yolov2学习笔记
本笔记系学习b站“同济子豪兄”的yolov2的系列课程的笔记,如需观看视频请转:【精读AI论文】YOLO V2目标检测算法_哔哩哔哩_bilibili
yolov2即为yolo9000,better,即是作者在yolov1的基础上性能和准确率提升;faster:通过修改骨干网络将速度提升;stronger:此目标检测算法已经可以检测9000各类别啦!!


一、Batch Normalization

Batch normalization:把神经元的输出-均值/标准差,把它变成了以0为均值标准差为1的一个的分布。(为什么要这么做呢,因为很多激活函数,如:sigmoid、双曲正切激活函数在0附近是非饱和区,如果输出太大或者太小的话就陷入了饱和区,饱和区就意味着梯度消失难以训练,所以用batch normalization强行的把神经元的输出集中到0附近)

讲解:例如batch=32,每一个step/batch/步长喂进去32张图片,某一个神经元就会输出32个响应值,每张图片都会输出一个响应值,每个输入都会有一个输出,对这个神经元输出的32个响应值求均值、标准差,再做标准化。即将这个神经元的32个输出-这32个值的均值再/这32个值的标准差,这就是标准化,把这个标准化的响应再乘上γ,再加上β。(γ和β是都要经过训练才能得到的常数,每个神经元都训练一组γ和β)。这一系列操作以后就把神经元的输出限制在以0为均值,1为标准差这个分布里面,再通过乘γ加β就尽可能的通过一个线性变换把它又还原回了原始的空间。这样来弥补信息的丢失。(把神经元的输出压缩到了非饱和区,大大加快收敛,防止过拟合、梯度消失,加快训练速度)
在测试阶段,把均值、方差、γ、β都用训练全局求出的,比如:均值就用训练阶段很多很多个batch,每一个batch的很多期望作为最终的均值,是一个常数。方差是用训练阶段很多很多个batch的方差做了一个无偏估计,上图中的m-1就是无偏估计的意思,γ和β也是在训练的时候通过所有的batch全局求出的常数。在测试阶段进行前向推断的时候,把这个神经元响应值-全局的均值再除以全局的标准差,这里加一个e是防止分母变为0,这里是无穷小,再乘以γ再加全局的β。因为这些均值、标准差、γ和β都是训练阶段全局求出的常数,所以这相当于是线性变换。
通过batch normalization这个操作后,将所有神经元的输出都变到0附近,在sigmiod函数和双曲正切函数的非饱和区,在非饱和区是有最大的梯度的,最容易训练的,所有通过batch normalization这个操作可以大大加快收敛。batch normalization最早是在BN inseption文中提出的。

batch size = m,m个数的均值,m个数的方差,这个神经元对第i个输入的响应-均值/标准差,再乘γ加β就得到了batch normalization之后的结果。
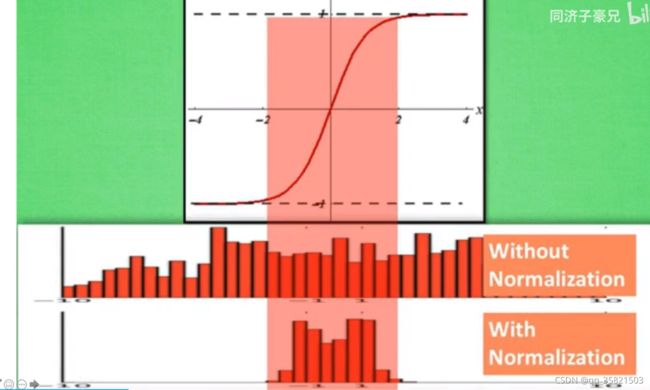
(注:上图为子豪兄说是b站莫烦python大佬的图)
经过batch normalization之后,分布很分散的数据就被压缩到了0附近,变成了以0为均值,1为标准差的分布。
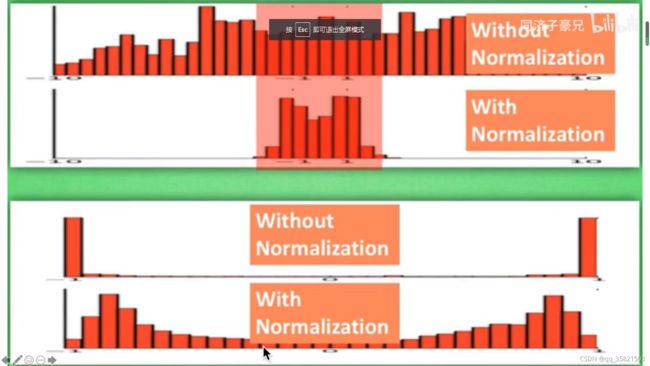
(注:上图为子豪兄说是b站莫烦python大佬的图)
此图的下半部分这种两边高,中间几乎没有的这种数据,使用了batch normalization后中间的数据就没有之前那种缺少得很厉害,得到了些优化。因为如果是这种两边高,中间几乎没有的这种数据的sigmoid函数和双曲正切都是饱和的,所以batch normalization就是尽可能的将数据往0附近聚。
 (注:上图为子豪兄说是b站莫烦python大佬的图)
(注:上图为子豪兄说是b站莫烦python大佬的图)

