Vision Transformer(ViT)论文精读和Pytorch实现代码解析
Vision Transformer(ViT)论文精读和Pytorch实现代码解析
自从CV领域的Vision Transformer把NLP领域的Transormer借鉴到图像处理领域,就屠杀了各大CV榜单。本文将精读最原始的Vision Transformer论文,并介绍其PyTorch实现。
Abstract
虽然说transformer已经是NLP(自然语言处理)领域的一个标准,但是用transformer来做CV还是很有限的。在视觉领域,自注意力要么是跟卷积神经网络一起使用,要么用来把某一些卷积神经网络中的卷积替换成自注意力,但是还是保持整体的结构不变。
这篇文章证明了这种对于卷积神经网络的依赖是完全不必要的,一个纯的Vision Transformer直接作用于一系列图像块的时候,也是可以在图像分类任务上表现得非常好的,尤其是当在大规模的数据上面做预训练然后迁移到中小型数据集上面使用的时候,Vision Transformer能够获得跟最好的卷积神经网络相媲美的结果。并且它只需要更少的训练资源,而且表现还特别好。
1 Introduction
自注意力机制的网络,尤其是Transformer,已经是自然语言中的必选模型了,现在比较主流的方式,就是先去一个大规模的数据集上去做预训练,然后再在一些特定领域的小数据集上面做微调(BERT文章中提出)得益于transformer的计算高效性和可扩展性,现在已经可以训练超过1000亿参数的模型了(比如说GPT3)。随着模型和数据集的增长,目前还没有发现任何性能饱和的现象。
所以现在很多工作就是在研究如何将自注意力用到机器视觉中:一些工作是说把卷积神经网络和自注意力混到一起用;另外一些工作就是整个将卷积神经网络换掉,全部用自注意力。这些方法其实都是在干一个事情:因为序列长度太长,所以导致没有办法将transformer用到视觉中,所以就想办法降低序列长度。最近的一些模型,这种方式虽然理论上是非常高效的,但事实上因为这个自注意力操作都是一些比较特殊的自注意力操作,所以说无法在现在的硬件上进行加速,所以就导致很难训练出一个大模型,因此在大规模的图像识别上,传统的残差网络还是效果最好的。
本文是被transformer在NLP领域的可扩展性所启发,本文想要做的就是直接应用一个标准的transformer直接作用于图片,尽量做少的修改(不做任何针对视觉任务的特定改变),看看这样的transformer能不能在视觉领域中扩展得很大很好。
本文在引言的最后说在中型大小的数据集上(比如说ImageNet)上训练的时候,如果不加比较强的约束,Vit的模型其实跟同等大小的残差网络相比要弱一点。
作者对此的解释是:这个看起来不太好的结果其实是可以预期的,因为transformer跟卷积神经网路相比,它缺少了一些卷积神经网络所带有的归纳偏置。为了验证这个假设,作者在更大的数据集(14M-300M)上做了预训练,这里的14M是ImageNet 22k数据集,300M是google自己的JFT 300M数据集,然后发现大规模的预训练要比归纳偏置好。Vision Transformer只要在有足够的数据做预训练的情况下,就能在下游任务上取得很好的迁移学习效果。具体来说,就是当在ImageNet 21k上或者在JFT 300M上训练,ViT能够获得跟现在最好的残差神经网络相近或者说更好的结果。
总结一下,引言就说明了四件事:
第一件事是说因为Transformer在NLP中扩展的很好,越大的数据或者越大的模型,最后performance会一直上升,没有饱和的现象,然后提出:如果将Transformer使用到视觉中,会不会产生同样的效果;
第二件事是讲述前人的工作,讲清楚了自己的工作和前人工作的区别:之前的工作要么就是把卷积神经网络和自注意力结合起来,要么就是用自注意力去取代卷积神经网络,但是从来没有工作直接将transformer用到视觉领域中来,而且也都没有获得很好的扩展效果;
第三件事讲Vision Transformer就是用了一个标准的Transformer模型,只需要对图片进行预处理,然后送到transformer中就可以了,而不需要做其他的改动,这样可以彻底地把一个视觉问题理解成是一个NLP问题,就打破了CV和NLP领域的壁垒;
第四件事就是展示了结果,只要在足够多的数据做预训练的情况下,Vision Transformer能够在很多数据集上取得很好的效果。
2 Related Works
transformer在NLP领域的应用:
自从2017年transformer提出做机器翻译以后,基本上transformer就是很多NLP任务中表现最好的方法。
现在大规模的transformer模型一般都是先在一个大规模的语料库上做预训练,然后再在目标任务上做一些细小的微调,这当中有两系列比较出名的工作:BERT和GPT。BERT是用一个denoising的自监督方式;GPT用的是language modeling(已经有一个句子,然后去预测下一个词是什么,也就是next word prediction,预测下一个词)做自监督。这两个任务其实都是人为定的,语料是固定的,句子也是完整的,只是人为的去划掉其中的某些部分或者把最后的词拿掉,然后去做完形填空或者是预测下一个词,所以这叫自监督的训练方式。
跟本文工作最相似的是一篇ICLR2020的论文,区别在于Vision Transformer使用了更大的patch更大的数据集。在计算机视觉领域还有很多工作是把卷积神经网络和自注意力结合起来的,这类工作相当多,而且基本涵盖了视觉里的很多任务(检测、分类、视频、多模态等)
还有一个工作和本文的工作很相近,叫image GPT。image GPT也是一个生成性模型,也是用无监督的方式去训练的,它和Vit相近的地方在于它也用了transformer。
