有很多软件智能化开发任务是没法转化为深度学习问题的。
其次,不少用深度学习解决某些特定软件智能化开发任务需要较高质量的大规模手工标注数据,获取这样的数据不太现实且需要付出高的代价。即使是基于开源代码数据,谁来去标注?谁来买单?如何保障标注的质量?这都是很开放、很有挑战的问题。开源代码片段的注释标注就是这样一个具体的例子。
最后,在如上我回答第一个问题的时候也提到,一是如何给这些深度学习系统提供高质量的用户“输入”(比如用自然语言去刻画待生成代码需要满足的需求等),二是如何让用户去理解、消化、判定深度学习系统生成的结果等,目前都是比较开放性、挑战性的问题。这第二点也涉及到深度学习系统的可信度,这是人工智能领域的热门话题,在其被应用到软件智能化开发任务中也是一个重要话题。
观点讨论
@彭鑫(复旦大学):嗯,看起来一方面对基于深度学习的智能化开发水平的提升有信心,另一方面开发人员也不用担心饭碗问题
@邢振昌(ANU):@谢涛@北京大学 我想请问一下谢老师,您认为什么性质的软件智能化开发任务无法转化为深度学习问题呢?
@谢涛@北京大学:@邢振昌 (ANU) 比如我们在开发过程里面要采用的设计策略,影响到采取的设计策略因素很多,这些因素不见得在已有数据里能体现。
@邢振昌(ANU):@谢涛@北京大学 有道理,是否可以说是更多需要人智能的策略问题?
张洪宇:
我觉得大模型有很大的潜力。GPT-2有1.5 billion参数,GPT-3有175 billion 参数,据说GPT-4有100 兆(Trillion)的参数,是GPT3的500倍。这些包含巨量参数的大模型可以学习很多复杂问题,效果也不断提升。我想大模型是需要的。一个简单的,参数不多的线性模型是学不会复杂的分类和生成问题的。
关于是否有天花板的问题,我觉得目前的很多工作能帮助程序员解决编程中的各样accidental complexity,如何能更好的解决实质性问题(essential complexity) 还有待观察。刚才提高GitHub 团队使用Copilot也只是生成了30%代码。
邢振昌:
我认为深度学习的输入是软件工程产生的各种artifacts,尤其关注的code,program execution等等数据。这种输入数据其实就限定了深度学习的天花板,因为这些artifacts是软件工程的outcomes,就是果,从这些果学到的东西让我们知其然,比如各种coding or error patterns,但要知其所以然是深度学习就很难达到了。这就需要其他技术补充,比如知识图谱方法就有潜力提供这个所以然,就是可解释性。近期也出现一些可解释性预测工作,但重点还是在model or data可解释性,除此之外我们还应该关注软件工程task和知识本身可解释性。
观点讨论
@楼建光:@邢振昌(ANU) 数据问题确实是一个瓶颈。
李戈:
==通过..在多大程度上提升..水平?==
1、不能“鲁莽地”增大训练数据量,数据与应用场景应该匹配,数据多样性很重要;
2、不能仅依赖于“改进代码表示、模型设计”,参数量、数据、模型都需要;
3、多大程度上提升 取决于 当前能提供多少“计算力”【计算力仍是制约智能化水平的重要因素】;
==巨量参数的大模型..潜力如何?==
1、潜力很大
2、成本很高
3、因为【计算很贵】
==深度学习..是否存在“天花板”?==
有,天花板可能来源于:
1、计算力
2、多样化数据积累
3、深度学习的低效学习能力
观点讨论
@彭鑫(复旦大学):@李戈·北京大学 听起来感觉主要是个成本问题,而不是可行性问题
@熊英飞(北京大学):成本问题也能量变引起质变啊
熊英飞:
Copilot在生成能力上确实有令人惊艳的表现,但我猜测超大规模预训练模型可能已经接近天花板,一些采用更大量参数的探索并没有报出来显著更好的效果。另外,正如我之前谈到的,这些模型依赖于数据和算力,这也导致这些模型的应用显著受限。
1. 数据:很多领域并没有大数据。比如,在缺陷修复领域,高质量的缺陷修复提交的数量远远少于代码的数量,很多类别的缺陷在历史上只出现过一两次。这就导致较难为这些领域构造超大规模的预训练模型。一方面数据量不需要那么多参数来概括,另一方面重复度较少的数据也使得模型不容易收敛。
同时,这些领域和通用的代码补全可能有很大差别,不能简单把GPT-3这样的模型拿过来重新训练。比如,在缺陷修复的时候,修复代码是在之前的代码上产生修改,而GPT-3的预训练场景和这样的任务差别巨大。采用大型预训练模型对这些问题的提升有多大很难说。
2. 算力:目前我们实验室已经找不到服务器有能力重新训练GPT-3了。而我从工业界听到的一些反馈是,类似Copilot这样的模型计算资源消耗过大,能找到的商业模式都是亏本的。这就极大的限制了这些模型的应用场景。实际上,对于代码补全,最理想情况是在单机上用不影响其他操作的计算资源就能实现补全,如何剪裁大模型达到这个要求是一个难题。
另外一个常常被大家忽视的问题是基于大模型的代码生成的速度。由于神经网络的复杂性,网络做一次预测已经显著慢于一些基础机器学习模型(如SVM),而代码生成通常是用一个搜索算法搜索出最优代码序列的过程,导致一次生成可能需要数秒甚至数分钟的时间。在一些效率敏感的任务中(比如程序合成比赛SyGuS),大型神经网络都很难被用起来,我们之前在这个任务的一些工作都是采用基础统计模型(OOPSLA20)或者奥卡姆剃刀这样的通用原则(OOPSLA21)。
观点讨论
@李戈·北京大学:实验室重新训练GPT-3基本不可能,太费钱了
王千祥:
目前深度学习在软件开发方面的应用仍然处于探索阶段。对于不同的任务,如何对代码进行embedding,如何更好地对代码进行建模,都还没有明确的最佳方案。代码大模型的探索也还比较初步,到底潜力有多大,还需要实验结果来说话。
