【论文笔记】Civil Rephrases Of Toxic Texts With Self-Supervised Transformers
Civil Rephrases Of Toxic Texts With Self-Supervised Transformers

会议:EACL2021
代码:链接
任务:言论去毒/文本复述/文本风格迁移/可控文本生成
原文:链接
Abstract
本文提出了一个自监督学习模型CAE-T5,该模型采用一种端到端的预训练的文本到文本(text-to-text)的transformer,并通过一种去噪(denoising)和循环自编码(cyclic auto-encoder)损失进行微调。本文在当前最大的毒性检测数据集Civil Comments上进行实验,和早期的文本迁移模型相比,该模型能够生成更加流畅、更好地保留原始文本内容的句子,在自动评估和人工评估指标上都得到了较好的结果。
1. Introduction
本文首次在现有的无监督模型中将Seq2Seq Transformer、大规模预训练模型迁移学习、自监督微调(去噪自编码和循环一致性)结合起来。
本文的主要贡献:
-
第二次使用无监督方法来解决言论去毒任务,并第一次使用Civil Comments数据集来应对这个任务,模型取得超越基线的有效性能。
-
开发了一个任务无关的方法,可以泛化并应用到其他相关的属性迁移任务。
2. Related Work
-
T5模型;
-
无监督机器翻译中的trick如去噪自编码和回译法;
-
无监督复杂文本属性迁移;
-
最初的无监督属性迁移方法试图为输入句子建立一个共享的、属性无关的潜在表示编码,并进行对抗训练。然后,通过一个知道目标属性的解码器,生成一个风格迁移的句子。区别于一系列无监督属性迁移方法,本文的方法与这些模型的不同之处在于,它们要么没有利用大规模预训练的Transformer,要么是没有带去噪目标的训练。
-
StyleTransformer(ST):使用无监督方法和判别网络训练Transformer来解决风格迁移任务。
-
Fighting Offensive Language on Social Media with Unsupervised Text Style Transfer.ACL2018
该文首次利用一个无监督的编码器-解码器方法来重写冒犯性句子。
-
-
无条件的言论解毒;
-
GeDi: Generative Discriminator Guided Sequence Generation.arXiv
-
Realtoxicityprompts: Evaluating neural toxic degeneration in language models.EMNLP2020
-
-
可控文本生成;
- 该任务由以文本的属性如风格为条件的语言模型组成,其和属性迁移的主要区别是没有对输入文本内容的保存进行约束。
- CTRL - A Conditional Transformer Language Model for Controllable Generation.提出用控制码来约束可控文本生成任务。
- Plug and play language models: A simple approach to controlled text generation.ICLR2020
3. Method
Our approach is based on bi-conditional encoder-decoder generation
本文的方法是训练一个以输入文本 x x x目标属性 a a a和为条件的自回归语言模型。使用 L M − p ( y ∣ x , a ; θ ) LM-p(y|x,a;θ) LM−p(y∣x,a;θ)来计算 f θ f_θ fθ。
语言模型LM使用控制码(control code),以目标属性为条件。控制码即预先添加在解码器输入 s s s上的一个固定序列,并且应该在具有目标属性 a a a的句子空间中生成。
定义: γ ( a , s ) = c o n c a t ( c ( a ) , s ) γ(a,s)=concat(c(a),s) γ(a,s)=concat(c(a),s),其中, c ( a ) c(a) c(a)是属性 a a a的控制码。
在本文中, c ( a ) = c o n c a t ( a , " : " ) c(a) = concat(a, ": ") c(a)=concat(a,":")
对于情感迁移任务, a ∈ " p o s i t i v e " , " n e g a t i v e " a ∈ {"positive", "negative"} a∈"positive","negative",而对于言论去毒任务: a ∈ " t o x i c " , " c i v i l " a ∈ {"toxic", "civil"} a∈"toxic","civil"
为了以输入文本的条件限制生成,将输入编码并输出一个内容相关而非属性相关的隐变量 z z z。(怎么理解?)
Training the encoder-decoder with an unsupervised objective
-
训练时,按照BERT的方法破坏输入文本,将模型以去噪自编码器(DAE)的方式训练,这是一个有效的自监督策略。
对于输入文本 x x x, η ( x ) η(x) η(x):以15%的概率随机mask单词,然后对于mask掉的单词,以10%的概率将其替换为词汇表中的随机单词,90%的概率将其替换为一个sentinel(一个共享的mask单词)单词。
模型的去噪自编码损失定义为:
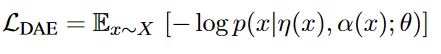
-
受到无监督的图像到图像风格迁移方法的启发,本文添加了一个循环一致性(cycle-consistency)目标,从而在生成文本的过程中实现内容保留。(这个CC损失具体原理是什么?)
循环一致性损失定义为:
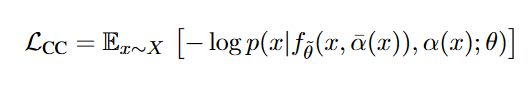
由于循环一致性目标在随机梯度下降训练过程中计算一个不可微的自回归(AR)伪预测 y ^ \hat{y} y^,因此在某一训练步时梯度不会反向传播。(怎么理解?)
