Rust机器学习之Polars
Rust机器学习之Polars
本文将带领大家学习Polars的基础用法,通过数据加载 → \rarr →数据探索 → \rarr →数据清洗 → \rarr →数据操作一整个完整数据处理闭环,让大家学会如何用Polars代替Pandas进行数据处理。
本文是“Rust替代Python进行机器学习”系列文章的第二篇,其他教程请参考下面表格目录:
| Python库 | Rust替代方案 | 教程 |
|---|---|---|
numpy |
ndarray |
Rust机器学习之ndarray |
pandas |
Polars |
Rust机器学习之Polars |
scikit-learn |
Linfa |
Rust机器学习之Linfa |
pytorch |
tch-rs |
Rust机器学习之tch-rs |
networks |
petgraph |
Rust机器学习之petgraph |
matplotlib |
plotters |
Rust机器学习之plotters |
数据和算法工程师偏爱Jupyter,为了跟Python保持一致的工作环境,文章中的示例都运行在Jupyter上。因此需要各位搭建Rust交互式编程环境(让Rust作为Jupyter的内核运行在Jupyter上),相关教程请参考 Rust交互式编程环境搭建
文章目录
-
- 什么是Polars?
- 为什么需要Polars?
- 安装Polars
- 创建DataFrame
-
- 手动创建
- 加载外部数据
- 数据探索
-
- 浏览数据
- 数据描述
- 聚合统计
- 数据清洗
-
- 处理缺失值
- 剔除重复值
- 数据操作
-
- 选择列
- 数据筛选(过滤)
- 排序
- 合并
- 分组
- 结论
什么是Polars?

Polars一个用纯Rust开发的速度极快的DataFrame库,底层使用Apache Arrow内存模型。上层提供Python和JavaScript语言绑定。
数据科学家和数据分析师都对Pandas非常熟悉。对于数据科学领域的从业者来说几乎无一例外的都会花大量时间学习用Pandas处理数据。然而Pandas被诟病最多的是其运行速度和大数据集处理效率。幸运的是Polars的出现弥补了Pandas的不足。

简单地说Polars相当于Rust的Pandas,且性能比Pandas要好很多。
为什么需要Polars?

跟Pandas比,Polars有如下优势:
- Polars取消了DataFrame中的索引(index)。消除索引让Polar可以更容易地操作数据。(Pandas中的DataFrame的索引很鸡肋);
- Polars数据底层用Apache Arrow数组表示,而Pandas数据背后用NumPy数组表示。Apache Arrow在加载速度、内存占用和计算效率上都更加高效。
- Polars比Pandas支持更多并行操作。因为Polars是用Rust写的,因此可以无畏并发。
- Polars支持延迟计算(lazy evaluation),Polars会根据请求,检验、优化他们以找到加速方法或降低内存占用。另一方面,Pandas仅支持立即计算(eager evaluation),即收到请求立即求值。
正如开篇所讲,Polars就是为了解决Pandas的性能而生的。在很多测试中,Polars比Pandas快2-3倍。
| 操作 | Pandas | Polars |
|---|---|---|
| 读取CSV | 217.17 | 114.04 |
| 大小(Shape) | 0.0 | 0.0010 |
| 过滤(Filter) | 0.80 | 0.779 |
| 分组(Group By) | 3.59 | 1.23 |
| Apply(Apply) | 13.08 | 6.03 |
| 计数(Value Counts) | 2.82 | 1.76 |
| 去重(Unique) | 2.15 | 1.03 |
| 保存到CSV | 779 | 439 |
安装Polars
由于Polars提供Python和JavaScript绑定,所以Polars支持多种语言环境安装
传统的Rust程序有Cargo进行包管理,只需要在cargo.toml的[dependencies]中加入
polars = "0.25.1"
或者用 cargo add
$ cargo add polars