深度学习技术在软件智能化开发方面是存在天花板的:对于重复性的、已经有人做过很多实例的开发任务,深度学习可以有效地学习到并融入到模型中。但软件开发本质是一个需要大量创新的过程,在软件开发领域,由于新运行环境、新语言的不断出现,因此总是会有许多新任务,没有可以学习的案例,或者样例很小。这时候深度学习能提供的能力就很有限了。
尽管如此,如果深度学习确实能够消除大量的重复性工作,提升软件开发生产力,这个贡献也是非常大的。尤其是对于新手,帮助更大。
楼建光:
我同意老师们讲的这个数据问题和成本问题,确实是一个瓶颈。但是,尽管目前的模型参数已经很大了,但是应该说目前模型参数往上涨还没有碰到天花板。最近DeepMind试图通过实验验证来回答这个问题,发现增大模型参数还可以继续改进阅读理解、事实问答等很多方面的能力,但是数学和逻辑推理的能力提高不多。根据OpenAI在文章中对Codex的介绍,我们可以大胆推测模型规模对代码生成准确率的提升作用看上去还远没有达到天花板。当然,目前的大模型也存在严重的问题,例如对大量优质数据和大规模计算的依赖; 例如模型是一个黑盒子,不可解释;等等。
在大数据和大计算面前,发现我们原来挖空心思想的那些精巧设计,好像都没有用了。
观点讨论
@楼建光:最近MIT和哈佛大学的学者发表了一篇文章,结论是“We now demonstrate that a neural network that is both pre-trained on text and fine-tuned on code can successfully answer advanced university-level mathematics problems by program synthesis. ”
@楼建光:据说在陶哲轩得90分的考题上,模型得到100分
@李戈·北京大学:@楼建光 university-level mathematics problems 这个限制太委婉玄妙了:)
@熊英飞(北京大学):@楼建光 做题和实际求解数学问题我感觉还不完全一样,做题重复性高,用到真正的未知问题上不知道效果如何。
甄焱鲲:
从GPT3和Copilot的实际效果来看,大模型的潜力还是非常大的,虽然对算力的要求也很高。深度学习技术在软件智能化开发方面是否存在“天花板”这个不敢下定论,但至少从目前来看,很多任务上受限于数据集等原因,远远还没挖掘出深度学习的全部潜力,还存在很大的提升空间。我们在内部实际项目中收集高质量代码进行结构化存储,并引入版本管理试图用 CDML 的方式持续迭代我们的数据集和算法模型,未来希望能够提供代码资产类开源数据集来降低研究的成本。
张玉明:
基于海量代码数据训练的深度学习模型说到底还是基于数据的“暴力美学”,通过大量无标注数据让模型先学习“常识”,再针对具体场景使用少量有标注数据进行精调。因此,模型的泛化能力得到了极大地提升,进而可以快速落地到具体的产业实际场景中并取得较好的应用效果,这是其最大潜力之处。现在大模型的训练和应用只能说是刚刚开始,潜力仍然很大。至于“天花板”,我当前能看到的有两方面:1.体现在算力上,我们已知的GPT-3这样的大模型的计算资源开销是非常大的,也就是说成本非常高,对于个人或中小企业、机构很难承担。2.以代码补全场景为例,从开发者实际使用感受来看,基于海量代码数据训练的深度学习模型,它在一些通用高频的编码场景效果会比较好,因为这类场景的代码是包含在训练集里面的,也容易抽取出代码范式,但是对于一些偏垂直业务型的代码其补全效果就不是很理想,很容易生成出不需要的代码块,因此与各种程序分析、语法分析等能力相结合也许可以突破纯深度学习技术的”天花板“,在这一点上我们阿里云代码平台团队也在探索尝试。
观众讨论
@张峰逸(复旦大学):感谢各位老师的精彩发言,很受启发!我有一个问题想要请教:如今像GPT3这样的超大规模预训练模型在代码生成等领域取得了碾压性的效果,那么对程序进行更深入的表示(如表示为数据流、控制流、编译时的IR等等)是否还有必要?如果我们基于树结构或图结果做预训练的话,相比于基于文本形式的预训练是否存在新的难点?谢谢!
@熊英飞(北京大学):第一个问题:更深入的表示可能需要更少的数据或者更少的计算资源。第二个问题我们想过,感觉方法上没有明显障碍,但最后没有尝试,因为穷。
@李戈·北京大学:这就像打仗一样,一方面得靠人多,另一方面,也得靠武器先进啊。
@张洪宇:@熊英飞(北京大学)也可能需要更多的数据以更充分的表示
@熊英飞(北京大学):@李戈·北京大学 这个比喻好,现阶段还处于堆人的阶段,或许到一定程度就靠武器先进了。
@彭鑫(复旦大学):那么如何理解 @楼建光 所说的“在大数据和大计算面前,发现我们原来挖空心思想的那些精巧设计,好像都没有用了。”代码表示和模型设计中哪些部分的改进是根本性的、无法靠大数据和大计算来弥补,哪些可以建光所说
@楼建光:其实这些问题大家都在尝试,主要还是怎么加入知识,加入什么知识的问题
@李戈·北京大学:@楼建光 这个涉及到整个AI的弱点,黑盒,黑盒不仅导致不可解释,更导致无法与其他方法对接。
@狄鹏(蚂蚁集团):@熊英飞(北京大学) 我们在尝试构建专用于分析的语言中间表达,某种程度上也是化简数据
@彭鑫(复旦大学):@李戈·北京大学 嗯,黑盒导致可组合性不足,没法想软件构件那样去组装
@楼建光:@彭鑫(复旦大学)现在感觉是没有足够数据的问题就用尽量加入知识,有足够数据的,模型就能干,当然算力也是一个约束
@张峰逸(复旦大学):我觉得像IR这样的表示形式可能会提供更高层次的抽象,一些代码操作(如type cast)可能反而在IR上表示的更清晰,但是相应的也确实会带来更高的数据获取以及训练成本
Question 3
知识在软件智能化开发中扮演着什么样的角色?是否有可能利用知识来提升现有的软件智能化开发水平?
