yolov2 论文笔记
摘要部分
real-time object detection system that can detect over 9000 object categories.
之所以叫yolo 9000 是因为可以检测9000个目标。
Using a novel, multi-scale training method the same YOLOv2 model can run at varying sizes, offering an easy tradeoff between speed and accuracy.
使用了一个新颖的多尺度训练的方法,使yolov2模型可以在不同尺寸的输入图像上运行,并在速度和准确率上有不错的平衡。
Finally we propose a method to jointly train on object detection and classification. Using this method we train YOLO9000 simultaneously on the COCO detection dataset and the ImageNet classification dataset. Our joint training allows YOLO9000 to predict detections for object classes that don’t have labelled detection data.
作者提出一个联合训练目标检测与目标分类的方法。使用这个方法在coco的目标检测数据集和imagenet的分类数据集上联合训练,使得yolo9000能够使检测网络在没有标注为检测目标的数据上执行目标检测任务。
better
YOLO has relatively low recall compared to region proposal-based methods. Thus we focus mainly on improving recall and localization while maintaining classification accuracy.
yolo算法的召回率对比RPN的方法太低了,因此作者主要专注于提高召回和定位的准确率,同时保持分类的准确率。
BN:
使用bn层实现对网络的正则化,并去掉dropout
高分辨率分类器:
The original YOLO trains the classifier network at 224 × 224 and increases the resolution to 448 for detection. This means the network has to simultaneously switch to learning object detection and adjust to the new input resolution.
原始yolo在224大小的分辨率图像下训练分类器,但是在448分辨率大小的图像上进行目标检测。
For YOLOv2 we first fine tune the classification network at the full 448 × 448 resolution for 10 epochs on ImageNet. This gives the network time to adjust its filters to work better on higher resolution input.
yolov2首先在448大小的图像上迭代10个epochs,对分类器进行微调。使网络能够对448大小的输入数据能够有更好预学习效果。
卷积生成anchor:
YOLO predicts the coordinates of bounding boxes directly using fully connected layers on top of the convolutional feature extractor.
原始的yolo网络是直接在backbone的卷积结构后面接上一个全连接层,直接用来生成目标的location信息(x, y, w, h),confidence(default box里面是否包含目标)以及类别概率。
与yolo不同,faster rcnn使用RPN,并结合人工设计anchor的尺度和大小生成default box,而且预测的是生成好的default box的相对于真实位置的偏移量,并非是直接预测default box最后真实位置。
Predicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn.
学习偏移量要比直接学习目标的具体位置要简单多了。
去掉全连接层,改用全卷积的结构可以使网络支持任意大小的输入图像。
作者做了如下的一些改进:
- 去掉全连接层,改用anchor的方式预测。精度小有降低,但是召回率大大提高。
- 去掉一个pooling层,提高分辨率。
- 把网络的输入尺寸由448改成416,这样最后用来设置anchor的特征图的大小就是一个奇数,如13×13(图像的降采样因子是32,416/32=13),奇数的特征图可以找到一个确定的中间位置,大目标出现在中间位置的概率更高。
- 预测内容包括,目标位置(学习default box的偏移),目标置信度(default box中是否有目标),目标的分类概率。
确定anchor的尺度:
faster rcnn的anchor的尺度信息是手动设定的,比如长宽比有1比2,2比1;anchor的大小也有一系列数值。
手动设定的依赖经验信息,作者使用聚类算法来计算anchor的尺度。注意,是计算anchor的尺度。
如,在生成的13×13的特征图上,每个特征图上的cell生成k个尺度的anchor,这k个尺度的anchor分别是多少?作者用kmeans聚类算法解决。
kmeans算法很简单,是一种无监督的算法,输入n个数据点和一个k值,对n个数据点分成k类。
根据kmeans算法的原理,计算n个数据点属于哪一类,需要一个度量标准,比如使用欧式距离来计算两个数据点之间的关系,根据这个关系的远近判断两个点是否属于同一类点。
在计算anchor的尺度过程中,使用的度量距离是IOU。
论文中的公式如下:
d ( b o x , c e n t r o i d ) = 1 / I O U ( b o x , c e n t r o i d ) d(box, centroid) = 1 / IOU(box, centroid) d(box,centroid)=1/IOU(box,centroid)
kmeans算法使用迭代运算,直到运算收敛。
centroid是某一次迭代的某一个类别的聚类中心点,box是需要待判断的box。
输入的n个数据的boxes就是训练数据中的ground truth boxes
作者实验了一些度量方法和不同的k值,最后得出使用上面的公式效果最好,k值最好设置为5.
