YOLOv3:K-means聚类和K-means++聚类anchor box理论以及源代码
文章目录
-
- 引言
- K-means
- K-means++
引言
最近在做YOLOv3的项目,想了想有哪些方面可以优化的,其中一个想法就是聚类算法了。
YOLOv3本身是用K-means聚类出锚框的,但K-means算法本身具有一定的局限性,聚类结果容易受初始值选取影响。K-means算法具体步骤可以参考我这篇博客:看得懂的K-means
K-means
K-means源码来源:YOLOv3_TensorFlow
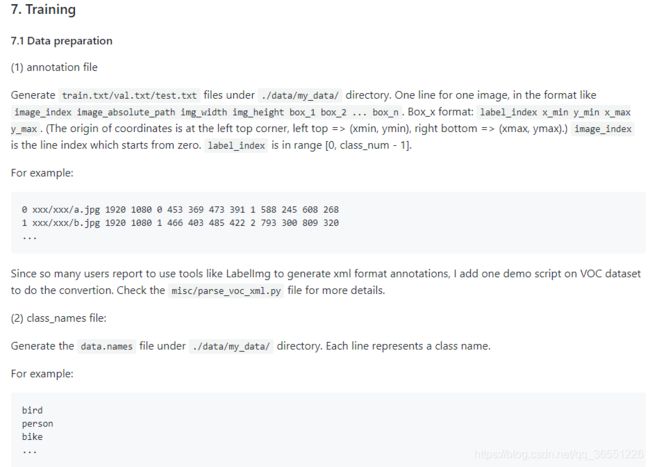
首先我们来看一眼YOLOv3训练集的数据格式

第一部分:图片索引
第二部分:图片路径
第三部分:图片宽和高(w,h)
第四~七部分:每个部分都是一个边界框,上图中就是有5张图,每张图有4个框
对于每个框说明如下:以 0,634,583,717,667举例
0:标签索引
634,583:框左上角坐标
717,667:框右下角坐标
具体的也可以看GitHub上的train部分
YOLOv3的K-means算法有个不同就是距离计算,都是图像怎么计算距离呢?标准K-means算法使用的是欧氏距离,而我们聚类的目的是让anchor box和ground truth越接近越好,所以定义一个新的距离公式:
![]()
这样就保证,交并比越大,距离越小,距离越小就越可能属于同一类
源代码
如果看了我那篇K-means算法的博客的话,这段代码我相信很好理解。方便起见我还是注释了下,也保留原作者的注释
(顺便一提,GitHub源码中的translate_boxes函数对于K-means算法没有任何作用,我这直接删掉了)
# coding: utf-8
# This script is modified from https://github.com/lars76/kmeans-anchor-boxes
from __future__ import division, print_function
import numpy as np
def iou(box, clusters):
"""
Calculates the Intersection over Union (IoU) between a box and k clusters.
param:
box: tuple or array, shifted to the origin (i. e. width and height)
clusters: numpy array of shape (k, 2) where k is the number of clusters
return:
numpy array of shape (k, 0) where k is the number of clusters
"""
x = np.minimum(clusters[:, 0], box[0])
y = np.minimum(clusters[:, 1], box[1])
if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0:
raise ValueError("Box has no area")
intersection = x * y # 相交面积
box_area = box[0] * box[1]
cluster_area = clusters[:, 0] * clusters[:, 1]
iou_ = np.true_divide(intersection, box_area + cluster_area - intersection + 1e-10) # 交并比 = 相交面积 / 两个框面积相加并减去相交面积
# iou_ = intersection / (box_area + cluster_area - intersection + 1e-10)
return iou_
def avg_iou(boxes, clusters):
"""
Calculates the average Intersection over Union (IoU) between a numpy array of boxes and k clusters.
param:
boxes: numpy array of shape (r, 2), where r is the number of rows
clusters: numpy array of shape (k, 2) where k is the number of clusters
return:
average IoU as a single float
"""
return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])]) # 查看训练集框和anchor box的交并比
def kmeans(boxes, k, dist=np.mean):
"""
Calculates k-means clustering with the Intersection over Union (IoU) metric.
