Python 使用OpenCV计算机视觉(一篇文章从零毕业)【附带OCR文字识别项目、停车场车位智能识别项目】
OpenCV计算机视觉
文章目录
- OpenCV计算机视觉
-
- 1、参考文档
- 2、环境详情
- 3、安装
-
- 安装opencv-python
-
- 报错install pyproject.toml-based projects
- 安装opencv-contrib-python
- 4、图像基本操作
-
- 读取图像
- 图像展示,cv2.imshow()
- 获取图像hwc三个属性
- 图像保存,cv2.imwrite()
- 计算像素点个数
- 数据类型
- 截取部分图像数据
- 颜色通道提取,cv2.split()
- 颜色通道组合,cv2.merge()
- 拷贝图像
- 只保留单通道颜色
- 边界填充,cv2.copyMakeBorder()
- 每一个像素点加10
- 两个相同hw的图相加
- cv2.add()
- 图像拉伸,重新设置hw,cv2.resize()
- 图像融合,cv2.addWeighted()
- 5、视频基本操作
-
- 读取视频,cv2.VideoCapture()
- 6、图像阈值
-
- 阈值处理函数,cv2.threshold()
- 7、图像平滑
-
- 图像与滤波
- 均值滤波
- 方框滤波
- 高斯滤波
- 中值滤波
- 展示所有结果
- 8、形态学morphology
-
- 腐蚀操作,cv2.erode()
- 膨胀操作,cv2.dilate()
- 开运算与闭运算
- 梯度运算
- 礼帽与黑帽
- 9、图像梯度
-
- Sobel算子
-
- 算法:右-左,下-上
- 方法参数:
- Scharr算子
-
- 算法:右-左,下-上
- 方法示例
- laplacian算子
-
- 算法
- 参数示例
- 10、Canny边缘检测
-
-
- 1. 高斯滤波器
- 3. 非极大值抑制
- 4. 双阈值检测
-
- 11、图像金字塔
-
- 高斯金字塔
-
- 向下采样方法(缩小)
- 向上采样方法(放大)
- 拉普拉斯金字塔
- 12、图像轮廓:cv2.findContours()
-
- 轮廓检测cv2.findContours()及绘制cv2.drawContours()
-
- 方法参数
- 示例代码
- 轮廓特征计算
-
- 面积计算:cv2.contourArea()
- 周长计算:cv2.arcLength()
- 轮廓近似cv2.approxPolyDP()
- 边界矩形(外接矩形)
- 外接圆
- 模版匹配,cv2.matchTemplate(),cv2.minMaxLoc()
-
- cv2.matchTemplate()详解及单模版匹配代码示例
- 匹配多个对象
- 13、直方图
-
- 定义
- 计算直方图,cv2.calcHist()
-
- 参数详解
- 灰度图的示例代码
- 彩色图的示例代码
- mask操作的直方图代码示例
- 直方图均衡化
-
- 均衡化是什么及其原理
- 图像整体均衡化,cv2.equalizeHist()
- 自适应直方图均衡化(图像分块做均衡化)
- 14、傅里叶变换
-
-
- 傅里叶变换的作用
- 滤波
- 注意事项
- 执行傅里叶变换的示例代码,cv2.dft()
- 傅里叶变换的低通滤波实现图像模糊的示例代码
- 傅里叶变换的高通滤波实现图像细节增强的示例代码
-
- 15、项目实战:信用卡数字识别
- 16、项目实战:利用OpenCV工具包进行文档扫描OCR识别
-
- 如何实现扫描的效果(结合透视变换)
- 利用扫描结果进行OCR文字识别识别
-
- 安装tesseract
- 命令行方式使用tesseract
- Python使用tesseract
- 17、图像特征-harris角点检测cv2.cornerHarris()
-
- 基本原理
- 在OpenCV中进行角点检测
-
- cv2.cornerHarris()
- 18、图像特征-sift(Scale Invariant Feature Transform),即平移不变性的特征匹配算法
-
- 第一步:图像尺度空间
-
- 模糊
- 多分辨率金字塔
- 第二步:高斯差分金字塔(DOG)
-
- 定义公式
- 步骤
-
- DOG空间极值检测
- 关键点的精确定位
- 消除边界响应
- 特征点的主方向
- 生成特征描述
- OpenCV SIFT函数
-
- 降低OpenCV版本
- 代码
- 19、特征匹配
-
- Brute-Force蛮力匹配
-
- 1对1的匹配
- k对最佳匹配
- 随机抽样一致算法(Random sample consensus,RANSAC)
-
- RANSAC算法详解
-
- 单应性矩阵(也称为H矩阵)
- 示例应用实战:图像拼接
-
- 目的
- 思路
- 代码实现
- 20、项目实战-停车场车位识别
-
- 整体流程
- 安装准备工作
-
- 安装tensorflow
- 安装keras
- 项目代码
附带:《停车场车位智能识别》项目
项目最终效果:
本文使用到的图片请自行下载:
https://github.com/Sjenrey/learningOpenCV
1、参考文档
官网
下载地址
图像与滤波-阮一峰
LENA.JS-将滤波器拖到图像上,产生过滤后的效果
浏览器实现滤波的GitHub范例代码
2、环境详情
-
MacOS-10.14.6
-
Python3.9
-
numpy-1.22.4
- NumPy(Numerical Python)是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
-
matplotlib-3.5.2
- Matplotlib是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。
-
opencv-python-3.4.11.45
- opencv是用于快速处理图像处理、计算机视觉问题的工具,支持多种语言进行开发如c++、python、java等。
-
opencv-contrib-python-3.4.11.45
- opencv-contrib-python包含了主要模块以及扩展模块,扩展模块主要是包含了一些带专利的收费算法(如shift特征检测)以及一些在测试的新的算法(稳定后会合并到主要模块)。相当于加了一些额外的扩展,比如特征提取的一些算法,这些是OpenCV中没有的。
3、安装
安装opencv-python
pip3 install opencv-python
报错install pyproject.toml-based projects

- 访问opencv的镜像文件的网站,下载whl文件安装
https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/opencv-python/
- 找到适合自己的whl文件

我是MacOS10.14.6,Python3.9所以直接用下面链接下载即可:
https://mirrors.tuna.tsinghua.edu.cn/pypi/web/packages/1f/e0/187bf6941ad68e1c12d4e11d473d0841257aa388e3e88f1541f1f0c9a5dd/opencv_python-3.4.11.45-cp39-cp39-macosx_10_13_x86_64.whl#sha256=87015ea21e3f2faa7923cc3505e671b5e99b791fc812630f5d5ca4474387b242
- 下载完成后,进入opencv_python-3.4.11.45-cp39-cp39-macosx_10_13_x86_64.whl文件所在目录执行安装
pip3 install opencv_python-3.4.11.45-cp39-cp39-macosx_10_13_x86_64.whl
Successfully installed numpy-1.22.4 opencv-python-3.4.11.45
- 验证是否可以在Python中使用OpenCV
import cv2
安装opencv-contrib-python
注意需要和opencv-python版本号相同!
pip3 install opencv-contrib-python==3.4.11.45
Successfully installed opencv-contrib-python-3.4.11.45
到此为止,OpenCV和opencv-contrib都装好了。
4、图像基本操作
计算机是由每一个小格构成像素点来组成图像的。
像素点就是一个值,是在0~255之间的值,共计256个值,表示该点的亮度,0代表黑的,255代表最亮的。
RGB是三元色,叫图像的颜色通道。
黑白图也叫灰度图,只有一个通道,来表示亮度就足够了。

读取图像
这里用到的cat.jpg 是h=414,w=500,分辨率=72
# import matplotlib需要先安装,执行下面命令
pip3 install matplotlib
Successfully installed cycler-0.11.0 fonttools-4.33.3 kiwisolver-1.4.3 matplotlib-3.5.2 packaging-21.3 pillow-9.1.1 pyparsing-3.0.9
- 读取成彩色图像:
cv2.imread('cat.jpg', cv2.IMREAD_COLOR) - 读取成灰度图像:
cv2.imread('cat.jpg', cv2.IMREAD_GRAYSCALE)
import cv2 # opencv默认读取的格式是BGR,不是RGB
img = cv2.imread('cat.jpg') # 读取彩色图像
# print(type(img)) # [[[142 151 160] # 从左上角开始,第一行,B G R
[146 155 164]
[151 160 170]
...
[156 172 185]
[155 171 184]
[154 170 183]]
[[108 117 126] # 第二行
[112 123 131]
[118 127 137]
...
[155 171 184]
[154 170 183]
[153 169 182]]
...
[[140 164 176] # 第n-1行
[147 171 183]
[139 163 175]
...
[169 187 188]
[125 143 144]
[106 124 125]]
[[154 178 190] # 第n行
[154 178 190]
[121 145 157]
...
[183 198 200]
[128 143 145]
[127 142 144]]]
# 读取灰度图
img = cv2.imread("cat.jpg", cv2.IMREAD_GRAYSCALE)
print(img)
[[153 157 162 ... 174 173 172]
[119 124 129 ... 173 172 171]
[120 124 130 ... 172 171 170]
...
[187 182 167 ... 202 191 170]
[165 172 164 ... 185 141 122]
[179 179 146 ... 197 142 141]]
图像展示,cv2.imshow()
# 图像的显示,也可以创建多个窗口
cv2.imshow('image', img) # image是窗口的名字
# 等待时间,毫秒级(1000ms=1s),0表示任意键终止
cv2.waitKey(1000)
cv2.destroyAllWindows()
获取图像hwc三个属性
# 获取图像的hwc三个属性,h=height,w=width,c=3是RGB
print(img.shape) # (414, 500, 3)
图像保存,cv2.imwrite()
cv2.imwrite("mycat.png", img)
计算像素点个数
print(img.size) # 207000
数据类型
print(img.dtype) # uint8
截取部分图像数据
# ROI(region of interest,感兴趣区域)
cat = img[0:50, 0:200] # 从左上角:截取h=50,w=200像素点的区域
cv2.imshow('image', cat)
颜色通道提取,cv2.split()
b, g, r = cv2.split(img)
print(b) # 打印每一个像素点中的blue
# print(g)
# print(r)
# print(b.shape) # (414, 500)
[[142 146 151 ... 156 155 154] # 从左上角开始,第一行所有像素点中全部的Blue值
[108 112 118 ... 155 154 153] # 第二行
...
[140 147 139 ... 169 125 106] # 第n-1行
[154 154 121 ... 183 128 127]] # 第n行
# 只保留R
cur_img = img.copy()
cur_img[:,:,0]=0
cur_img[:,:,1]=0
颜色通道组合,cv2.merge()
# 接上提取操作后,把b、g、r组合成一张图片
img = cv2.merge((b, g, r)) # 这里的结果img还是原图
拷贝图像
cur_img = img.copy()
只保留单通道颜色
# 只保留R
cur_img = img.copy()
# []里是hwc三个属性,:代表取所有,h=height,w=width,c=0是B c=1是G c=2是R
cur_img[:, :, 0] = 0 # 设置B为0
cur_img[:, :, 1] = 0 # 设置G为0
cv2.imshow('image', cur_img) # image是窗口的名字
# 等待时间,毫秒级(1000ms=1s),0表示任意键终止
cv2.waitKey(1000)
cv2.destroyAllWindows()
# 只保留G
cur_img = img.copy()
cur_img[:, :, 0] = 0 # 设置B为0
cur_img[:, :, 2] = 0 # 设置R为0
# 只保留B
cur_img = img.copy()
cur_img[:, :, 1] = 0 # 设置G为0
cur_img[:, :, 2] = 0 # 设置R为0
边界填充,cv2.copyMakeBorder()
- ORIGINAL:原图
- BORDER_REPLICATE:复制法,也就是复制最边缘像素。
- BORDER_REFLECT:反射法,对感兴趣的图像中的像素在两边进行复制,边界重复,例如:fedcba|abcdefgh|hgfedcb
- BORDER_REFLECT_101:反射法,也就是以最边缘像素为轴,对称,边界不重复,gfedcb|abcdefgh|gfedcba
- BORDER_WRAP:外包装法cdefgh|abcdefgh|abcdefg
- BORDER_CONSTANT:常量法,常数值填充。
top_size, bottom_size, left_size, right_size = (50, 50, 50, 50)
replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE)
reflect = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_REFLECT)
reflect101 = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_REFLECT_101)
wrap = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_WRAP)
constant = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_CONSTANT, value=0)
cv2.imshow('image', constant) # image是窗口的名字
# 等待时间,毫秒级(1000ms=1s),0表示任意键终止
cv2.waitKey(10000)
cv2.destroyAllWindows()
每一个像素点加10
print(img)
img2 = img + 10
print(img2)
array([[142, 146, 151, ..., 156, 155, 154],
[107, 112, 117, ..., 155, 154, 153],
[108, 112, 118, ..., 154, 153, 152],
[139, 143, 148, ..., 156, 155, 154],
[153, 158, 163, ..., 160, 159, 158]], dtype=uint8)
# 加10以后
array([[152, 156, 161, ..., 166, 165, 164],
[117, 122, 127, ..., 165, 164, 163],
[118, 122, 128, ..., 164, 163, 162],
[149, 153, 158, ..., 166, 165, 164],
[163, 168, 173, ..., 170, 169, 168]], dtype=uint8)
两个相同hw的图相加
如果相加超过255,则需要减去256,因为是0~255,还有个0,所以要减256
print(img + img2)
array([[ 38, 46, 56, ..., 66, 64, 62],
[224, 234, 244, ..., 64, 62, 60],
[226, 234, 246, ..., 62, 60, 58],
[ 32, 40, 50, ..., 66, 64, 62],
[ 60, 70, 80, ..., 74, 72, 70]], dtype=uint8)
cv2.add()
和直接+运算不同的是,如果相加超过255,就取255
print(cv2.add(img, img2))
array([[255, 255, 255, ..., 255, 255, 255],
[224, 234, 244, ..., 255, 255, 255],
[226, 234, 246, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255],
[255, 255, 255, ..., 255, 255, 255]], dtype=uint8)
图像拉伸,重新设置hw,cv2.resize()
print(img.shape) # (414, 500, 3)
# 设置shape值,相当于是图像拉伸操作。
img_cat = cv2.resize(img, (1000, 814))
print(img_cat.shape) # (814,1000,3)
# 以倍数拉伸
print(img.shape) # (414, 500, 3)
res = cv2.resize(img, (0, 0), fx=0.4, fy=2) # x轴即w拉伸0.4倍,y轴即h拉伸2倍
print(res.shape) # (828, 200, 3)
图像融合,cv2.addWeighted()
把两个图像叠加成一张图像。
注意:如果两张图片的shape值是不同的,是不可以直接用+运算的。
图像融合公式: R = α x 1 + β x 2 + b R=\alpha x_1+\beta x_2+b R=αx1+βx2+b
α \alpha α: x 1 x_1 x1的权重
β \beta β: x 2 x_2 x2的权重
b b b:偏置项
x 1 x_1 x1:图像1
x 2 x_2 x2:图像2

