基于MNIST数据集的手写数字识别项目1
CSV格式的MNIST数据集手写数字识别项目
- 资源文件
- 一、MNIST数据集介绍
- 二、开发步骤
-
- 1.引入库
- 2.加载数据集
- 3.将训练集分解为训练集和验证集
- 4.加载测试集test.csv
- 5.正则化数据集
- 6.可视化训练集和验证集中不同数字出现的频率
- 7.显示部分数据集中的数字图片
- 8.构建网络模型
- 9.编译模型
- 10.训练模型
- 11.绘制训练和验证结果
- 12.数据增强
- 13.学习率重置
- 14.重新训练
- 15.保存模型
- 16.绘制训练和验证过程
- 17.显示被预测错误的图片
- 18.在测试上预测
- 19.可视化模型中间层
- 20.将test的预测结果存入csv文件中
资源文件
csv格式的MNIST数据集
一、MNIST数据集介绍
(1)数据集有60000张
(2)每张图片大小28*28
(3)颜色通道:1(灰度)
(4)像素取值范围[0,255],0代表黑色,255代表白色
(5)每张图片有一个标签:0-9
二、开发步骤
1.引入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from keras.layers import Conv2D,Input,LeakyReLU,Dense,Activation,Flatten,Dropout,MaxPool2D
from keras import models
from keras.optimizers import Adam,RMSprop
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import ReduceLROnPlateau
2.加载数据集
np.random.seed(666) #随机种子,确保每次运行结果一致
train_data = pd.read_csv('/BASICCNN/MnistCsv/train.csv') #读取数据集
train_data = train_data.iloc[np.random.permutation(len(train_data))] #打乱数据集
train_data.head(3) #显示前3行 #默认显示5行
print(train_data.shape)
![]()
3.将训练集分解为训练集和验证集
train_size = train_data.shape[0] #训练集大小
print(train_size)
val_size = int(train_size*0.2) #验证集大小,占比20%
print(val_size)
#验证集数据和标签
X_val = np.asarray(train_data.iloc[:val_size,1:]).reshape([val_size,28,28,1]) #验证集
Y_val = np.asarray(train_data.iloc[:val_size,0]).reshape([val_size,1]) #标签
#训练集数据和标签
X_Train = np.asarray(train_data.iloc[val_size:,1:]).reshape([train_size-val_size,28,28,1])
Y_Train = np.asarray(train_data.iloc[val_size:,0]).reshape([train_size-val_size,1])
print(X_val.shape,X_Train.shape)

4.加载测试集test.csv
test_data = pd.read_csv('/BASICCNN/MnistCsv/test.csv')
X_test = np.asarray(test_data.iloc[:,:]).reshape([-1,28,28,1])
print(X_test.shape)
![]()
5.正则化数据集
X_Train =X_Train/255.
X_val = X_val/255.
X_test = X_test/255.
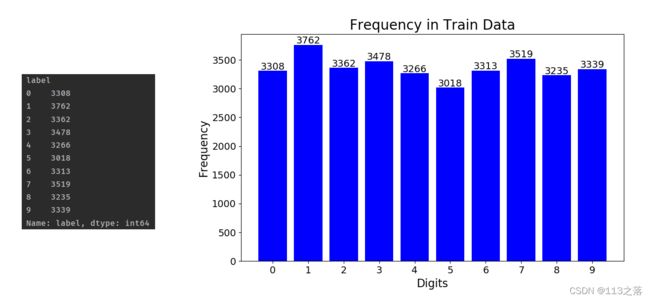
6.可视化训练集和验证集中不同数字出现的频率
#统计训练集中每个数字出现的频率
counts = train_data.iloc[val_size:,:].groupby('label')['label'].count() #groupby分组
print(counts)
#显示训练集
fig = plt.figure(figsize=(10,6)) #画布大小
fig.add_subplot(111) #1行1列,位置1
plt.bar(counts.index,counts.values,width=0.8,color='blue') #柱状图参数设置
for i in counts.index:
plt.text(i,counts.values[i]+20,str(counts.values[i]),horizontalalignment='center',fontsize=14)
plt.tick_params(labelsize=14)