位置预测:
yolov2借鉴RPN网络使用anchor boxes来预测bounding box相对先验框的offsets。
预测的bounding box的中心位置为 ( x , y ) (x, y) (x,y),设置的先验框的宽高为 ( w a , h a ) (w_a, h_a) (wa,ha),中心位置为 ( x a , y a ) (x_a, y_a) (xa,ya),网络学习到的偏移量是 ( t x , t y ) (t_x,t_y) (tx,ty)
那么,最后预测框的位置 ( x , y ) (x, y) (x,y)计算公式为:
x = ( t x ∗ w a ) + x a x = (t_x*w_a)+x_a x=(tx∗wa)+xa
y = ( t y ∗ h a ) + y a y = (t_y*h_a)+y_a y=(ty∗ha)+ya
上面公式与原论文的公式不一样,后面两个减法应该是加法(很多博主都是这样认为)
但是使用上面计算公式会有这样的一个问题:
假如当前正则计算左上角的bounding box的位置信息,如果计算出的offset的值非常大,那么可能左上角预测的bounding box加入offset以后,就有可能跑出左上角特征图cell所指定的grid(参见yolov1)。所以,需要将学习到的offset值做一个限制,使得当前cell所计算的bounding box的偏移量被限制在当前cell所指定的grid里面。
如文章中所述
For example, a prediction of tx = 1 would shift the box to the right by the width of the anchor box, a prediction of tx = =1 would shift it to the left by the same amount.
预测的边界框很容易向任何方向偏移,如当 t x = 1 t_x=1 tx=1时边界框将向右偏移先验框的一个宽度大小,而当 t x = − 1 t_x=-1 tx=−1 时边界框将向左偏移先验框的一个宽度大小,因此每个位置预测的边界框可以落在图片任何位置,这导致模型的不稳定性,在训练时需要很长时间来预测出正确的offsets。
作者最终使用如下的策略来避免上述问题:
在每个gird cell当中(gird cell就是特征图上的每个点映射会原始图像后得到的网格),将anchor设置在gird cell的左上角,坐标位置为 ( c x , c y ) (c_x, c_y) (cx,cy),预测的bounding box的宽高为 ( p w , p h ) (p_w, p_h) (pw,ph)。那么,公式如下:
b x = σ ( t x ) + c x b_x = σ(t_x) + c_x bx=σ(tx)+cx
b y = σ ( t y ) + c y b_y = σ(t_y) + c_y by=σ(ty)+cy
b w = p w e t w b_w = p_w^{e^{t_w}} bw=pwetw
b h = p h e t h b_h = p_h^{e^{t_h}} bh=pheth
P r ( o b j e c t ) ∗ I O U ( b , o b j e c t ) = σ ( t o ) Pr(object) ∗ IOU(b, object) = σ(t_o) Pr(object)∗IOU(b,object)=σ(to)
其中 t x , t y , t w , t h , t o t_x, t_y, t_w, t_h, t_o tx,ty,tw,th,to分别表示中心位置x,y的偏移量,宽高的尺度偏移以及目标概率值。预测的偏移量是相对于gird cell左上角的偏移量。相当于每个anchor被限制预测当前gird cell对应的区域。
σ σ σ为sigmoid函数,这样可以将 t x , t y t_x,t_y tx,ty等值限制在[0,1],就可以解决anchor加上偏移量跑飞的问题。
如下图:
 上图的虚线框是 ( p w , p y ) (p_w,p_y) (pw,py)表示anchor设置 box的大小,蓝色框是经过 ( t w , t y ) (t_w,t_y) (tw,ty)偏移计算以后得到的预测bounding box大小。
上图的虚线框是 ( p w , p y ) (p_w,p_y) (pw,py)表示anchor设置 box的大小,蓝色框是经过 ( t w , t y ) (t_w,t_y) (tw,ty)偏移计算以后得到的预测bounding box大小。
精细化特征:
We take a different approach, simply adding a passthrough layer that brings features from an earlier layer at 26 × 26 resolution.
为了更好的检测小目标,作者使用了一个passthrough层,将顶层的一个26×26的特征图与当前的13×13的特征图执行concat操作。
原始的yolov2有5个pooling操作,将输入的416大小的图像最后变成了13×13。26×26大小的特征图是最后一个pooling操作的输入特征。
这里借用B站上一个up主中视频的图

可以看到passthrough层上面还有一个1×1×64的卷积操作,将26×26×512的特征图变成26×26×64大小的特征图。
然后是passthrough层,passthrough的操作方式,同样借用B站UP主的一张视频截图。
 可以看到,输入大小为(W,H,C)的特征图,经过passthrough层以后,会变成(W/2, H/2, C×4)大小的特征图。具体做法如上,将特征图分成2×2份,每一份的第一个cell组成一个特征图,同理第2,3,4.如图中,相同颜色的cell放在一起。
可以看到,输入大小为(W,H,C)的特征图,经过passthrough层以后,会变成(W/2, H/2, C×4)大小的特征图。具体做法如上,将特征图分成2×2份,每一份的第一个cell组成一个特征图,同理第2,3,4.如图中,相同颜色的cell放在一起。
ps: 不明白为什么要这样搞,说是有利于小目标的检测,但是理由是什么啊?在知乎上找到一个说法,这东西也没法证明,愁人=_=
本质其实就是特征重排,2626512的feature map分别按行和列隔点采样,可以得到4幅1313512的特征,把这4张特征按channel串联起来,就是最后的13132048的feature map.还有就是,passthrough layer本身是不学习参数的,直接用前面的层的特征重排后拼接到后面的层,越在网络前面的层,感受野越小,有利于小目标的检测。
多尺度训练:
since our model only uses convolutional and pooling layers it can be resized on the fly.