print(img_cat + img_dog)
ValueError: operands could not be broadcast together with shapes (414,500,3) (429,499,3)
# 第一步:调整两张图片shape值为相等。
print(img_cat.shape) # (414,500,3)
print(img_dog.shape) # (429,499,3)
# 设置shape值,相当于是图像拉伸操作。
img_dog = cv2.resize(img_dog, (500, 414))
print(img_dog.shape) # (414,500,3)
# 第二步:根据融合公式进行融合
res = cv2.addWeighted(img_cat, 0.3, img_dog, 0.7, 0)
cv2.imshow('image', res) # image是窗口的名字
# 等待时间,毫秒级(1000ms=1s),0表示任意键终止
cv2.waitKey(10000)
cv2.destroyAllWindows()
5、视频基本操作
视频是由很多帧组成的,每一帧都可以当作是静止的图像,把很多张静止的图像连在一起就形成视频。
帧(frame);视频都是由一帧一帧组成的,每一帧其实是一个包含有音频视频信息的基本单位。
每秒传输的图片帧数,也可以理解为图形处理器每秒刷新的次数,通常以fps(Frames Per Second)表示。
读取视频,cv2.VideoCapture()
-
cv2.VideoCapture可以捕获摄像头,用数字来控制不同的设备,例如0,1 -
如果是视频文件,直接指定好路径即可。
import cv2 # opencv默认读取的格式是BGR,不是RGB
# cv2.VideoCapture可以捕获摄像头,用数字来控制不同的设备,例如0,1
# 如果是视频文件,直接指定好路径即可。
vc = cv2.VideoCapture("test.mp4")
# 检查是否打开正确
if vc.isOpened():
"""
is_open: bool,True/False
frame: 当前这一帧图像的像素点值,
read(): 读取视频的每一帧,可以写循环就读取所有帧了
"""
is_open, frame = vc.read()
else:
is_open = False
# 读取每一帧实现读取视频的效果
while is_open:
ret, frame = vc.read()
if frame is None:
break
if ret is True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转化成灰度图
cv2.imshow('result', gray) # 图像展示
"""cv2.waitKey(1)只能是integer,1代表PC能处理多快就多快,即处理完一帧要等少毫秒,所以视频是加速播放的。
27为ESC键,我们可以按ESC退出
13为ENTER键
9为TAB
20为Caps Lock键
"""
if cv2.waitKey(1) & 0xFF == 27:
break
vc.release()
cv2.destroyAllWindows()
6、图像阈值
首先,我们要求图像为灰度图,像素点值越接近255该点越亮。
其次,图像是由像素点组成,每一个像素点都是灰度的值,对每一个值进行判断,如果该值大于阈值,我们要怎么处理,小于要怎么处理。
# 灰度图的每一个像素点的list
[[153 157 162 ... 174 173 172]
[119 124 129 ... 173 172 171]
[120 124 130 ... 172 171 170]
...
[187 182 167 ... 202 191 170]
[165 172 164 ... 185 141 122]
[179 179 146 ... 197 142 141]]
阈值处理函数,cv2.threshold()
ret, dst = cv2.threshold(src, thresh, maxval, type)
-
src: 输入图,只能输入单通道图像,通常来说为灰度图
-
dst: 输出图
-
thresh: 阈值,不是百分比,是在0~255之前确定的值,比较常见的是127
-
maxval: 当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值,最大的值也就是255
-
type:二值化操作的类型,包含以下5种类型: cv2.THRESH_BINARY; cv2.THRESH_BINARY_INV; cv2.THRESH_TRUNC; cv2.THRESH_TOZERO;cv2.THRESH_TOZERO_INV
- cv2.THRESH_BINARY
- 超过阈值部分取maxval(最大值),否则取0
- cv2.THRESH_BINARY_INV
- THRESH_BINARY的反转
- cv2.THRESH_TRUNC
- 大于阈值部分设为阈值,否则不变。相当于指定一个截断值。
- cv2.THRESH_TOZERO
- 大于阈值部分不改变,否则设为0
- cv2.THRESH_TOZERO_INV
- THRESH_TOZERO的反转
- cv2.THRESH_BINARY
-
ret:你设置的thresh阈值的值,一般来说是用不到该返回变量的。
import cv2 # opencv默认读取的格式是BGR,不是RGB
import matplotlib.pyplot as plt
img = cv2.imread("cat.jpg", cv2.IMREAD_GRAYSCALE)
# BINARY,亮点的全为白,暗点的全为黑
ret, thresh1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
print(ret) # 127.0
# BINARY_INV,是BINARY的反转,即:亮点的全为黑,暗点的全为白
ret, thresh2 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY_INV)
# TRUNC,大于阈值部分设为阈值,否则不变,相当于指定一个截断值
ret, thresh3 = cv2.threshold(img, 127, 255, cv2.THRESH_TRUNC)
# TOZERO,大于阈值则不变,小于阈值全为黑
ret, thresh4 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO)
# TOZERO_INV,是TOZERO的反转,大于阈值全为黑,小于阈值则不变
ret, thresh5 = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO_INV)
titles = ['Original Image', 'BINARY', 'BINARY_INV', 'TRUNC', 'TOZERO', 'TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2, 3, i + 1), plt.imshow(images[i], 'gray')
plt.title(titles[i])
plt.xticks([]), plt.yticks([])
plt.show()
7、图像平滑
四种滤波:
- 均值滤波:cv2.blur()
- 方框滤波: cv2.boxFilter()
- 高斯滤波:cv2.GaussianBlur()
- 中值滤波:cv2.medianBlur()
图像与滤波
图像其实是一种波,可以用波的算法处理图像。
我们知道,图像由像素组成。下图是一张 400 x 400 的图片,一共包含了 16 万个像素点。

每个像素的颜色,可以用红、绿、蓝、透明度四个值描述,大小范围都是0 ~ 255,比如黑色是[0, 0, 0, 255],白色是[255, 255, 255, 255]。通过 Canvas API 就可以拿到这些值。
如果把每一行所有像素(上例是400个)的红、绿、蓝的值,依次画成三条曲线,就得到了下面的图形。

可以看到,每条曲线都在不停的上下波动。有些区域的波动比较小,有些区域突然出现了大幅波动(比如 54 和 324 这两点)。
对比一下图像就能发现,曲线波动较大的地方,也是图像出现突变的地方。

这说明波动与图像是紧密关联的。图像本质上就是各种色彩波的叠加。
两种常见的滤波器:
- 低通滤波器(lowpass):减弱或阻隔高频信号,保留低频信号
- 高通滤波器(highpass):减弱或阻隔低频信号,保留高频信号
lowpass使得图像的高频区域变成低频,即色彩变化剧烈的区域变得平滑,也就是出现模糊效果。
highpass正好相反,过滤了低频,只保留那些变化最快速最剧烈的区域,也就是图像里面的物体边缘,所以常用于边缘识别。

图像平滑:即对图像进行各种滤波操作。
下图即lenaNoise.png图片的原图,可以看到图片有一些白色的噪点。
现在我们想通过滤波或者是平滑处理操作,来尽可能去掉这些噪点。。
假设上图的像素点的矩阵为下图所示:

均值滤波
下述代码中的(3, 3)代表着上图黄色的区域(称为“核”,核一般是奇数,每3x3要进行一次计算),即处理值为204这个像素点的值,应该是和其周围像素点的值是比较相关的。所以,要使用该区域的9个像素点的均值来作为204这个像素点处理完后的值。
即: 121 + 75 + 78 + 24 + 204 + 113 + 154 + 104 + 235 9 \frac{121+75+78+24+204+113+154+104+235}{9} 9121+75+78+24+204+113+154+104+235

import cv2
img = cv2.imread("lenaNoise.png")
# 均值滤波
# 简单的平均卷积操作
blur = cv2.blur(img, (3, 3))
cv2.imshow('blur', blur)
cv2.waitKey(0)
cv2.destroyAllWindows()
方框滤波
和均值滤波一样,可以把boxFilter()和blur()当成一个,只不过boxFilter()多了一个参数。

import cv2
img = cv2.imread("lenaNoise.png")
# 方框滤波
# -1不用管是固定的,normalize=True代表做归一化操作(除9),此时和均值滤波一模一样
box = cv2.boxFilter(img,-1,(3,3), normalize=True)
cv2.imshow('box', box)
cv2.waitKey(0)
cv2.destroyAllWindows()
import cv2
img = cv2.imread("lenaNoise.png")
# 方框滤波
# normalize=False不做归一化操作(不除9),容易越界(值超过255则取255当作结果)
box = cv2.boxFilter(img,-1,(3,3), normalize=False)
cv2.imshow('box', box)
cv2.waitKey(0)
cv2.destroyAllWindows()
高斯滤波
高斯函数的意思就是越接近均值的时候,可能性越大。越接近x=0的时候y的值越大,即下图所示。
所以,要处理204这个像素点的值,那么离204点越近的点,可能性越大,即75、24、113、104点可能性更大,121、78、154、235点可能性小。

import cv2
img = cv2.imread("lenaNoise.png")
# 高斯滤波
# 高斯模糊的卷积核里的数值是满足高斯分布,相当于更重视中间的
aussian = cv2.GaussianBlur(img, (5, 5), 1)
cv2.imshow('aussian', aussian)
cv2.waitKey(0)
cv2.destroyAllWindows()
中值滤波
中值就是中间的值,所以需要从小到大排序,取中间的值。
即:24、75、78、104、113、121、154、204、235
所以,值为204的像素点经过中值滤波处理后的值就是113了。
所以,最后经过中值滤波处理的图像就没有噪点了。
import cv2
img = cv2.imread("lenaNoise.png")
# 中值滤波
# 相当于用中值代替
median = cv2.medianBlur(img, 5)
cv2.imshow('median', median)
cv2.waitKey(0)
cv2.destroyAllWindows()
展示所有结果
import cv2
import numpy as np
img = cv2.imread("lenaNoise.png")
# 均值滤波
blur = cv2.blur(img, (3, 3))
# 方框滤波
box1 = cv2.boxFilter(img, -1, (3, 3), normalize=True)
box2 = cv2.boxFilter(img, -1, (3, 3), normalize=False)
# 高斯滤波
aussian = cv2.GaussianBlur(img, (5, 5), 1)
# 中值滤波
median = cv2.medianBlur(img, 5)
# 展示所有的
# hstack是横向拼接展示;vstack是纵向拼接展示
res = np.hstack((blur, box1, box2, aussian, median))
# print(res)
cv2.imshow('median vs average', res)
cv2.waitKey(0)
cv2.destroyAllWindows()
8、形态学morphology
腐蚀操作,cv2.erode()
前提条件:图像一般都是2值的数据图像。
现在想把下图文字上的毛刺去掉。
缺点就是图像有价值的信息越来越少,即下图所示经过腐蚀操作后白色线条变细了。
场景:当我们的图像中有一些细线条的时候,我们可以用腐蚀操作去掉,再用膨胀操作复原。

import cv2
import numpy as np
img = cv2.imread('dige.png')
# 设置3x3的核心
kernel = np.ones((3, 3), np.uint8)
# iterations迭代次数,次数越多,白色字条越细,甚至消失。
erosion = cv2.erode(img, kernel, iterations=1)
res = np.hstack((img, erosion))
cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()
膨胀操作,cv2.dilate()
可以用来弥补腐蚀操作后图像中线条变细的情况。

import cv2
import numpy as np
img = cv2.imread('dige.png')
# 腐蚀操作
kernel = np.ones((3, 3), np.uint8)
erosion = cv2.erode(img, kernel, iterations=1)
# 膨胀操作
kernel = np.ones((3, 3), np.uint8)
dilate = cv2.dilate(erosion, kernel, iterations=1)
res = np.hstack((img, erosion, dilate))
cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()
开运算与闭运算
其实就是把腐蚀和膨胀总结成了一个方法cv2.morphologyEx()
import cv2
import numpy as np
# 开:先腐蚀,再膨胀
img = cv2.imread('dige.png')
kernel = np.ones((5, 5), np.uint8)
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
cv2.imshow('opening', opening)
cv2.waitKey(0)
cv2.destroyAllWindows()
import cv2
import numpy as np
# 闭:先膨胀,再腐蚀
img = cv2.imread('dige.png')
kernel = np.ones((5, 5), np.uint8)
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
cv2.imshow('closing', closing)
cv2.waitKey(0)
cv2.destroyAllWindows()
梯度运算
梯度=膨胀-腐蚀

import cv2
import numpy as np
# 梯度=膨胀-腐蚀
pie = cv2.imread('pie.png')
kernel = np.ones((7,7),np.uint8)
dilate = cv2.dilate(pie,kernel,iterations = 5)
erosion = cv2.erode(pie,kernel,iterations = 5)
res = np.hstack((dilate,erosion))
cv2.imshow('res', res)
cv2.waitKey(0)
cv2.destroyAllWindows()
import cv2
import numpy as np
# 梯度运算
pie = cv2.imread('pie.png')
kernel = np.ones((7, 7), np.uint8)
gradient = cv2.morphologyEx(pie, cv2.MORPH_GRADIENT, kernel)
cv2.imshow('gradient', gradient)
cv2.waitKey(0)
cv2.destroyAllWindows()
礼帽与黑帽
-
礼帽 = 原始输入-开运算结果
-
黑帽 = 闭运算-原始输入

import cv2
import numpy as np
img = cv2.imread('dige.png')
kernel = np.ones((7, 7), np.uint8)
# 礼帽
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
cv2.imshow('tophat', tophat)
cv2.waitKey(0)
cv2.destroyAllWindows()

import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('dige.png')
kernel = np.ones((7, 7), np.uint8)
# 黑帽
blackhat = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
cv2.imshow('blackhat', blackhat)
cv2.waitKey(0)
cv2.destroyAllWindows()
9、图像梯度
梯度=膨胀-腐蚀
梯度就是边界点。下图红线部分是没有梯度的,因为红线的左右两边都是白色的,红线部分也是白色的。
我们要做的就是把那些像素点有梯度给找出来,这样的事。相当于是做边缘检测。

Sobel算子
算法:右-左,下-上

在像素点层面执行找梯度操作,即像素点左右、上下颜色是不同的。


方法参数:
dst = cv2.Sobel(src, ddepth, dx, dy, ksize)
-
src:当前图像
-
ddepth:图像的深度,通常情况指定为-1,代表输出深度和输出深度是相同的。
-
dx、dy:分别表示水平和竖直方向
-
ksize:Sobel算子的大小,一般情况是3x3或5x5即写3或5就行。
import cv2
img = cv2.imread('pie.png')
"""
opencv的像素点的值是0~255的。
但是opencv默认会把两个像素点相减后得到的负值截断成0,但是正常情况咱们左右或者上下相减就是会有负值的情况。
cv2.CV_64F代表opencv支持负数的结果。
dx=1,dy=0代表现在算的是水平梯度,不算竖直梯度
"""
# Gx计算
sobel_x = cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=3)
# 白到黑是整数,黑到白就是负数了,所有的负数会被截断成0,我们算的是左右或者上下的差异,不关心值的正负,所以要取绝对值。
sobel_x = cv2.convertScaleAbs(sobel_x)
# Gy计算
sobel_y = cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=3)
sobel_y = cv2.convertScaleAbs(sobel_y)
# 图像融合,把Gx和Gy两张图融合在一起。
sobel_xy = cv2.addWeighted(sobel_x, 0.5, sobel_y, 0.5, 0)
cv2.imshow("image", sobel_xy)
cv2.waitKey()
cv2.destroyAllWindows()

# 也可以一起算Gx和Gy,但是不建议,效果不好
import cv2
img = cv2.imread('pie.png')
# Gx、Gy同时计算
sobel_xy = cv2.Sobel(img, cv2.CV_64F, 1, 1, ksize=3)
sobel_xy = cv2.convertScaleAbs(sobel_xy)
cv2.imshow("image", sobel_xy)
cv2.waitKey()
cv2.destroyAllWindows()

换个图片效果更明显:

Scharr算子
Scharr算子的计算方式和Sobel算子是一样的,只不过核的数值是有差异的。Scharr算子对结果的差异更敏感。
算法:右-左,下-上
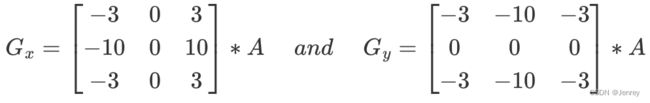
方法示例
import cv2
img = cv2.imread('lena.jpg', cv2.IMREAD_GRAYSCALE)
scharr_x = cv2.Scharr(img, cv2.CV_64F, 1, 0)
scharr_y = cv2.Scharr(img, cv2.CV_64F, 0, 1)
scharr_x = cv2.convertScaleAbs(scharr_x)
scharr_y = cv2.convertScaleAbs(scharr_y)
scharr_xy = cv2.addWeighted(scharr_x, 0.5, scharr_y, 0.5, 0)
cv2.imshow("image", scharr_xy)
cv2.waitKey()
cv2.destroyAllWindows()

laplacian算子
laplacian算子是二阶导,二阶导相当于是一阶导的变化率。laplacian算子对变化更敏感;
缺点就是对一些噪音点也比较敏感,这不是好事,因为噪音点不是边界。
通常情况下,laplacian算子要和其他方法一同使用,我们一般不会单独使用。
算法