对于Python环境,我们可以安装Polars的Python语言绑定PyPolars
$ pip install polars
对于node环境,我们可以安装Polars的JavaScript语言绑定
$ yarn add nodejs-polars
数据科学家和算法工程师更喜欢用Jupyter,Jupyter环境下我们需要用evcxr的:dep命令来引入包。在Jupyter中输入如下代码:
:dep polars = {version = "0.25.1"}
创建DataFrame
手动创建
我们先来看一下如何创建DataFrame:
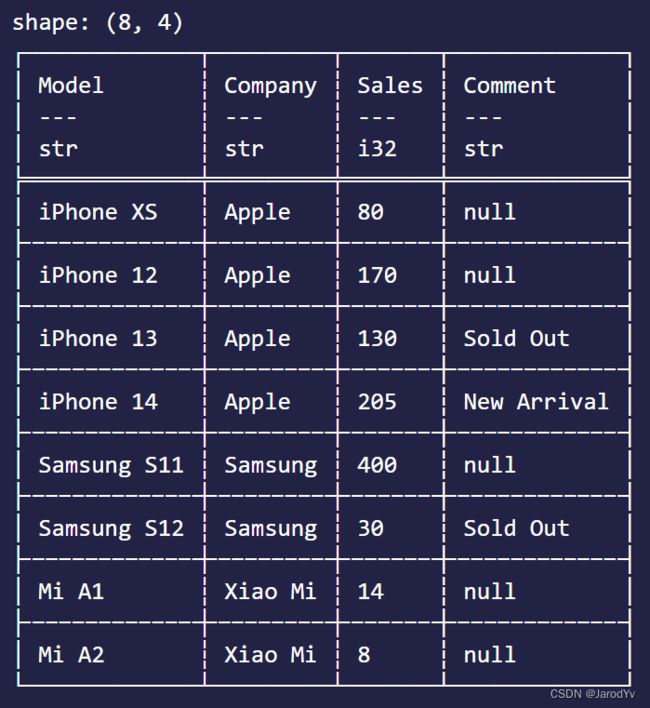
use polars::prelude::*;
let df = df! [
"Model" => ["iPhone XS", "iPhone 12", "iPhone 13", "iPhone 14", "Samsung S11", "Samsung S12", "Mi A1", "Mi A2"],
"Company" => ["Apple", "Apple", "Apple", "Apple", "Samsung", "Samsung", "Xiao Mi", "Xiao Mi"],
"Sales" => [80, 170, 130, 205, 400, 30, 14, 8],
"Comment" => [None, None, Some("Sold Out"), Some("New Arrival"), None, Some("Sold Out"), None, None],
]?;
println!("{}", &df);
Polars提供了df!宏来创建DataFrame。df!按列接受数据,每列含有列名和数据,数据以数组形式提供。这里需要注意的是,如果数据中存在空数据,我们需要用None来表示,而Rust是强类型语言,需要列数据类型一致,所以如果数据中有None存在,其他非None的数据需要用Some()包裹,达到类型一致。
DataFrame实现了std::fmt::Display方法,因此创建的对象可以直接利用println!宏输出。
跟Pandas一样,在Jupyter Notebook中Polars DataFrame会以整齐美观的格式输出,并且还很贴心地将每列的数据类型展示出来,非常方便。
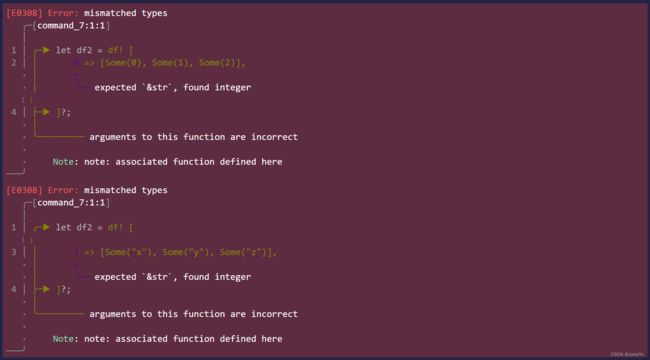
这里注意,Polars DataFrame跟Pandas DataFrame有一点不同,Polars DataFrame的列名必须是字符串类型。如果列名不是字符串类类型,运行时会报错。请看下面的代码:
let df2 = df! [
0 => [Some(0), Some(1), Some(2)],
1 => [Some("x"), Some("y"), Some("z")],
]?;
println!("{}", &df2);
上面的代码运行会报错mismatched types错误,因为列名是i32类型不是str字符串类型。
除了显示列名,Polars DataFrame还会在列名下面显示该列的数据类型。我们也可以调用dtypes()方法获取各列的数据类型:
df.dtypes()
运行上面的代码我们会看到下面的输出:
[Utf8, Utf8, Int32, Utf8]
我们也可以用get_column_names()方法获取所有列名:
df.get_column_names()
输出
["Model", "Company", "Sales", "Comment"]
我们能也可以通过get_row()方法传入行下标来获取一行数据:
df.get_row(0)
上面的代码会将第一行数据显示出来:
Row([Utf8("iPhone XS"), Utf8("Apple"), Int32(80), Null])
⚠注意:与Pandas不同,Polars中没有行索引的概念。Polar的设计哲学认为DataFrame不需要行索引。
加载外部数据
除了手动创建DataFrame外,我们更多时候都是从外部将数据集加载到DataFrame中。Polars支持多种格式的数据加载,包括csv、json、parquet 等常见的数据格式。
我们以csv数据载入为例演示一下Polars如何加载外部数据:
iris_data= CsvReader::from_path("iris.csv")?
