【论文笔记】Segformer论文阅读笔记
论文:SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
SegFormer是一个简单、高效但功能强大的语义分割模型,它结合了Transformer 与轻量级多层感知 (MLP) 解码器。SegFormer有2个特征:
(1)SegFormer包含一个可以输出多尺度信息的transformer编码器(没有使用position embedding,避免了position插值);
(2)SegFormer没有使用复杂的解码器。
为了简单起见,Segformer并未使用OHEM,辅助损失函数和类别不平衡交叉熵损失。
目录
网络结构
Hierarchical Transformer Encoder
1、Hierarchical Feature Representation
2、Overlapped Patch Merging
3、Efficient Self-Attention
4、Mix-FFN(Feed-forward Network)
Lightweight All-MLP Decoder
Effective Receptive Field Analysis
实验结果
网络结构
网络结构如下图所示,主要包含2个模块:
(1)Encoder:分层的Transformer产生高分辨率低级特征和低分辨率的细节特征;
(2)Decoder:轻量级的全MLP解码器融合多级特征得到语义分割结果。
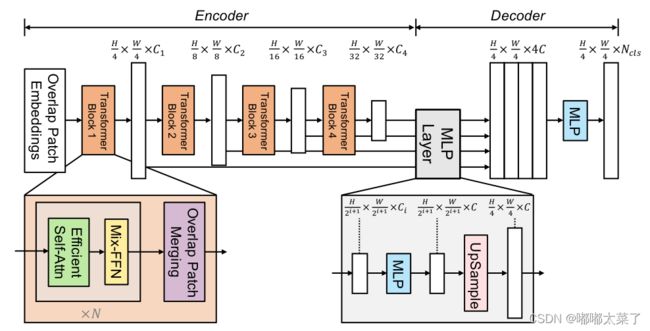
Hierarchical Transformer Encoder
作者设计了一系列的MiT( Mix Transformer encoder)编码器模型(MiT-B0 to MiT-B5),它们结构相同但是模型大小不一样,MiT设计灵感来自ViT,但是针对语义分割任务做了一些优化。
1、Hierarchical Feature Representation
ViT只能生成单分辨率的特征图,类似CNN的多尺度特征图,MiT生成不同尺度的特征图,生成的特征图分辨率是原图的1/4 1/8 1/16 1/32。
2、Overlapped Patch Merging
ViT的Patch Embedding是无重叠的(non-overlapping),但是non-overlapping对语义分割任务来说,会导致patch边缘不连续。MiT使用overlapped patch embedding,保证patch边缘连续。
3、Efficient Self-Attention
Transformer的主要计算瓶颈在Attention层,设Q/K/V的维度为[N, C](N=H*W),注意力计算公式如下:

它的计算复杂度是O(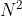 ),当对大分辨率的图片,计算量过大,segformer引入一个衰减比率R,利用全连接层减少Attention计算量。K的维度为[N, C],先将其reshape为[N/R, C*R],通过全连接层将维度变为[N/R, C],那么计算复杂度变为O(/R),从stage1到stage4,R分别设置为[64, 16, 4, 1]。
),当对大分辨率的图片,计算量过大,segformer引入一个衰减比率R,利用全连接层减少Attention计算量。K的维度为[N, C],先将其reshape为[N/R, C*R],通过全连接层将维度变为[N/R, C],那么计算复杂度变为O(/R),从stage1到stage4,R分别设置为[64, 16, 4, 1]。
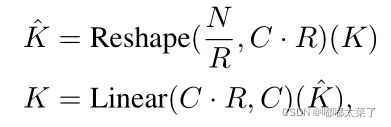
4、Mix-FFN(Feed-forward Network)
作者认为位置编码对语义分割任务来说是不必要的,但是语义分割任务需要相邻像素间的信息,在MLP前向传播中引入卷积层(为了减少参数,使用深度可分离卷积),公式如下:

实验证明3x3的卷积可以提供给transformer充分的位置信息。
Lightweight All-MLP Decoder
对于不同分辨率的特征图Fi,将其上采样至1/4,然后将多个特征图concat后,送入后续网络,得到分割结果。

Effective Receptive Field Analysis
下图为DeepLabv3+和SegFormer在100张cityscapes取平均的有效感受野对比图,可以看出DeepLabV3+的感受野远小于SegFormer;
实验结果
下图为Segformer在不同数据集上的表现。