BN层也就是batch normalization层一般是在线性层的后面,激活函数(yolov2是leak relu)的前面。
makes deep networks much easier to train 加快神经网络的收敛;
improves gradient flow改善梯度(远离饱和区)
allows higher learing rates,faster convergence可以使用比较大的学习率来训练网络
networks become more robust to initialization对初始化不敏感(如果之前初始化方法不好就会导致神经网络的输出都在非饱和区,经过batch normalization后就对初始化不那么敏感了)
acts as regularization during training起到一个正则化的作用(可以取代dropout层)
训练和测试时的BN层不一样。
但是BN与dropout不能一起用。
二、High Resolution Classifier高分辨率分类器
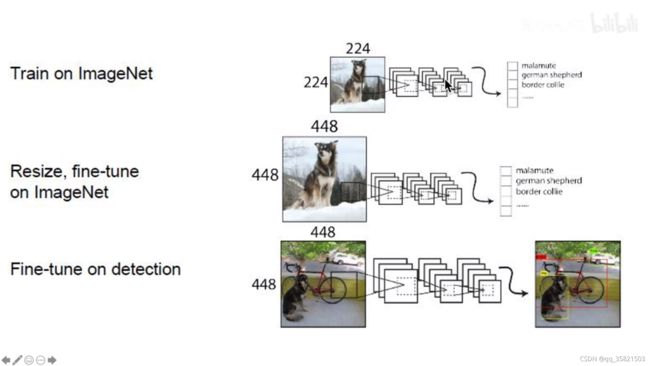
一般的图像分类网络都是用小的分辨率在imgNet的图像分类数据集上训练的,yolov1的目标检测的输入图像是448*448。如果用一个224*224的图片训练的网络,再在448*448的目标检测上训练,那网络就得学习切换这两种分辨率,从小分辨率切换到大的分辨率,性能肯定会降低。yolov2就直接在448*448的图像分类数据集上进行训练,适应了大分辨率。论文中,先是224*244训练了一会儿,再在448*448上训练了10epoch,再在448*448的目标检测数据集上进行fine-tune,这样网络就能适应大分辨率的输入。这个trick提高了3.5%mAP。这样网络就不需要做很大的变动,让它一开始就在448*448上去训练。
三、anchor机制
yolov1-yolov5都用了anchor,到后面很多目标检测算法就不用anchor了,而是用的anchor free。
这三个技巧是在一块儿用的所以子豪兄就放一起了哦。

在yolov1中,每个grid cell都有两个肆意的bounding box,yolov2中,我们给每个grid cell安排两个先验框,如下图,一个是瘦高的,一个是矮胖的,两个bounding box只需在原有的位置上微调,预测它的偏移量,就没有了大的变化,哪个框和ground truth的IOU大,哪个就负责拟合这个ground truth,这两个框就有了分工,一个就天生的负责拟合矮胖的物体,一个就天生的负责拟合瘦高的物体,这样就不会野蛮生长了,就让模型训练就更加稳定了。