谢涛:
知识在软件智能化开发中扮演着很重要的角色。一类是软件工程领域的知识,另外一类是特定应用领域的知识或者是通用的背景知识、常识。前一类知识对于提升现有的软件智能化开发水平的重要性好理解。后一类知识也很重要,比如前面我提到基于深度学习的代码生成需要用户提供的“输入”为自然语言的描述来刻画待生成代码的需求。用户提供的自然语言需求要很完备且含义做到self-contained是不现实的,这样应用领域知识和背景知识/常识就很重要。
知识的体现以及传达给软件智能化开发辅助工具的形式可以是显示的可以是隐式的。有不少我们国内学者的工作围绕知识图谱或知识驱动来去开展,比如我们北大谢冰老师、邹燕珍老师组的工作,我们复旦彭鑫老师组的工作等,有些工作是从现有的软件相关的数据中抽取其中所描述的知识,用知识图谱组织起来,还有些工作是能让人来主动、显示地把脑子里的知识提供给工具。我们最近和eBay王含章的团队合作的ASE 2021论文“Groot: An Event-graph-based Approach for Root Cause Analysis in Industrial Settings”提出了显示让人去给AIOps系统提供过往调试积累的知识,来更好做好根因分析。这是一个基于数据驱动结合知识驱动AIOps的例子。
总而言之,在支撑软件智能化开发上,我看好数据驱动结合知识驱动的技术路线。
张洪宇:
我认为知识肯定能提升现有的软件智能化开发水平。但是如果有大数据,很多“知识”应该可以通过机器学习,从数据中自动学到。正如刚才大家说的:“数据和算力碾压一切”,可能不一定需要人来提供知识。当然,在一些缺乏大数据的场景中,人工知识还是很重要的。
观点讨论
@彭鑫(复旦大学):@张洪宇 主要是通过机器学习的知识如何连接起来。例如针对代码的机器学习模型如何与针对海量互联网文本学习的模型结合起来,因为代码中蕴含的有些背景知识在互联网文本中可能有解释
@张洪宇:@彭鑫(复旦大学)ok,那"知识"是重要的。我们之前的研究显示理解token的意思(semantic understanding)对很多务都有提升效果。。
邢振昌:
以api推荐为例,目前关注点主要在提升ranking,ranking肯定是重要的,尤其是developers已经知道他要找到是什么的时候,就是known-unknowns,比如他知道要用什么,只是不记清细节了。但在更开放developers是unknown unknowns情况下,要是能让developers认识到为什么会推荐某个api,为什么会会有ranking,不同推荐apis之间关系和异同,对developers做出正确选择就很重要了。而后一种情况,只靠深度学习,提升ranking就不能满足information needs了,而相关api知识的分析和呈现就非常重要了。现有方法也不是完全不考虑知识角度,只是比较隐性间接,我们应该需要更显性直接的知识表示和分析方法,比如知识图谱。
观点讨论
@彭鑫(复旦大学):@邢振昌(ANU) 看起来主要是可解释性问题,这个可解释性不仅仅是对所产生的推荐结果的解释,还包括对周边上下文和上下游知识的解释
@邢振昌(ANU):@彭鑫(复旦大学)是的,还有常识知识,这个谢老师也提到了。
李戈:
==知识..扮演什么样的角色==
1、很重要
2、但目前还没发威
==是否有可能利用知识提升..智能化水平?==
1、有可能
2、但目前有点难,因为“Case by case”
观点讨论
@李戈·北京大学:给@彭鑫(复旦大学) 老师提供点儿料:我在搞深度学习之前,就是在搞知识。如果说基于深度学习的方法还处在初级阶段,那我觉得基于知识的方法还处在____阶段。
@邢振昌(ANU):@李戈·北京大学 可能是......阶段,还没成____呢
@李戈·北京大学:@邢振昌(ANU) 哈哈,看来这么想的不止我一个哈,握个手吧
熊英飞:
我理解这个问题是限定在基于神经网络的软件智能化开发中的。那么如前所述,有非常多的应用场景是没有大数据和大算力的,而问题领域的知识就可以在这些场景发挥作用。我们之前的很多工作(如TreeGen, AAAI20)就是系统性将代码的语法语义知识融合到基于神经网络的代码生成中,实验表明可以显著提升模型表现。
王千祥:
这个问题看来大家有共识:知识对于软件智能化开发肯定很重要。
但目前主要还是开发人员大脑中的知识在发挥作用。目前的工具对知识的运用还比较初步。尤其是,工具对知识的运用需要首先对开发相关的知识进行提炼、表示,然后才能应用起来。这里面有许多技术问题需要解决,而且需要结合具体的开发场景持续探索,估计是个长期的过程。
楼建光:
知识肯定还是非常有用的,可以与模型结合起来一起进一步提高系统性能。比如,sumit在oopsla2021上的文章就在介绍怎么将传统的基于知识规则的方法与大模型相结合来做程序合成。这个上面还有很大的值得深入探索的空间。我的研究组也采用了知识+模型的混合方法来提高程序生成系统的跨数据领域推广能力,解决很多实际应用场景中的具体问题,成功地将成果转化到产品中。