3 Method
在模型的设计上是尽可能按照最原始的transformer来做的,这样做的好处就是可以直接把NLP中比较成功的Transformer架构拿过来用,而不用再去对模型进行改动,而且因为transformer因为在NLP领域已经火了很久了,它有一些写的非常高效的实现,同样ViT也可以直接拿来使用。
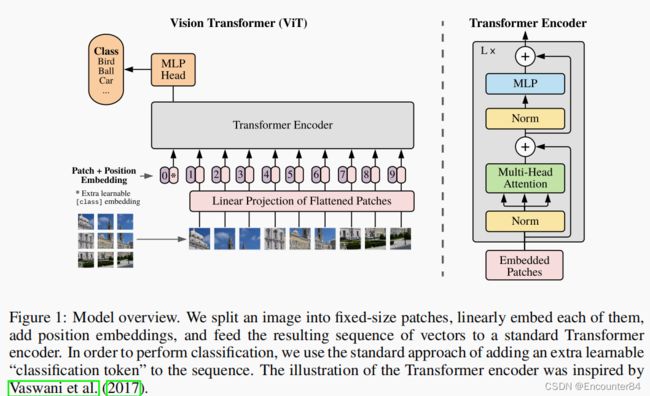
模型的总览图如上。ViT的基本框架和流程如下:
1.首先给定一张图,先将这张图打成了很多的patch(如上图左下角所示),这里是将图打成了九宫格
2.然后再将这些patch变成了一个序列,每个patch通过线性投射层(相当于一个全连接层)的操作得到一个特征(就是本文中提到的patch embedding)自注意力是所有元素之间两两做交互,所以本身并不存在顺序的问题,但是对于图片来说,图片本身是一个整体,这个九宫格是有自己的顺序的,如果顺序颠倒了就不是原来的图片了。所以类似于NLP,给patch embedding加上了一个position embedding,等价于加上了一个位置编码
3.在加上这个位置编码信息之后,整体的token就既包含了图片块原本有的图像信息,又包含了这个图片块的所在位置信息
4.在得到了这个token之后,接下来就跟NLP中完全一样了,直接将它们输入进一个Transformer encoder,然后Transformer encoder就会得到很多输出
5.这么多输出,应该拿哪个输出去做分类?这里借鉴了BERT,BERT中有一个extra learnable embedding,它是一个特殊字符CLS(分类字符),所以这里也添加了一个特殊的字符,用 * 代替,而且它也是有position embedding,它的位置信息永远是0。
6.因为所有的token都在跟其它token做交互信息,所以作者相信,class embedding能够从别的序列后面的embedding中学到有用的信息,从而只需要根据class embedding的输出做最后的判断就可以了
7.MLP Head其实就是一个通用的分类头
8.最后用交叉熵函数进行模型的训练
9.模型中的Transformer encoder是一个标准的Transformer,具体的结构如上图中右部分所示。
10.Transformer的输入是一些patch,一个Transformer block叠加了L次整体上来看Vision Transformer的架构还是相当简洁的,它的特殊之处就在于如何把一个图片变成一系列的token
具体的模型的前向过程:
1.假如说有一个224×224×3的图片,如果使用16×16的patch size大小,就会得到196个图像块,每一个图像块的维度就是16×16×3=768,到此就把原先224×224×3的图片变成了196个patch,每个patch的维度是768
2.接下来就要将这些patch输入一个线性投射层,这个线性投射层其实就是一个全连接层(在文章中使用E表示),这个全连接层的维度是768×768,第二个768就是文章中的D,D是可以变的,如果transformer变得更大了,D也可以相应的变得更大,第一个768是从前面图像的patch算来的(16×16×3),它是不变的。
3.经过了线性投射就得到了patch embedding(X×E),它是一个196×768的矩阵(X是196×768,E是768×768),意思就是现在有196个token,每个token向量的维度是768
到目前为止就已经成功地将一个vision的问题变成了一个NLP的问题了,输入就是一系列1d的token,而不再是一张2d的图片了
4.除了图片本身带来的token以外,这里面加了一个额外的cls token,它是一个特殊的字符,只有一个token,它的维度也是768,这样可以方便和后面图像的信息直接进行拼接。所以最后整体进入Transformer的序列的长度是197×768(196+1:196个图像块对应的token和一个特殊字符cls token)
5.最后还要加上图像块的位置编码信息,这里是将图片打成了九宫格,所以位置编码信息是1到9,但是这只是一个序号,并不是真正使用的位置编码,具体的做法是通过一个表(表中的每一行就代表了这些1到9的序号,每一行就是一个向量,向量的维度是768,这个向量也是可以学的)得到位置信息,然后将这些位置信息加到所有的token中(注意这里是加,而不是拼接,序号1到9也只是示意一下,实际上应该是1到196),所以加上位置编码信息之后,这个序列还是197×768
6.到此就做完了整个图片的预处理,包括加上特殊的字符cls和位置编码信息,也就是说transformer输入的embedded patches就是一个197×768的tensor,这个tensor先过一个layer norm,出来之后还是197×768,然后做多头自注意力,这里就变成了三份:k、q、v,每一个都是197×768,这里因为做的是多头自注意力,所以其实最后的维度并不是768,假设现在使用的是VIsion Transformer的base版本,即多头使用了12个头,那么最后的维度就变成了768/12=64,也就是说这里的k、q、v变成了197×64,但是有12个头,有12个对应的k、q、v做自注意力操作,最后再将12个头的输出直接拼接起来,这样64拼接出来之后又变成了768,所以多头自注意力出来的结果经过拼接还是197×768
7.然后再过一层layer norm,还是197×768
8.然后再过一层MLP,这里会把维度先对应地放大,一般是放大4倍,所以就是197×3072
然后再缩小投射回去,再变成197×768,就输出了