plt.xticks(counts.index)
plt.xlabel('Digits',fontsize=16)
plt.ylabel('Frequency',fontsize=16)
plt.title('Frequency in Train Data',fontsize=20)
plt.savefig('/BASICCNN/TrainImage/Csvmnist_Train.png')
plt.show()
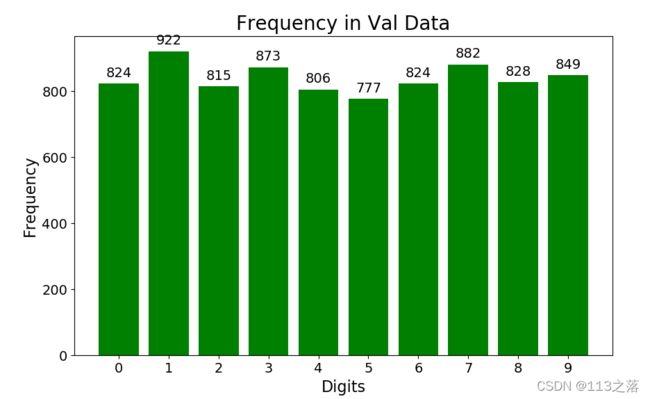
#显示验证集
fig = plt.figure(figsize=(10,6)) #画布大小
fig.add_subplot(111) #1行1列,位置1
counts2 = train_data.iloc[:val_size,:].groupby('label')['label'].count()
plt.bar(counts2.index,counts2.values,width=0.8,color='green') #柱状图参数设置
for i in counts2.index:
plt.text(i,counts2.values[i]+20,str(counts2.values[i]),horizontalalignment='center',fontsize=14)
plt.tick_params(labelsize=14)
plt.xticks(counts2.index)
plt.xlabel('Digits',fontsize=16)
plt.ylabel('Frequency',fontsize=16)
plt.title('Frequency in Val Data',fontsize=20)
plt.savefig('/BASICCNN/TrainImage/Csvmnist_Val.png')
plt.show()
7.显示部分数据集中的数字图片
rows = 5
cols = 6
fig = plt.figure(figsize=(2*cols,2*rows))
for i in range(rows*cols):
fig.add_subplot(rows,cols,i+1) #图片添加到相应的位置
plt.imshow(X_Train[i].reshape([28,28]),cmap='PuOr')
plt.axis('off')
plt.title(str(Y_Train[i]),y=-0.15,color='blue') #显示对应标签
plt.savefig('/BASICCNN/TrainImage/Csvmnist_Show.png')
plt.show()

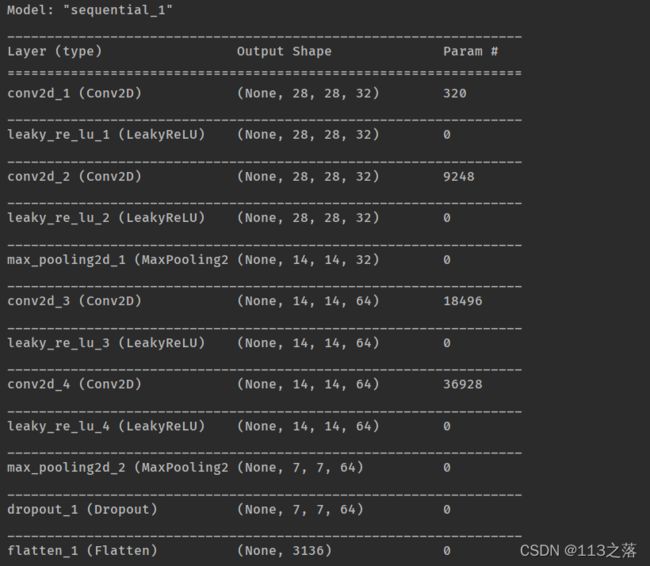
8.构建网络模型
model = models.Sequential()
model.add(Conv2D(32,3,padding='same',input_shape=(28,28,1)))
model.add(LeakyReLU())
model.add(Conv2D(32,3,padding='same'))
model.add(LeakyReLU())
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Conv2D(64,3,padding='same',input_shape=(28,28,1)))
model.add(LeakyReLU())
model.add(Conv2D(64,3,padding='same'))
model.add(LeakyReLU())
model.add(MaxPool2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten()) #维度拉平
model.add(Dense(256,activation='relu'))
model.add(Dense(64,activation='relu'))
model.add(Dense(10,activation='sigmoid')) #sigmoid归一[0,1]
9.编译模型
lr = 0.001 #学习率
loss = 'sparse_categorical_crossentropy' #损失函数
model.compile(Adam(lr=lr),loss=loss,metrics=['accuracy'])
model.summary()
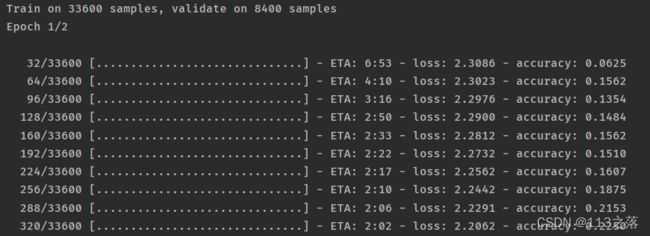
10.训练模型
epochs = 2
batch_size = 32
history1 = model.fit(X_Train,Y_Train,batch_size=batch_size,epochs=epochs,validation_data=(X_val,Y_val))
model.save('/BASICCNN/TrainModel_h5/CsvmnistTrain.h5')
![]()
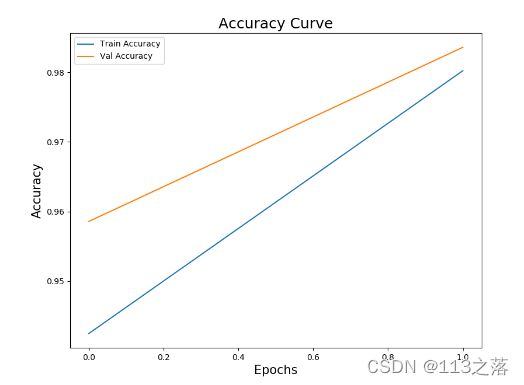
11.绘制训练和验证结果
fig = plt.figure(figsize=(20,7))
