BEVFusion:A Simple and Robust LiDAR-Camera Fusion Framework 论文笔记
原文链接:https://arxiv.org/abs/2205.13790
1.引言
目前的相机和激光雷达融合方法通常是将激光雷达点或提案投影到图像平面,作为查询选择相应的图像特征。但这种方法使得模型依赖于激光雷达点云。当激光雷达故障时,这些融合方法不能产生有意义的结果。
本文认为理想的融合应是各模态独立(即一个模态不应该受到其余失效模态的影响),且使用所有模态时能进一步提高性能。如下图(c)所示,本文提出BEVFusion,两个独立分支分别处理图像和激光雷达点云,将它们编码到相同的BEV空间;然后融合这些分支的BEV特征,输入到预测头。
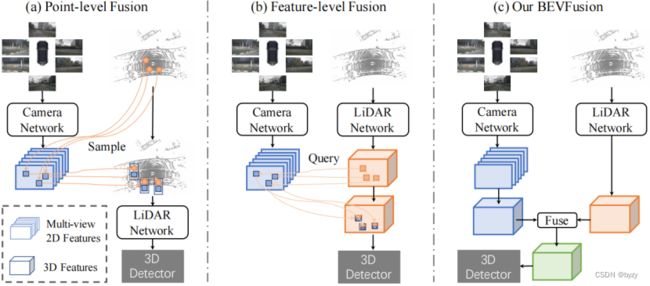
BEVFusion可直接使用单一模态BEV表达模型,如LSS、PointPillars、CenterPoint等。此外,本文还针对激光雷达失效的鲁棒性实验,提出一种新的增广技术。
3.BEVFusion
BEVFusion的详细结构如下图所示。
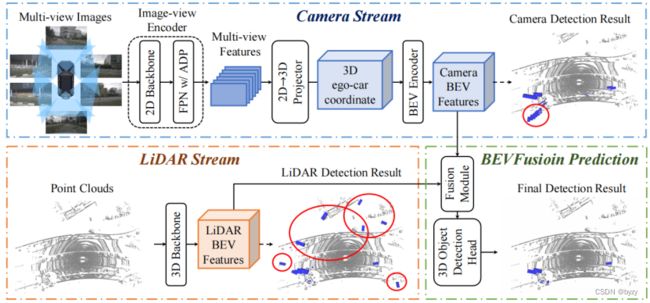
3.1 相机分支结构:从多视图图像到BEV空间
本文使用LSS的结构,但由于LSS是为BEV分割任务设计的,在3D检测任务上的性能较差,因此略有调整。如图2的上半部分所示,图像分支包含图像编码器、视图投影模块(将图像特征转移到3D空间)和BEV编码器。
图像编码器:包含用于基本特征提取的2D主干(Dual-Swin-Tiny)和用于尺度变化物体表达的颈部模块(FPN)。为更好地对齐多尺度特征,设计特征自适应模块(ADP)修正上采样的特征,即在拼接前使用自适应均值池化和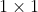 卷积处理每个上采样特征(详见附录A.1)。
卷积处理每个上采样特征(详见附录A.1)。
视图投影模块:与LSS相同,即以分类的方式预测深度分布,将图像特征提升为点云,并进一步转化为体素。
BEV编码器:未使用池化或3D卷积,而是使用空间到通道(S2C)操作,即将4D张量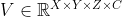 reshape为
reshape为![]() ,以保留语义信息并减小计算;再使用
,以保留语义信息并减小计算;再使用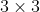 卷积提取高级特征并减小通道维度。
卷积提取高级特征并减小通道维度。
3.2 激光雷达分支结构:从点云到BEV空间
使用PointPillars、CenterPoint和TransFusion-L的结构以检验BEVFusion的泛化能力。
3.3 动态融合模块

如上图所示,使用类似Squeeze-and-Excitation的机制,用通道注意力选择重要的融合特征:
![]()
其中![]() 表示通道维度上的拼接;
表示通道维度上的拼接;![]() 是静态通道&空间融合函数(由卷积实现),用于减小通道维度;
是静态通道&空间融合函数(由卷积实现),用于减小通道维度;
![]()
其中 是线性变换阵,
是线性变换阵,![]() 是全局均值池化,
是全局均值池化, 是sigmoid函数。
是sigmoid函数。
3.4 检测头
使用三种检测头验证BEVFusion的泛化能力:基于锚框的(PointPillars)、无需锚框的(CenterPoint)和基于transformer的(TransFusion-L)。
4.实验
4.1 实验设置
实施细节:先预训练两个分支,然后训练BEVFusion。激光雷达分支使用翻转、全局旋转、全局缩放等数据增广方法,并使用CBGS进行类平衡采样;相机分支在多视图图像输入条件下,没有使用任何数据增广(如翻转、旋转、CBGS)。
4.2 泛化能力
在不同激光雷达主干和检测头下,BEVFusion均能大幅超过相应的激光雷达方法。
4.3 与SOTA方法的比较
本文比TransFusion性能略高,尽管TransFusion使用了两个解码器(即检测头;可视为两阶段网络),而BEVFusion仅有一个检测头。本文与TransFusion的区别仅在于融合方法上,说明了BEV融合的好处。
4.4 鲁棒性实验
4.4.1 激光雷达失效的鲁棒性实验
考虑两种激光雷达失效:激光雷达故障,即有有限角度的视野;物体不能反射激光雷达点。
为鲁棒性实验进行数据增广:模拟激光雷达视野受限的情况,将视野角度限制在180°和120°;以50%的概率丢弃物体,以50%的概率丢弃物体内的点。训练时,在增广数据集上微调检测头。
激光雷达故障:使用上述数据增广方案训练时,相比激光雷达单一模态方法以及原始的TransFusion,BEVFusion对视野受限具有更强的鲁棒性。
物体不能反射激光雷达点:在未使用数据增广时,BEVFusion就能超过激光雷达单一模态方法和TransFusion;引入数据增广后,BEVFusion进一步大幅提高性能,而TransFusion甚至出现性能下降,这可能是增广数据集中前景点的缺失带来了错误的监督。
以上结果说明本文融合相机的方法能在一定程度上补偿激光雷达失效问题。
4.4.2 相机失效的鲁棒性实验
实验了三种相机故障:仅前视相机故障、除前视相机外均故障、50%的相机卡帧。结果表明本文方法在任何情况下均比相机单一模态方法和其他融合方法性能更优。
4.5 消融研究
相机分支:与ResNet18 BEV编码器相比,使用本文的BEV编码器能大幅提高性能;FPN中的自适应特征对齐模块能略微提高性能;使用更大的2D主干能带来更好的性能。
动态融合模块:仅使用通道&空间融合(图3蓝色区域)即可大幅提高PointPillars、CenterPoint和TransFusion的性能,进一步使用自适应特征选择(图3橙色区域)能进一步提高性能。
A.附录
A.1 网络结构
FPN自适应模块的结构:如下图所示。