param:
boxes: numpy array of shape (r, 2), where r is the number of rows
k: number of clusters
dist: distance function
return:
numpy array of shape (k, 2)
"""
rows = boxes.shape[0] # boxes就是result,看看有多少个框
distances = np.empty((rows, k)) # 存放每个点与中心点的距离
last_clusters = np.zeros((rows,)) # 存放上一次的距离,用于结束循环
np.random.seed()
# the Forgy method will fail if the whole array contains the same rows
clusters = boxes[np.random.choice(rows, k, replace=False)] # 随机选取k个中心点,默认是9个
while True:
for row in range(rows):
distances[row] = 1 - iou(boxes[row], clusters) # 上述的距离公式,用1减去每个框和中心点的交并比,得到每个框到中心点的距离
nearest_clusters = np.argmin(distances, axis=1) # 得到每个框距离哪个中心点距离最小
if (last_clusters == nearest_clusters).all(): # 如果上一次距离和这次距离一样,跳出循环,结束(距离一样,聚类结果肯定一样)
break
for cluster in range(k):
clusters[cluster] = dist(boxes[nearest_clusters == cluster], axis=0) # 更新中心点
'''
利用与第几个点距离最小的框求均值得到聚类结果,如现在求第一个anchor box,
那么就取出nearest_clusters == 0的box,因为这些box是与第一个中心点距离最近的(nearest_clusters)=0
然后利用均值,求出新的中心点
'''
last_clusters = nearest_clusters
return clusters
def parse_anno(annotation_path, target_size=None):
anno = open(annotation_path, 'r') # 读入训练集
result = []
for line in anno:
s = line.strip().split(' ') # 以空格分割(回头再看一眼训练集格式)
img_w = int(s[2])
img_h = int(s[3])
s = s[4:] # 高(h)后面的数据都是框的数据
box_cnt = len(s) // 5 # 每5个数据为1个框,看看有多少个框
for i in range(box_cnt):
x_min, y_min, x_max, y_max = float(s[i*5+1]), float(s[i*5+2]), float(s[i*5+3]), float(s[i*5+4]) # 取出每个框的左上角坐标和右下角坐标
width = x_max - x_min # 计算框的宽
height = y_max - y_min # 计算框的高
assert width > 0
assert height > 0
# use letterbox resize, i.e. keep the original aspect ratio
# get k-means anchors on the resized target image size
if target_size is not None:
resize_ratio = min(target_size[0] / img_w, target_size[1] / img_h) # 计算图像放缩比例
width *= resize_ratio
height *= resize_ratio # 将框的尺寸同比例放缩
result.append([width, height]) # 将框的结果放入result中
# get k-means anchors on the original image size
else:
result.append([width, height])
result = np.asarray(result) # 变成numpy数组比较好操作
return result # 此时result中存放的是训练集所有框经过放缩后的尺寸
def get_kmeans(anno, cluster_num=9):
anchors = kmeans(anno, cluster_num)
ave_iou = avg_iou(anno, anchors)
anchors = anchors.astype('int').tolist()
anchors = sorted(anchors, key=lambda x: x[0] * x[1])
return anchors, ave_iou
if __name__ == '__main__':
# target resize format: [width, height]
# if target_resize is speficied, the anchors are on the resized image scale
# if target_resize is set to None, the anchors are on the original image scale
target_size = [416, 416] # 由于YOLOv3默认输入为416*416,所以需要将图像都放缩到这个尺寸,anchor同时也需要放缩
annotation_path = "train.txt" # 训练集路径
anno_result = parse_anno(annotation_path, target_size=target_size)
anchors, ave_iou = get_kmeans(anno_result, 9) # 对result中的结果进行聚类,聚类出9个框
# 格式化输出anchors格式
anchor_string = ''
for anchor in anchors:
anchor_string += '{},{}, '.format(anchor[0], anchor[1])
anchor_string = anchor_string[:-2]
print('anchors are:')
print(anchor_string)
print('the average iou is:')
print(ave_iou)
到此K-means就结束了,其实K-means++和K-means差不多,如果理解了K-means那么K-means++就很好理解了。
K-means++
上文说过K-means存在受初始值选取影响大的问题,那么怎么降低初始值选取的影响呢?