作者使用全卷积的网络,因此不受尺度限制。
Every 10 batches our network randomly chooses a new image dimension size. Since our model downsamples by a factor of 32, we pull from the following multiples of 32: {320,352,…,608}. Thus the smallest option is 320 × 320 and the largest is 608 × 608.
作者每10个batches重新随机选取新的输入图像尺寸,尺寸的变化以32为步长,从320大小到608大小。
faster
训练策略:
ps:一下来自知乎
YOLOv2的训练主要包括三个阶段。
第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 224×224 ,共训练160个epochs。
然后第二阶段将网络的输入调整为 448×448,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。
第三个阶段就是修改Darknet-19分类模型为检测模型,并在检测数据集上继续finetune网络。网络修改包括(网路结构可视化):移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个3×3×1024卷积层,同时增加了一个passthrough层,最后使用1×1 卷积层输出预测结果,输出的channels数为: number_anchor×(5 + number_class) ,和训练采用的数据集有关系。由于anchors数为5,对于VOC数据集输出的channels数就是125,而对于COCO数据集则为425。
相当于每一个anchor预测自己的位置信息(×4),目标置信度(×1)以及类别概率(×number_class)
训练数据的预处理与yolov1相同,将判断label落在哪个cell对应的grid当中,那么该cell负责预测这个目标。每个cell会根据kmeans生成5个anchor,那么在训练的时候会选区IOU最大的计算loss。
ps:论文里面没写怎么计算Loss,真诡异,看知乎上博主的分析如下。
 上面的图是知乎上博主总结的,省去我硬扒别人代码的时间,tql!
上面的图是知乎上博主总结的,省去我硬扒别人代码的时间,tql!
我们来一点点解释,首先 (W,H)分别指的是特征图(13,13)的宽与高,而A指的是先验框数目(这里是5),各个 λ值是各个loss部分的权重系数。
第一项loss是计算background的置信度误差,但是哪些预测框来预测背景呢,需要先计算各个预测框和所有ground truth的IOU值,并且取最大值Max_IOU,如果该值小于一定的阈值(YOLOv2使用的是0.6),那么这个预测框就标记为background,需要计算noobj的置信度误差。
第二项是计算先验框与预测框的坐标误差,但是只在前12800个iterations间计算,我觉得这项应该是在训练前期使预测框快速学习到先验框的形状。
ps:应该是为了训练kmeans挑选合适先验框的尺寸
第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。先说一下匹配原则,对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个先验框与ground truth的IOU值(YOLOv2中bias_match=1),计算IOU值时不考虑坐标,只考虑形状,所以先将先验框与ground truth的中心点都偏移到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框与ground truth匹配,对应的预测框用来预测这个ground truth。在计算obj置信度时,target=1,但与YOLOv1一样而增加了一个控制参数rescore,当其为1时,target取预测框与ground truth的真实IOU值(cfg文件中默认采用这种方式)。对于那些没有与ground truth匹配的先验框(与预测框对应),除去那些Max_IOU低于阈值的,其它的就全部忽略,不计算任何误差。这点在YOLOv3论文中也有相关说明:YOLO中一个ground truth只会与一个先验框匹配(IOU值最好的),对于那些IOU值超过一定阈值的先验框,其预测结果就忽略了。这和SSD与RPN网络的处理方式有很大不同,因为它们可以将一个ground truth分配给多个先验框。尽管YOLOv2和YOLOv1计算loss处理上有不同,但都是采用均方差来计算loss。另外需要注意的一点是,在计算boxes的宽和 高 误差时,YOLOv1中采用的是平方根以降低boxes的大小对误差的影响,而YOLOv2是直接计算,但是根据ground truth的大小对权重系数进行修正:l.coord_scale * (2 - truth.w*truth.h)(这里w和h都归一化到(0,1)),这样对于尺度较小的boxes其权重系数会更大一些,可以放大误差,起到和YOLOv1计算平方根相似的效果
stronger
作者使用检测数据和分类数据进行联合训练,策略如下:
During training we mix images from both detection and classification datasets. When our network sees an image labelled for detection we can backpropagate based on the full YOLOv2 loss function. When it sees a classification image we only backpropagate loss from the classification-
specific parts of the architecture.