参数示例
import cv2
img = cv2.imread('lena.jpg', cv2.IMREAD_GRAYSCALE)
laplacian = cv2.Laplacian(img, cv2.CV_64F)
laplacian = cv2.convertScaleAbs(laplacian)
cv2.imshow("image", laplacian)
cv2.waitKey()
cv2.destroyAllWindows()

10、Canny边缘检测
Canny进行边缘检测的流程:
- 使用高斯滤波器,以平滑图像,滤除噪声。
- 计算图像中每个像素点的梯度强度和方向。
- 应用 非极大值抑制(Non-Maximum Suppression),以消除边缘检测带来的杂散响应。
- 非极大值抑制:把极值小的给抑制掉,只保留极值大的,相当于把最明显的体现出来。
- 应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘。
- 通过抑制孤立的弱边缘最终完成边缘检测。
1. 高斯滤波器

###2. 梯度和方向

3. 非极大值抑制
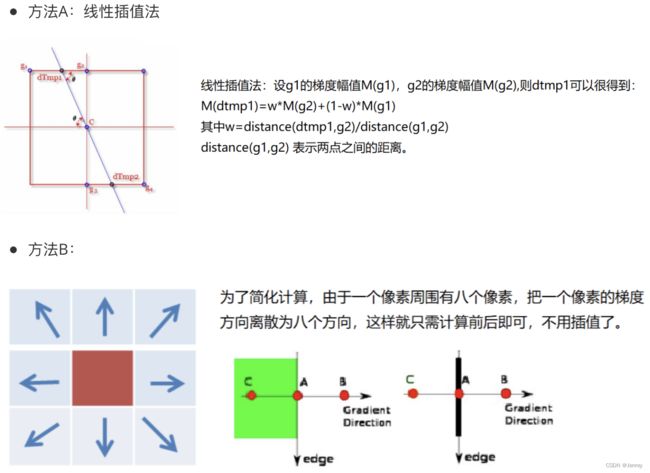
4. 双阈值检测

import cv2
import numpy as np
img = cv2.imread("lena.jpg", cv2.IMREAD_GRAYSCALE)
# 80是minVal,150是maxVal
v1 = cv2.Canny(img, 80, 150)
# minVal和maxVal越小,条件越松,边界越多
v2 = cv2.Canny(img, 50, 100)
res = np.hstack((v1, v2))
cv2.imshow("image", res)
cv2.waitKey()
cv2.destroyAllWindows()

v1=cv2.Canny(img,120,250)
v2=cv2.Canny(img,50,100)

11、图像金字塔
- 高斯金字塔
- 拉普拉斯金字塔
把图像组合成金字塔形状(即每层图像的大小不同);
用法就是比如在做图像的特征提取时,我们不光要对原始图像做特征提取,还要对金字塔不同层的图片做特征提取。

高斯金字塔
向下采样方法(缩小)
即从金字塔底向金字塔尖采样。
L0是800x800像素点的,那么L1就是4x4像素点的,以此类推。

向上采样方法(放大)
即从金字塔尖向金字塔底采样。
L4是2x2像素点,变换后就是4x4的像素点,以此类推。

import cv2
img = cv2.imread("AM.png")
print(img.shape) # (442, 340, 3)
# 向上采样
up = cv2.pyrUp(img)
print(up.shape) # (884, 680, 3)
# 向下采样
down = cv2.pyrDown(img)
print(down.shape) # (221, 170, 3)
cv2.imshow("image", up)
cv2.waitKey()
cv2.destroyAllWindows()
注意:比如原图先执行上采样,再执行下采样,虽然最后的图像和原图shape一样,但是色彩和清晰度会降低。因为上采样会增加一些0,下采样会损失一些信息。

拉普拉斯金字塔

import cv2
import numpy as np
img = cv2.imread("AM.png")
# print(img.shape) # (442, 340, 3)
down = cv2.pyrDown(img)
down_up = cv2.pyrUp(down)
l_1 = img - down_up
# print(l_1.shape) # (442, 340, 3)
res = np.hstack((img, l_1))
cv2.imshow("image", res)
cv2.waitKey()
cv2.destroyAllWindows()
12、图像轮廓:cv2.findContours()
- 边缘:有零零散散的线段。就是梯度之间发生一些事情,然后我们用梯度值把边缘摘出来。零零散散的线段是不能叫做图像轮廓的。
- 轮廓:轮廓的定义首先要是一个整体的连在一起的线。
轮廓检测cv2.findContours()及绘制cv2.drawContours()
注意:为了更高的准确率,请使用二值图像。
方法参数
cv2.findContours(img, mode, method)
- img:当前图像
- mode:轮廓检索模式
- RETR_EXTERNAL :只检索最外面的轮廓;
- RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中;
- RETR_CCOMP:检索所有的轮廓,并将他们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界;
- RETR_TREE:最常用的;检索所有的轮廓,并重构嵌套轮廓的整个层次;包含上述所有检测的模式,用什么模式就调用什么模式即可。
- method:轮廓逼近方法
- CHAIN_APPROX_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)。
- CHAIN_APPROX_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分。

示例代码
import cv2
import numpy as np
# 读取图像
img = cv2.imread('contours.png') # BGR图
# 把彩色图像转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
"""阈值处理函数cv2.threshold()
进行二值化操作(让黑白差异更明显)
cv2.THRESH_BINARY:超过阈值部分取maxval(最大值),否则取0;即亮点的全为白,暗点的全为黑
大于127取255,小于127取0
"""
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
"""轮廓检测函数cv2.findContours()
binary是二值图片可以直接展示;contours是list的轮廓点;hierarchy是结果的层级
"""
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
# print(np.array(contours))
"""绘制轮廓函数cv2.drawContours()
传入绘制图像draw_img,轮廓list点contours,轮廓索引-1(代表所有检测到的轮廓都画出来,只要不越界可以传入0、1、2...),轮廓线条的颜色模式(B,G,R),线条厚度2
注意需要copy,要不原图会变。"""
draw_img = img.copy()
draw_contours = cv2.drawContours(draw_img, contours, -1, (0, 0, 255), 2)
res = np.hstack((img, draw_contours))
cv2.imshow("image", res)
cv2.waitKey()
cv2.destroyAllWindows()

轮廓特征计算
面积计算:cv2.contourArea()
import cv2
# 读取图像
img = cv2.imread('contours.png') # BGR图
# 把彩色图像转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
"""阈值处理函数cv2.threshold()
进行二值化操作(让黑白差异更明显)
cv2.THRESH_BINARY:超过阈值部分取maxval(最大值),否则取0;即亮点的全为白,暗点的全为黑
大于127取255,小于127取0
"""
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
"""轮廓检测函数cv2.findContours()
binary是二值图片可以直接展示;contours是list的轮廓点;hierarchy是结果的层级
"""
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
# print(np.array(contours))
print(type(contours))
# 轮廓特征:计算面积
cnt = contours[0] # 取索引为0的轮廓
print("面积:", cv2.contourArea(cnt)) # 面积: 8500.5
周长计算:cv2.arcLength()
import cv2
# 读取图像
img = cv2.imread('contours.png') # BGR图
# 把彩色图像转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
"""阈值处理函数cv2.threshold()
进行二值化操作(让黑白差异更明显)
cv2.THRESH_BINARY:超过阈值部分取maxval(最大值),否则取0;即亮点的全为白,暗点的全为黑
大于127取255,小于127取0
"""
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
"""轮廓检测函数cv2.findContours()
binary是二值图片可以直接展示;contours是list的轮廓点;hierarchy是结果的层级
"""
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
# print(np.array(contours))
print(type(contours))
cnt = contours[0] # 取索引为0的轮廓
# True表示闭合的
print("周长:", cv2.arcLength(cnt, True)) # 周长: 437.9482651948929
轮廓近似cv2.approxPolyDP()
一些不规则的轮廓可以近似成比较规则的形状,比如近似成矩形,曲线轮廓近似成直线等等。

import cv2
import numpy as np
# 读取图像,原图,BGR格式
img = cv2.imread('contours2.png')
# 制作灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 制作二值图
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 找轮廓
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0] # 取索引为0的轮廓
# 画原始轮廓图像
draw_img = img.copy()
draw_contours = cv2.drawContours(draw_img, [cnt], -1, (0, 0, 255), 2)
# 轮廓的周长计算,取0.1倍的周长作为后面的近似阈值参数,如果指定0.01则得到的近似轮廓越接近原轮廓
epsilon = 0.1 * cv2.arcLength(cnt, True)
# 轮廓近似函数,cnt轮廓信息,epsilon用来做近似的阈值(一般是按照周长的百分比做设置的)
approx = cv2.approxPolyDP(cnt, epsilon, True)
# 画轮廓近似图像
draw_approx_img = img.copy()
draw_approx_contours = cv2.drawContours(draw_approx_img, [approx], -1, (0, 0, 255), 2)
# 展示原始图像、轮廓图像、轮廓近似图像
res = np.hstack((img, draw_contours, draw_approx_contours))
cv2.imshow("image", res)
cv2.waitKey()
cv2.destroyAllWindows()

边界矩形(外接矩形)
用法例如可以用来算轮廓面积与边界矩形比,或者基于外接矩形构建额外特征
import cv2
import numpy as np
img = cv2.imread('contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
"""
cv2.boundingRect(cnt)函数:
cnt是一个轮廓点集合,也就是它的参数,可以通过cv2.findContours获取
返回四个值,分别是x,y,w,h
x,y是矩阵左上点的坐标,w,h是矩阵的宽和高
"""
x, y, w, h = cv2.boundingRect(cnt)
draw_rectangle = img.copy()
"""
cv2.rectangle()画出矩行:
第一个参数:img是原图
第二个参数:(x,y)是矩阵的左上点坐标
第三个参数:(x+w,y+h)是矩阵的右下点坐标
第四个参数:(0,255,0)是画线对应的rgb颜色
第五个参数:2是所画的线的宽度
"""
draw_rectangle_img = cv2.rectangle(draw_rectangle, (x, y), (x + w, y + h), (0, 255, 0), 2)
res = np.hstack((img, draw_rectangle_img))
cv2.imshow("image", res)
cv2.waitKey()
cv2.destroyAllWindows()
area = cv2.contourArea(cnt) # 计算原始轮廓面积
x, y, w, h = cv2.boundingRect(cnt)
rect_area = w * h
extent = float(area) / rect_area
print('轮廓面积与边界矩形比', extent) # 0.5154317244724715
外接圆
import cv2
import numpy as np
img = cv2.imread('contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
(x, y), radius = cv2.minEnclosingCircle(cnt)
center = (int(x), int(y))
radius = int(radius)
draw_circle = img.copy()
draw_circle_img = cv2.circle(draw_circle, center, radius, (0, 255, 0), 2)
res = np.hstack((img, draw_circle_img))
cv2.imshow("image", res)
cv2.waitKey()
cv2.destroyAllWindows()

模版匹配,cv2.matchTemplate(),cv2.minMaxLoc()
模版匹配和卷积原理很像,模版在原图像上从原点开始滑动,计算模版与(图像被模版覆盖的地方)的差别程度,这个差别程度的计算方法在opencv中有6种,然后将每次计算的结果放入一个矩阵里,作为结果输出。
假如原图形是 A × B A\times B A×B 大小,而模版是 a × b a\times b a×b 大小,则输出结果的矩阵是 ( A − a + 1 ) × ( B − b + 1 ) (A-a+1)\times(B-b+1) (A−a+1)×(B−b+1)
比如我们之前用到的lena图片,我们把人物的脸截出来,现在希望得知脸是在原始图像中哪个部分。

cv2.matchTemplate()详解及单模版匹配代码示例
opencv是从左到右,从上到下进行匹配。
- TM_SQDIFF:真值为0,计算平方不同,计算出来的值越小,越相关
- TM_CCORR:真值为2,计算相关性,计算出来的值越大,越相关
- TM_CCOEFF:真值为4,计算相关系数,计算出来的值越大,越相关
- TM_SQDIFF_NORMED:真值为1,计算归一化平方不同,计算出来的值越接近0,越相关
- TM_CCORR_NORMED:真值为3,计算归一化相关性,计算出来的值越接近1,越相关
- TM_CCOEFF_NORMED:真值为5,计算归一化相关系数,计算出来的值越接近1,越相关
真值就是简写,可以传0、1、2、3、4、5的真值,也可以传匹配模式的类型,注意类型不是字符串。
公式
用TM_SQDIFF匹配模式做的代码示例:
import cv2
import matplotlib.pyplot as plt
# 加载图片及预处理
img = cv2.imread('lena.jpg', 0)
# print(img.shape) # (263,263)
template = cv2.imread('face.jpg', 0)
# print(template.shape) # (93, 81)
h, w = template.shape[:2] # 93 81
"""cv2.matchTemplate()模版匹配函数
在源图像上从左到右,从上到下滑动模板,在每一个位置都计算一个指标以表明这个位置处 两个图像块之间匹配程度的高低。
最终将不同位置的相似度结果,存储在我们的结果矩阵res中。
img输入图像:包含我们要检测的对象的图像
template模板图像:对象的图像
1:模板匹配方法,或者写cv2.TM_SQDIFF等等,建议使用带归一化的匹配方法结果更可靠
res返回值:输出结果是具有特定尺寸的相似度结果矩阵
宽度: image.shape [ 1 ] - template.shape [ 1 ] + 1
高度: image.shape [ 0 ] - template.shape [ 0 ] + 1
"""
res = cv2.matchTemplate(img, template, cv2.TM_SQDIFF)
# print(res)
# print(res.shape) # 263-93+1=171,263-81+1=183 (171, 183)
"""cv2.minMaxLoc()找出矩阵最小值和最大值的位置
不同匹配methods,取各自对应的min_location或max_location
如cv2.TM_SQDIFF方法匹配,则min_location就是最小差异值的点即此点两图最相关,即目标图在原图中匹配到的最相关位置的左上角的点
下一步,我们知道了左上角的点,我们还知道template的w、h值,就可以把人脸框画出来了
"""
min_val, max_val, min_location, max_location = cv2.minMaxLoc(res)
# print(min_val, max_val) # 128626792.0 212456176.0
# 画矩形
draw_img = img.copy()
top_left = min_location
# print(top_left) # (110, 98)
bottom_right = (top_left[0] + w, top_left[1] + h)
# print(bottom_right) # (191, 191)
draw_contours = cv2.rectangle(draw_img, top_left, bottom_right, 255, 2)
# 展示
titles = ['Template', 'Original Image', 'matchTemplate']
images = [template, img, draw_contours]
for i in range(len(images)):
plt.subplot(2, 3, i + 1)
# 直接使用plt显示图像,它默认使用三通道显示图像,所以这里要加参数,否则灰度图展示出来发绿:cmap=plt.get_cmap('gray')或cmap='Greys_r'
plt.imshow(images[i], cmap='Greys_r')
plt.title(titles[i])
# plt.xticks([]), plt.yticks([])
plt.show()

