使用sklearn完成4种基本的分类算法:朴素贝叶斯算法、决策树算法、人工神经网络、支持向量机算法
文章目录
- 实验目的
- 实验内容及步骤
- 实验数据说明
- 实验过程
-
- 朴素贝叶斯分类
- 决策树
-
- 决策树概念简介
- 神经网络
- SVM
实验目的
- 巩固4种基本的分类算法的算法思想:朴素贝叶斯算法,决策树算法,人工神经网络,支持向量机算法;
- 能够使用现有的分类器算法代码进行分类操作
- 学习如何调节算法的参数以提高分类性能;
实验内容及步骤
利用现有的分类器算法对文本数据集进行分类
实验步骤:
1.了解文本数据集的情况并阅读算法代码说明文档;
2.利用文本数据集中的训练数据对算法进行参数学习;
3.利用学习的分类器对测试数据集进行测试;
4.统计测试结果;
利用现有的分类器算法对文本数据集进行分类
实验步骤:
1.了解文本数据集的情况并阅读算法代码说明文档;
2.利用文本数据集中的训练数据对算法进行参数学习;
3.利用学习的分类器对测试数据集进行测试;
4.统计测试结果;
实验数据说明
汽车评估数据集包含1728个数据,其中训练数据1350,测试数据 个。每个数据包含6个属性,所有的数据分为4类:
Class Values: unacc, acc, good, vgood
Attributes:
buying: vhigh, high, med, low.
maint: vhigh, high, med, low.
doors: 2, 3, 4, 5,more.
persons: 2, 4, more.
lug_boot: small, med, big.
safety: low, med, high.
其中Attributes是指它的属性子集。而其属性子集包括了六类,分别是购买(buying),维修(maint),车门数(doors),承载人数(Persons),载行李量(Luggage boot),安全性(safety)。每种属性又分成了相应的子集,分别为高中低或者是能承载的数量。下图是提供该数据集的网站截图。
实验过程
- 首先将所需要的库和数据集导入,分为训练集和测试集
from sklearn import svm,tree
from sklearn.naive_bayes import GaussianNB,MultinomialNB,BernoulliNB
from sklearn.metrics import classification_report
from sklearn.neural_network import MLPClassifier
import numpy as np
def iris_type1(s):
Class_Values = {b'unacc':0, b'acc':1, b'good':2, b'vgood':3}
return Class_Values[s]
def iris_type2(s):
buying = {b'vhigh': 0, b'high': 1, b'med': 2, b'low': 3}
return buying[s]
def iris_type3(s):
maint = {b'vhigh': 0, b'high': 1, b'med': 2, b'low': 3}
return maint[s]
def iris_type4(s):
doors = {b'2':0, b'3':1, b'4':2, b'5more':3}
return doors[s]
def iris_type5(s):
persons = {b'2':0, b'4':1, b'more':2}
return persons[s]
def iris_type6(s):
lug_boot = {b'small':0, b'med':1, b'big':2}
return lug_boot[s]
def iris_type7(s):
safety = {b'low':0, b'med':1, b'high':2}
return safety[s]
path1 = u'D:/大三上/人工智能导论/实验/dataset/test.txt' # 数据文件路径
path2 = u'D:/大三上/人工智能导论/实验/dataset/predict.txt'
train = np.loadtxt(path1,dtype=int,delimiter=',',converters={0: iris_type3, 1: iris_type3, 2: iris_type4,
3: iris_type5, 4: iris_type6, 5: iris_type7,
6: iris_type1})
test = np.loadtxt(path2,dtype=int,delimiter=',',converters={0: iris_type3, 1: iris_type3, 2: iris_type4,
3: iris_type5, 4: iris_type6, 5: iris_type7,
6: iris_type1})
- 将训练集和测试集的特征属性划分
train_x, train_y = np.split(train, (6,), axis=1) #划分特征 和 标签
test_x, test_y = np.split(test, (6,), axis=1) #划分属性 和 value
朴素贝叶斯分类
- 朴素贝叶斯算法 3种朴素贝叶斯分类算法:GaussianNB(高斯朴素贝叶斯)、MultinomialNB(多项式朴素贝叶斯)、BernoulliNB(伯努利朴素贝叶斯)
高斯模型
当特征是连续变量的时候,假设特征分布为正太分布,根据样本算出均值和方差,再求得概率。