这里主要需要回答几个问题:1. 知识怎么表达?2. 知识怎么获取?3. 知识与模型的结合方式?其实,从本质上来说,用大数据来训练大模型也是一种知识提取和表达的过程,这个时候知识是用模型参数的方式隐式保存在模型中,与我们传统符号式(symbolic)的知识表达形成对比。最近我们研究院就对模型中知识是怎么被保存的这个问题进行了初步研究,得到一些很有意思的发现。两种知识的表达各有特点,要根据项目中具体情况下,根据它们的特点来合理选择,得到比较好的方案。一般来说,没有足够数据的问题就用尽量加入知识,有足够数据的,在算力允许的条件下,模型就能干。
甄焱鲲:
知识的应用一直被认为是走向认知人工智能的基础,为此学术界有一系列尝试早年的特征工程和专家系统近年的知识图谱构建-目前辅助理解最为真实可用的技术。最近的大规模预训练技术-目前研究最为火热的方向。GPT 系列,通过更大规模的参数量和更大的文本语料,加上少量领域打标的 Finetune 技术以期达到零样本学习的目标。核心就是通过大模型学习更为通用的知识。NLP 第四范式- Prompt,目的是期望将下游任务无缝衔接到预训练阶段,降低 finetune 和 pretrain 的不一致性。也有一些研究知识和软件智能化开发的paper,主要在代码生成领域更多一些。比如从API文档、Stack Overflow挖掘一些知识来进行代码生成。(Incorporating External Knowledge through Pre-training for Natural Language to Code Generation, ACL 2020)或者检索一部分代码作为额外信息来辅助代码生成,比如 emnlp retrieval_based code generation 我们与北大的研究过程中应用知识的尝试:整理业务代码中的变量语义表 + 机器翻译中的 memory + mechanism以及正在沉淀的针对阿里的 PRD 专用术语、业务领域模型上的关键概念等,都是为了进一步正确理解真实意图,从而在需求理解和代码生成中更准确的使用知识。
观点讨论
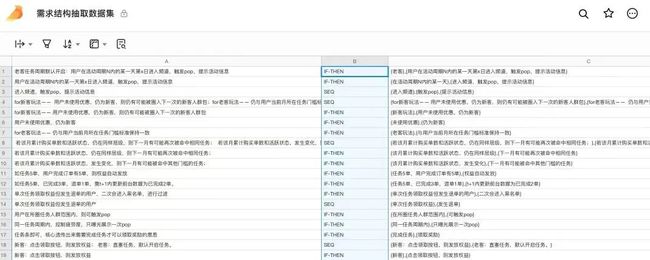
@甄焱鲲:类似上图这种
张玉明:
我这里举个不是很恰当的比喻,如果把软件开发产生的大量代码数据比作金矿,那么知识就是将一些粗加工的金条、金砖转变为一件件精美首饰的图纸和工艺流程。结合上一个问题的回答,目前基于大模型的深度学习技术仍是基于数据的学习,未来在软件智能化开发领域的技术趋势一定是数据+知识去驱动。针对代码数据来看其特点是碎片化、规模巨大、讲究逻辑精准性,软件智能化开发实现上需要充分考虑需求侧来自哪一特定业务领域以及相关工程实践等,唯有在当前的数据基础之上,去提取、融合多方面的知识信息才能持续有效的驱动智能化开发水平的进步。
彭鑫:
其实说到知识,还有一个问题可能绕不过去,那就是软件的“架构”和“设计”。在端到端的自动化完全接管“编程”这件事之前,软件还是需要人类架构师和设计人员根据自己的经验完成软件设计,而AI主导的代码生成和推荐只是在每个局部的模块中去填补一些具体实现。越到高层的设计,也是需要知识,不过如何获取和表示都是挑战,这些软件设计知识比概念化的常识知识更加难以抽取和表达。
观点讨论
@李戈·北京大学:@彭鑫(复旦大学) 嗯,这个的确是个很值得思考的问题。以前曾经有过一个想法,能不能把基于UML等的设计直接转成知识,这个积累起来很有用。
Question 4
近两年流行的低代码/无代码开发大量采用了特定领域语言(DSL)以及基于模型的可视化编程的技术路线,那么低代码/无代码开发与软件智能化开发是什么样的关系?软件智能化开发技术在低代码/无代码开发中扮演着什么样的角色?
谢涛:
我最近把软件的智能化创建仿照自动驾驶领域的L1-L5的等级划分也相应分为L1-L5等级。L5最高级别是“完全自动开发”,对应了我们国内提的“软件自动化”。L5其实已经没有开发者的手工“开发”成分了。而“低代码/无代码开发”还是需要手工“开发”的,只是这个开发过程不需要写代码(这种情况也就让开发者不需要懂得写代码)或者写很少的代码。总的来说,低代码/无代码开发的使用者懂应用需求,可能懂计算思维,也可能懂编程。像在Excel里编写公式,或现在流行的拖拽式应用搭建工具。软件自动化更进一步,使用者只需要懂应用需求,不一定需要懂计算思维,也不一定需要懂编程。像是Excel里的快速填充功能,不再需要公式,只需要给出少量示例即可自动完成内容填充。
和软件工程的目标类似,软件智能化开发技术可以用来去降低用于低代码/无代码开发的人力开销以及开发出来软件的质量。软件智能化开发技术也是使得软件的智能化创建级别从低级别(低代码/无代码开发目前大多所在的级别)提升到高级别,甚至L5(软件自动化),把“开发”去掉了。也许将来“低代码/无代码开发”会变成“低代码/无代码软件生成”,不需要开发了。
另外一个软件智能化开发技术可以辅助到低代码/无代码开发平台的地方是解决这些平台的“未知的未知”局限性。如下图来自于我最近的报告,里面提到的“面向智构件的开发”我在最后一个问题讨论的时候再解释。:)

观点讨论
@彭鑫(复旦大学):@谢涛@北京大学 目前业界实用的低代码开发平台似乎还是以Model-based和DSL路线为主导?智能化似乎还不明显?