-
最终的损失函数为DAE损失和CC损失加权求和产生,这两个系数是超参数。
![]()
The text-to-text bi-transformer architecture
使用基于Transformer的编码器解码器架构,但是不保留编码器和解码器之间的交叉注意力,因为生成受到输入句的太多条件的影响,但是观察到输出句中没有显著的变化。
利用编码器输出的隐藏向量 h 0 h_0 h0(即输入文本的第一个token输出的隐藏向量)进行映射变换来获取输入的潜变量表示,向量 z z z是输入序列的聚合表征。
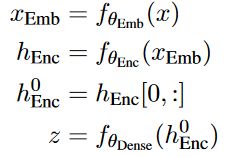
将潜变量 z z z集成到解码器的输入 s s s的每个单词的嵌入中,因为这种方式平衡了来自原始输入和来自目标属性空间中生成的输出的信号的反向传播,并且这种方式在实验中表现得比较好。
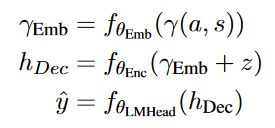
编码器和解码器共享一个嵌入层。
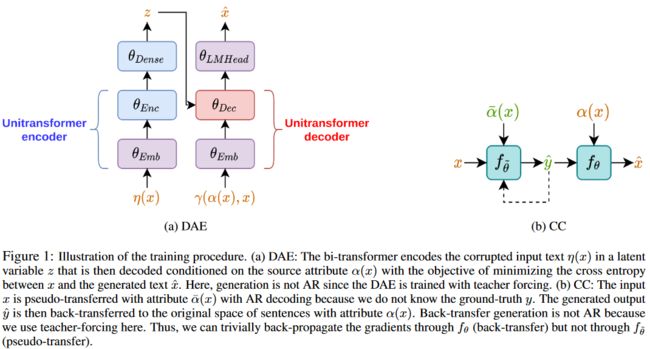

除了计算隐变量 z z z的线性层的参数外,其余参数均在预训练好的T5模型上使用DAE和CC损失进行微调。
4. Experiments
Datasets
-
Civil Comments:大数据集,有毒性和毒性子类型标注。用NLTK分句,然后用在CC数据集上预训练好的BERT毒性分类器进行句子分类,得到 X T X_T XT(表示毒性句子子集,毒性得分大于0.9)和 X C X_C XC。
-
Yelp
Evaluation
- ACC:在CC上微调好的BERT毒性分类器,阈值0.5;
- PPL:GPT2在CC和Yelp上微调;
- self-SIM:使用预训练好的通用句子编码器(Universal sentence encoder.arXiv)来编码输入和输出文本,从而计算它们的余弦相似度;
- GM:ACC、1/PPL、self-SIM。
- 人工评估。
Results
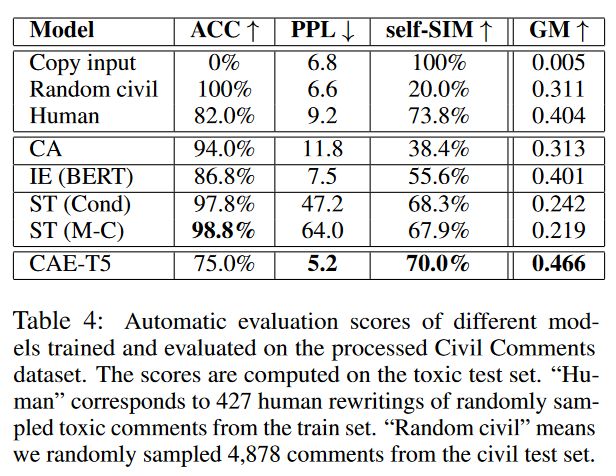
其他模型在ACC上表现好,但是在其他指标上低于CAE-T5,说明它们在毒性的判别上表现更好,但是却难以以连贯的方式复述文本。
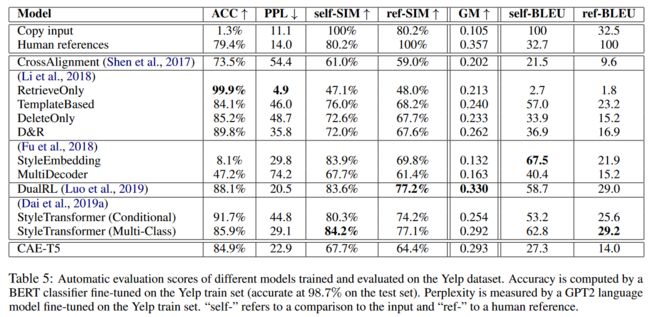
模型在Yelp数据集上性能下降,SIM很低,说明隐变量没有很好地捕捉到源文本的语义。其次,因为CAE-T5是基于子词表示法,而基线往往是基于有限大小的预训练词嵌入:如果想保持合理的词汇量,那么来自Civil Comments数据集的更多单词可能会归因于未知的标记,从而导致性能下降(怎么理解?)。但是模型在总体指标上表现都不错(如GM),仅次于强化学习,但是本文的方法比强化学习更稳定、更好训练。
Discussion
从训练集中随机采样了500个句子,雇佣500个众包标注者进行复述,并统计他们认为无法复述的言论。最后仅有约17.1%的句子被标注者们认为可以复述。原因有二,一,并非所有的毒性评论都可以改写成无毒复述,例如一些侮辱、人身攻击的严重有毒评论。二,标注者的能力和人工众包产生复述的质量有待考量。这些都使得在这一任务上使用监督学习的方法很难,而促使无监督方法的应用。
最后,对于该任务的自动评估也是一个难点,无论是ACC、PPL,还是SIM。
5. Conclusion and future work
CAE-T5利用了大规模预训练模型的自然语言理解和生成的能力来应对言论去毒任务。未来的研究工作中,作者将尝试探索解码是否能从非自回归生成(NAR)中受益,以及对范式转换(paradigm shift)工作感兴趣(Von misesfisher loss for training sequence to sequence models with continuous outputs.ICLR2019)。这两个工作应该都是在解码生成端做的工作。