Frustum PointNets for 3D Object Detection from RGB-D Data 论文学习笔记
Abstract
论文中直接通过对RGB-D的原始扫描图来对原始点云进行处理。这个方法的关键挑战是如何在大规模场景的点云中对物体进行定位(region Proposal)
相较于只使用3D图的proposal,我们的方法在物体定位中使用了成熟的2D物体检测器和额外的3D深度学习。这使得我们的模型在高效的基础上获得很高的召回率(recall 指正例被预测正确的比例)
得益于直接对原始的3D点云进行处理,我们的方法也能够精准的估计3D bonding box,即便是在很高的遮挡率和很稀疏的点云的情况下
Introduction
对于2D bounding box 和 pixel mask 任务,3D语义理解的在很多的应用中需求很大,例如自动驾驶、AR(augmented reality)。本文中学习一个最重要的3D感知任务,那就是3D物体检测,一个用于物体类别识别和估计3D bonding box的任务。
目前现有的大多数的3D检测任务都是将3D点云进行投影到2D平面进行操作。
《Multi-view Convolutional Neural Networks for 3D Shape Recognition》
这篇论文中就是对一个立体图像进行12个角度的拍照,获取到十二个角度的2D平面图像,之后根据将每个图像过一个CNN然后再合并过一个Pooling,最后将结果再过一个CNN然后通过softmax进行分类。其中卷积核选用的算子是VLFeat。
或者是进行量子化体积网格然后进行卷积操作
《3D ShapeNets: A Deep Representation for Volumetric Shapes 2015》
这篇论文就是利用将数据放到体素网格中的方法,然后对体素网格进行卷积
PointNets网络对于点云的分类和预测每一个点的语义类别上起到了很好的作用,但是我们不清楚它在3D物体检测上能否很好的运用。为了实现这个目标,首先有一个关键的挑战,那就是如何在三维空间中有效地提出三维物体的可能位置?我们可以模仿2D层面直接通过sliding windows 或者 region proposal network来罗列候选的3D boxs。但是这种方式的计算复杂度会呈现立方级的增长,得到结果的时间过长。
因此,在我们的模型中,我们通过以下原则来减少搜索空间:
- 首先我们通过从图像检测器中挤出二维边界盒来提取一个物体的三维包围椎体
- 然后在由3D包围椎体修剪出的3D空间中我们连续的对3D实体进行分割,然后使用PointNet的两种变体进行三维边界box回归。其中segmentation network 预测目标物体的3D掩码,regression network 估计3D bounding box。
相比较其它将3D图像转换为2D图然后对图进行CNN卷积的操作,本文的模型的优点在于:首先,在论文中提出的3D object detection pipeline在三维坐标上连续应用了一些变换,这些变换将点云调整为一连串更有约束性和规范性的框架。再者,在3D空间中进行学习可以更好的利用3D空间的拓扑和几何结构。
Related Work
3D Object Dectection from RGB-D Data
-
基于前视图像的方法:
利用单眼RGB图像和形状先验或闭塞模式来推断3D边界盒。
通过2D maps 的深度图的信息,然后利用CNNs来定位2D图像中的物体。
-
基于鸟瞰图的方法:
将LiDAR点云转换为鸟瞰图然后训练一个RPN网络来预测3D bounding box。但是这种方法在检测小物体时比较落后,并且在垂直方向上有多个物体时没办法很好的进行检测
-
基于3D的方法:
一些模型通过从3D点云中获取,并手工设计的特征来训练SVM然后通过滑动窗口来定位物体。进阶版利用体素格栅上的CNNs来替代SVM
Deep Learning on Point Clouds
- 在特征学习之前,大多数现有的工作在特征学习之前都会将点云转换成图像或者体积类型。
Problem Definition
给予一个RGB-D数据作为输入,我们的目标是分类并且确定物体在3D空间中的位置。Projection matrix 被给出这样才能从2D 图像的区域获取到3D的锥型图。amodal box 会完全框住整个物体即使物体的一部分被遮挡或者被截断。
3D box 可以参数化: h , w , l h,w,l h,w,l为其大小, c x , c y , c z c_x,c_y,c_z cx,cy,cz作为其中心, θ , ϕ , ψ \theta,\phi,\psi θ,ϕ,ψ作为其旋转角度。其中论文中的模型只考虑了围绕上轴方向上的旋转。
3D Detection with Frustum PointNets
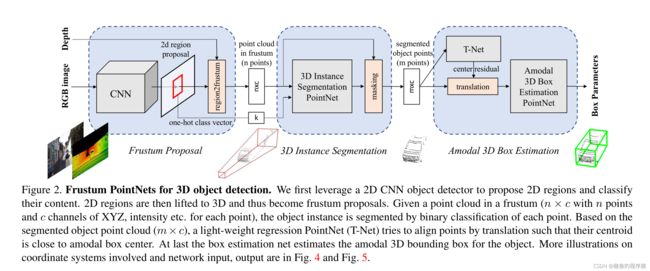
Frustum Proposal
因为当时的3D传感器能够给予的信息要少于一般的2D照相机,因此我们利用成熟的二维物体检测器来提出RGB图像中的二维物体区域,并对物体进行分类。
通过已知的相机投影矩阵下,2D box 可以升维一个3D椎体来定义一个3D 的搜索空间。然后我们收集所有在椎体中的点形成一个frustum point cloud。但是因为这个三维椎体可以朝向很多方向,这导致点云的位置有很大的变化。因此,我们通过向中心视图旋转来归一化三角椎体,使其的中心轴与图像平面正交。这一正则化方法有效的提升算法的旋转不变性
3D Instance Segmentation
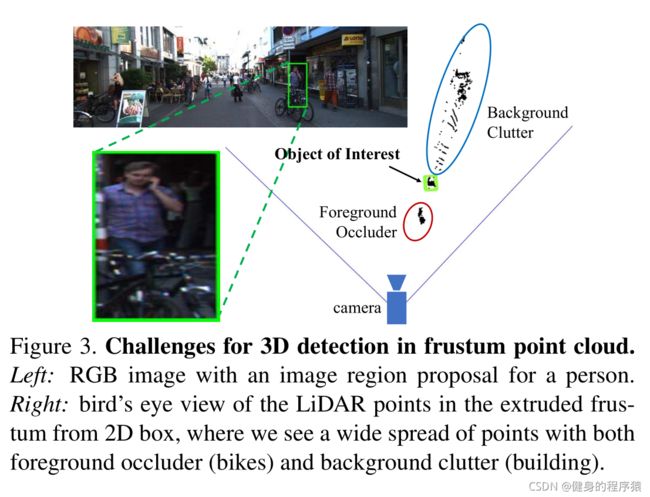
对于一个给定的2D图像的位置,有一些方法可以用来获得3D物体的位置。
第一种方法是直接通过2D 的CNNs 结合深度图进行回归,但是由于遮挡物和自然背景中的杂波是十分常见的(从Figure 3 中可以看出),这很大程度上会影响定位。在3D点云层面上进行实例分割会比在图像上进行分割要容易,因为对于图像来讲,两个在深度上相差甚远的像素点在图中却十分临近,而3D点云上却有更大的距离。因此我们在3D点云层面上进行分割而不是2D图像。因此我们使用PointNet-based Network 进行点云在frustums上的分割
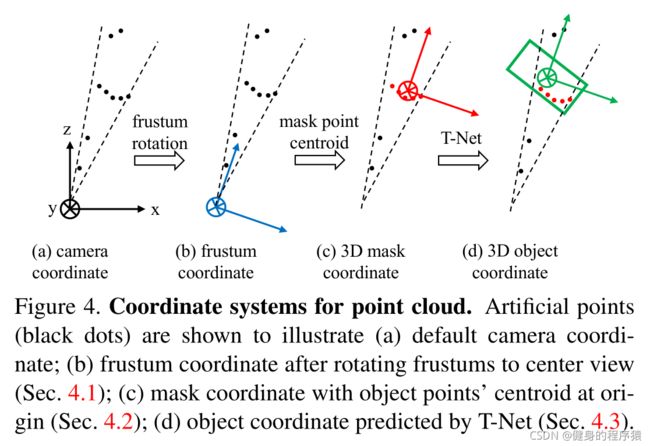
同时因为点云中的真实物理坐标相较于传感器的范围较大,所以坐标的范围值较大,因此我们将3D bounding box的对象点的中点作为作为mask coordinate的原点坐标。如Figure 4 中所示
3D Instance Segmentation PointNet
网络主要作用是对frustum中的点判断其属于物体的可能性,因为这其中可能有很多的点被遮挡或者有噪点。因此网络需要学习遮挡和杂波模式,以及识别某个类别物体的几何形状
在一个多类别的检测任务重,我们会使用语义。例如,如果我们知道一个目标物体是行人,然后我们的分割网络会使用这个先验条件去找到像行人的几何物体。其中对语义的编码采用one-hot编码模式,然后将one-hot vector 和中级点云特征进行连接。
经过3D Segmentation之后的点需要再次进行正则化,将点云转换进以3D box 中心点为原点的坐标中。值得注意的是,模型特意不对点云进行缩放,因为部分点云的球型边界大小会受到视点的影响,而点云的真实大小有助于对点云的box进行估计。
Amodal 3D Box Estimation