clf = GaussianNB()
clf.fit(train_x, train_y.ravel())
print (clf.score(train_x, train_y))
print (clf.score(test_x, test_y))
输出结果:
0.766666666667
0.666666666667
- 多项式朴素贝叶斯:sklearn.naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)主要用于离散特征分类,例如文本分类单词统计,以出现的次数作为特征值
多项式模型:多项式模型在计算先验概率P(Yk)P(Yk)和条件概率P(xi|Yk)P(xi|Yk)时,会做一些平滑处理,具体公式为:
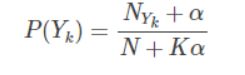
参数说明: alpha:浮点型,可选项,默认1.0,添加拉普拉修/Lidstone平滑参数
fit_prior:布尔型,可选项,默认True,表示是否学习先验概率,参数为False表示所有类标记具有相同的先验概率
class_prior:类似数组,数组大小为(n_classes,),默认None,类先验概率
clf = MultinomialNB(alpha=2.0,fit_prior=True)
clf.fit(train_x, train_y.ravel())
print (clf.score(train_x, train_y))
print (clf.score(test_x, test_y))
输出结果:
0.731851851852
0.582010582011
- 伯努利模型 伯努利模型适用于离散特征的情况,伯努利模型中每个特征的取值只能是1和0

伯努利朴素贝叶斯:sklearn.naive_bayes.BernoulliNB类似于多项式朴素贝叶斯,也主要用户离散特征分类,和MultinomialNB的区别是:MultinomialNB以出现的次数为特征值,BernoulliNB为二进制或布尔型特性
参数说明: binarize:将数据特征二值化的阈值
clf = BernoulliNB(binarize = 3.0,fit_prior=True)
clf.fit(train_x, train_y.ravel())
print (clf.score(train_x, train_y))
print (clf.score(test_x, test_y))
输出结果:
0.733333333333
0.582010582011
决策树
决策树概念简介
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果
分类树(决策树)是一种十分常用的分类方法。他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
比较重要的参数:
criterion :规定了该决策树所采用的的最佳分割属性的判决方法,有两种:“gini”,“entropy”。 gini值表示采用了CART树的规则,采用一种二分递归分割的技术,将当前的样本集分为两个子样本集,使得生成的的每个非叶子节点都有两个分支。因此,CART算法生成的决策树是结构简洁的二叉树。即不纯度来作为树结构的指标的二叉树, 在CART算法中, 基尼不纯度表示一个随机选中的样本在子集中被分错的可能性。
基尼不纯度为这个样本被选中的概率乘以它被分错的概率。
当一个节点中所有样本都是一个类时,基尼不纯度为零。
而entropy则表示选择C3树的规则,即信息增益来作为树结构产生的标准,选择分裂后信息增益最大的属性进行分裂。