用所有匹配模式做的代码示例:
import cv2
import matplotlib.pyplot as plt
# 加载图片及预处理
img = cv2.imread('lena.jpg', 0)
# print(img.shape) # (263,263)
template = cv2.imread('face.jpg', 0)
# print(template.shape) # (93, 81)
h, w = template.shape[:2] # 93 81
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR', 'cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF',
'cv2.TM_SQDIFF_NORMED']
for meth in methods:
img2 = img.copy()
# 匹配方法的真值
method = eval(meth)
# print(meth, method) # methods对应的4、5、2、3、0、1
res = cv2.matchTemplate(img, template, method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 如果是平方差匹配TM_SQDIFF或归一化平方差匹配TM_SQDIFF_NORMED,去最小值
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
# 画矩形
cv2.rectangle(img2, top_left, bottom_right, 255, 2)
plt.subplot(121) # 和plt.subplot(1, 2, 1)写法等效
plt.imshow(res, cmap='gray')
plt.xticks([]), plt.yticks([]) # 隐藏坐标轴
plt.subplot(122), plt.imshow(img2, cmap='gray')
plt.xticks([]), plt.yticks([]) # 隐藏坐标轴
plt.suptitle(meth)
plt.show()
下图为所有匹配模式的结果展示,以及各自的res相似度结果矩阵绘图。
在res相似度结果矩阵图中,最亮的位置表示最佳匹配位置,而暗区表示源图像和模板图像之间的相关性很小。

最亮的位置以下图的方式可以更直观的理解:


匹配多个对象
import cv2
import numpy as np
img = cv2.imread('mario.png')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
template = cv2.imread("mario_coin.png", 0)
h, w = template.shape[:2]
res = cv2.matchTemplate(img_gray, template, cv2.TM_CCOEFF_NORMED)
threshold = 0.8
# 取匹配程度大于80%的坐标
loc = np.where(res >= threshold)
for pt in zip(*loc[::-1]): # *代表可选参数
bottom_right = (pt[0] + w, pt[1] + h)
cv2.rectangle(img, pt, bottom_right, (0, 0, 255), 1)
cv2.imshow('images', img)
cv2.waitKey(0)

13、直方图
定义
下图左图是图像的灰度图的像素点。右图是直方图。
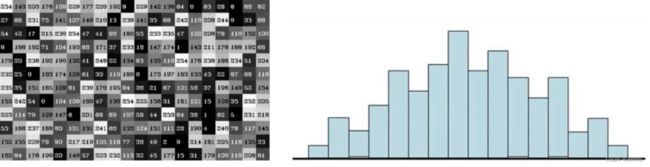
计算直方图,cv2.calcHist()
参数详解
cv2.calcHist(images,channels,mask,histSize,ranges)
- images:待统计成直方图的图像。通常我们都是转化成灰度图图像传入。原图像的图像格式为uint8或float32。当传入函数时应 用中括号[]括起来,例如[img]
- channels:通道。同样需要用中括号括起来;如果入图像是灰度图,它的值就是[0];如果是彩色图像的传入的参数可以是[0][1][2],它们分别对应着BGR。
- mask:掩模图像。如果要统计整幅图像的直方图,就把它设置为None;但是如果你想统计图像某一部分的直方图,你就制作一个掩模图像并使用它。
- histSize:BIN的数目。也就是直方图柱子的数量,[256]代表从灰度0到灰度255都要统计,也就是256个柱子。我们也可以把统计的范围压缩小一点,比如直方图第一个柱子是010,第二个柱子是1120的等等。也要用中括号括起来。
- ranges:像素值范围,常为[0,256]
灰度图的示例代码
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('cat.jpg', 0)
# 计算图像的直方图
hist = cv2.calcHist([img], [0], None, [256], [0, 256])
# 也可以用plt.hist(img.ravel(), 256)计算直方图
# print(hist.shape) # (256, 1) 1代表二维的,每个柱子出现多少个。
plt.hist(img.ravel(), 256)
plt.show()

彩色图的示例代码
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('cat.jpg')
color = ('b', 'g', 'r')
for i, col in enumerate(color):
# print(i, col) # 枚举类型,0 b、1 g、2 r
histr = cv2.calcHist([img], [i], None, [256], [0, 256])
plt.plot(histr, color=col)
plt.xlim([0, 256])
plt.show()

mask操作的直方图代码示例
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('cat.jpg', 0)
# print(img.shape) # (414, 500, 3)
# print(img.shape[:2]) # (414, 500)
# 创建mask
mask = np.zeros(img.shape[:2], np.uint8) # 返回给定形状和类型的新数组,用零填充(纯黑图)。
mask[100:300, 100:400] = 255 # 编辑变量mask的图:左上角开始:h=从100~300,w=从100~400 设置为纯白
# 与操作;0与1是0
masked_img = cv2.bitwise_and(img, img, mask=mask)
# 计算直方图
hist_full = cv2.calcHist([img], [0], None, [256], [0, 256])
hist_mask = cv2.calcHist([img], [0], mask, [256], [0, 256])
# 展示
# plt调整子图样式;wspace=左右边距、hspace=上下边距
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.35, hspace=None)
# plt.subplot(232)的意思是:2行3列布局,放在索引为2的位置
plt.subplot(231), plt.imshow(img, 'gray'), plt.title('Original Image')
plt.subplot(232), plt.imshow(mask, 'gray'), plt.title('mask')
plt.subplot(233), plt.imshow(masked_img, 'gray'), plt.title('masked_img')
# plt.xlim() 显示的是x轴的作图范围,plt会默认在x轴图像结束后再加一段空白显得好看些,这里我们不需要
plt.subplot(234), plt.plot(hist_full), plt.title('hist_full'), plt.xlim([0, 256])
plt.subplot(235), plt.plot(hist_mask), plt.title('hist_mask'), plt.xlim([0, 256])
# 把hist_full和hist_mask叠加在一个子图中显示
plt.subplot(236), plt.plot(hist_full), plt.plot(hist_mask), plt.title('overlay'), plt.xlim([0, 256])
plt.show()
直方图均衡化
均衡化是什么及其原理
下图我们发现,有些位置值特别多,有些位置值特别少。
我们做了均衡处理后,有时候图像的色彩和亮度能有稍微的提升。

下图左表我们认为是原图像的像素点的灰度值即可,是不均衡的。
下图右表我们认为是做了均衡化后的图像像素点的灰度值即可,是均衡的。

-
概率:当前灰度值概率 = 当前灰度值像素个数 / 总像素个数
- 先把总的像素个数统计出来为16个像素点,而后灰度值50的点有4个,则其概率为4/16=0.25
-
累积概率:当前灰度值点的累积概率 = 当前灰度值点的概率 + 之前所有行灰度值点的概率。
- 灰度值50的点是第一个,所以累积概率等于概率 +0,即0.25
- 灰度值128的点的概率为0.1875,则为0.25+0.1875=0.4375
-
映射后的灰度值:累积概率 * (255-0)
- 255-0 是取值范围
- 灰度值128的点:0.4375 * (255-0) = 111.5625
-
取整:四舍五入
- 即原来像素点灰度值为50的,均衡后为灰度值64
- 即原来像素点灰度值为128的,均衡后为灰度值112
图像整体均衡化,cv2.equalizeHist()
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('cat.jpg', 0)
# print(img.shape) # (414, 500)
# 均衡后的灰度图像
equ = cv2.equalizeHist(img)
# print(equ.shape) # (414, 500)
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.35, hspace=0.5)
plt.subplot(321), plt.imshow(img, 'gray'), plt.title('Original Image')
plt.subplot(322), plt.imshow(equ, 'gray'), plt.title('Equalize Image')
plt.subplot(323), plt.hist(img.ravel(), 256), plt.title('Original hist'), plt.xlim([0, 256])
plt.subplot(324), plt.hist(equ.ravel(), 256), plt.title('Equalize hist'), plt.xlim([0, 256])
plt.subplot(313), plt.hist(img.ravel(), 256), plt.hist(equ.ravel(), 256), plt.title('overlay hist'), plt.xlim([0, 256])
plt.show()
由上图可知,做了均衡化后,石膏人脸的一些细节丢失。这是因为本来属于自己的特征,咱们做了整体上的平均,所以我们应该给图像分块做均衡化操作。
分块后做均衡化也有个问题,就是图像噪点就会产生影响,没准还不如整体取做均衡化。这个自己把握吧。
自适应直方图均衡化(图像分块做均衡化)
如果以每一个块去做均衡化,做完之后会在块的边界处产生色彩上的边界的视觉效果,但是不用担心,opencv在做完均衡化后会进行线性的差值处理,即对每一个块的结果再进行处理的。
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('clahe.jpg', 0)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
res_clahe = clahe.apply(img)
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=0.35, hspace=0.5)
plt.subplot(321), plt.imshow(img, 'gray'), plt.title('Original Image')
plt.subplot(322), plt.imshow(res_clahe, 'gray'), plt.title('clahe Image')
plt.subplot(323), plt.hist(img.ravel(), 256), plt.title('Original hist'), plt.xlim([0, 256])
plt.subplot(324), plt.hist(res_clahe.ravel(), 256), plt.title('clahe hist'), plt.xlim([0, 256])
plt.subplot(313), plt.hist(img.ravel(), 256), plt.hist(res_clahe.ravel(), 256), plt.title('overlay hist'), plt.xlim([0, 256])
plt.show()
由上图可知,现在人脸的细节很好的被保留下来了。下面直接放上对比图。

14、傅里叶变换
我们生活在时间的世界中,早上7:00起来吃早饭,8:00去挤地铁,9:00开始上班。。。以时间为参照就是 时域 分析。
但是在 频域 中一切都是静止的!即上帝视角看,你在每周中,你每天都要吃饭,每个工作日都要挤地铁,每天都要上班。我们不需要关心什么时间做了什么事,而要关心你做了哪些事,做这些事的间隔频率。
所以我们需要在频域中对图像进行描述。
傅里叶分析之掐死教程
傅里叶变换的作用
-
高频:变化剧烈的灰度分量,例如图像的边界
-
低频:变化缓慢的灰度分量,例如一片大海
滤波
-
低通滤波器:只保留低频,会使得图像模糊
-
高通滤波器:只保留高频,会使得图像细节增强
注意事项
-
opencv中主要就是cv2.dft()和cv2.idft(),输入图像需要先转换成np.float32 格式。
- cv2.dft():执行傅里叶变换
- cv2.idft():执行傅里叶逆变换
-
得到的结果中频率为0的部分会在左上角,通常要转换到中心位置,可以通过shift变换来实现。
-
cv2.dft()返回的结果是双通道的(实部,虚部),通常还需要转换成图像格式才能展示(0,255)。
执行傅里叶变换的示例代码,cv2.dft()
import numpy as np
import cv2
from matplotlib import pyplot as plt
# 载入图像的灰度图
img = cv2.imread('lena.jpg', 0)
# 进行傅里叶变换前的准备,把图片格式转换成np.float32格式。
img_float32 = np.float32(img)
# 执行傅里叶变换
dft = cv2.dft(img_float32, flags=cv2.DFT_COMPLEX_OUTPUT)
# 使用np的fftshift变换把傅里叶变换后的频值为0的部分 从左上角转换到中间位置
dft_shift = np.fft.fftshift(dft)
# 得到灰度图能表示的形式
magnitude_spectrum = 20 * np.log(cv2.magnitude(dft_shift[:, :, 0], dft_shift[:, :, 1]))
plt.subplot(121), plt.imshow(img, cmap='gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(magnitude_spectrum, cmap='gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()
Magnitude Spectrum图片就是得到的频率结果(傅里叶图,可以理解为滤波图),中间点比较亮,即越靠近中间的亮点,频值越低。越高频越向周边发散。
傅里叶变换的低通滤波实现图像模糊的示例代码
import numpy as np
import cv2
from matplotlib import pyplot as plt
# 载入图像的灰度图
img = cv2.imread('lena.jpg', 0)
# 进行傅里叶变换前的准备,把图片格式转换成np.float32格式。
img_float32 = np.float32(img)
# dft,执行傅里叶变换
dft = cv2.dft(img_float32, flags=cv2.DFT_COMPLEX_OUTPUT)
# 使用np的fftshift变换把傅里叶变换后的频值为0的部分 从左上角转换到中间位置
dft_shift = np.fft.fftshift(dft)
# 获取原图的大小及中心点位置
rows, cols = img.shape
crow, ccol = int(rows / 2), int(cols / 2) # 中心位置
"""创建mask,即创建掩模图像
30的意思是,以中心点为基础,向四周30个像素单位画正方形,即在傅里叶变换后的滤波图中取到了较亮的部分,也就是自己构建了一个低通滤波器
"""
mask = np.zeros((rows, cols, 2), np.uint8) # np.zeros会初始化一张纯黑的图
mask[crow - 30:crow + 30, ccol - 30:ccol + 30] = 1 # 除了0,写啥都想,推荐1或者255都行
fshift = dft_shift * mask # 把mask掩模图像和傅里叶变换后的结果结合在一起,是1的就保留下来,不是1的就全部过滤掉,即低通滤波能通过的低频
f_ishift = np.fft.ifftshift(fshift) # 把傅里叶变换后的频值为0的部分 从中间位置还原到左上角位置
# idft,傅里叶逆变换成原始图像
img_back = cv2.idft(f_ishift) # 这个结果图片还不能看,因为还是双通道的有实部和虚部,还不是一个图像
img_back = cv2.magnitude(img_back[:, :, 0], img_back[:, :, 1]) # 对实部和虚部进行处理,处理成一个能看的图像
# 展示
plt.subplot(121), plt.imshow(img, cmap='gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(img_back, cmap='gray')
plt.title('Lowpass Image'), plt.xticks([]), plt.yticks([])
plt.show()
傅里叶变换的高通滤波实现图像细节增强的示例代码
import numpy as np
import cv2
from matplotlib import pyplot as plt
# 载入图像的灰度图
img = cv2.imread('lena.jpg', 0)
# 进行傅里叶变换前的准备,把图片格式转换成np.float32格式。
img_float32 = np.float32(img)
# dft,执行傅里叶变换
dft = cv2.dft(img_float32, flags=cv2.DFT_COMPLEX_OUTPUT)
# 使用np的fftshift变换把傅里叶变换后的频值为0的部分 从左上角转换到中间位置
dft_shift = np.fft.fftshift(dft)
# 获取原图的大小及中心点位置
rows, cols = img.shape
crow, ccol = int(rows / 2), int(cols / 2) # 中心位置
"""创建mask,即创建掩模图像
30的意思是,以中心点为基础,向四周30个像素单位画正方形,即在傅里叶变换后的滤波图中把较亮的部分置于0,即该部分不要,也就是自己构建了一个高通滤波器
"""
mask = np.ones((rows, cols, 2), np.uint8) # 返回给定形状和类型的新数组,其中全部填充了1。
mask[crow - 30:crow + 30, ccol - 30:ccol + 30] = 0
fshift = dft_shift * mask # 把mask掩模图像和傅里叶变换后的结果结合在一起,是1的就保留下来,不是1的就全部过滤掉
f_ishift = np.fft.ifftshift(fshift) # 把傅里叶变换后的频值为0的部分 从中间位置还原到左上角位置
# idft,傅里叶逆变换成原始图像
img_back = cv2.idft(f_ishift) # 这个结果图片还不能看,因为还是双通道的有实部和虚部,还不是一个图像
img_back = cv2.magnitude(img_back[:, :, 0], img_back[:, :, 1]) # 对实部和虚部进行处理,处理成一个能看的图像
# 展示
plt.subplot(121), plt.imshow(img, cmap='gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122), plt.imshow(img_back, cmap='gray')
plt.title('Highpass Image'), plt.xticks([]), plt.yticks([])
plt.show()
15、项目实战:信用卡数字识别
载入一张银行卡的图片:
- 需要把银行卡卡号按照每4个数字一组进行分组,比如第一组是4000,第二组是1234,第三组是5678,第四组是9010
- 把银行卡号识别出来,并且告诉我这个数对应的位置,让计算机能知道卡号4就是数字4
思路:
- 对银行卡的数字模版的数字做轮廓检测,使用外轮廓。
- 把每一个数字的外轮廓得到为外接矩形。
- for循环,把每一个数字的外接均线轮廓做一个resize
最终项目效果:

"""
pip3 install imutils
"""
# 导入工具包
from imutils import contours
import numpy as np
import argparse
import cv2
# 设置参数,也可以直接把图片地址传入
# ap = argparse.ArgumentParser() # ArgumentParser()用于将命令行字符串解析为Python对象的对象。
# ap.add_argument("-i", "--image", required=True, help="path to input image") # 添加参数操作
# ap.add_argument("-t", "--template", required=True, help="path to template OCR-A image") # 添加参数操作
# args = vars(ap.parse_args())
# 指定信用卡类型,根据卡号开头的第一个数字即可分别信用卡类型
FIRST_NUMBER = {
"3": "American Express",
"4": "Visa",
"5": "MasterCard",
"6": "Discover Card"
}
# SECTION: 图片展示方法
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 轮廓排序方法,和contours.sort_contours()的源码一样
def sort_contours(contours, method="left-to-right"):
reverse = False
i = 0
if method == "right-to-left" or method == "bottom-to-top":
reverse = True
if method == "top-to-bottom" or method == "bottom-to-top":
i = 1
"""cv2.boundingRect(cnt)函数:
cnt是一个轮廓点集合,也就是它的参数,可以通过cv2.findContours获取
返回四个值,分别是x,y,w,h
x,y是矩阵左上点的坐标,w,h是矩阵的宽和高
"""
bounding_boxes = [cv2.boundingRect(c) for c in contours] # 返回一个list,list中每一个元素都是(x,y,h,w)
# print(bounding_boxes) # [(730, 20, 54, 85), (651, 20, 53, 85)...(15, 20, 53, 85)]
"""对轮廓的array按照每一个轮廓的左上角的x点进行排序:这样就可以知道哪个轮廓在前,哪个轮廓在后
内层zip():把contours中每一个轮廓的数组与其对应的(x,y,h,w)打包到一起
sorted():可以对可迭代类型的容器内的数据进行排序
key:用来接收一个自定义的排序规则
reverse:选择升序还是降序排列方式,当需要降序排序时,需要使用reverse = True
"""
(contours, boundingBoxes) = zip(*sorted(zip(contours, bounding_boxes), key=lambda b: b[1][i], reverse=reverse))
return contours, boundingBoxes
# resize方法
def my_resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
return resized
"""1、载入数字模版图像并转化成二值图
"""
# 读取一个银行卡数字的模板图像
img = cv2.imread("images/ocr_a_reference.png")
# cv_show('img', img)
# 转化成灰度图
ref = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# cv_show('ref', ref)
# 转化成二值图像
ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]
# cv_show('ref', ref)
""""2、计算轮廓
2.1、轮廓检测:cv2.findContours()
cv2.findContours()函数接受的参数为二值图,即纯黑纯白的(不是灰度图)
cv2.RETR_EXTERNAL只检测外轮廓
cv2.CHAIN_APPROX_SIMPLE只保留终点坐标
返回的list中每个元素都是图像中的一个轮廓
2.2、绘制轮廓:cv2.drawContours()
img:传入待绘制图像
ref_contours:轮廓list点
-1:轮廓索引(代表所有检测到的轮廓都画出来,只要不越界可以传入0、1、2...)
(0,0,255):轮廓线条的颜色模式(B,G,R),纯红色的轮廓线条
3:轮廓绘制的线条厚度
2.3、对轮廓进行排序:sort_contours()
因为现在不一定数字0的轮廓是第一个,数字1的轮廓是第二个...
所以要进行排序,
"""
# 轮廓检测
ret, ref_contours, hierarchy = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 绘制轮廓
cv2.drawContours(img, ref_contours, -1, (0, 0, 255), 3)
# cv_show('img', img)
# print(np.array(ref_contours).shape)
# 对轮廓Array中的每一个轮廓按照其左上角的点的x值进行排序,并返回排序后的轮廓Array
ref_contours = sort_contours(ref_contours, method="left-to-right")[0] # 排序,从左到右,从上到下
# 遍历每一个轮廓,把每一个轮廓都设置一下k键为其对应的真实数字,并把每一个轮廓内的像素点在数字模版图中给抠出来
digits = {} # kv键值对类型,存储 key=每一个已知真实数字,value=对应数字模版图的对应轮廓矩形内的像素点的值
for (i, c) in enumerate(ref_contours):
# 计算外接矩形并且resize成合适大小
(x, y, w, h) = cv2.boundingRect(c)
roi = ref[y:y + h, x:x + w] # 设置roi感兴趣区域,并在数字模版图中抠图
roi = cv2.resize(roi, (57, 88)) # 因为抠出来的图太小了,咱们resize一下
# 每一个数字对应每一个模板
digits[i] = roi
# 到此为止,我们有了digits,里面存储的是0、1、2...数字的模版,下面我们用模版匹配识别就好了。
"""3、针对待识别的信用卡图像做预处理操作
3.1、构造卷积核:cv2.getStructuringElement(shape, ksize)
shape:内核的形状,有三种形状可以选择。
cv2. MORPH_RECT:矩形结构元素,所有元素值都是1
cv2. MORPH_CROSS:十字形结构元素或者叫交叉形,对角线元素值都是1
cv2. MORPH_ELLIPSE:椭圆形结构元素
ksize:代表形状元素的大小
3.2、形态学操作:cv2.morphologyEx()
3.3、图像梯度之Sobel算子:cv2.Sobel()
3.4、对数组中的每一个元素求其绝对值:np.absolute()
np.abs是这个函数的简写
3.5、
"""
# 初始化2个卷积核,大小要根据实际的任务进行设置
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
# 读取信用卡输入图像,预处理
image = cv2.imread("images/credit_card_03.png")
# cv_show('image', image)
image = my_resize(image, width=300) # resize小一些
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转换成灰度图
# cv_show('gray', gray)
# 礼帽操作,突出更明亮的区域
# 礼帽=原始输入-开运算结果
# 开运算=先腐蚀,再膨胀
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
# cv_show('tophat', tophat)
# 图像梯度之Sobel算子,我们可以算X,也可以算Y,也可以都算,但是最后发现只算X效果更好
gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1) # ksize=-1相当于用3*3的
gradX = np.absolute(gradX) # 对数组中的每一个元素求其绝对值
(minVal, maxVal) = (np.min(gradX), np.max(gradX)) # 取数组中最小值、最大值
gradX = (255 * ((gradX - minVal) / (maxVal - minVal))) # 归一化
gradX = gradX.astype("uint8")
print(np.array(gradX).shape)
# cv_show('gradX', gradX)
# 通过闭操作(先膨胀,再腐蚀)将数字连在一起,即把信用卡上的数字分组
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
# cv_show('gradX', gradX)
# 二值化处理
# THRESH_OTSU会自动寻找合适的阈值,适合双峰即图像中有两个主体要进行阈值处理,所以就需把阈值参数设置为0让opencv自动判断什么样的主体阈值是比较合适的,需搭配cv2.THRESH_OTSU
thresh = cv2.threshold(gradX, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# cv_show('thresh', thresh)
# 再来一个闭操作,目的是把信用卡上的数字分组中每一个组内用白色填充起来使其组内更连贯。
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel) # 再来一个闭操作
# cv_show('thresh', thresh)
"""
4、计算轮廓
"""
# 计算轮廓
thresh_, threshCnts, hierarchy = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = threshCnts
cur_img = image.copy()
# 绘制轮廓
cv2.drawContours(cur_img, cnts, -1, (0, 0, 255), 3)
# cv_show('img', cur_img)
locs = [] # 保存我们想要的轮廓的区域,即四组数字的4个大轮廓
# 遍历轮廓,进行轮廓Array的过滤,只留下自己想要的轮廓
for (i, c) in enumerate(cnts):
# 计算外接矩形
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h) # 算矩形的长宽比,因为4组数字的长宽比和其他杂项的长宽比不同
# 选择合适的区域,根据实际任务来,这里的基本都是四个数字一组
if 2.5 < ar < 4.0:
if (40 < w < 55) and (10 < h < 20):
# 符合的留下来
locs.append((x, y, w, h))
# 将符合的大轮廓从左到右排序
locs = sorted(locs, key=lambda x: x[0])
# print(locs) # [(35, 99, 45, 13), (94, 99, 46, 13), (154, 99, 46, 13), (214, 99, 46, 13)]
output = []
# 遍历每一个大轮廓中的数字
for (i, (gX, gY, gW, gH)) in enumerate(locs):
# initialize the list of group digits
groupOutput = []
# 根据坐标提取每一组数字在gray图片中的区域,-+5的目的是因为轮廓可能是正正好好的,所以要扩大一下轮廓
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]
# cv_show('group', group)
# 预处理,二值化处理
group = cv2.threshold(group, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# cv_show('group', group)
# 计算每一组的轮廓
group_, digitCnts, hierarchy = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
digitCnts = contours.sort_contours(digitCnts, method="left-to-right")[0] # 从左到右排序
# 计算每一组中的每一个数值,一组是4个数字
for c in digitCnts:
# 找到当前数值的轮廓,resize成合适的的大小
(x, y, w, h) = cv2.boundingRect(c)
roi = group[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88)) # 这里要和之前的大小一样,为后续模版匹配做准备
# cv_show('roi', roi) # 从左到右依次展示每组数字的每一个数字
# 计算匹配得分
scores = []
# 在模板中计算每一个得分
for (digit, digitROI) in digits.items():
"""
cv2.matchTemplate()模版匹配函数
在源图像上从左到右,从上到下滑动模板,在每一个位置都计算一个指标以表明这个位置处 两个图像块之间匹配程度的高低。
最终将不同位置的相似度结果,存储在我们的结果矩阵res中。
roi输入图像:包含我们要检测的对象的图像
digitROI模板图像:对象的图像
1:模板匹配方法,或者写cv2.TM_SQDIFF等等,建议使用带归一化的匹配方法结果更可靠
result返回值:输出结果是具有特定尺寸的相似度结果矩阵
宽度: image.shape [ 1 ] - template.shape [ 1 ] + 1
高度: image.shape [ 0 ] - template.shape [ 0 ] + 1
cv2.minMaxLoc()找出矩阵最小值和最大值及其位置
min_val, max_val, min_location, max_location = cv2.minMaxLoc(res)
"""
# 模板匹配
result = cv2.matchTemplate(roi, digitROI, cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
scores.append(score)
# 得到最合适的数字,即取最大的数(cv2.TM_CCOEFF取最大的数)
groupOutput.append(str(np.argmax(scores)))
# 画出来
"""
cv2.rectangle()画出矩行:
第一个参数:img是原图
第二个参数:(x,y)是矩阵的左上点坐标
第三个参数:(x+w,y+h)是矩阵的右下点坐标
第四个参数:(0,0,255)是画线对应的rgb颜色
第五个参数:1是所画的线的宽度
cv2.putText()绘制文本字符串
"""
cv2.rectangle(image, (gX - 5, gY - 5), (gX + gW + 5, gY + gH + 5), (0, 0, 255), 1)
cv2.putText(image, "".join(groupOutput), (gX, gY - 15), cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)
# 得到结果
output.extend(groupOutput)
# print(output) # ['5', '4', '1', '2', '7', '5', '1', '2', '3', '4', '5', '6', '7', '8', '9', '0']
# 打印结果
print("Credit Card Type: {}".format(FIRST_NUMBER[output[0]]))
print("Credit Card #: {}".format("".join(output)))
cv2.imshow("Image", image)
cv2.waitKey(0)
16、项目实战:利用OpenCV工具包进行文档扫描OCR识别
- 边缘检测
- 获取轮廓
- 变换
- OCR
如何实现扫描的效果(结合透视变换)
import numpy as np
# import argparse
import cv2
# 设置参数
# ap = argparse.ArgumentParser()
# ap.add_argument("-i", "--image", required=True,
# help="Path to the image to be scanned")
# args = vars(ap.parse_args())
def order_points(pts):
# 一共4个坐标点
rect = np.zeros((4, 2), dtype="float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis=1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect # 得到四个点的坐标
# 计算输入的w和h值
"""
**2是平方,sqrt是根号。
"""
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2)) # 底长
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2)) # 顶长
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2)) # 右高
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2)) # 左高
maxHeight = max(int(heightA), int(heightB))
# 设置变换后对应坐标位置
dst = np.array([
[0, 0], # 左上
[maxWidth - 1, 0], # 右上,-1是为了保证别出现错误
[maxWidth - 1, maxHeight - 1], # 右下
[0, maxHeight - 1]], dtype="float32") # 左下
"""获取透视变换矩阵函数cv2.getPerspectiveTransform(src, dst)
src:源图像四边形顶点坐标
dst:目标图像对应的四边形顶点坐标
返回值:透视变换矩阵M
根据透视矩阵M变换图像cv2.warpPerspective(image, M, (dst_width, dst_height))
image:原始图像
M:为透视矩阵
(dst_width, dst_height)为变换后的图像大小
"""
# 计算变换矩阵
M = cv2.getPerspectiveTransform(rect, dst) # 从四对相应的点计算透视变换。
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
"""
通过指定的w或h去计算比例是多少,基于比例去推算w和h,最后对图像进行resize操作
即:只需要传入w或h,自动对图像进行resize等比缩放操作
"""
dim = None
(h, w) = image.shape[:2] # 获取图像的h、w值
if width is None and height is None:
return image
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter) # dim是(w,h)形式的
return resized
# 读取输入
image = cv2.imread("./images/page.jpg")
# 因为后续我们要对图像进行resize操作,同时坐标也会进行相同变化,所以我们要先获取输入图像的比例
ratio = image.shape[0] / 500.0 # shape[0]是h
orig = image.copy()
image = resize(orig, height=500) # 只需要传入h=500,w的值会自动帮我们进行计算并进行等比缩放操作
# 预处理
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转成灰度图
gray = cv2.GaussianBlur(gray, (5, 5), 0) # 通过高斯滤波操作处理噪点,剔除一些干扰项
# 使用Canny进行边缘检测
print("STEP 1: 边缘检测")
edged = cv2.Canny(gray, 75, 200)
# 展示预处理边缘检测结果
cv2.imshow("Image", image)
cv2.imshow("Edged", edged)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 轮廓检测
cnts = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[1]
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5] # 对轮廓的面积进行降序排序,从大到小取前5个轮廓
# 遍历轮廓
for c in cnts:
peri = cv2.arcLength(c, True) # 计算每一个轮廓的周长,True表示闭合的
"""轮廓近似函数cv2.approxPolyDP(cnt, epsilon, True)
cnt:轮廓信息
epsilon:用来做近似的阈值(一般是按照周长的百分比做设置的)。表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数
True:表示封闭的,即近似曲线闭合(其第一个和最后一个顶点是连接在一起的)。反之它不会闭合。
"""
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
# 如果近似后得到一个矩形,也就是4个点,那么就说明这就是我们想要的小票的轮廓,直接break跳出轮廓循环
if len(approx) == 4:
screenCnt = approx
break
# 展示结果,到此就获取到了我们的roi区域
print("STEP 2: 获取轮廓")
cv2.drawContours(image, [screenCnt], -1, (0, 255, 0), 2)
cv2.imshow("Outline", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 透视变换
"""reshape(cn, rows)既可以改变矩阵的通道数,又可以对矩阵元素进行序列化
cn为新的通道数,如果cn = 0,表示通道数不会改变。
rows为新的行数,如果rows = 0,表示行数不会改变。
注意新的行*列必须与原来的行*列相等。就是说,如果原来是5行3列,新的行和列可以是1行15列,3行5列,5行3列,15行1列。仅此几种,否则会报错。
"""
warped = four_point_transform(orig,
screenCnt.reshape(4, 2) * ratio) # orig没做resize操作,screenCnt是做了resize后得到的坐标点,所以要乘比例还原回去
# 为了让图像显示的更清晰
warped = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY) # 转成灰度图
ref = cv2.threshold(warped, 100, 255, cv2.THRESH_BINARY)[1] # 二值化处理
cv2.imwrite('scan.jpg', ref)
# 展示结果
print("STEP 3: 变换")
cv2.imshow("Original", resize(orig, height=650))
cv2.imshow("Scanned", resize(ref, height=650))
cv2.waitKey(0)
利用扫描结果进行OCR文字识别识别
tesseract是开源的OCR识别工具,默认只支持英文。如果想支持中文,需要在官网下载中文的训练包,自己训练一下。
tesseract官方GitHub
安装文档
各种平台编译指南
Windows平台下载
安装tesseract
有两个部分需要安装,引擎本身和语言的训练数据。
语言训练数据包称为**‘tesseract-ocr-langcode’和’tesseract-ocr-script-scriptcode’**,其中langcode是三字母语言代码和scriptcode四字母脚本代码。
示例: tesseract-ocr-eng(英文)、tesseract-ocr-ara(阿拉伯语)、tesseract-ocr-chi-sim(简体中文)、tesseract-ocr-script-latn(拉丁文)、tesseract-ocr-script- deva(梵文脚本)等。
# MacOS之用Homebrew安装方式
brew install tesseract
# MacOS查找tesseract目录
brew info tesseract
# 测试tesseract是否安装成功
tesseract -v
# (选择性安装)由于默认仅包含“eng”、“osd”和“snum”语言数据文件。
# 如果您需要任何其他受支持的语言,请运行此命令,该命令会在Cellar目录下创建一个tesseract-lang/4.1.0/share/tessdata下有很多语言的数据文件,我们不需要将其拷贝到tesseract目录下
brew install tesseract-lang