#121代表1行2列第一张
fig.add_subplot(121)
plt.plot(history1.epoch,history1.history['accuracy'],label='Train Accuracy')
plt.plot(history1.epoch,history1.history['val_accuracy'],label='Val Accuracy')
plt.title('Accuracy Curve',fontsize=18)
plt.xlabel('Epochs',fontsize=15)
plt.ylabel('Accuracy',fontsize=15)
plt.legend()
plt.savefig('/BASICCNN/TrainImage/CsvmnistTrain_accuracy.png')
plt.show()
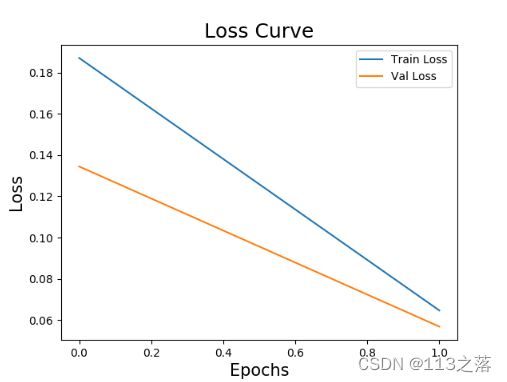
plt.plot(history1.epoch,history1.history['loss'],label='Train Loss')
plt.plot(history1.epoch,history1.history['val_loss'],label='Val Loss')
plt.title('Loss Curve',fontsize=18)
plt.xlabel('Epochs',fontsize=15)
plt.ylabel('Loss',fontsize=15)
plt.legend()
plt.savefig('/BASICCNN/TrainImage/CsvmnistVal_loss.png')
plt.show()
12.数据增强
datagen = ImageDataGenerator(
rotation_range=10,
zoom_range=0.1,
)
datagen.fit(X_Train)
13.学习率重置
new_lr = ReduceLROnPlateau(monitor='val_accuracy',patience=2,verbose=1,
factor=0.5,min_lr=0.00001)
14.重新训练
epochs = 2
history2 = model.fit_generator(datagen.flow(X_Train,Y_Train,batch_size=batch_size),
steps_per_epoch=int(X_Train.shape[0]/batch_size)+1,
epochs=epochs,validation_data=(X_val,Y_val),callbacks=[new_lr])
15.保存模型
model.save('/BASICCNN/TrainModel_h5/CsvmnistTrain2.h5')
![]()
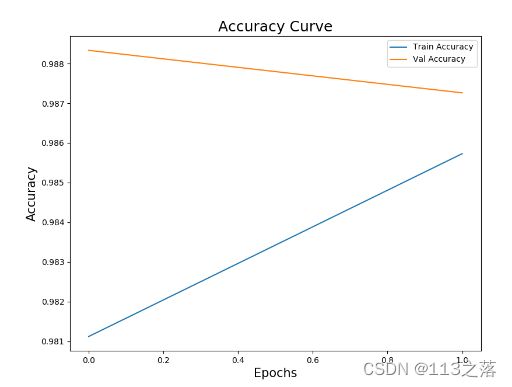
16.绘制训练和验证过程
fig = plt.figure(figsize=(20,7))
#121代表1行2列第一张
fig.add_subplot(121)
plt.plot(history2.epoch,history2.history['accuracy'],label='Train Accuracy')
plt.plot(history2.epoch,history2.history['val_accuracy'],label='Val Accuracy')
plt.title('Accuracy Curve',fontsize=18)
plt.xlabel('Epochs',fontsize=15)
plt.ylabel('Accuracy',fontsize=15)
plt.legend()
plt.savefig('/BASICCNN/TrainImage/CsvmnistTrain2_accuracy.png')
plt.show()
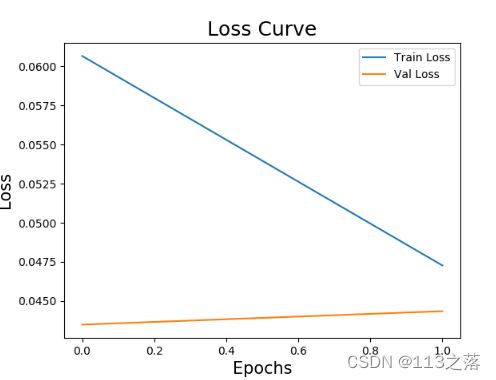
plt.plot(history2.epoch,history2.history['loss'],label='Train Loss')
plt.plot(history2.epoch,history2.history['val_loss'],label='Val Loss')
plt.title('Loss Curve',fontsize=18)
plt.xlabel('Epochs',fontsize=15)
plt.ylabel('Loss',fontsize=15)
plt.legend()
plt.savefig('/BASICCNN/TrainImage/CsvmnistVal2_loss.png')
plt.show()
17.显示被预测错误的图片
predict_val = np.argmax(model.predict(X_val),axis=1) #对验证集预测,输出每行预测概率最高的索引
rows = 10
cols = 10
fig = plt.figure(figsize=(cols,rows))
for i in range(rows*cols):
