YOLO v1原理详解
YOLO v1原理详解
YOLO(You Only Look Once)这篇论文提出了一个实时的新型目标检测框架,不同于以前RCNN系列基于Region划分再分类和DPM(Deformable Parts Model)这类基于滑动窗口的目标检测系统。YOLO将整个目标检测问题中的bounding box和classfier这两大问题统一成了一个回归的问题。
相较于其他state-of-the-art的目标检测系统, YOLO容易出错的地方在于bbox的定位, 但是却有着更少的False Positive(主要就是RCNN系列在划分Region Proposals的时候, 会产生大量的背景Region,这样很容易造成数据倾斜,虽然论文中采用了Hard Negative Mining,但是也仅仅是缓解了一下这个问题)。
文章目录
- YOLO v1原理详解
-
- 1. Introduction
- 2. YOLO v1原理
-
- 2.1 Bounding Boxes
- 2.2 Conditional Class Probabilities
- 2.3 Class-specific Confidence Score
- 3. Loss function
-
- 3.1 四个损失项
- 3.2 λ n o o b j 、 λ c o o r d \lambda_{noobj}、\lambda_{coord} λnoobj、λcoord
- 3.3 w ^ 和 h ^ \sqrt{\hat{w}}和\sqrt{\hat{h}} w^和h^
- 4. 总结
1. Introduction
YOLO之前的目标检测系统主要分为两大类,第一类就是DPM这类使用滑动窗口在整个图像中均匀移动的目标检测系统;第二类就是RCNN这类先生成Region Proposals,然后再在Region Proposals的基础之上运行Classifier,最后由于Region Proposals生成的较多,所以还会使用一些post-proccessing去掉一些重复的bboxes。这些复杂的pipelines除了会降低训练速度,还会让整个模型被分割成为不同的几个部分,难以统一训练和优化,即违背了深度学习里面end-to-end的思想(不过Faster RCNN作为和YOLO v1同期的目标检测模型, 它也是端到端的)。
2. YOLO v1原理
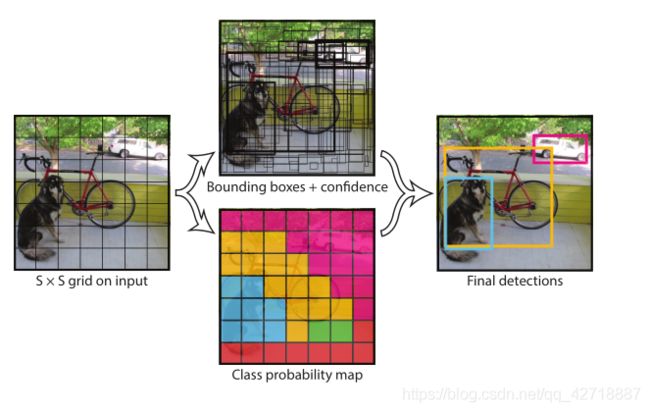
如上图所示,一副图像经过YOLO v1之后,将会得到以下结果:
- 整幅图像被划分为 S × S S \times S S×S个网格
- 对于每个网格都会输出B个Bounding Boxes和一组C个conditional class probabilities
PS: 上面两个点其实是同时进行的,图像经过YOLO v1之后,就会得到 S × S × ( B ∗ 5 + C ) S \times S \times (B*5 + C) S×S×(B∗5+C)这样的结果张量(后面的预测细节会解释为什么是这样的张量)。
下面对YOLO v1的预测细节做详细的介绍。
2.1 Bounding Boxes
前面提到了, YOLO v1将整个图像划分为了 S × S S \times S S×S个格子,而每一个格子又包括了B个Bounding Boxes。文中用5个参数描述一个Bounding Boxes,分别是:x, y, w, h, confidence。它们的含义如下:
- (x, y) 坐标是Bounding Box相对于格子边界(也就是左上角)的偏移量。
- (w, h) 则是Bouding Box相对于整个图像的宽高占比。
- confidence = P r ( O b j e c t ) × I O U p r e d t r u t h Pr(Object) \times IOU^{truth}_{pred} Pr(Object)×IOUpredtruth,也就是说如果Bounding Box包含物体中心的话, 那么confidence就是 I O U p r e d t r u t h IOU^{truth}_{pred} IOUpredtruth, 如果不包含物体中心的话就是0。
上面的(x, y)和(w, h)我没有详细说怎么计算,如果想要看详细计算公式的话,可以参考这篇博客YOLO模型参数解释。
2.2 Conditional Class Probabilities