命令行方式使用tesseract
我们可以直接使用命令行的方式去使用tesseract了。
# 识别当前路径下的test.png图片的文字并保存到result.txt文件中,注意图片是黑底白字。
tesseract test.png result
# 可以一次与多种语言训练数据一起使用,例如。英语和德语
tesseract myscan.png out -l eng+deu
# tesseract(版本 >=3.03)创建可搜索的out.pdf文件
tesseract myscan.png out pdf
# 识别黑底白字简体中文图片
tesseract t2.png result -l chi_sim
# 识别黑底白字繁体中文图片
tesseract t2.png result -l chi_tra
Python使用tesseract
# 安装pytesseract
pip3 install pytesseract
from PIL import Image
import pytesseract
import cv2
import os
print("STEP 4: OCR")
preprocess = 'blur' # thresh
image = cv2.imread('scan.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if preprocess == "thresh":
# 二值化处理
# THRESH_OTSU会自动寻找合适的阈值,适合双峰即图像中有两个主体要进行阈值处理,所以就需把阈值参数设置为0让opencv自动判断什么样的主体阈值是比较合适的,需搭配cv2.THRESH_OTSU
gray = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
if preprocess == "blur":
# 图像平滑-中值滤波
gray = cv2.medianBlur(gray, 3)
filename = "{}.png".format(os.getpid()) # 返回当前进程ID作为图片名字
cv2.imwrite(filename, gray)
# pytesseract.image_to_string()返回对提供的图像到字符串运行的Tesseract OCR的结果
text = pytesseract.image_to_string(Image.open(filename))
print(text)
os.remove(filename)
cv2.imshow("Image", image)
cv2.imshow("Output", gray)
cv2.waitKey(0)
17、图像特征-harris角点检测cv2.cornerHarris()

基本原理
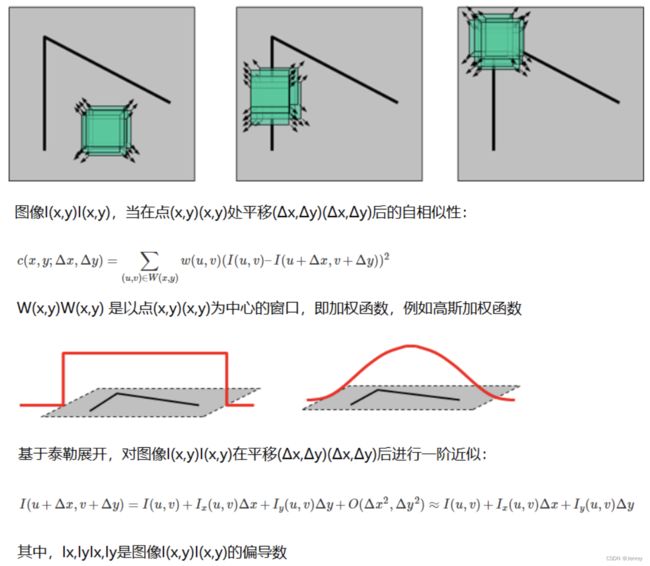


在OpenCV中进行角点检测
cv2.cornerHarris()
- img: 数据类型为 float32 的入图像
- blockSize: 角点检测中指定区域的大小
- ksize: Sobel求导中使用的窗口大小,一般设置为3即可
- k: 取值参数为 [0.04,0.06],一般设置为0.04即可
import cv2
import numpy as np
img = cv2.imread('chessboard.jpg')
print('img.shape:', img.shape) # img.shape: (512, 512, 3)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# gray = np.float32(gray) # 转换成float32格式
dst = cv2.cornerHarris(gray, 2, 3, 0.04)
print('dst.shape:', dst.shape) # dst.shape: (512, 512)
# 通常我们不设置固定值,所以都是和最大值相比,最大值肯定是角点
img[dst > 0.01 * dst.max()] = [0, 0, 255] # 自相似性大于0.01倍的最大值,则认为可能是角点,并用红色画出
cv2.imshow('dst', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
18、图像特征-sift(Scale Invariant Feature Transform),即平移不变性的特征匹配算法
sift是最常用应用的算法,在2004年完善,后续进行过各种升级,所以我们实战中不一定会用sift本身,可能是一些延伸算法,但是基本思想是不变的。
第一步:图像尺度空间
在一定的范围内,无论物体是大还是小,人眼都可以分辨出来,然而计算机要有相同的能力却很难,所以要让机器能够对物体在不同尺度下有一个统一的认知,就需要考虑图像在不同的尺度下都存在的特点。
比如我们在很远的地方看见班主任都会跑,这就是人在远处能观察到图像的特点进行分辨,那么计算机也需要这种能力,即让计算机不光在清晰的层面上能够看到是什么物品还要在模糊的情况下也能分辨,另外也需要让计算机对图像对分辨率低、分辨率高的时候都能分辨。
模糊
尺度空间的获取通常使用高斯模糊来实现


多分辨率金字塔

第二步:高斯差分金字塔(DOG)
比如我们想分辨一个特征,那么什么特征才是有用的?
比如我们像分辨两个学生A、B,哪个是好学生,哪个是差学生,
A:身高180,体重60,考试100分
B:身高180,体重59,考试5分
我们看身高、体重是无法区分学生好坏的,只能看成绩。
即,有价值的特征应该是可以呈现出不同的地方。
高斯差分金字塔就是用来选出有意义的特征点的。
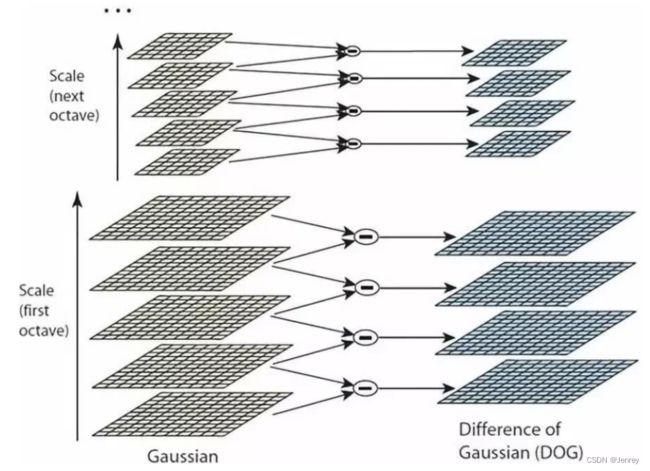
定义公式
x,y:某个点的位置
σ:高斯模糊的参数,模糊程度
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wT3W4gQa-1656919150118)(…/…/pic/sift_6.png)]
步骤
DOG空间极值检测
为了寻找尺度空间的极值点,每个像素点要和其图像域(同一尺度空间)和尺度域(相邻的尺度空间)的所有相邻点进行比较,当其大于(或者小于)所有相邻点时,该点就是极值点。
如下图所示,中间的检测点要和其所在图像的3×3邻域8个像素点,以及其相邻的上下两层的3×3领域18个像素点,共26个像素点进行比较。
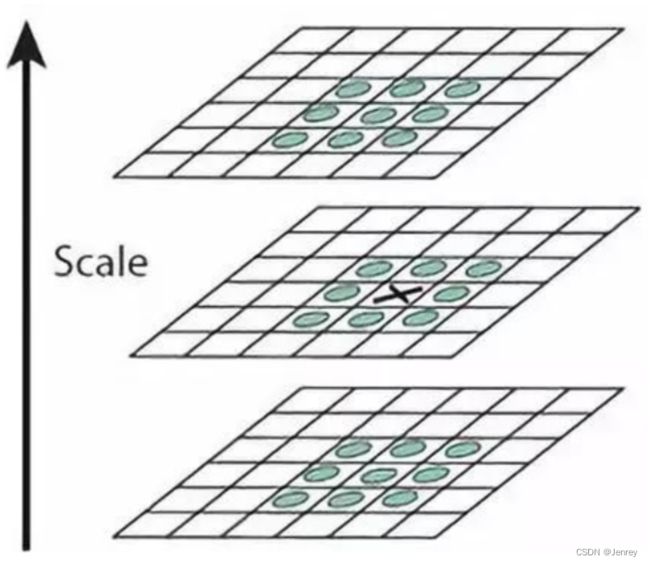
关键点的精确定位
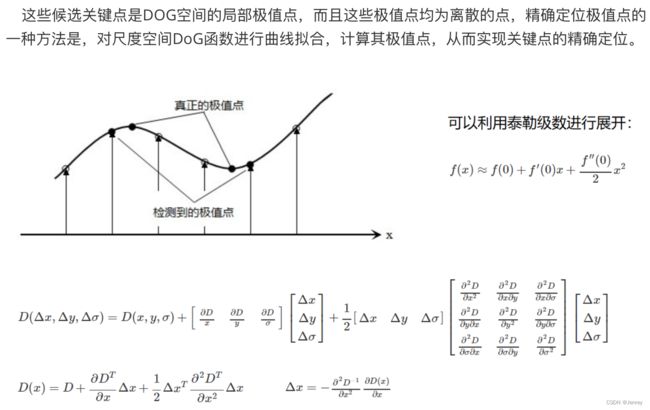
消除边界响应

特征点的主方向

生成特征描述

旋转之后的主方向为中心取8x8的窗口,求每个像素的梯度幅值和方向,箭头方向代表梯度方向,长度代表梯度幅值,然后利用高斯窗口对其进行加权运算,最后在每个4x4的小块上绘制8个方向的梯度直方图,计算每个梯度方向的累加值,即可形成一个种子点,即每个特征的由4个种子点组成,每个种子点有8个方向的向量信息。

OpenCV SIFT函数
在OpenCV去做SIFT函数时,可能遇到一些问题。
- SIFT算法在OpenCV 3.4.3版本往上就进入了专利保护阶段,即SIFT算法不再免费。
import cv2
import numpy as np
img = cv2.imread('test_1.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
print(cv2.__version__) # 3.4.11
降低OpenCV版本
# 查看python的包列表
pip3 list
目前我使用的是(其实也是可以正常使用的)
-
opencv-python 3.4.11.45
-
opencv-contrib-python 3.4.11.45
# 删除高版本
pip3 uninstall opencv-python
pip3 uninstall opencv-contrib-python
注意:python3.6版本才可以安装3.4.1.15
# 安装3.4.1.15版本
pip3 install opencv-python==3.4.1.15
pip3 install opencv-contrib-python==3.4.1.15
SIFT函数是在opencv-contrib-python里面的。
代码
import cv2
import numpy as np
img = cv2.imread('test_1.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
print(cv2.__version__)
# 得到特征点
sift = cv2.xfeatures2d.SIFT_create() # SIFT算法的实例化
kp = sift.detect(gray, None) # 得到关键点,类型,没办法直接进行显示
# 绘制关键点
img = cv2.drawKeypoints(gray, kp, img) # 把关键点绘制出来
cv2.imshow('drawKeypoints', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 计算特征
kp, des = sift.compute(gray, kp)
print(np.array(kp).shape) # (6827,)
print(des.shape) # (6827, 128)
print(des[0])
"""
array([ 0., 0., 0., 0., 0., 0., 0., 0., 21., 8., 0.,
0., 0., 0., 0., 0., 157., 31., 3., 1., 0., 0.,
2., 63., 75., 7., 20., 35., 31., 74., 23., 66., 0.,
0., 1., 3., 4., 1., 0., 0., 76., 15., 13., 27.,
8., 1., 0., 2., 157., 112., 50., 31., 2., 0., 0.,
9., 49., 42., 157., 157., 12., 4., 1., 5., 1., 13.,
7., 12., 41., 5., 0., 0., 104., 8., 5., 19., 53.,
5., 1., 21., 157., 55., 35., 90., 22., 0., 0., 18.,
3., 6., 68., 157., 52., 0., 0., 0., 7., 34., 10.,
10., 11., 0., 2., 6., 44., 9., 4., 7., 19., 5.,
14., 26., 37., 28., 32., 92., 16., 2., 3., 4., 0.,
0., 6., 92., 23., 0., 0., 0.], dtype=float32)
"""
19、特征匹配
由18节我们使用了SIFT算法,并且能够得到图像中的关键点。
比较图像中哪些关键点是比较类似的,或者说它们关键点之间距离比较近(也就是比较向量之间的差异)
Brute-Force蛮力匹配
把每一个特征向量之间进行比较,进而得到哪两个特征向量之间最近,那么这两个就最相似。
1对1的匹配
import cv2
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img1 = cv2.imread('box.png', 0)
img2 = cv2.imread('box_in_scene.png', 0)
cv_show('img1', img1)
cv_show('img2', img2)
sift = cv2.xfeatures2d.SIFT_create() # SIFT算法的实例化
# detectAndCompute()检测关键点并计算特征向量,相当于是二步合一,返回kp关键点、des特征向量
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# crossCheck=True表示两个特征点要互相匹,例如A中的第i个特征点与B中的第j个特征点最近的,并且B中的第j个特征点到A中的第i个特征点也是最近的
# NORM_L2: 默认参数;归一化数组的(欧几里德距离),如果其他特征计算方法需要考虑不同的匹配计算方式
bf = cv2.BFMatcher(crossCheck=True) # Brute-Force蛮力匹配
# 1对1的匹配
matches = bf.match(des1, des2) # 传入两个图的特征向量
matches = sorted(matches, key=lambda x: x.distance) # 排序
img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None, flags=2) # 在两图中,画出前10个最接近的关键点及其连线
cv_show('img3', img3)
k对最佳匹配
import cv2
def cv_show(name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img1 = cv2.imread('box.png', 0)
img2 = cv2.imread('box_in_scene.png', 0)
cv_show('img1', img1)
cv_show('img2', img2)
sift = cv2.xfeatures2d.SIFT_create() # SIFT算法的实例化
# detectAndCompute()检测关键点并计算特征向量,相当于是二步合一,返回kp关键点、des特征向量
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
# k对最佳匹配
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2) # 本图中的1个特征点对应另外图中2个和其最近的特征点
good = []
for m, n in matches:
if m.distance < 0.75 * n.distance: # 自己指定的过滤方法,因为直接匹配的不一定是最合适的
good.append([m])
img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, good, None, flags=2)
cv_show('img3', img3)
如果需要更快速完成操作,可以尝试使用cv2.FlannBasedMatcher
发现下图粉色连接配对出现错误,即左上角和椅子进行相连了。
随机抽样一致算法(Random sample consensus,RANSAC)
为了解决上图中出现的“粉色连接配对出现错误,即左上角和椅子进行相连”问题,就需要RANSAC算法。
- 最小二乘:现在我们有一些数据点,我们想进行拟合成直线,那么就要尽可能的满足所有数据点,因为下面有很多数据点,受此影响,所以图像中红线就向下偏移了。
- RANSAC:没有受到下方数据点的影响,即绿线