在yolov2中把每张图片划分成13*13个grid cell,每个grid cell预测5个anchor,事先准备了5种大小不同的先验框,每个anchor对应一个预测框,而这个预测框只需要预测输出它相对于它所在的anchor的偏移量。
人工标注框的中心点落在哪个grid cell,就由哪个grid cell产生的这5个anchor与这个grid truth的IOU最大的框(anchor)负责预测,而这个预测框只负责预测相较于自己anchor的偏移量。
每个grid cell都有5个anchor,这个白框是人工标注框,中心点落在了4号grid cell中,这个车就应该由4号grid cell产生的5个anchor中的与白框IOU最大的那个去负责预测这个车,这个anchor对应得预测框只需要输出它相比于所在anchor的偏移量
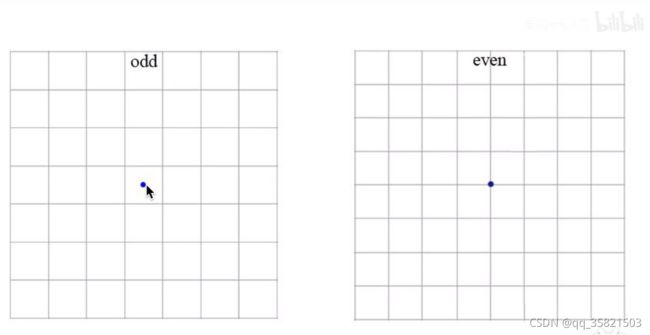
模型输出的feature map是奇数长宽,而不是偶数长宽,因为奇数长宽有一个中心的grid cell,通常下图片中一个物体占主导,此物体的中心点应该有一个确定的grid cell去负责预测它,而不应该像右图一样是有偶数4个feature map,4个grid cell来预测它。
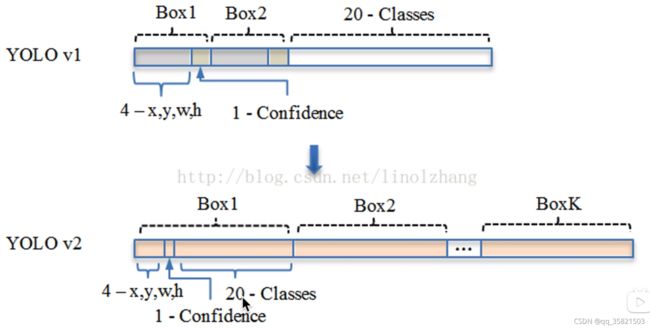
模型输出的结构也改了,在yolov1里面没有用anchor,划分成7*7个grid cell网格,每个grid cell预测两个bounding box,每个bounding box有4个位置参数(x,y,w,h)和一个置信度参数confidence,还有20个类别的条件概率,所以5*B+C=5*2+20=30,每个grid cell有30个数,这30个数构成了一个30维的向量;类别归grid cell管的。
在yolov2中,类别归anchor管了,把整个图片划分成13*13的grid cell,每个grid cell产生5个anchor,每个anchor有4个位置参数(x,y,w,h)和一个置信度参数confidence,还有20个类别的条件概率,所以每个anchor有4+1+20=25个参数,5个anchor,5*25=125个数,所以就是一个grid cell有125个数构成了一个125维的向量,或者是5*25维的矩阵。13*13*125维的张量。

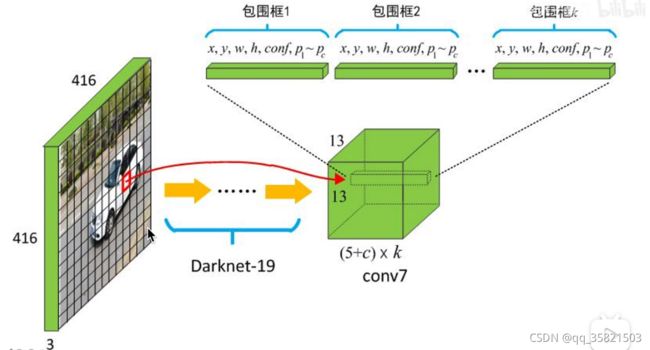
YOLOv2用的骨干网络是darknet-19网络,输入图像是416*416的,yolov2将输入图像划分成13*13的grid cell,对应得就是输出13*13的feature map,这13*13个grid cell中,每个grid cell都产生一个125维的向量,就包含了5个anchor,每个anchor是4个位置参数和一个置信度参数和20个类别的条件概率共有25个数,此处K是anchor的个数,这里是5,c是类别个数,这里是20。
这个5是怎么来的呢?不是手动去选择的哦,在faster rcnn和SSD里面这个anchor的长宽大小是人手工选择的,就是人手工决定长宽比1:1.2还是1:1.5这种,万一数据集里面它的比例并符合假设呢,比如我的数据集里面大量都是路灯、行人、长颈鹿,这样高瘦的物体,那我们就需要设置一些高瘦的anchor,为了解决这个问题,yolov2的作者对整个pascal Voc和co co数据集做了一个长宽比的聚类,不同的聚类中心和聚类个数对应了不同的IOU,即聚类中心越多,anchor能覆盖的IOU就越大,但是这个anchor越多,这个模型就会变得更复杂,取了折中,此处就取的是5,能尽可能覆盖,长宽比如右图所示。
这5个anchor的长宽比是长啥样呢?如右图所示,黑框表示pascal voc2007数据集中的anchor的长宽比,蓝框表示coco目标检测数据集的anchor长宽比,可以看到coco的变化要更多,更复杂一些,通过这样聚类的方法就比手工选择anchor指定anchor的长宽高更加的科学,尽可能覆盖所有数据的所有框。