前面还提到了YOLO v1的每一个格子都会输出一组C个conditional class probablities, 即 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object)。这个概率代表了该格子上如果有对象,那这个对象是 C l a s s i Class_i Classi的概率是多少。这里请注意,原文中还提到:We Only predict one set of class probabilities per grid cell,也就是说无论每个格子中有多少个BBoxes,预测的时候也只是输出一组C个概率值,也就是预测时只是输出一个最高概率的class。这就意味着一个格子里面如果包含了多个物体的中心,这时候YOLO v1难以解决这个问题。
2.3 Class-specific Confidence Score
在测试的阶段,结合2.1和2.2的输出,我们就很容易得到各个类的confidence score,公式如下:
P r ( C l a s s i ∣ O b j e c t ) ⏞ c o n d i t i o n a l c l a s s p r o b × P r ( O b j e c t ) × I O U t r u t h p r e d ⏞ b b o x c o n f i d e n c e = P r ( C l a s s i ) × I O U t r u t h p r e d \overbrace{Pr(Class_i|Object)}^{conditional~class~prob} \times \overbrace{ Pr(Object) \times IOU_{truth}^{pred} }^{bbox~confidence}= Pr(Class_i) \times IOU_{truth}^{pred} Pr(Classi∣Object) conditional class prob×Pr(Object)×IOUtruthpred bbox confidence=Pr(Classi)×IOUtruthpred
这个score既包含了class的概率, 又包含了bbox位置是否预测的准确。
3. Loss function
这里我单开一节讲解YOLO v1的Loss function,并没有将其并入2中YOLO v1原理的讲解之中,是因为Loss function中有些细节需要单独讨论。下图示YOLO v1的Loss function, 这张图的原博客在此,感觉画的比较好,但是有一点错误,我已经更正了:
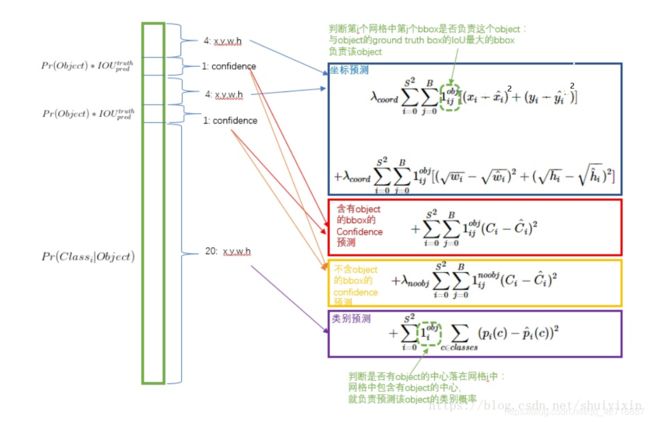
3.1 四个损失项
这个loss function主要分成了上图的这四个部分。从公式可以看出来,只有在Object出现在第i个网格中的时候,才会有第1,2,4这四个损失项,如果第i个网格中没有Object的话,只有黄色的第3个损失项。如果一个Object出现在了第i个网格中的时候,只有第1,2,4这四个损失项。
3.2 λ n o o b j 、 λ c o o r d \lambda_{noobj}、\lambda_{coord} λnoobj、λcoord
由于每个图像中不包含Object的网格居多,所以第3个损失项需要被适当地调小,不然会让模型变得向预测无Object偏斜。在此处作者引入了 λ n o o b j = 0.5 \lambda_{noobj}=0.5 λnoobj=0.5这个参数。
由于模型惩罚BBox位置损失和分类损失力度一样,而YOLO v1这个模型在输出BBox位置时精度较差,所以作者想加大惩罚BBox位置损失的力度,引入了 λ c o o r d = 5 \lambda_{coord}=5 λcoord=5和这个参数。
3.3 w ^ 和 h ^ \sqrt{\hat{w}}和\sqrt{\hat{h}} w^和h^
作者在计算x,y损失的时候并没有进行开方处理,而在计算w,h损失的时候进行了开方处理。因为,对于一个大的bbox来说 w ^ , h ^ \hat{w},\hat{h} w^,h^差一点问题不大,而对一个小的bbox来说差一点问题就很严重,所以作者使用了开方运算。原理如下所示,同样是搬运的那篇文章的:
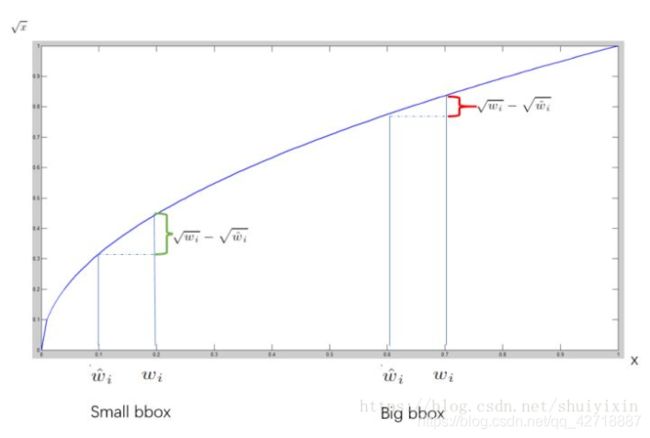
从开方函数图像很容易就知道对于较大的bbox来说两者之差是会被慢慢缩小的,即惩罚力度没有小bbox这么大。
4. 总结
YOLO v1实现了精度和速度双赢,并且作为一个end-to-end的模型,十分便于训练和部署。原文中在艺术画数据集中证明了YOLO v1有着比较强的泛化能力,并且与其他的实时目标检测系统做了详细的对比,这些部分就需要大家自行阅读了。