if Y_val[i] != predict_val[i]:
fig.add_subplot(rows,cols,1+i) #图片添加到相应的位置
plt.imshow(X_val[i].reshape([28,28]),cmap='BrBG')
plt.axis('off')
plt.title('T:'+str(Y_val[i])+'P:'+str(predict_val[i]),y=-0.15,color='blue') #显示对应标签
plt.savefig('/BASICCNN/TrainImage/Csvmnist_ShowError.png')
plt.show()

18.在测试上预测
Y_Test = np.argmax(model.predict(X_test),axis=1)
rows = 4
cols = 9
fig = plt.figure(figsize=(2*cols,2*rows))
for i in range(rows*cols):
fig.add_subplot(rows,cols,i+1) #图片添加到相应的位置
plt.imshow(X_test[i].reshape([28,28]),cmap='PuOr')
plt.axis('off')
plt.title(str(Y_Test[i]),y=-0.15,color='blue') #显示对应标签
plt.savefig('/BASICCNN/TrainImage/Csvmnist_Test.png')
plt.show()

19.可视化模型中间层
#1 抽取模型所有层,除了Flatten和Dense层
output_layers = [layer.output for layer in model.layers[:-4]]
#2 创建新的模型,一个输入,多个输出
new_model = models.Model(inputs=model.input,outputs=output_layers)
#3 预测每一层的输出
pred_2 = new_model.predict(X_val[2].reshape([1,28,28,1]))
pred_6 = new_model.predict(X_val[6].reshape([1,28,28,1]))
#4 抽取预测结果的第一层
first_layer = pred_2[0]
first_layer.shape #32 通道数
#5 显示以上两张图片,第一层的4个通道的图片
rows = 4
cols = 2
fig = plt.figure(figsize=(2*cols,2*rows))
for i in range(4):
fig.add_subplot(rows,cols,2*i+1)
plt.imshow(pred_2[0][0,:,:,i].reshape([28,28]),cmap='PuOr')
plt.axis('off')
fig.add_subplot(rows, cols, 2 * i + 2)
plt.imshow(pred_6[0][0, :, :, i].reshape([28, 28]), cmap='PuOr')
plt.axis('off')
plt.savefig('/BASICCNN/TrainImage/Csvmnistlayer_compare'+str(i)+'.png')
first_layer.shape[2]
#7 定义可视化函数
def plot_layer(layer,i,layer_name=None):
rows = layer.shape[-1]/16 #层的通道数
cols = 16
fig = plt.figure(figsize=(cols,rows))
for i in range(layer.shape[-1]):
fig.add_subplot(rows,cols,i+1)
plt.imshow(layer[0,:,:,i].reshape(layer.shape[2],layer.shape[2]),cmap='Blues')
plt.axis('off')
fig.suptitle(layer_name,fontsize=14)
fig.savefig('/BASICCNN/TrainImage/Csvmnistintlayer'+str(i)+'.png')
plt.show()
#6 可视化所有中间层
for i ,layer in enumerate(new_model.predict(X_val[6].reshape([1,28,28,1]))):
plot_layer(layer,i,output_layers[i].name)


20.将test的预测结果存入csv文件中
df_submit = pd.DataFrame([test_data.index+1,Y_Test],['Image ID','Label']).transpose()
df_submit.to_csv('/BASICCNN/MnistCsv/submit.csv',index=False)
dt = pd.read_csv('/BASICCNN/MnistCsv/submit.csv')
dt.head()
![]()