论文作者做了对比实验, 用聚类的方法,5个anchor的IOU能达到61.0,手动选anchor的话,IOU要达到60.9也就是和61.0接近的需要9个anchor。因此,用聚类的方法用5个anchor就能达到faster RCNN的9个手动选的anchor的效果。说明选anchor的时候可以用聚类哦,yolov2-yolov5都用了k-means聚类的方法。

在yolov1中,两个grid cell是野蛮生长的,它可以跑到图像中的任何位置,可以在全图上乱窜,yolov2加了anchor后,它是输出它相较于它所在anchor的偏移量,这个便偏移量仍然是可以全图乱窜的,无异于也是野蛮生长,会导致模型特别是在训练初期的时候特别不稳定,为了限制预测框的位置,这里加了限制。

模型输出的是相比于anchor的偏移量(tx,ty,tw,th),其中tx,ty可以使从正无穷到负无穷的任何数,这无异于导致了野蛮生长,yolov2给tx,ty加了sigmoid函数(逻辑回归用的激活函数,这函数的作用是无论你输入的是正无穷到负无穷的任何数,最终的输出是0-1之间),通过sigmiod函数就把预测框的中心点限制在了它所在的grid cell里面,cx,xy是这个grid cell左上角对应的坐标,这里全部归一化为1*1了,pw,ph是anchor的宽、高,因为预测物体可能会很大,所以我们就不限制它的大小了。加速模型的稳定。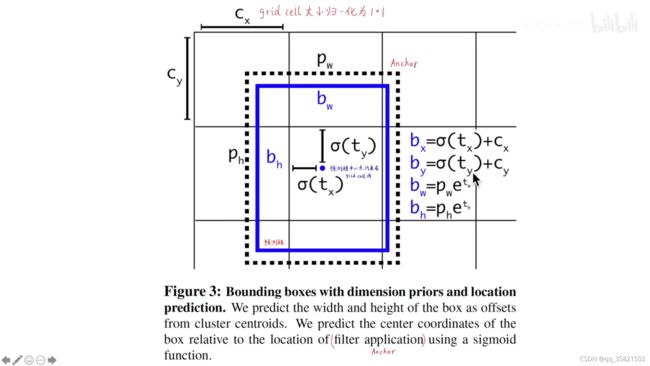
模型输出的是tx,ty,tw,th,to(置信度),cx,cy是归一化后的grid cell左上角的坐标,pw,ph是anchor的宽度和高度,最终的b是预测框,置信度的标签是pr(object)*IOU(b,object)<预测框和ground truth的IOU> =sigmoi(to),要让等号两边的值尽可能的接近。
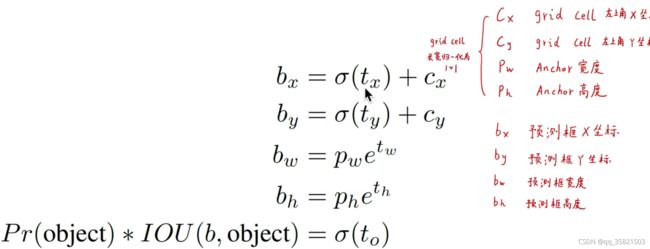
三、yolov2的损失函数
在yolov2遍历了13*13所有的grid cell的每一个anchor,这个蓝框就相当于遍历了所有的anchor,也就是遍历了所有的预测框,因为每个预测框是相较于它所在anchor的偏移,所以是相当于遍历所有的预测框,包含了3项,第一项是这个anchor是否与gorund truth的IOU小于0.6,IOU是怎么算的呢?把anchor与ground truth中心点重合来算的哦,只看形状不看位置,哪怕这个anchor中心点并不和ground truth重合。如果anchor与ground truth的IOU小于0.6就符合第一项。第二项是是否是模型训练的早期,第3项是anchor负责检测物体。每个grid cell产生5个anchor,这5个anchor由它和ground truth的IOU最大的那个anchor去负责拟合这个ground truth,第3项就是这个IOU最大的anchor。