该模块通过使用box regression PointNet和预处理转换网络来估计物体的amodal oriented 3D bounding box。
Learning-based 3D Alignment by T-Net
虽然前面使用了对点云 frustum 上的划分所产生的mask coordinate ,但我们发现使用这个坐标的原点和amodal box的中心仍然存在较大的差距,因此,我们采用light-weight regression PointNet来估计整个物体的真正的中心 ,然后将坐标转换到以该中心为原点的坐标上。
Amodal 3D Box Estimation PointNet
通过残差的方法来预测box 的中心。由box estimation network预测的中心残差与之前来自T-Net的和被遮蔽点的中心残差相结合,恢复一个绝对中心。对于box size 和 heading angle 我们采用一个混合型的分类和回归方法。
首先我们定义了一个NS 大小的模板和一个NH 平分的箱子,我们的模型对size 和 heading 都会做一个分类,我们的模型将把尺寸/标题分类到那些预先定义的类别,并预测每个类别的残差数字。最终,该网络会输出3+ 4 × NS + 2 × NH的数字。
Training with Multi-task Losses
我们使用多Loss来同时优化包括3D instance segmentation PointNet,T-Net 和amodal box estimation PointNet 在内的三个网络。其中 L c 1 − r e g L_{c1-reg} Lc1−reg 是T-Net的坐标平移损失, L c 2 − r e g L_{c2-reg} Lc2−reg是box estimation Net的中心回归的损失(也就是判断长方体模型中心产生的损失); L h − c l s L_{h-cls} Lh−cls 和 L h − r e g L_{h-reg} Lh−reg分别对应朝向的类别损失和回归损失(这是因为frustum pointnet给box的朝向规定了几个量化的方向,在代码中既包含了这些方向的标号,也会将这些标号转成连续的弧度值); L s − c l s L_{s-cls} Ls−cls 和 L s − r e g L_{s-reg} Ls−reg分别对应是box size 的类别损失和回归损失。因此最后的损失函数为
L m u l t i − t a s k = L s e g + λ ( L c 1 − r e g + L c 2 − r e g + L h − c l s + L h − r e g + L s − c l s + L s − r e g + γ L c o r n e r ) L_{multi−task} =L_{seg} + \lambda(L_{c1−reg} + L _{c2−reg} + L_{h−cls} + L_{h−reg} + L_{s−cls} + L_{s−reg} + \gamma L_{corner} ) Lmulti−task=Lseg+λ(Lc1−reg+Lc2−reg+Lh−cls+Lh−reg+Ls−cls+Ls−reg+γLcorner)
类别判定过程中用的是Softmax方法,回归问题用的是smooth- l 1 l_1 l1(huber)损失。
联合优化箱体参数的Corner Loss
上面的损失公式将box的尺寸和角度等参数视为独立的变量计算损失,但实际情况是box的尺寸和角度共同决定了box的信息,而最终得到的box的信息才是我们想要的。因此,frumstum pointnet引入了box的角损失,也就是上面的损失公式中的 L c o r n e r L_{corner} Lcorner,具体的计算公式为:
L c o r n e r = ∑ i = 1 N S ∑ j = 1 N H δ i j m i n { ∑ k = 1 8 ∥ P k i j − P k ∗ ∥ , ∑ k = 1 8 ∥ P k i j − P k ∗ ∗ ∥ } L_{corner}=\sum_{i=1}^{N\ S}\sum_{j=1}^{N\ H}\delta_{ij}min\{\sum_{k=1}^8\parallel P_k^{ij}-P_k^{*}\parallel ,\sum_{k=1}^8\parallel P_k^{ij}-P_k^{**}\parallel\} Lcorner=i=1∑N Sj=1∑N Hδijmin{k=1∑8∥Pkij−Pk∗∥,k=1∑8∥Pkij−Pk∗∗∥}
corner Loss 是预测box 和 真实box 的八个角点的距离。
最后两项之间找一个最小值的原因是,frusmtum pointnet算法认为估计得到的box上下颠倒其实并不影响最终给出的结果,因此将box上下旋转180度,取最小的那个损失。
Conclusion
从实验的结果可以看出,第一,对于距离合理且没有遮挡的物体(这种情况下我们可以获得足够多的点),我们的模型输出的准确率在语义分割和3D bounding box的任务上表现优异。第二,我们的模型还可以在只有部分数据的时候正确的进行预测(例如并列停着的车)
但另一个角度看,我们确实发现了在一些模式上表现不好。
第一个错误是由于点云过于稀疏,有时甚至少于5个点。因此导致了对姿势和尺寸的估计不准确,我们认为未来图像特征可以改善这个情况。
第二个挑战是对于同一个frustum有多个同一类别的实例,虽然我们当前的通道一次性只在一个frustum中识别一个物体,多个物体的存在可能会让其困惑。如果我们可以在同一个frustum中识别多个物体,那这种情况应该会得到改善。
第三个挑战是有的时候由于光线过暗或者过多的遮挡,我们的2D传感器可能错过物体。由于我们的frustum proposal是基于region proposal,因此在没有二维检测的情况下,不会检测到三维物体。然而,我们的3D实例分割和amodal 3D box estimation PointNets并不限于RGB 的 region proposal。同样的框架也可以扩展到鸟瞰图中的region proposal。
感想与总结
首先论文中提出了一个问题:通常的三维目标(用图像获得,3D体素)检测方法忽略了3D目标的自然状态和3D数据的不变性。所以为了解决这个问题我们采用直接在原生的点云上进行操作。但是新的问题产生,因为原生的点云很庞大,所以如何缩小查找范围,提高计算效率?为了解决这个问题,论文中就提出了结合2D目标检测来实现3D的目标检测。
由于现在的3维的传感器相对于2维图像传感器效果较差,因此选用图像进行目标的识别和二维目标区域定位;
由于锥形会朝向不同的方向,因此本文将其变换到垂直于图像的平面,对这些椎体进行标准归一化,作者说有助于提升目标的旋转不变性(原因简单:多种目标旋转过来的进行学习,测试过程中能够检测来自多个方向)。
有了2D目标检测区域和锥形的目标区域如何得到目标对应的3D点云?
- 考虑到目标在3D的自然状态下是自然分离的,使用3维的实例分割,得到粗略的目标3D点云;
- 本文方法一个锥形体只分割出一个点云对象,被完全遮挡的点云视为背景;
目标旋转过来的进行学习,测试过程中能够检测来自多个方向)。
有了2D目标检测区域和锥形的目标区域如何得到目标对应的3D点云?
- 考虑到目标在3D的自然状态下是自然分离的,使用3维的实例分割,得到粗略的目标3D点云;
- 本文方法一个锥形体只分割出一个点云对象,被完全遮挡的点云视为背景;