.has_header(true)
.finish()?;
println!("{}", &iris_data);
上面的代码会将iris.csv文件中的数据加载到DataFrame中。其中has_header(true)的意思是csv文件有表头。输出结果如下:
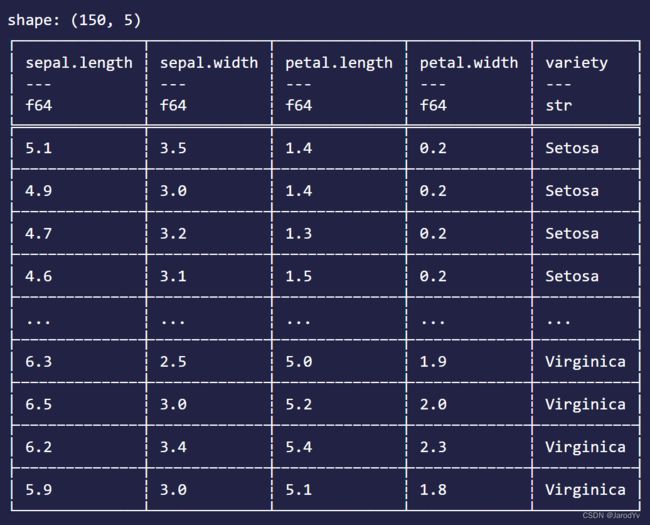
其他格式的数据都有对应的Reader,用法类似。
数据探索
有了数据之后,通常第一步我们需要对数据进行一些探索。常用的数据探索功能Polars都已经内置。
浏览数据
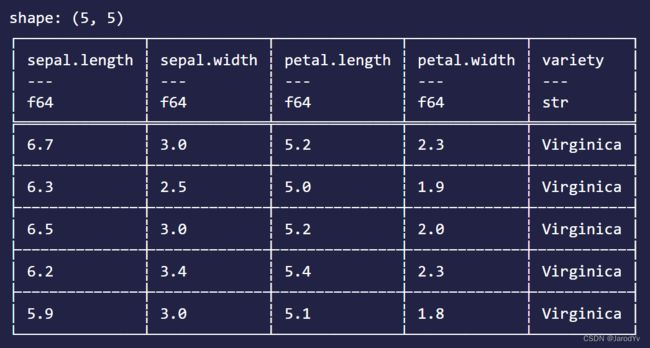
当我们的数据集比较大时,我们一般只会选择开头或结尾的几行来浏览数据。
iris_data.head(Some(5)) // 输出前5行
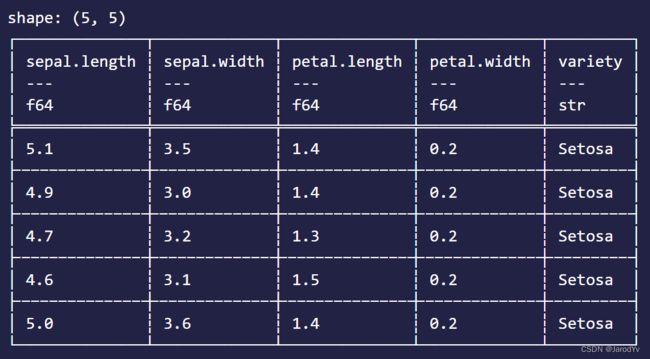
iris_data.tail(Some(5)) // 输出后5行
数据描述
我们可以通过shape()来查看数据集的大小
iris_data.shape()
输出
(150, 5)
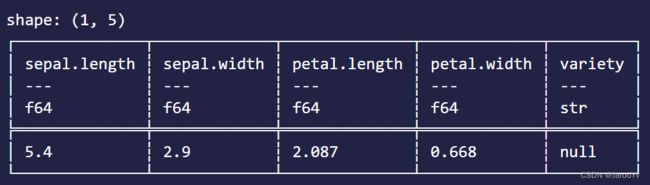
对数据集更详细的描述可以使用类似Pandas的describe()方法。describe()方法在describe feature中,所以要使用describe()我们需要在引入Polars时带上feature。
iris_data.describe(None)
输出如下:

从输出可以看到,Polars的describe方法的输出跟Pandas的几乎一致。
describe()方法接受一个参数,用于指定分位数。如果传None,则默认显示25%,50%,75%分位数。我们可以传入f64数组引用来自定义分位数,比如:
iris_data.describe(Some(&[0.3, 0.6, 0.9]))
上面的代码会输出30%,60%,90%分位数。(注意,describe()方法的参数是Option类型,所以我们需要用Some将浮点数数组包裹起来)

聚合统计
describe()中已经包含了常用的聚合统计,这些数据都有对应的函数可以单独统计。除此之外,Polars还提供了众多聚合统计函数:
sum(): 求和std(): 求标准差var(): 求方差mean(): 求平均数median(): 求中位数max(): 求最大值min(): 求最小值quantile(): 求分位数