@谢涛@北京大学:@彭鑫(复旦大学) 对的。现有大部分低代码、无代码平台主要是软件复用的思路,智能化成分偏少。也许微软的Power系列有一些智能化成分。@楼建光 有发言权:)
张洪宇:
我认为低代码/无代码开发在某些特定领域,如表格处理或Web/App编程中,有一定价值,软件智能化开发技术可以提供很多帮助,如UI生成,代码生成等。但我看到的一些低代码/无代码技术类似30年前的CASE技术,在通用的软件系统开发上,对程序员的帮助可能有限,需要继续研究。。
邢振昌:
低代码/无代码肯定要依靠某种智能开发技术。我觉得这里的关键是要搞清什么样的人需要什么低代码无代码服务。之前彭老师组织的低代码无代码微访谈,印象很深的一点就是低代码无代码服务对象是很广泛的,对developers适合的技术未必适合non-professional developers,比如scientists,对scientists适合的未必适合老年人使用computing services。所以在讨论技术方案之前,应该还有很多前期需求分析要做好,搞清谁需要什么样的低代码或是无代码,才能有的放矢的开发正确的技术。
李戈:
==低/无代码..与智能化开发什么关系?==
两个词,强调了不同方面:
1、低/无代码强调【结果】,智能化强调【手段】;
2、低/无代码不一定需要“狭义的智能化”,模型转换、组装等都可以实现;
3、智能化的目标“不只是”低/无代码;
==智能化..在低/无代码开发中..什么角色?==
智能化是低代码/无代码手段之一。两者关系如上所述。
熊英飞:
我对低代码/无代码的了解有限,主要来自于和美团工程师Conan在知乎上的一些交流。根据我有限的理解,低代码/无代码就是构建一个领域特定语言(可以是图形化的),使得不懂通用编程语言的人采用该领域特定语言也可以很容易地完成该领域的工作。那么这里的一个主要难题是如何构建出这样的DSL。这个问题在软件工程社区是经典问题,比如软件产品线的大量工作都是如何从已有代码中总结出一个软件产品线,而该产品线所使用的配置文件就是这样一个领域特定语言。不过,早期的研究大多比较初步,通常是一些原则指导程序员设计这样的领域特定语言,最近大家才开始研究如何自动设计领域特定语言。我们研究所谢冰老师和邹艳珍老师小组刚刚毕业的沈琦博士,其博士论文就是如何从代码中依靠统计自动生成这样的领域特定语言。
王千祥:
我和洪宇的观点比较接近:现在的许多低代码/无代码主要适用于特定的开发场景,尤其是业务功能相对稳定的领域。这个可以利用智能化开发技术相关,但也不是一定要利用智能化技术。比如有一些采用可视化技术就可以实现,展示无代码的效果。这个与李戈老师的观点比较接近。
将来,相信软件智能化开发技术可以在低代码/无代码开发中发挥很重要的作用,扩大适用的场景。
甄焱鲲:
使用DSL或者可视化编程本质上是在用户和编程语言之间提供了一个“中介”,给用户提供了一个比编程语言更简单的“开发方式”,实际上后端还是需要把用户输入的DSL或可视化模型,基于平台开发时编写好的规则转换成代码。这可能并没有运用到太多智能化开发的内容。我们与北大合作的成果在数据集方面的部分进展:第一个工业级可用的前端字段绑定的表达式级别的代码生成数据集-已开源:https://tianchi.aliyun.com/dataset/dataDetail?dataId=107819
和@李戈·北京大学 老师的合作成果:
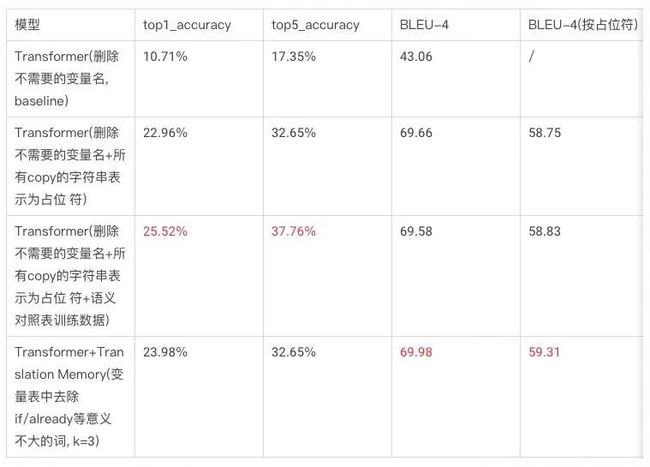

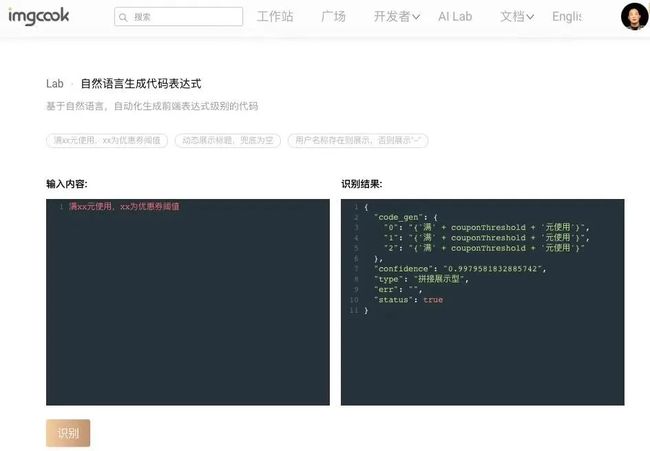
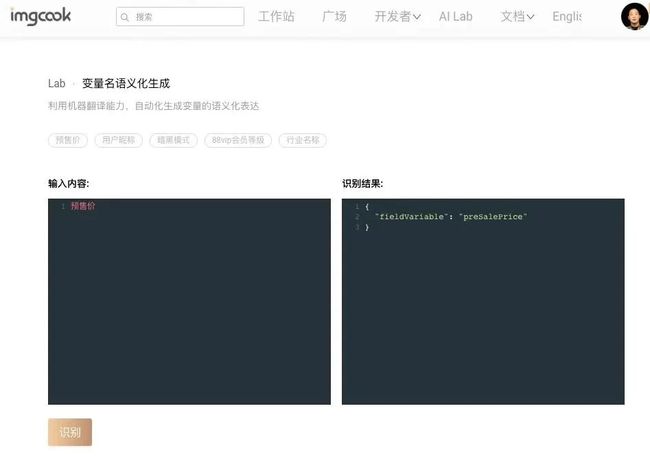
张玉明:
首先,在我看来无论是低代码/无代码开发还是软件智能化开发核心要解决的问题都是降低软件开发成本,提升软件开发及交付效率,因此从目标上来看是一致的。其次,二者的关系以及各自所扮演的角色我认为在一些情况下可以做到互补。这主要体现在三方面:1.从系统规模来看,低代码/无代码开发当前还主要围绕在“轻应用”开发维度,其还不能很好支撑复杂、大型系统的开发问题,这仍需要专业开发人员使用传统+智能化开发工具来完成;2.从用户开发过程来看,低代码/无代码开发实际上是用户基于对业务逻辑、流程的理解通过平台不断沉淀的组件进行组装式开发,而刚才提到目前的深度学习技术在业务代码开发上是弱项,这正是低代码/无代码开发平台可以进行弥补的,反过来AI能帮助低代码/无代码平台维护者更快的编写并沉淀通用组件;3.从低代码/无代码平台建设上来看,基于DevOps视角,AI可以应用于需求识别、设计、开发、日志分析、问题定位等各阶段。单纯以智能化开发来讲,能够将代码补全、生成的相关技术应用到低代码/无代码开发中各个组件之间的关联上,使用者只需要输入少量的文字描述,平台就能把需要用到的组件筛选并推荐出来、并且建立相关连接,大幅提升用户开发效率。
观点讨论
@彭鑫(复旦大学):@张玉明(阿里) 互补性的说法有道理。低代码/无代码现在应该主要面向业务人员,而智能化开发主要面向专业程序员。
Question 5
现有的软件智能化开发方法和技术在研究和实践中面临着哪些问题和挑战?展望未来,软件智能化开发在理论、方法和工程上还需要取得哪些突破?未来有哪些有价值的研究和实践探索方向?
谢涛:
我在上面其它问题的回答中已经大体覆盖了面临的主要问题和挑战,这里不再重复。
至于未来需要取得的突破以及有价值的研究和实践探索方向,除了前面我提到的点,我认为一个未来重要方向是“面向智构件开发”(我前面报告ppt截图里提到)的软件开发方法学。这是我们去年底提出来的,首次提出是在去年的云栖大会主会场我做的一个主旨报告上。简单来说就是“搭积木”,用复用、组装、集成来进一步提高软件开发效率。和以往不同的是这些“积木”(也就是构件)中很多是被智能化地创建出来的,不需要人手动开发。另外,一些复用、组装、集成也被智能化地自动进行,不需要投入人力。不过,“搭积木”创建出整个软件系统的过程中仍然需要有人的参与去做开发,而面向智构件开发就是指导人在这如何去开发的方法学。
另外,就是贯彻“getting real:real data, real problems, real users, real tools”,也就是去让研发成果真正产生产业影响。大约10年前,2011年我学术休假年到微软亚洲研究院软件解析学(Software Analytics)组访问,和组里张冬梅博士、楼建光博士等一起合作去定义并推动软件解析学这个领域,所强调很重要的一点就是如上所述的“getting real”。
张洪宇:
目前有大量的软件智能化开发模型、工具被提了出来,这些模型的有效性还有待充分验证。我们的研究发现(ICSME’21,ICSE’22),有很多因素会对模型的评估有影响,如评价指标,数据质量,数据特征,数据预处理,模型训练方式等。举例来说,对于一个代码注释生成模型,目前有很多相似但不同的BLEU指标,这些指标在一些论文中常常不加区分,都叫做BLEU。但是它们的值不一样,对结果的理解有很大影响。
关于未来,有很多工作可以做,比如提升模型的准确性,可解释性等。学术界和产业界可以在这方面多合作交流,争取早日开发出能被广泛使用的实用工具出来,当然距离完全实现软件智能化开发的愿景还有很长路要走。大家在新的一年内继续努力
邢振昌:
如何突破前面提到的机器学习天花板。知识图谱在这个突破上应该的潜力。当前软工领域知识图谱研究还非常初步,还有很多未知和挑战。第一,软工数据是多模态的,知识蕴涵在大量文本,也有图片和视频中,这需要恰当使用很多不同nlp,cv技术。第二,通用nlp,cv技术很难直接用到软广数据上,必须要做domain adaptation。而domain adaptation需要软工数据标注,也要做方法调整,还有技术通用性挑战。第三也是最重要的,相比于data-driven deep learning,知识图谱最终交付态和在软工任务相关应用还有很多未知,而且不是一两个算法就能解决的,而是需要系统化的知识工程。我觉得这些挑战都是值得进一步探索的,这些探索应该对提升智能软件开发能力有利。
观点讨论
@彭鑫(复旦大学):@邢振昌 (ANU) 嗯,KG知识的覆盖度和质量到达某个临界点之前可能很难带来突破性进展。不过支持下搜索推荐应该是可以的。
@邢振昌 (ANU) :@彭鑫(复旦大学)对的,就是刚刚李戈老师提到____阶段
李戈:
==现有智能化方法..面临哪些挑战?==
研究挑战:很多啊,例如(包括但不限于)
代码逻辑到概率模型的低效转换、低效的学习能力、有限的记忆存储能力...
