ViT 机器视觉transformer
transformer的高效计算(矩阵并行)和可扩展性
目录
1.引言
2.ViT结构
3.结论
4.具体实现
1.引言
(1)CV领域用transformer的局限性:图片尺寸大,参数太多,算法复杂度为序列长度的平方。引文中,有用局部窗口,有的将高和宽独立做两部分attention。本文使用的是标准Transformer架构,做有监督的图像分类任务。
(2)优势:随着数据集的增大,transformaer架构并没有表现出饱和性(saturating),在大规模数据集上,vit的效果要好一些。可在大规模数据集上做预训练,然后迁移到小数据集上做微调。
(3)卷积网络的优点:
locality局部性,相邻假设,要提取某一局部特征,只需用卷积核窗口大小的视野来看该特征局部(相关度最高)的信息即可。
translation equivariance,平移不变性,权值共享。f(g(x))=g(f(x)),f(x)卷积,g(x)平移,先做平移,先做卷积,效果一样。平移不变性是指不管输入如何平移,系统产生完全相同的响应 。平移同变性(translation equivariance)意味着系统在不同位置的工作原理相同,但它的响应随着目标位置的变化而变化 。卷积核看做不同位置的特征检测器,无论目标出现在图像中的哪个位置,它都会检测到同样的这些特征,输出同样的响应。最大池化返回感受野中的最大值,如果特征被移动了,但是仍然在感受野中,那么池化层仍会输出相同的最大值。
2.ViT结构

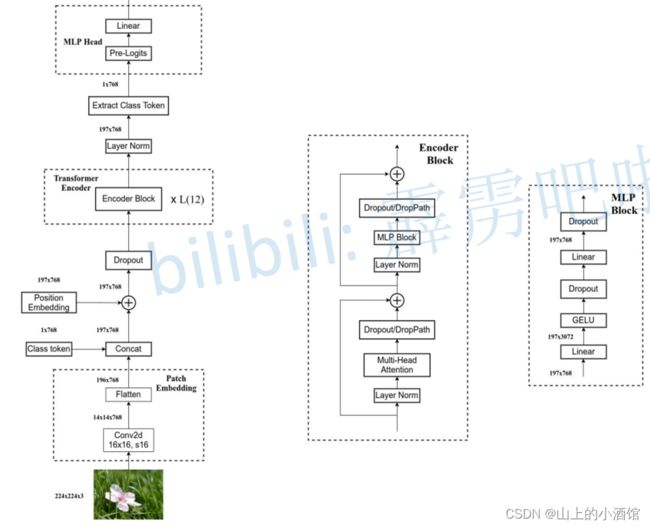
(1)ViT标准架构
将3*224*224(CHW)的图片按高和宽分14段,分成(14*14=196)个(3*16*16=768)的patch,即为196个token,每个token是维度为768的向量。再加上[CLS],即为197*768的张量,经过线性层(Linear Projection,768*768),线性层输出为(197*768)*(768*768)=197*768,在与位置编码(位置表197*768)相加,得到197*768的张量输入到Transformer Encoder中,进行汇聚。
Transformer Encoder的输入为197*768的tensor,进入layernorm,输出为197*768,注意力层的QKV(197*64*12)(H-W-Heads),contact后为197*768,MLP(197*768—197*3042—197*768),输出197*768通过MLP Head提取分类特征进行分类。
(2)CNN与Transformer混合模型
也有人将CNN与Transformer结合起来,先用CNN做特征提取,最后一层14*14的特征图,再进入Transformer分类。
3.结论
预训练后,微调时,图片大小不一致,位置编码失效。可采用差值的方式更新位置编码。
ViT,计算更快,在大的数据集上要优于Resnet。
4.具体实现
代码引用自,源码可以去大佬视频下方的github获取。11.2 使用pytorch搭建Vision Transformer(vit)模型_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1AL411W7dT?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1AL411W7dT?spm_id_from=333.999.0.0
(1)droppath
(2)PatchEmbed (卷积;kernel_size=16*16,stride=16,768channels)
3@224*224----3@16*16*14*14即为196*768 Conv2d(),flatten(),transpose()
(3)Attention
# qkv(): [batch_size, num_patches + 1, 3 * total_embed_dim]
# reshape: [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]
# permute: [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]
qkv=self.qkv(x).reshape(B,N,3,self.num_heads,C//self.num_heads).permute(2,0,3,1,4)
#将拼在一起的qkv切片分开
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)(4)MLP多层感知机 768----3042----768
(5)Encoder_Block
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))(6)VisionTransformer
x = self.patch_embed(x) #patch_embedding
x = torch.cat((cls_token, x), dim=1) #[CLS], contcat196*768---197*768
x = self.pos_drop(x + self.pos_embed) #加入位置编码
x = self.blocks(x) #Transformer块,Attention机制
x = self.norm(x) #标准化
#21k的网络,全连接层FC和than激活函数;1k或自己的数据集,nn.Identity()
self.pre_logits(x[:, 0]) #切片,1*768,提取特征至[CLS]
x = self.head(x) #nn.Linear(self.num_features,num_classes);768----类别数(7)权重初始化_init_vit_weights(m)
(8)训练
python的学习还是要多以练习为主,想要练习python的同学,推荐可以去看,他们现在的IT题库内容很丰富,属于国内做的很好的了,而且是课程+刷题+面经+求职+讨论区分享,一站式求职学习网站,最最最重要的里面的资源全部免费。
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网求职之前,先上牛客,就业找工作一站解决。互联网IT技术/产品/运营/硬件/汽车机械制造/金融/财务管理/审计/银行/市场营销/地产/快消/管培生等等专业技能学习/备考/求职神器,在线进行企业校招实习笔试面试真题模拟考试练习,全面提升求职竞争力,找到好工作,拿到好offer。https://www.nowcoder.com/link/pc_csdncpt_ssdxjg_python
他们这个python的练习题,知识点编排详细,题目安排合理,题目表述以指导的形式进行。整个题单覆盖了Python入门的全部知识点以及全部语法,通过知识点分类逐层递进,从Hello World开始到最后的实践任务,都会非常详细地指导你应该使用什么函数,应该怎么输入输出。
牛客网(牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网)还提供题解专区和讨论区会有大神提供题解思路,对新手玩家及其友好,有不清楚的语法,不理解的地方,看看别人的思路,别人的代码,也许就能豁然开朗。
快点击下方链接学起来吧!
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网
引用:
11.2 使用pytorch搭建Vision Transformer(vit)模型_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1AL411W7dT?spm_id_from=333.999.0.0
11.1 Vision Transformer(vit)网络详解_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1Jh411Y7WQ?spm_id_from=333.999.0.0