RANSAC算法详解
选择初始样本点进行拟合,给定一个容忍范围,不断进行迭代。
每一次拟合后,容差范围内都有对应的数据点数,找出数据点个数最多的情况,就是最终的拟合结果。
- 左图:随机选n=2两个点,即左图红点,然后连接成线。
- 中图:绿色虚线叫做红色的容忍范围,相当于是针对左图连接成线的最大浮动区间,在此区间内,我们都认为是局内点,不在区间内认为是局外点。统计局内点个数。
- 右图:不断迭代,重复说那个面操作1、2,统计局内点个数
- 最后,不断迭代,最终选出局内点最多的点,此时两红点的连线就是RANSAC算法拟合出来的最佳直线

单应性矩阵(也称为H矩阵)
自由度设置为8,最后一个设置为1,方便我们做归一化操作。

示例应用实战:图像拼接
目的
有下图所示Image A和Image B,现在希望把两张图拼接成一张图。
思路
下面我们用特征匹配方法去实现两张图的图像拼接:
对左图或右图做变换,也就是求变换矩阵,即该变换矩阵使得这两张图按照某个角度去做变换,使得拼接后是最合适的状态。
思路:
- 分别提取图片的图像特征提取SIFT
- 而后对两图做特征点的匹配,构造H矩阵,即需要最少4对特征点。
- 对B图做H矩阵变换,即B * H做变换
- 最后,把A和 B * H 拼接在一起
最终结果:
代码实现
import cv2
import numpy as np
class Stitcher:
# 拼接函数
def stitch(self, images, ratio=0.75, reprojThresh=4.0, showMatches=False):
# 获取输入图片
(imageB, imageA) = images
# 检测A、B图片的SIFT关键特征点,并计算特征描述子
(kpsA, featuresA) = self.detectAndDescribe(imageA)
(kpsB, featuresB) = self.detectAndDescribe(imageB)
# 匹配两张图片的所有特征点,返回匹配结果
M = self.matchKeypoints(kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh)
# 如果返回结果为空,没有匹配成功的特征点,退出算法
if M is None:
return None
# 否则,提取匹配结果
# H是3x3视角变换矩阵
(matches, H, status) = M
# 将图片A进行视角变换,result是变换后图片
result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0]))
self.cv_show('result', result)
# 将图片B传入result图片最左端
result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB
self.cv_show('result', result)
# 检测是否需要显示图片匹配
if showMatches:
# 生成匹配图片
vis = self.drawMatches(imageA, imageB, kpsA, kpsB, matches, status)
# 返回结果
return (result, vis)
# 返回匹配结果
return result
def cv_show(self, name, img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def detectAndDescribe(self, image):
# 将彩色图片转换成灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 建立SIFT生成器
descriptor = cv2.xfeatures2d.SIFT_create()
# 检测SIFT特征点,并计算描述子
(kps, features) = descriptor.detectAndCompute(image, None)
# 将结果转换成NumPy数组
kps = np.float32([kp.pt for kp in kps])
# 返回特征点集,及对应的描述特征
return (kps, features)
def matchKeypoints(self, kpsA, kpsB, featuresA, featuresB, ratio, reprojThresh):
# 建立暴力匹配器
matcher = cv2.BFMatcher()
# 使用KNN检测来自A、B图的SIFT特征匹配对,K=2
rawMatches = matcher.knnMatch(featuresA, featuresB, 2)
matches = []
for m in rawMatches:
# 当最近距离跟次近距离的比值小于ratio值时,保留此匹配对
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
# 存储两个点在featuresA, featuresB中的索引值
matches.append((m[0].trainIdx, m[0].queryIdx))
# 当筛选后的匹配对大于4时,计算视角变换矩阵
if len(matches) > 4:
# 获取匹配对的点坐标
ptsA = np.float32([kpsA[i] for (_, i) in matches])
ptsB = np.float32([kpsB[i] for (i, _) in matches])
# 计算视角变换矩阵
(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)
# 返回结果
return (matches, H, status)
# 如果匹配对小于4时,返回None
return None
def drawMatches(self, imageA, imageB, kpsA, kpsB, matches, status):
# 初始化可视化图片,将A、B图左右连接到一起
(hA, wA) = imageA.shape[:2]
(hB, wB) = imageB.shape[:2]
vis = np.zeros((max(hA, hB), wA + wB, 3), dtype="uint8")
vis[0:hA, 0:wA] = imageA
vis[0:hB, wA:] = imageB
# 联合遍历,画出匹配对
for ((trainIdx, queryIdx), s) in zip(matches, status):
# 当点对匹配成功时,画到可视化图上
if s == 1:
# 画出匹配对
ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1]))
ptB = (int(kpsB[trainIdx][0]) + wA, int(kpsB[trainIdx][1]))
cv2.line(vis, ptA, ptB, (0, 255, 0), 1)
# 返回可视化结果
return vis
if __name__ == '__main__':
# 读取拼接图片
imageA = cv2.imread("left_01.png")
imageB = cv2.imread("right_01.png")
# 把图片拼接成全景图
stitcher = Stitcher()
(result, vis) = stitcher.stitch([imageA, imageB], showMatches=True)
# 显示所有图片
cv2.imshow("Image A", imageA)
cv2.imshow("Image B", imageB)
cv2.imshow("Keypoint Matches", vis)
cv2.imshow("Result", result)
cv2.waitKey(0)
cv2.destroyAllWindows()
20、项目实战-停车场车位识别
需要:
- tensorflow-2.9.1
- keras-2.9.0
整体流程
目标:
- 实现当前停车场中一共有多少车,一共有多少空余车位。
- 有多少停车位被占用。
- 哪个停车位被占,哪个没被占,标示出没被占用的车位。
思路:
- 把视频每一帧进行计算,这里我们计算2张图即可。
- 对原始图像进行过滤操作,把没用的区域去除。
- 我们需要先检测出每一个停车位的位置,即每个停车位都是矩形
- 基于停车位裁剪出来,建立一个模型(做一个判断,到底是不是空的),分类任务。
安装准备工作
TensorFlow 是谷歌发布的深度学习开源的计算框架,该计算框架可以很好地实现各种深度学习算法,涉及自然语言处理、机器翻译、图像描述、图像分类等一系列技术。
简单来说,TensorFlow 为我们封装了大量机器学习、神经网络的函数,帮助我们高效地解决问题。
Keras是一个Python深度学习框架,可以方便地定义和训练几乎所有类型的深度学习模型。
Keras是一个用Python编写的高级神经网络API,它能够以TensorFlow, CNTK, 或者 Theano 作为后端运行。
在安装 Keras 之前,请安装以下后端引擎之一:TensorFlow,Theano,或者 CNTK。我们推荐 TensorFlow 后端。
默认情况下,Keras将使用 TensorFlow 作为其张量操作库
安装tensorflow
TensorFlow中文社区官方地址
-
直接pip安装太慢,我们从清华镜像站找到适合自己的tensorflow
清华镜像-tensorflow
-
本人使用tensorflow-2.9.1-cp39-cp39-macosx_10_14_x86_64.whl
tensorflow-2.9.1-cp39-cp39-macosx_10_14_x86_64.whl
-
执行pip命令安装whl文件
pip3 install tensorflow-2.9.1-cp39-cp39-macosx_10_14_x86_64.whl
Successfully installed absl-py-1.1.0 astunparse-1.6.3 cachetools-5.2.0 flatbuffers-1.12 gast-0.4.0 google-auth-2.9.0 google-auth-oauthlib-0.4.6 google-pasta-0.2.0 grpcio-1.47.0 h5py-3.7.0 keras-preprocessing-1.1.2 libclang-14.0.1 markdown-3.3.7 opt-einsum-3.3.0 protobuf-3.19.4 pyasn1-modules-0.2.8 tensorboard-2.9.1 tensorboard-data-server-0.6.1 tensorboard-plugin-wit-1.8.1 tensorflow-2.9.1 tensorflow-estimator-2.9.0 tensorflow-io-gcs-filesystem-0.26.0 termcolor-1.1.0
安装keras
pip3 install keras
Successfully installed keras-2.9.0
项目代码
主程序:
from __future__ import division
import matplotlib.pyplot as plt
import cv2
import os
import glob
import numpy as np
from PIL import Image
from keras.applications.imagenet_utils import preprocess_input
from keras.models import load_model
from keras.preprocessing import image
import pickle
"""
pip3 install keras
"""
class Parking:
def show_images(self, images, cmap=None):
"""
图像展示
:param images:
:param cmap:
:return:
"""
cols = 2
rows = (len(images) + 1) // cols
plt.figure(figsize=(15, 12))
for i, image in enumerate(images):
plt.subplot(rows, cols, i + 1)
cmap = 'gray' if len(image.shape) == 2 else cmap
plt.imshow(image, cmap=cmap)
plt.xticks([])
plt.yticks([])
plt.tight_layout(pad=0, h_pad=0, w_pad=0)
plt.show()
def cv_show(self, name, img):
"""
图像展示
:param name:
:param img:
:return:
"""
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def select_rgb_white_yellow(self, image):
"""
过滤掉背景
:param image:
:return:
"""
lower = np.uint8([120, 120, 120]) # 最小阈值
upper = np.uint8([255, 255, 255]) # 最大阈值
# cv2.inRange()函数会把低于lower和高于upper_red的部分分别变成0,lower~upper之间的值变成255,相当于过滤背景;
# 即小于120变成0,大于120变成255
white_mask = cv2.inRange(image, lower, upper) # image:对什么数据进行变换,lower:最小阈值,upper:最大阈值
self.cv_show('white_mask', white_mask)
# 与操作;0与1是0,即只有255的图像才会保留下来
masked = cv2.bitwise_and(image, image, mask=white_mask)
self.cv_show('masked', masked)
return masked
def convert_gray_scale(self, image):
"""
转成灰度图
:param image:
:return:
"""
return cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
def detect_edges(self, image, low_threshold=50, high_threshold=200):
"""
使用Canny进行边缘检测
* 梯度值>最大阈值 是边界,保留
* 最小阈值<梯度值<最大阈值 连有边界则保留,否则舍弃
* 梯度值<最小阈值 舍弃
:param image:
:param low_threshold:最小阈值
:param high_threshold:最大阈值
:return:
"""
return cv2.Canny(image, low_threshold, high_threshold)
def filter_region(self, image, vertices):
"""
剔除掉不需要的地方
"""
mask = np.zeros_like(image) # 返回与给定数组具有相同形状和类型的0数组。即返回与image图像相同形状和类型的纯黑图
if len(mask.shape) == 2:
# 按照传入的vertices(即停车场位置的6个点)围起来的区域进行255白色填充
cv2.fillPoly(mask, vertices, 255) # 填充操作,填充由一个或多个多边形包围的区域。
self.cv_show('mask', mask)
return cv2.bitwise_and(image, mask) # 与操作,只在255的位置留下,其他位置的图像剔除
def select_region(self, image):
"""
手动选择区域
"""
# 基于当前的业务需求,指定了6个点,把这些点连起来就是停车场的位置了
rows, cols = image.shape[:2]
pt_1 = [cols * 0.05, rows * 0.90]
pt_2 = [cols * 0.05, rows * 0.70]
pt_3 = [cols * 0.30, rows * 0.55]
pt_4 = [cols * 0.6, rows * 0.15]
pt_5 = [cols * 0.90, rows * 0.15]
pt_6 = [cols * 0.90, rows * 0.90]
vertices = np.array([[pt_1, pt_2, pt_3, pt_4, pt_5, pt_6]], dtype=np.int32)
point_img = image.copy()
point_img = cv2.cvtColor(point_img, cv2.COLOR_GRAY2RGB) # 把灰度图转成RGB,为了演示画的这6个点
for point in vertices[0]:
cv2.circle(point_img, (point[0], point[1]), 10, (0, 0, 255), 4) # 把6个点的每一个点的位置都画一个小红圈
self.cv_show('point_img', point_img)
return self.filter_region(image, vertices) # 过滤操作,剔除不需要的地方
def hough_lines(self, image):
"""
找停车场中每一个停车位的直线,即霍夫变换直线检测
:param image:最好是进行过边缘检测后的结果
:return:
"""
# rho:距离精度,一般情况设置为1即像素点级别,但是咱们的这个任务中停车位的分割线需要更精确一些
# theta:角度精度
# threshold:超过设定阈值才被检测出线段,相当于最终有一个投票的环节,因为经过霍夫变换得到的是曲线,计算曲线中一共连到了多少个点,这些点一起投票超过了阈值才能认为是直线,阈值越大得到的直线越少
# minLineLength:直线最小的长度,比这个短的都被忽略,设置需要根据实际场景来设置
# maxLineGap:直线与直线之间最大的间隔,小于此值,认为是一条直线;因为做完边缘检测后可能原本是1条线,但是显示2条线,非常近,我们则处理成一条线
return cv2.HoughLinesP(image, rho=0.1, theta=np.pi / 10, threshold=15, minLineLength=9, maxLineGap=4)
def draw_lines(self, image, lines, color=[255, 0, 0], thickness=2, make_copy=True):
"""
过滤霍夫变换检测到的直线,并画出有效直线
:param image:
:param lines:
:param color:
:param thickness:
:param make_copy:
:return:
"""
# 过滤霍夫变换检测到直线
if make_copy:
image = np.copy(image)
# 一条直线是由x1 y1 x2 y2组成
cleaned = [] # 存储过滤后的直线
# (y2 - y1) <= 1 判断倾斜程度,即在水平方向是直的,所以如果>=1证明该直线是斜的,停车位不是斜线,所以要过滤掉
# 25 <= (x2 - x1) <= 55 过滤直线长度,去除过短和过长的直线
for line in lines:
for x1, y1, x2, y2 in line:
if abs(y2 - y1) <= 1 and 25 <= abs(x2 - x1) <= 55:
cleaned.append((x1, y1, x2, y2))
cv2.line(image, (x1, y1), (x2, y2), color, thickness) # 绘制连接两点的线段
print(" No lines detected: ", len(cleaned))
return image
def identify_blocks(self, image, lines, make_copy=True):
"""
识别区域,即把停车场分成12列(12簇)并绘制每簇的外接直角矩形
:param image:
:param lines:
:param make_copy:
:return:
"""
if make_copy:
new_image = np.copy(image)
# Step 1: 过滤部分直线,和之前做法相同
cleaned = []
for line in lines:
for x1, y1, x2, y2 in line:
if abs(y2 - y1) <= 1 and abs(x2 - x1) >= 25 and abs(x2 - x1) <= 55:
cleaned.append((x1, y1, x2, y2))
# Step 2: 对直线按照x1点的坐标进行排序,因为传进来的直线list是无序的,我们需要按照x1点的坐标依次排序
import operator
list1 = sorted(cleaned, key=operator.itemgetter(0, 1))
# Step 3: 找到12个列即12个簇,相当于每列是一排车
clusters = {} # 用来存12列停车位或者称为12个簇
dIndex = 0 # 簇组的编号,用来迭代
clus_dist = 10 # 设置簇间距离10,用来判断该直线是属于当前簇还是下一个簇,如果两直线间的距离小于了簇间距离,则认为是同一组簇中的直线
for i in range(len(list1) - 1):
distance = abs(list1[i + 1][0] - list1[i][0])
if distance <= clus_dist: # 条件达成,则说明i直线和i+1直线是同簇内的直线
if dIndex not in clusters.keys(): # 如果clusters内没有此簇编号
clusters[dIndex] = [] # 则给clusters增加新簇编号
# 把比较的这两个直线均加入当前簇编号内
clusters[dIndex].append(list1[i])
clusters[dIndex].append(list1[i + 1])
else:
dIndex += 1
# Step 4: 得到坐标
rects = {} # 存储每个簇的外接矩形的坐标
i = 0
for key in clusters:
all_list = clusters[key] # 拿到每一列中全部的直线
cleaned = list(set(all_list))
if len(cleaned) > 5: # 如果该簇中的直线数量大于5,则证明是个列
cleaned = sorted(cleaned, key=lambda tup: tup[1])
avg_y1 = cleaned[0][1] # 该列中第一条直线的y值
avg_y2 = cleaned[-1][1] # 该列中最后一条直线的y值
avg_x1 = 0
avg_x2 = 0
# 对于同簇内的直线来说,每组簇内的直线的长度x不是完全相等的,所以我们要计算一下每簇内直线的平均值
for tup in cleaned:
avg_x1 += tup[0] # 每条直线左端x点坐标
avg_x2 += tup[2] # 每条直线右端x点坐标
avg_x1 = avg_x1 / len(cleaned) # x1即直线左端平均位置
avg_x2 = avg_x2 / len(cleaned) # x2即直线右端平均位置
rects[i] = (avg_x1, avg_y1, avg_x2, avg_y2) # 该簇的外接矩形的两点坐标
i += 1
print("Num Parking Lanes: ", len(rects)) # Num Parking Lanes: 12
# Step 5: 把列矩形画出来
buff = 7
for key in rects:
tup_topLeft = (int(rects[key][0] - buff), int(rects[key][1]))
tup_botRight = (int(rects[key][2] + buff), int(rects[key][3]))
cv2.rectangle(new_image, tup_topLeft, tup_botRight, (0, 255, 0), 3) # 绘制直角矩形
return new_image, rects
def draw_parking(self, image, rects, make_copy=True, color=[255, 0, 0], thickness=2, save=True):
"""
根据rects即每簇外接矩形的坐标进行切分每一个停车位
:param image:
:param rects:
:param make_copy:
:param color:
:param thickness:
:param save:
:return:
"""
if make_copy:
new_image = np.copy(image)
gap = 15.5 # 车位的宽度15.5
spot_dict = {} # 字典:一个车位对应一个位置
tot_spots = 0