这里给大家详细说一下quantile(),其他的跟Pandas非常类似。
quantile()接受2个参数,第一个参数分位数,第二个参数是求值策略,它是个QuantileInterpolOptions 枚举值,有如下选项:
- Nearest
- Lower
- Higher
- Midpoint
- Linear
下面代码演示了如何用线性策略求33%分位数:
iris_data.quantile(0.33, QuantileInterpolOptions::Linear)?
数据清洗
处理缺失值
Polars有drop_nulls()删除缺失值。请看下面的代码:
let df2 = df.drop_nulls(Some(&["Comment".to_string()]))?;
println!("{}", &df2);
上面代码移除Comment列数据为空的记录。输出结果为:
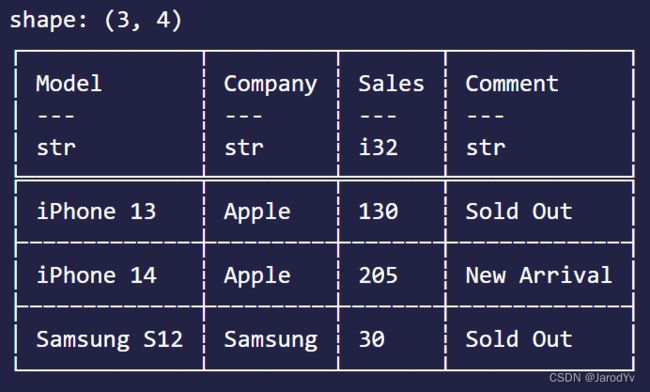
如果参数传None则是对所有列移除数据为空的记录。
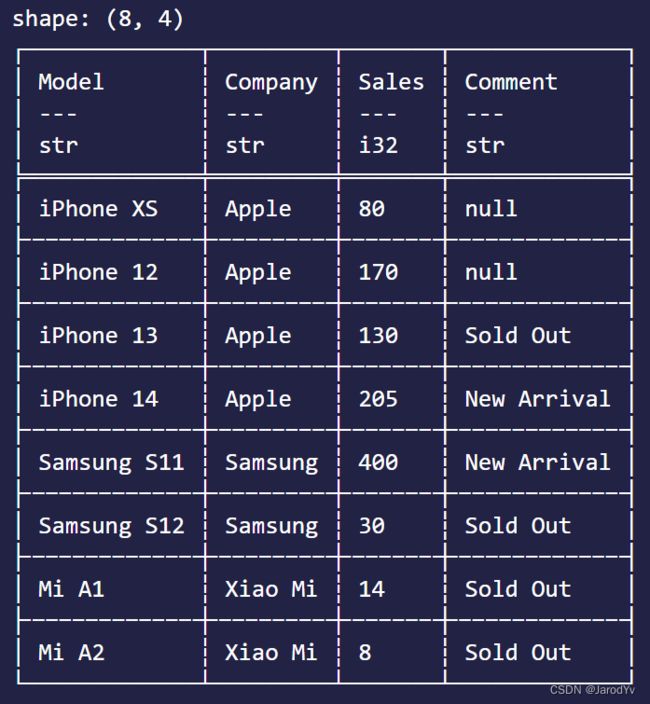
除了直接将缺失值所在行删除掉,很多时候我们希望用某个值来填充缺失值。Polars中有fill_null()可以实现这个功能。
let df3 = df.fill_null(FillNullStrategy::Forward(None))?;
println!("{}", &df3);
上面的代码会用遇到的第一个非空值填充后面的空值。输出结果如下:
fill_null提供多种填充策略:
- Forward(Option):向后遍历,用遇到的第一个非空值(或给定下标位置的值)填充后面的空值
- Backward(Option):向前遍历,用遇到的第一个非空值(或给定下标位置的值)填充前面的空值
- Mean:用算术平均值填充
- Min:用最小值填充
- Max: 用最大值填充
- Zero:用0填充
- One:用1填充
- MaxBound:用数据类型的取值范围的上界填充
- MinBound:用数据类型的取值范围的下界填充
剔除重复值
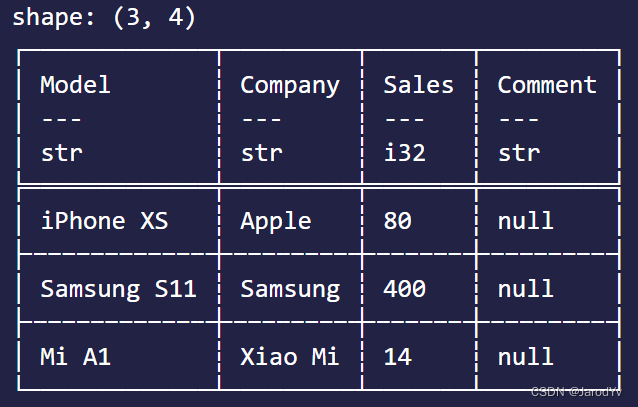
在数据清洗时我们往往还要去除数据中的重复记录,Polars提供了drop_duplicates()。请看下面的代码:
let df4 = df.drop_duplicates(true, Some(&["Company".to_string()]))?;
println!("{}", &df4);
drop_duplicates()接收2个参数,第一个参数是个bool值,表示是否保持数据的顺序;第二个参数是要处理的列名列表,如果传None表示所有列。上面代码执行后,Company列中重复的数据只会保留第一条。输出结果如下:
数据操作
选择列
Polars中选择列非常的直接,只需要给出列名即可:
df.select(["Model"])?
上面的代码会返回仅包含Model列的DataFrame。

如果你想获取多列,只需要将多个列名放在数组里即可:
df.select(["Model", "Company"])?

除了用列名获取列,我们还可以用下标来获取,
df.select_by_range(0..1)?
df.select_by_range(0..=1)?
上面两行代码的输出跟之前用列名选择列的输出是一样的。
数据筛选(过滤)
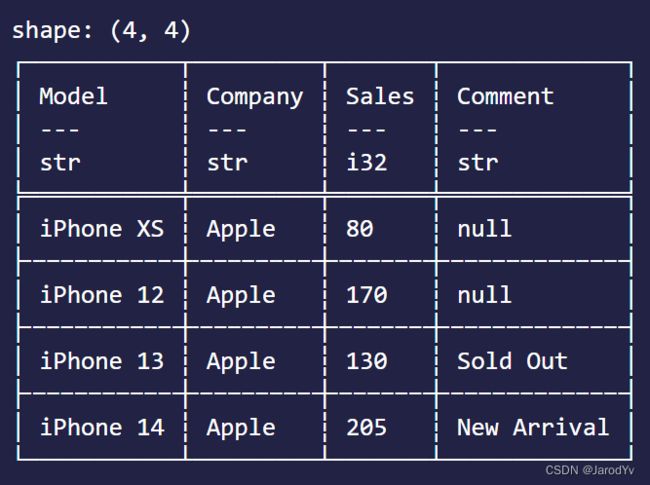
从数据集中按条件筛选(过滤)数据是最常用的操作之一。Polars用filter()进行数据筛选。filter()接收一个bool数组为参数,根据数组中的bool值来留下(为true时)或过滤掉(为false时)数据。因此数据筛选(过滤)的核心是产生此bool数组。比如,我们想筛选出苹果公司的手机,可以这样写:
let mask = df.column("Company")?.equal("Apple")?;
df.filter(&mask)
上面代码df.column("Company")获取Company列数据,然后用equal()判断值相等,得到bool数组,再由filter()函数过滤出数据。输出结果为:
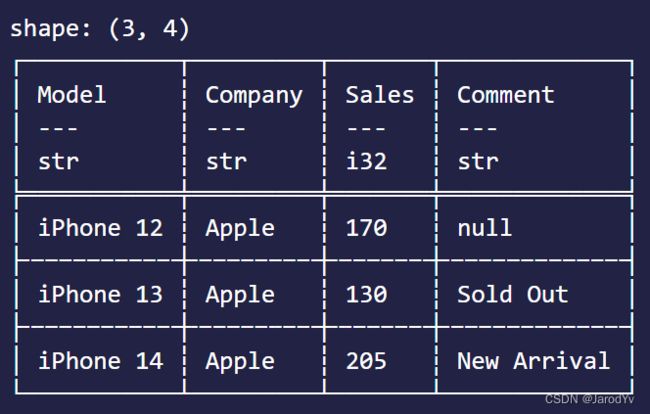
我们当然也可以通过逻辑运算(与&, 或|, 非!)组合多个筛选条件。比如我想筛选出苹果公司销售量大于100的数据,可以这样组合:
let mask = df.column("Company")?.equal("Apple")? & df.column("Sales")?.gt(100)?;
df.filter(&mask)?