参数说明:
max_depth:限定了决策树的最大深度,防止过拟合
min_samples_leaf:限定了叶子节点包含的最小样本数,这个属性对于防止数据碎片问题很有作用。
使用该算法训练数据时的注意事项:
当我们数据中的feature较多时,一定要有足够的数据量来支撑我们的算法,不然的话很容易overfitting 。
PCA是一种避免高维数据overfitting的办法。从一棵较小的树开始探索,用export方法打印出来看看。
善用max_depth参数,缓慢的增加并测试模型,找出最好的那个depth。
善用min_samples_split和min_samples_leaf参数来控制叶子节点的样本数量,防止overfitting。
平衡训练数据中的各个种类的数据,防止一个种类的数据dominate。
6.
#使用信息熵作为划分标准,对决策树进行训练
clf=tree.DecisionTreeClassifier(criterion='entropy')
clf.fit(train_x, train_y.ravel())
print (clf.score(train_x, train_y))
print (clf.score(test_x, test_y))
clf=tree.DecisionTreeClassifier(criterion='gini')
clf.fit(train_x, train_y.ravel())
print (clf.score(train_x, train_y))
print (clf.score(test_x, test_y))
神经网络
人工神经网络 多层向前神经网络组成部分
输入层(input layer),隐藏层(hiddenlayer),输出层(output layer)
每层由单元(units)组成
输入层(input layer)是由训练集的实例特征向量传入
经过连接结点的权重(weight)传入下一层,一层的输出是下一层的输入
隐藏层的个数是任意的,输出层和输入层只有一个
每个单元(unit)也可以被称作神经结点,根据生物学来源定义
上图称为2层的神经网络(输入层不算)
一层中加权的求和,然后根据非线性的方程转化输出
作为多层向前神经网络,理论上,如果有足够多的隐藏层(hidden layers)和足够大的训练集,可以模拟出任何方程

训练方法:
计算的时间复杂度非常高 solver=‘lbfgs’, MLP的求解方法:L-BFGS 在小数据上表现较好,Adam 较为鲁棒,SGD在参数调整较优时会有最佳表现(分类效果与迭代次数); SGD标识随机梯度下降。
SGD:随机从训练集选取数据训练,不归一化数据,需要专门在外面进行归一化,支持L1,L2正则化。
L-BFGS:所有的数据都会参与训练,算法融入方差归一化和均值归一化。支持L1,L2正则化。
adam: 随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率
参数说明:
alpha:同样也称为学习率或步长因子,它控制了权重的更新比率(如 0.001)。较大的值(如 0.3)在学习率更新前会有更快的初始学习,而较小的值(如 1.0E-5)会令训练收敛到更好的性能
L2的参数:MLP是可以支持正则化的,默认为L2,具体参数需要调整,正则化的目的是限制参数过多或者过大,避免模型更加复杂
hidden_layer_sizes=(5, 2) hidden层2层,第一层5个神经元,第二层2个神经元)
通过应用Softmax作为输出函数,MLPClassifier支持多类别分类。进一步,模型支持多标签分类,即,一个样本能够属于多个类。对于每一个类,原始输出经历logistic函数。大于等于0.5的值,记为1;否则,记为0. 对于一个样本的预测输出,值是1的索引代表分派给那个样本的类。
clf = MLPClassifier(hidden_layer_sizes=(12,9),
activation='logistic',
solver='lbfgs',
alpha=1e-3,
random_state=1)
clf.fit(train_x, train_y.ravel())
print (clf.score(train_x, train_y))
print (clf.score(test_x, test_y))
输出结果:
0.988888888889
0.910052910053
SVM
训练svm分类器 C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。

参数说明:
gamma : ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。默认是’auto’,则会选择1/n_features
kernel='linear’时,为线性核。
kernel='rbf’时(default),为高斯核,
decision_function_shape='ovr’时,为one v rest,即一个类别与其他类别进行划分,
decision_function_shape='ovo’时,为one v one,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
核函数
clf = svm.SVC(C=0.8, kernel='rbf', gamma=10, decision_function_shape='ovo')
clf.fit(train_x, train_y.ravel())
输出结果:
SVC(C=0.8, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=‘ovo’, degree=3, gamma=10, kernel=‘rbf’,
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
计算svc分类器的准确率
高斯核:

print (clf.score(train_x, train_y)) # 精度
y_hat = clf.predict(train_x)
print (clf.score(test_x, test_y))
y_hat = clf.predict(test_x)
#print(classification_report(test_y,y_hat))
输出结果:
0.963703703704
0.582010582011
线性划分:
clf = svm.SVC(C=0.8, kernel='linear', decision_function_shape='ovr')
clf.fit(train_x, train_y.ravel())
print (clf.score(train_x, train_y))
print (clf.score(test_x, test_y))
输出结果:
0.868888888889
0.804232804233