==未来有哪些有价值的研究和实践探索方向?==
Learning + Code Logic
Code Logic + Learning
或者说得大一点:
Learning + Knowledge
Knowledge + Learning
观点讨论
@李戈·北京大学:@彭鑫(复旦大学) 采访主持人一下,您对知识与学习在软件开发中的应用,如何看待呢?
@邢振昌 (ANU) :@李戈·北京大学 "低效转换、低效的学习能力" 这里低效是什么意思?
@彭鑫(复旦大学):@李戈·北京大学 我觉得跟机器学习应该有一些互补的作用。除了可解释性之外,有些特定项目的知识也是很重要的,对于这种知识我们不一定要追求全自动的知识抽取,而可以主要避免知识的浪费和相关的重复思考。如何让程序员的思考和知识形成积累和凝练,是一个值得探索的方向。这方面跟企业有一些合作在探索。
@李戈·北京大学: @邢振昌 (ANU) 需要大量训练,才能学到少数逻辑...
@王千祥(华为):@李戈·北京大学 逻辑表达方式有局限
@邢振昌 (ANU) :不光低效,好像还有偷懒问题。貌似人有什么毛病,ai也会有的
@楼建光:@李戈·北京大学 ,我觉得人类几亿年的学习也不太高效,如果学一把可以用到很多场景中的话,问题也不大。
@张洪宇:@彭鑫(复旦大学)能举个例子吗?
@彭鑫(复旦大学):@张洪宇 比如原来大家原来所研究的traceability,是不是也是一种知识? 例如一个软件内置了20条报警规则,那么这些规则对应代码哪些地方?这些知识能否沉淀下来当其他人想了解的时候可以直接使用?
另外,这些地方能否以某种对称和规范的方式实现?这样当程序在代码中添加了第21条报警规则的时候,工具可以自动抽取出这条知识。
软件开发知识很重要的一点是要跟代码同步演化,如果跟代码两张皮的话就没有太大意义了
@李戈·北京大学: 把知识和概率模型相结合,目前似乎还只能是人去做的事情。这是个AI的大问题。
熊英飞:
软件智能化开发按我的理解就是替代程序员完成尽可能多的开发任务。虽然已经取得了很多进展,但目前智能化开发方法的水平还很有限,软件中大部分核心任务还是依靠人来手动完成的。如何自动化这些任务是未来的方向。
我们团队最近重点解决的一个问题是算法的合成。传统的程序合成工作往往只能合成表达式级别的程序,对程序员的帮助有限。要想真正帮助程序员,需要解决实践中对程序员来说比较困难的问题,设计算法就是这样一个问题。我们希望在给定一个逻辑规约的时候,给出满足这个规约的时间复杂度尽可能低的算法程序。如果我们把写好的程序当作规约,那么算法合成也可以用来做程序优化,从而有广阔的应用前景。
该问题也较难被大规模预训练模型解决。一方面,实践中很难收集到足够多的算法规约和对应程序作为训练集;另一方面,算法和规约的关系也难用浅层统计关系描述。因此,该问题非常适合学术界进行深入研究。
观点讨论
@楼建光:DeepMind提出了一个Neural Algorithmic Network.