这三个黄色的值都是非0即1的,符合就是1,不符合就是0,这些紫框里面的“入”是权重,有些是和yolov1是一样的,有些是yolov1特有的,这个值呢并不重要,我们只关心它的算法思路。
第一项就是anchor与ground truth的IOU<0.6,就是不负责预测物体的anchor,这些anchor的置信度越为0越好,直接给它做一个平方,那为什么要加负号呢?因为是0(-bijk)^2,0就是不负责检测物体的预测框的标签值为0。
第二项在训练的早期,求和遍历x,y,w,h这4个定位参数,要让anchor的x,y,w,h与预测框的x,y,w,h尽可能的接近,给它们两个做差平方,训练效果就是让它们两个尽可能接近,才能让这个损失函数越小,为了让预测框的位置与anchor的位置尽可能的一致,让模型更快的学会预测anchor的位置,让tx,ty,tw,th更稳定,让anchor们在训练早期的时候就能够各司其职,各站其位,让模型更加稳定。
第三项anchor框负责预测这个物体,假设一个grund truth只分配给一个anchor,即这个anchor与ground truth的IOU最大,它就负责预测这个ground truth,与SSD不同,SSD里面一个ground truth可以分配给多个anchor。在yolov2中呢,一个grund truth只分配给一个anchor。那anchor就被分成了与ground truth的IOU最大的也就是负责检测物体的anchor;还有一类就是不负责检测物体的就是IOU<0.6的anchor;还有一类anchor的IOU>0.6但是却不是最大的,那这anchor怎么办呢?在yolov2中忽略了这些anchor的损失,不管他们了哦。对于与ground truth的IOU最大anchor呢要算3项,第一项,定位误差,就是ground truth标注框的位置与预测框的位置,让其x,y,w,h尽可能的接近。第二项是anchor与标注框的IOU与预测框的置信度尽可能的一致,即对于置信度而言,anchor与标注框的IOU就是置信度的标签,我们希望用预测框的置信度去拟合这个标签,yolov1也是这么做的,预测框和标注框的IOU作为标签,在yolov2中加了anchor,那就是anchor与标注框的IOU;第三项是分类误差,和yolov1是一样的,标注框的类别和预测框的类别做差再平方。这里的pascal voc有20个类别,标注框会生成一个20维的向量,里面有一个为1,其他为0。预测框也会生成一个20维的向量,每一个向量的值就代表它对这个类别预测的概率,逐元素作差平方再求和。
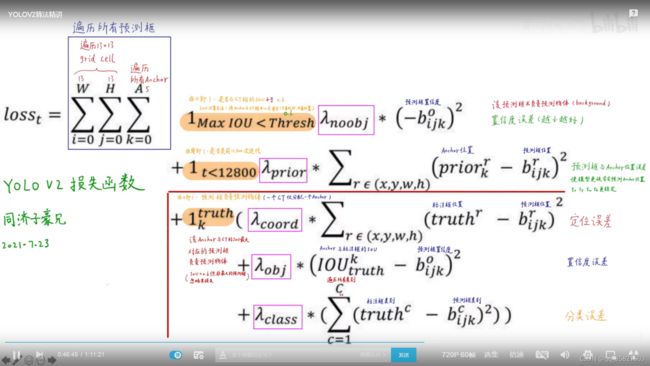
子豪兄说,yolov2论文并没将损失函数给出,这是网友根据作者的代码整理出来的。
三、Fine-Grained Features 细粒度特征
把浅层的网络预测出的feature map,一路把这个网络拆成4分,另一路进行正常的下采样、卷积,把这4个长条拼成一个长积木,和之前另一路的长条拼在一起,变成一个更长的积木,这个更长的积木里面就包含了底层的细粒度的信息和经过卷积之后高层的信息,这样就整合了不同尺度的特征,有利于小目标的目标检测的。
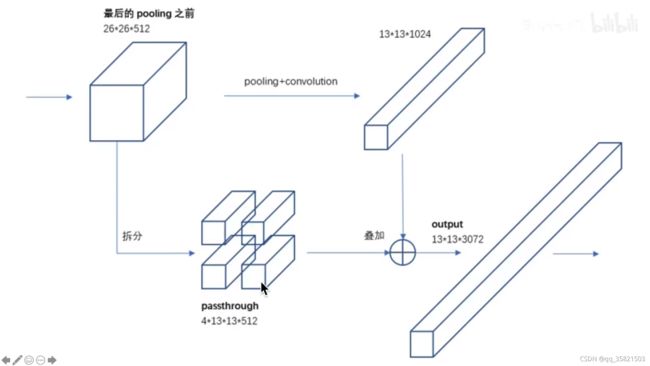
子豪兄说此图来源某知乎上的大佬的博客
具体拆分,和yolov5的foucs结构一样,把一张纸变成4种颜色,然后把这四种颜色拼起来,把一张纸长宽缩小为原来的一半,但是通道数变成了原来的4倍,原来只有3通道,现在是12。