这里用与运算&组合两个判断条件,形成新的bool数组。结果如下:
排序
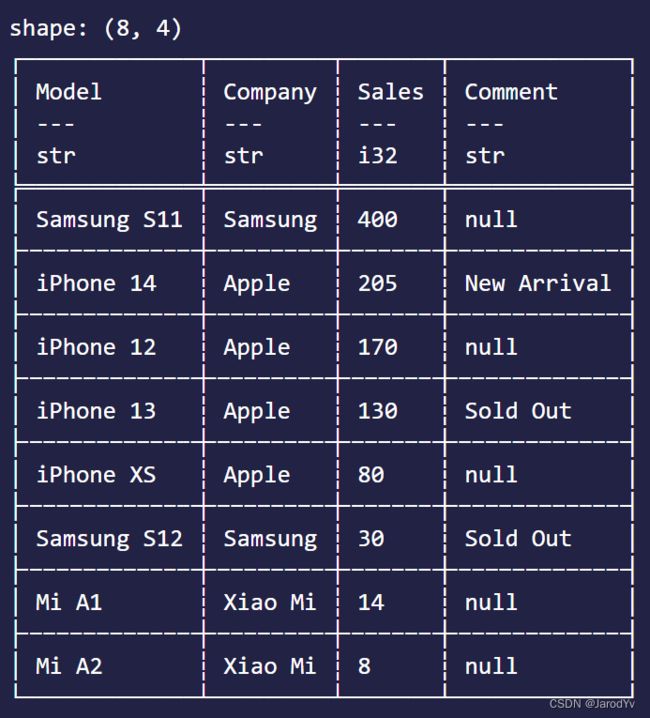
对数排序是数据分析中最常用的另一个操作。Polars提供sort()方法可以单列排序或多列组合排序。
单列排序很简单,只需要传入2个参数–列名和是否降序排列,请看下面的代码:
df.sort(["Sales"], true)?
上面的代码对Sales列降序排序,输出结果为:
多列组合排序需要传入多个列名组成的数组和对应的排序方式数组,请看下面的代码:
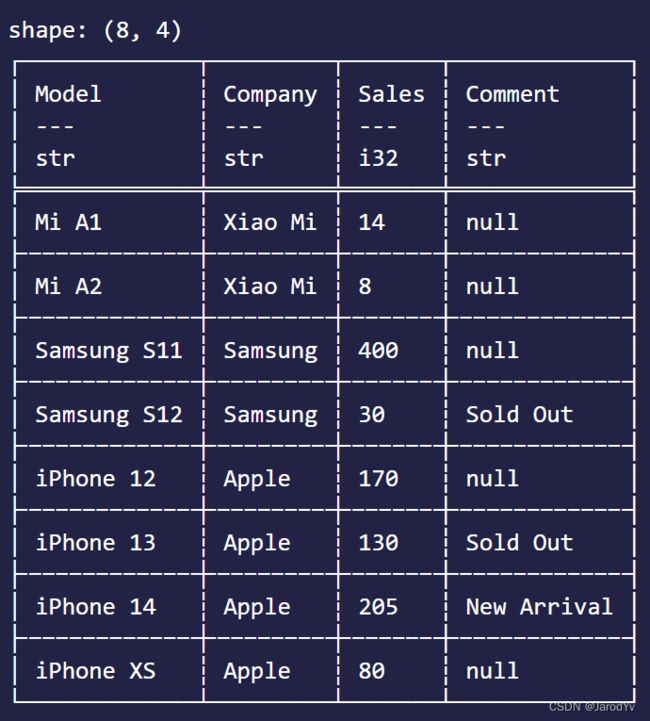
df.sort(["Model", "Sales"], vec![false, true])?