在训练的过程中,混合检测数据和分类数据。当网络发现一个图片有检测的标注,那么就是用yolov2的loss函数进行计算。当发现图片是分类的数据集时,计算loss的时候仅对分类的部分进行反向传播。
在coco和imagetnet的数据集上,有很多类别不是互斥的,比如“狗”和“柯基”的关系,实际上“柯基”属于“狗”这个类别。因此,作者使用了一种层级分类的方法。
WordNet is structured as a directed graph, not a tree, because language is complex.
作者使用了一种“wordNet"有向图结构(树)。根节点节点为physical object,然后根据类别依次设计对象的属性,如是否时动物,如果时动物,是猫,狗还鱼等等,最后得到更加具体的目标类别。比如,上面提到的“柯基”犬。
引用知乎上的解释
整个WordTree中的对象之间不是互斥的关系,但对于单个节点,属于它的所有子节点之间是互斥关系。比如terrier节点之下的Norfolk terrier、Yorkshire terrier、Bedlington terrier等,各品种的terrier之间是互斥的,所以计算上可以进行softmax操作。
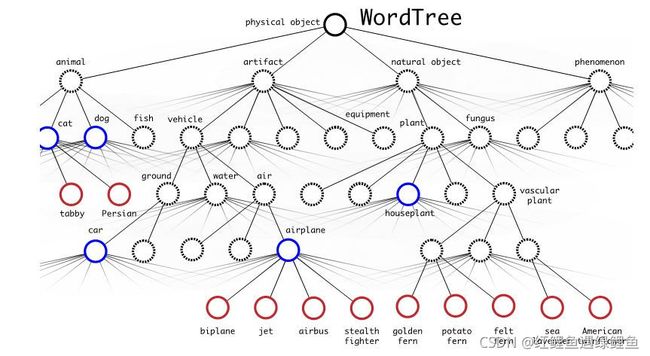
wordtree的构建:
引用知乎上的解释
构建好的WordTree有9418个节点(对象类型),包括ImageNet的Top
9000个对象,COCO对象,以及ImageNet对象检测挑战数据集中的对象,以及为了添加这些对象,从WordNet路径中提取出的中间对象。构建WordTree的步骤是:①检查每一个将用于训练和测试的ImageNet和COCO对象,在WordNet中找到对应的节点,如果该节点到WordTree根节点(physical
object)的路径只有一条(大部分对象都只有一条路径),就将该路径添加到WrodTree。②经过上面操作后,剩下的是存在多条路径的对象。对每个对象,检查其额外路径长度(将其添加到已有的WordTree中所需的路径长度),选择最短的路径添加到WordTree。这样就构造好了整个WordTree。
表达对象类别:
To perform classification with WordTree we predict conditional probabilities at every node for the probability of each hyponym of that synset given that synset.
作者使用条件概率的方式来表达目标的类别概率。
如:
Pr(Norfolk terrier|terrier)
Pr(Yorkshire terrier|terrier)
Pr(Bedlington terrier|terrier)
If we want to compute the absolute probability for a particular node we simply follow the path through the tree to the root node and multiply to conditional probabilities.
如果想要计算一个具体节点的概率,可以简单的将节点所在路径到根节点的条件概率值相乘。
如:
P(Norfolk terrier) = P(Norfolk terrier|terrier) * P(terrier|hunting dog) * P(hunting dog|dog) … P(animal|physical object) * P(physical object)
实际中并不计算出所有节点的绝对概率。而是采用一种比较贪婪的算法。从根节点开始向下遍历,对每一个节点,在它的所有子节点中,选择概率最大的那个(一个节点下面的所有子节点是互斥的),一直向下遍历直到某个节点的子节点概率低于设定的阈值(意味着很难确定它的下一层对象到底是哪个),或达到叶子节点,那么该节点就是该WordTree对应的对象。
在wordtree中,计算概率的方式使用的是softmax,但是要注意。同一个根节点下的子节点,使用一个softmax。如下图:
 可以看到,上图
可以看到,上图
联合训练:
imagenet样本比coco多,所以对coco样本会多做一些采样(oversampling),适当平衡一下样本数量,使两者样本数量比为4:1。
对于分类样本,则只计算分类误差。YOLO9000总共会输出13133=507个预测框(预测对象),计算它们对样本标签的预测概率,选择概率最大的那个框负责预测该样本的对象,即计算其WrodTree的误差。
参考:
https://zhuanlan.zhihu.com/p/47575929
https://zhuanlan.zhihu.com/p/35325884
https://www.bilibili.com/video/BV1yi4y1g7ro?p=2
感谢以上博主