在yolov2代码里,有个26*26*512的中间层的feature map,对它进行一个1*1卷积变成了26*26*64,说明有64个卷积核,对26*26*64进行1拆4,把这4个拆分块变成一条13*13*256,就是长宽变为原来的一半,通道变为原来的4倍,这是path throuh的分支,其他的就正常进行卷积,13*13*1024,把这个13*13*1024的,把这个13*13*256拼在13*13*1024后面,就变成了13*13*1280,concatenate就是拼接层,这样就把底层的细粒度特征和高层的语义特征融合,有利于目标检测,最后生成了13*13*125的3维张量。

四、Multi-Scale Training
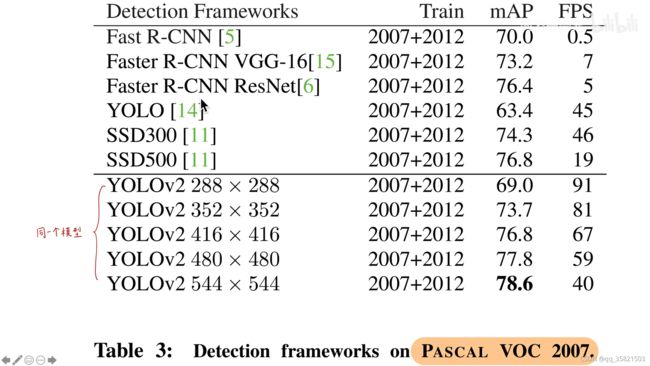
同一个模型,它每十步就会重新选取一个输入图像的大小,就是在模型训练的期间,把不同大小的图片输入,就是模型应兼容各种尺寸大小的图片。注意:模型权重和结构均未改变。因为darknet-19有一个global average pooling全局平均池化层,它会把输出feature map的每一个通道求平均来替代全连接层,如果是yolov1一样用全连接层的话,输入的图像大小必须是固定的,但是现在有了global average pooling,可输入任意大小的图像,到最后都能变成那个数据结构,这样的操作提升了1.5%的mAP。但是有一个副作用,如果输入高分辨率的大图片,yolo会预测得比较慢,但是会预测得很准,如输入低分辨率的小图片,yolo会预测得比较快,但是精度不高。所以你可以通过选择图像的输入大小来达到精度和速度的权衡。

不同的蓝点就表示不同大小的图像,如果输入大图片,速度就慢,精度就好。输入小图片速度很快,精度很差。此图就表示在同样速度的情况下,yolov2是精度最高的,在同样精度下,yolov2速度最快。FPS(每秒处理图像帧数)>30就是实时目标检测系统。
加了anchor虽然精度下降了,但是论文中说了,加了anchor可以大大增加recall,那些没用的框的比例也增大了,所以precision肯定降低了,对于这个问题,可通过后处理来规避掉precision降低带来的影响,所以,加anchor的利大于弊。
换了new network,虽然也没有很大的提升,相比于之前的yolov1可以大大减少计算量