排在前面的列为主排序列,后面的列为辅助排序列。排序时会先按主列排序,然后再按辅列排序。上面的代码实现的是先按Model升序排序,然后在此基础上再按Sales降序排序,所以输出结果为:
合并
有时我们需要将两个DataFrame按主键合并成一个DataFrame,此时就需要用得到join()。join()接收5个参数,分别是要合并的DataFrame,左键,右键,合并方式,及前缀。请看下面的代码:
let df_price = df! [
"Model" => ["iPhone XS", "iPhone 12", "iPhone 13", "iPhone 14", "Samsung S11", "Samsung S12", "Mi A1", "Mi A2"],
"Price" => [2430, 3550, 5700, 8750, 2315, 3560, 980, 1420],
"Discount" => [Some(0.85), Some(0.85), Some(0.8), None, Some(0.87), None, Some(0.66), Some(0.8)],
]?;
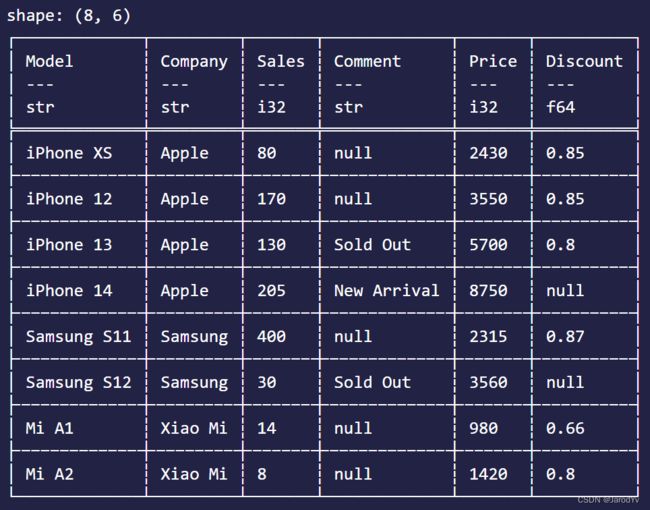
let mut df_join = df.join(&df_price, ["Model"], ["Model"], JoinType::Inner, None)?;
println!("{}", &df_join);
上面的代码将新建的df_price按照Model为主键合并到df中,合并后的结果为:
分组
数据分析时往往需要分组来分析,我们可以用groupby()对数据进行分组。groupby()接受一个参数,指定以哪个属性(列名)来分组。比如我们想按公司品牌来统计销量,可以这样写:
df.groupby(["Company"])?
.select(["Sales"])
.sum()?
上面的代码很好理解,先按Company分组,然后对Salse进行加总,结果如下:

最后,我们可以将前面学到的内容结合在一起使用,按公司品牌统计销售额并降序排序。 销售额 = 销量 × 售价 × 折扣 \text{销售额} = \text{销量} \times \text{售价} \times \text{折扣} 销售额=销量×售价×折扣,其中折扣为空表示不打折。代码如下:
// 计算销售额
let mut amount = (df_join.column("Sales")?) * (df_join.column("Price")?) * (df_join.column("Discount")?.fill_null(FillNullStrategy::One)?);
amount.rename("Amount");
// 将销售额加入DataFrame
df_join.with_column(amount)?;
// 分组统计销售额
df_join.groupby(["Company"])?
.select(["Amount"])
.sum()?
.sort(["Amount_sum"], true)?
输出为:

结论
本章我们学习了Polars的基本用法,并带大家实操了从数据生成/加载,到数据探索,数据清洗,再到数据操作一整个数据处理流程。Pandas能实现的功能,Polars都能实现且性能更好。
Polars的功能还有很多,能处理的问题十分丰富。并且Polars并行计算和延迟计算等高级特性本文还为涉及,后面会为大家专门介绍Polars的延迟计算和并行计算,让大家可以最大程序挖掘Polars的性能极限。