王千祥:
我觉得最大的问题是系统化不足:目前研究了很多不同的智能化技术,应用于分散的开发场景中,缺乏抽象与梳理。当然,这个也许是当前所处的发展阶段决定的:现在还没有到系统化梳理的阶段。就像元素周期表,一定要在发现足够多的元素之后,总结的周期表才有价值。
至于需要的突破,我在以前的访谈中应该提到过,这里再重复一下(刚才几位老师也提到了类似的观点):基于规则(知识)的方法与基于统计的方向相结合。这个也是我认为有价值的研究和实践方向。
楼建光:
其实最大的挑战之前大家已经谈到了。高质量的数据是目前智能化方法的前提,无论是知识抽取方法还是大模型方法其实都需要高质量的数据。目前来说,收集高质量的数据是面临的一个很大挑战。我们尽管可以从Github或者Internet上收集到很多数据,但是这些数据质量参差不齐,数据的处理也是一个非常大的挑战。
从技术上来看,目前的方法包括大模型方法对代码语义的理解和表达还比较初步,要取得进步也必须在这些方面有更进一步的突破。
从工程上来看,现有的研究大部分重心在代码上,很多工作都是围绕代码开展的。其实程序,特别是应用程序主要包括MVC三大部分,支持一下邢振昌老师在前面讲到的点,我也觉得把近来智能技术上的突破跟自动数据建模和自动交互设计结合起来,也是值得研究的方向。
甄焱鲲:
我最近很感兴趣翻译和需求/设计稿生成代码的关系。前辈韦弗老师经过两年的思考,在1948年与英国伦敦大学伯克贝克学院的布斯(Andrew D. Booth)进行了深入探讨,最终于1949年7月正式在《翻译》备忘录中提出机器翻译概念以及四种可能的实现策略。
第一种实现策略基于简单的词语替换方法,其核心是解决词义消岐问题。该思想在最初实现的基于直接转换的机器翻译方法中得到了应用。
第二种实现策略假设语言是一种逻辑表达。后来,基于规则的翻译方法和统计机器翻译中基于同步上下文无关文法的译文推导模型与该策略的基本思想可以说是一致的。
第三种实现策略假设语言间的自动翻译实际上可以看作通信过程,即一种输入信号(未知的目标语言文本,也可以称为密码学中的明文)经过信道输出另一种信号(可观察的源语言,密码学中的密文),翻译过程就是根据输出信号恢复输入信号的过程。1990年左右统计机器翻译的兴起就是基于这个策略的基本思想。
第四种实现策略假设所有语言之间存在相同的逻辑特征,可以视为一种通用语言或者中间语言。后来,美国卡内基梅隆大学开发的JANUS机器翻译系统就采用了基于中间语言的翻译方法。
我的一些拙见:
1、编程语言和自然语言语言有很多相似性,甚至更简单(特殊关键字、保留字等)、更结构化和逻辑严谨(逻辑控制、输入输出等);
2、设计稿、PRD 生成代码应该可以类比成翻译的过程,把设计领域的概念和产品领域的概念翻译成编程领域的概念。
3、如果香农能够从信息论角度剥离内容和语义去看待信息的工程部分,应该也能够剥离内容和语义去看待代码生成的工程部分,类比前文第三种翻译策略,输入信号为设计稿和PRD输出为 AST 或 JavaScript/TypeScript/C++/Rust等。
4、如果对设计稿和PRD进行信息的有效压缩,祛除冗余信息和无效信息,设计稿生成代码的 D2C 里设计稿的信息量如果和生成代码的信息量对等,PRD 的信息量和业务逻辑、交互逻辑的信息量对等,最终生成的代码就应该是包含完整信息的代码。
未来我们会继续尝试设计稿、PRD生成代码在日常业务开发中的应用和落地,把那些重复的、低价值的编程工作逐步用机器替代。
观点讨论
@王千祥(华为):PRD是指什么?
@甄焱鲲:PRD指产品需求文档
@楼建光:这个很有道理。现在的大模型是囫囵吞枣式,其实需求文档本身有很多不同的抽象层次
@邢振昌(ANU):@甄焱鲲 请问imgcook外部用户有几类呢?
@甄焱鲲:@邢振昌(ANU) 外部用户现在大多是前端开发者,用来生成前端视图代码和部分数据绑定和交互逻辑。内部用户深度使用了业务逻辑代码生成,也就是和@李戈·北京大学 老师合作的成果,这部分还没有开放出来,要等再完善一点。
张玉明:
当前智能化开发方法用到的各种模型说到底依然只是学习到了代码文本层次上到某些范式,离对代码逻辑、业务逻辑的真正理解还有较大的距离。近期阿里达摩院也发布了2022的技术趋势,其中一项是大小模型的协同进化,大模型沉淀的知识与认知推理能力向小模型输出,小模型基于大模型在垂直业务场景去辅助开发者开发,并将获取到新知识反馈给大模型,让大模型的知识及能力持续进化,再借助类似联邦学习的技术去保护开发者的隐私,这样使用的开发者越多,受惠的开发者也越多,才是一套可持续循环的智能化开发系统。同时,从产业界的用户角度来看,随着云计算、云原生技术的普及,无论是基于CloudIDE的云端开发平台、低代码平台、还是无代码平台,其核心本质都是为了在满足企业业务发展的前提下让应用开发更简单更高效,软件智能化开发技术一定是结合着这些平台工具建设进而面向具体行业、具体场景去发力的。
自由讨论
@李戈·北京大学:我个人觉得,目前 知识的表示和存储方式 出现了问题,人不是利用本体、关系、确定性规则来表示和存储逻辑(或知识)的,应该思考知识的新的表示和存储方式,才有可能解决确定性逻辑+概率推断的问题。
@楼建光:李老师的这个观点我很同意
@吴文胜@华为:我一直在用自己做架构设计的实践中的体会来印证,越来越发现:我很难在其中找到非常确定性的所谓本体和规则。
这些东西一直在不断的演化。其中只有一些相对不大变的术语、实体和规则。
@李戈·北京大学:我觉得关键是 思考一下 人是怎么表示和存储知识的。
@王千祥(华为):人类的表示和存储,不一定是最佳啊
@邢振昌(ANU):难道真要去搞量子啦
@李戈·北京大学:这个吧,我还是有点笃信的,至少,人类进化的成果还是值得机器借鉴的
@李戈·北京大学:@邢振昌(ANU) 哎呀,这就复杂了,我最近还真在看一本书《量子力学史话》,不过,这纯属对物理学的兴趣,跟知识表示没啥关系
@王千祥(华为):广义上讲,机器的表示和存储,也是人类设定的。我得思考一下
@楼建光:@李戈·北京大学 ,人类大脑在某些脑区专门用来存储比较抽象的schema
访谈结束

欢迎关注CodeWisdom,Codewisdom平台由复旦大学软件工程实验室运营,提供智能化软件开发平台及线上沙龙相关资讯,关注可了解更多智能化软件开发的最新消息~