9.以上就是一个Transformer block的前向传播的过程,进去之前是197×768,出来还是197×768,这个序列的长度和每个token对应的维度大小都是一样的,所以就可以在一个Transformer block上不停地往上叠加Transformer block,最后有L层Transformer block的模型就构成了Transformer encoder。
10.Transformer从头到尾都是使用D当作向量的长度的,都是768,这个维度是不变的
Pytorch代码实现如下:
首先,导入我们需要的包,其中einops和einsum包用来操作张量。
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
Layer Norm层的实现如下,其中参数dim是维度,参数fn是预先要进行的处理函数,是Attention或者FeedForward。
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
前馈神经网络层由全连接层,激活函数GELU和Dropout实现。参数dim和hidden_dim分别是输入输出的维度和中间层的维度,dropout是dropout操作的概率。
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
Attention神经网络层是Transformer中的核心部件,参数heads是多头自注意力的头的数目,dim_head是每个头的维度。本层的对应公式就是经典的Tansformer的计算公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V Attention(Q,K,V)=softmax(dkQKT)V
class Attention(nn.Module):
def __init__(self, dim, heads=8, dim_head=64, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout),
) if project_out else nn.Identity()
def forward(self, x):
b, n, _, h = *x.shape, self.heads
qkv = self.to_qkv(x).chunk(3, dim=-1) # (b, n(65), dim*3) ---> 3 * (b, n, dim)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=h), qkv) # q, k, v (b, h, n, dim_head(64))
dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
attn = self.attend(dots)
out = einsum('b h i j, b h j d -> b h i d', attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
定义好几个层之后,就可以构建整个Transformer Block了,即对应框图中的整个右半部分Transformer Encoder。
参数depth是每个Transformer Block重复的次数,其他参数与上面各个层的介绍相同。
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout=dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return x
在 x x x 送入transformer之前,是如下公式的预处理操作:
z = [ x class ; x p 1 E , x p 2 E , … ; x p N E ] + E p o s , E ∈ R ( P 2 ⋅ C ) ) × D , E p o s ∈ R ( N + 1 ) × D \mathbf{z}=\left[\mathbf{x}_{\text {class }} ; \mathbf{x}_{\mathrm{p}}^{1} \mathbf{E}, \mathbf{x}_{\mathrm{p}}^{2} \mathbf{E}, \ldots ; \mathbf{x}_{\mathrm{p}}^{\mathrm{N}} \mathbf{E}\right]+\mathbf{E}_{\mathrm{pos}}, \quad \mathbf{E} \in \mathbb{R}^{(\left.\mathrm{P}^{2} \cdot \mathrm{C})\right) \times \mathrm{D}}, \mathbf{E}_{\mathrm{pos}} \in \mathbb{R}^{(\mathrm{N}+1) \times \mathrm{D}} z=[xclass ;xp1E,xp2E,…;xpNE]+Epos,E∈R(P2⋅C))×D,Epos∈R(N+1)×D
positional embedding和class token由nn.Parameter()定义,该函数会将送到其中的Tensor注册到Parameters 列表,随模型一起训练更新。
到这里为止,ViT模型的定义就全部完成了,在训练脚本中实例化一个ViT模型来进行训练即可:
model_vit = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(16, 3, 256, 256)
preds = model_vit(img)
print(preds.shape) # (16, 1000)
参考网址:
1.ViT精读
2.ViT Pytorch实现