那我们可以慢慢来嘛,一个一个选,不要一次性选K个
关于K-means++可以参考我这篇博客K-means++
源代码
代码和K-means的非常像,唯一区别就是,这段代码计算IOU的时候,K-means++我是一个一个中心点输入计算的,所以单独有个iou_kpp为K-means++用
from __future__ import division, print_function
import numpy as np
import random
import math
def iou(box, clusters):
x = np.minimum(clusters[:, 0], box[0])
y = np.minimum(clusters[:, 1], box[1])
if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0:
raise ValueError("Box has no area")
intersection = x * y
box_area = box[0] * box[1]
cluster_area = clusters[:, 0] * clusters[:, 1]
iou_ = np.true_divide(intersection, box_area + cluster_area - intersection + 1e-10)
# iou_ = intersection / (box_area + cluster_area - intersection + 1e-10)
return iou_
def iou_kpp(box, clusters):
x = np.minimum(clusters[0], box[0])
y = np.minimum(clusters[1], box[1])
if np.count_nonzero(x == 0) > 0 or np.count_nonzero(y == 0) > 0:
raise ValueError("Box has no area")
intersection = x * y
box_area = box[0] * box[1]
cluster_area = clusters[0] * clusters[1]
iou_ = np.true_divide(intersection, box_area + cluster_area - intersection + 1e-10)
# iou_ = intersection / (box_area + cluster_area - intersection + 1e-10)
return iou_
def avg_iou(boxes, clusters):
return np.mean([np.max(iou(boxes[i], clusters)) for i in range(boxes.shape[0])])
def get_closest_dist(point, centroids):
min_dist = math.inf # 初始设为无穷大
print(centroids)
for i, centroid in enumerate(centroids):
print(centroids)
dist = 1 - iou_kpp(point, centroid) # 点和当前每个中心点进行计算距离
if dist < min_dist:
min_dist = dist # 注意我K-means++博客中的这句“指该点离中心点这一数组中所有中心点距离中的最短距离”
return min_dist
def kpp_centers(data_set: list, k: int) -> list:
"""
从数据集中返回 k 个对象可作为质心
"""
cluster_centers = []
cluster_centers.append(random.choice(data_set))
d = [0 for _ in range(len(data_set))]
#print(d)
for _ in range(1, k):
total = 0.0
for i, point in enumerate(data_set):
d[i] = get_closest_dist(point, cluster_centers) # 与最近一个聚类中心的距离
total += d[i]
total *= random.random()
for i, di in enumerate(d): # 轮盘法选出下一个聚类中心;
total -= di
if total > 0:
continue
cluster_centers.append(data_set[i])
break
return cluster_centers
def kmeans(boxes, k, dist=np.median):
rows = boxes.shape[0]
distances = np.empty((rows, k))
last_clusters = np.zeros((rows,))
np.random.seed()
# the Forgy method will fail if the whole array contains the same rows
clusters = kpp_centers(boxes, k)
clusters = np.array(clusters)
#clusters = boxes[np.random.choice(rows, k, replace=False)] 这是K-means的,两个切换注释下就行了
while True:
for row in range(rows):
distances[row] = 1 - iou(boxes[row], clusters) # iou很大则距离很小
# 对每个标注框选择与其距离最接近的集群中心的标号作为所属类别的编号。
nearest_clusters = np.argmin(distances, axis=1) # axis=1表示沿着列的方向水平延伸
if (last_clusters == nearest_clusters).all():
break
for cluster in range(k):
clusters[cluster] = dist(boxes[nearest_clusters == cluster], axis=0) # 给每类算均值新中心点
last_clusters = nearest_clusters
print(last_clusters)
return clusters
def parse_anno(annotation_path, target_size=None):
anno = open(annotation_path, 'r')
result = []
# 对每一个标记图片
for line in anno:
s = line.strip().split(' ')
img_w = int(s[2])
img_h = int(s[3])
s = s[4:]
box_cnt = len(s) // 5
# 分别处理每一个标记框的信息,并提取标记框的高度和宽度,存入result 列表
for i in range(box_cnt):
x_min, y_min, x_max, y_max = float(s[i*5+1]), float(s[i*5+2]), float(s[i*5+3]), float(s[i*5+4])
width = x_max - x_min
height = y_max - y_min
# assert width > 0
# assert height > 0
# use letterbox resize, i.e. keep the original aspect ratio
# get k-means anchors on the resized target image size
if target_size is not None:
resize_ratio = min(target_size[0] / img_w, target_size[1] / img_h)
width *= resize_ratio
height *= resize_ratio
result.append([width, height])
# get k-means anchors on the original image size
else:
result.append([width, height])
result = np.asarray(result)
return result
def get_kmeans(anno, cluster_num=9):
# 使用kmeans算法计算需要的anchors
anchors = kmeans(anno, cluster_num)
ave_iou = avg_iou(anno, anchors)
# 格式化为int类型
anchors = anchors.astype('int').tolist()
# 按照面积大小排序,
anchors = sorted(anchors, key=lambda x: x[0] * x[1])
return anchors, ave_iou
if __name__ == '__main__':
target_size = [416, 416]
annotation_path = "train.txt"
anno_result = parse_anno(annotation_path, target_size=target_size)
anchors, ave_iou = get_kmeans(anno_result, 9)
# 格式化输出anchors数据
anchor_string = ''
for anchor in anchors:
anchor_string += '{},{}, '.format(anchor[0], anchor[1])
anchor_string = anchor_string[:-2]
print('anchors are:')
print(anchor_string)
print('the average iou is:')
print(ave_iou)