# 微调,通过人工指定的方式对每一个簇的外接矩形x1 y1 x2 y2进行微调
adj_y1 = {0: 20, 1: -10, 2: 0, 3: -11, 4: 28, 5: 5, 6: -15, 7: -15, 8: -10, 9: -30, 10: 9, 11: -32}
adj_y2 = {0: 30, 1: 50, 2: 15, 3: 10, 4: -15, 5: 15, 6: 15, 7: -20, 8: 15, 9: 15, 10: 0, 11: 30}
adj_x1 = {0: -8, 1: -15, 2: -15, 3: -15, 4: -15, 5: -15, 6: -15, 7: -15, 8: -10, 9: -10, 10: -10, 11: 0}
adj_x2 = {0: 0, 1: 15, 2: 15, 3: 15, 4: 15, 5: 15, 6: 15, 7: 15, 8: 10, 9: 10, 10: 10, 11: 0}
for key in rects:
tup = rects[key]
# 对每一个簇的外接矩形x1 y1 x2 y2进行微调
x1 = int(tup[0] + adj_x1[key])
x2 = int(tup[2] + adj_x2[key])
y1 = int(tup[1] + adj_y1[key])
y2 = int(tup[3] + adj_y2[key])
cv2.rectangle(new_image, (x1, y1), (x2, y2), (0, 255, 0), 2) # 重新画每簇的外接矩形
num_splits = int(abs(y2 - y1) // gap) # 每一簇切多少到,得到num_splits+1个车位
for i in range(0, num_splits + 1): # 计算每一个停车位的位置
y = int(y1 + i * gap)
cv2.line(new_image, (x1, y), (x2, y), color, thickness) # 绘制连接两点的线段
if 0 < key < len(rects) - 1: # 即非两侧的簇,需要画一个竖直线
x = int((x1 + x2) / 2) # 竖直线
cv2.line(new_image, (x, y1), (x, y2), color, thickness) # 绘制连接两点的线段
# 计算数量
if key == 0 or key == (len(rects) - 1): # 单排车位
tot_spots += num_splits + 1
else: # 双排车位,即该簇内左右都可以停车
tot_spots += 2 * (num_splits + 1)
# 把每一个车位的编号标识出来,字典对应好
if key == 0 or key == (len(rects) - 1):
for i in range(0, num_splits + 1):
cur_len = len(spot_dict)
y = int(y1 + i * gap)
spot_dict[(x1, y, x2, y + gap)] = cur_len + 1
else:
for i in range(0, num_splits + 1):
cur_len = len(spot_dict)
y = int(y1 + i * gap)
x = int((x1 + x2) / 2)
spot_dict[(x1, y, x, y + gap)] = cur_len + 1
spot_dict[(x, y, x2, y + gap)] = cur_len + 2
print("total parking spaces: ", tot_spots, cur_len) # total parking spaces: 535 534
if save:
filename = 'with_parking.jpg'
cv2.imwrite(filename, new_image)
return new_image, spot_dict
def assign_spots_map(self, image, spot_dict, make_copy=True, color=[255, 0, 0], thickness=2):
if make_copy:
new_image = np.copy(image)
for spot in spot_dict.keys():
(x1, y1, x2, y2) = spot
cv2.rectangle(new_image, (int(x1), int(y1)), (int(x2), int(y2)), color, thickness)
return new_image
def save_images_for_cnn(self, image, spot_dict, folder_name='cnn_data'):
"""
裁剪每一个停车位的图片,保存到本地当中
:param image:
:param spot_dict:
:param folder_name:
:return:
"""
for spot in spot_dict.keys():
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
# 裁剪
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (0, 0), fx=2.0, fy=2.0) # 裁剪后的图片非常小,我们进行放大
spot_id = spot_dict[spot]
filename = 'spot' + str(spot_id) + '.jpg'
print(spot_img.shape, filename, (x1, x2, y1, y2))
cv2.imwrite(os.path.join(folder_name, filename), spot_img)
def make_prediction(self, image, model, class_dictionary):
# 预处理
img = image / 255.
# 转换成4D tensor
image = np.expand_dims(img, axis=0)
# 用训练好的模型进行训练
class_predicted = model.predict(image)
inID = np.argmax(class_predicted[0])
label = class_dictionary[inID]
return label
def predict_on_image(self, image, spot_dict, model, class_dictionary, make_copy=True, color=[0, 255, 0], alpha=0.5):
"""
对图像进行预测操作
:param image:
:param spot_dict:
:param model:
:param class_dictionary:
:param make_copy:
:param color:
:param alpha:
:return:
"""
if make_copy:
new_image = np.copy(image)
overlay = np.copy(image)
self.cv_show('new_image', new_image)
cnt_empty = 0
all_spots = 0
for spot in spot_dict.keys():
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (48, 48))
label = self.make_prediction(spot_img, model, class_dictionary)
if label == 'empty':
cv2.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1)
cnt_empty += 1
cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
cv2.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.putText(new_image, "Total: %d spots" % all_spots, (30, 125),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
save = False
if save:
filename = 'with_marking.jpg'
cv2.imwrite(filename, new_image)
self.cv_show('new_image', new_image)
return new_image
def predict_on_video(self, video_name, final_spot_dict, model, class_dictionary, ret=True):
cap = cv2.VideoCapture(video_name)
count = 0
while ret:
ret, image = cap.read()
count += 1
if count == 5:
count = 0
new_image = np.copy(image)
overlay = np.copy(image)
cnt_empty = 0
all_spots = 0
color = [0, 255, 0]
alpha = 0.5
for spot in final_spot_dict.keys():
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (48, 48))
label = self.make_prediction(spot_img, model, class_dictionary)
if label == 'empty':
cv2.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1)
cnt_empty += 1
cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
cv2.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.putText(new_image, "Total: %d spots" % all_spots, (30, 125),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.imshow('frame', new_image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
cap.release()
cwd = os.getcwd()
def img_process(test_images, park):
"""
对输入的图像进行各种处理操作
:param test_images:
:param park:
:return:
"""
# 过滤掉背景
white_yellow_images = list(map(park.select_rgb_white_yellow, test_images))
park.show_images(white_yellow_images)
# 转成灰度图
gray_images = list(map(park.convert_gray_scale, white_yellow_images))
park.show_images(gray_images)
# 使用Canny进行边缘检测
edge_images = list(map(lambda image: park.detect_edges(image), gray_images))
park.show_images(edge_images)
# 手动选择区域(选择停车场的6个点,然后把停车场抠出来,其他没用区域过滤成纯黑色)
roi_images = list(map(park.select_region, edge_images))
park.show_images(roi_images)
# 霍夫变换直线检测,得到停车场区域内所有的直线,大概是五百多条
list_of_lines = list(map(park.hough_lines, roi_images))
# 把得到的直线画出来
line_images = []
for image, lines in zip(test_images, list_of_lines):
line_images.append(park.draw_lines(image, lines)) # 过滤霍夫变换检测到的直线,并画出有效直线
park.show_images(line_images) # 到此为止,没有车的停车位直线画的很好,但是有车停放的停车位直线受到了车的干扰,直线没有画出来
# 画出每簇的外接矩形
rect_images = []
rect_coords = []
for image, lines in zip(test_images, list_of_lines):
new_image, rects = park.identify_blocks(image, lines) # 识别区域,即把停车场分成12列(12簇)并绘制每簇的外接直角矩形
rect_images.append(new_image)
rect_coords.append(rects)
park.show_images(rect_images)
# 根据每簇外接矩形的坐标进行切分每一个停车位
delineated = []
spot_pos = []
for image, rects in zip(test_images, rect_coords):
new_image, spot_dict = park.draw_parking(image, rects) # 根据rects即每簇外接矩形的坐标进行切分每一个停车位
delineated.append(new_image)
spot_pos.append(spot_dict)
park.show_images(delineated)
final_spot_dict = spot_pos[1] # 因为我们读入的是两张图,所以哪张图做出来效果好,我们就选择哪张即可。最后返回每一个停车位的矩形坐标位置的字典
print(len(final_spot_dict)) # 555
with open('spot_dict.pickle', 'wb') as handle:
# pickle模块是Python专用的持久化模块,可以持久化包括自定义类在内的各种数据,比较适合Python本身复杂数据的存储。
# python的pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;
# 通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
# pickle.dump(obj, file[, protocol])序列化对象,并将结果数据流写入到文件对象中。
# 参数protocol是序列化模式,默认值为0,表示以文本的形式序列化。protocol的值还可以是1或2,表示以二进制的形式序列化。
pickle.dump(final_spot_dict, handle, protocol=pickle.HIGHEST_PROTOCOL)
park.save_images_for_cnn(test_images[0], final_spot_dict) # 裁剪每一个停车位的图片,保存到本地当中,为后面使用cnn卷积网络模型来判断停车位是否有车作准备
return final_spot_dict
def keras_model(weights_path):
"""
load_model()是keras提供的函数,可以把car1.h5读取进来
:param weights_path:
:return:
"""
model = load_model(weights_path)
return model
def img_test(test_images, final_spot_dict, model, class_dictionary):
"""
对图像做检测
:param test_images:待检测图像
:param final_spot_dict:每一个停车位的矩形坐标位置的字典
:param model:训练好的网络模型
:param class_dictionary:预测为0是空车位,为1是该车位被车占据
:return:
"""
for i in range(len(test_images)):
predicted_images = park.predict_on_image(test_images[i], final_spot_dict, model, class_dictionary)
def video_test(video_name, final_spot_dict, model, class_dictionary):
name = video_name
cap = cv2.VideoCapture(name)
park.predict_on_video(name, final_spot_dict, model, class_dictionary, ret=True)
if __name__ == '__main__':
"""
1、glob模块用来查找文件目录和文件,并将搜索的到的结果返回到一个列表中。
glob.glob()可同时获取所有的匹配路径
glob支持*?[]这三种通配符:
*代表0个或多个字符
?代表一个字符
[]匹配指定范围内的字符,如[0-9]匹配数字
2、
"""
test_images = [plt.imread(path) for path in glob.glob('test_images/*.jpg')]
weights_path = 'car1.h5' # 训练的网络模型得到的结果(或者叫权重参数),后续判断一个车位是否被占用就需要car1.h5
video_name = 'parking_video.mp4'
class_dictionary = {} # 模型预测完结果返回0或1,不会返回字符串
class_dictionary[0] = 'empty'
class_dictionary[1] = 'occupied'
park = Parking() # 实例化
park.show_images(test_images) # 展示test_images文件夹下scene1380.jpg、scene1410.jpg图像
final_spot_dict = img_process(test_images, park) # 对输入的图像进行各种处理操作,最终拿到每一个停车位的矩形坐标位置的字典
model = keras_model(weights_path)
img_test(test_images, final_spot_dict, model, class_dictionary)
video_test(video_name, final_spot_dict, model, class_dictionary)
train.py代码如下:
"""train.py是训练的一个脚本
1、执行此脚本需要:
* 安装tensorflow:由于直接pip安装太慢,建议在使用"清华镜像站"找到适合自己的whl文件,而后用pip3 install xxx.whl命令进行安装
https://pypi.tuna.tsinghua.edu.cn/simple/tensorflow/
* 安装keras:pip3 install keras
2、说明:
在此之前,我们需要把之前通过代码裁剪出来的每一个停车位的图片的cnn_data文件夹,人为的筛选分类出 有车占用的停车位图 和 空车位的图。
当然,在github中也提供了作者手动筛选分类后的train_data文件夹。
* train_data文件夹:
* test文件夹:
* train文件夹:
* empty文件夹:空车位的车位图
* occupied文件夹:已占用车位的车位图
"""
import os
from keras import applications
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
from keras.models import Model
from keras.callbacks import ModelCheckpoint, EarlyStopping
from keras.layers.core import Flatten
from keras.layers.core import Dense
files_train = 0
files_validation = 0
cwd = os.getcwd() # 返回表示当前工作目录的unicode字符串
"""
Step1:读数据
"""
folder = 'train_data/train'
for sub_folder in os.listdir(folder): # 返回一个包含目录中文件名字的列表
# next()从迭代器返回下一项。如果给出默认值并且迭代器已用尽,则返回它而不是引发 StopIteration。
path, dirs, files = next(os.walk(os.path.join(folder, sub_folder)))
files_train += len(files)
folder = 'train_data/test'
for sub_folder in os.listdir(folder):
path, dirs, files = next(os.walk(os.path.join(folder, sub_folder)))
files_validation += len(files)
print(files_train, files_validation)
"""
Step2:指定参数
"""
img_width, img_height = 48, 48
train_data_dir = "train_data/train"
validation_data_dir = "train_data/test"
nb_train_samples = files_train
nb_validation_samples = files_validation
batch_size = 32
epochs = 15
num_classes = 2
"""
Step3:使用VGG16网络模型
"""
# 实例化VGG16模型
model = applications.VGG16(weights='imagenet', include_top=False, input_shape=(img_width, img_height, 3))
for layer in model.layers[:10]:
layer.trainable = False
x = model.output
x = Flatten()(x)
predictions = Dense(num_classes, activation="softmax")(x)
model_final = Model(input=model.input, output=predictions)
model_final.compile(loss="categorical_crossentropy", optimizer=optimizers.SGD(lr=0.0001, momentum=0.9),
metrics=["accuracy"])
# 数据增强
train_datagen = ImageDataGenerator(
rescale=1. / 255,
horizontal_flip=True,
fill_mode="nearest",
zoom_range=0.1,
width_shift_range=0.1,
height_shift_range=0.1,
rotation_range=5)
test_datagen = ImageDataGenerator(
rescale=1. / 255,
horizontal_flip=True,
fill_mode="nearest",
zoom_range=0.1,
width_shift_range=0.1,
height_shift_range=0.1,
rotation_range=5)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode="categorical")
validation_generator = test_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_height, img_width),
class_mode="categorical")
checkpoint = ModelCheckpoint("car1.h5", monitor='val_acc', verbose=1, save_best_only=True, save_weights_only=False,
mode='auto', period=1)
early = EarlyStopping(monitor='val_acc', min_delta=0, patience=10, verbose=1, mode='auto')
history_object = model_final.fit_generator(
train_generator,
samples_per_epoch=nb_train_samples,
epochs=epochs,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples,
callbacks=[checkpoint, early])